一种基于PGM的问题分类方法与流程
本发明涉及一种分类方法,具体为一种基于pgm的问题分类方法,属于计算机软件领域。
背景技术:
随着信息技术突飞猛进的发展,信息检索的形式从原始的关键词检索发展到基于问答形式的检索,相应的应用比如百度知道、搜搜问问、知乎等问答社区发展迅速,问答系统以用户自然语言作为输入,根据一定规则,从大规模文档集合中提取用户所提问题的可能答案,问答系统具体涉及问题分类、信息检索和答案抽取三个部分,其中问题分类负责限定答案空间、选择答案策略;信息检索根据问题中的关键词在文档集合中搜索可能的结果;答案抽取根据问题分类的限定和信息检索的结果,寻找适合的答案作为问答系统的响应返回给用户,其中的问题分类过程对之后的答案抽取有重要的指导意义,好的问题分类性能会使得问答系统整体准确性有很大幅度提升,与此相反,问题分类性能不好,会直接影响后续答案抽取的结果,有文献指出,问答系统中36.4%的错误来自于问题分类过程。因此,对问题分类的研究对问答系统有重要价值。
问题分类在一般意义上来说属于分类问题,可以借鉴经典的分类算法,例如最小距离分类器、k-means分类、朴素贝叶斯分类、支持向量机分类等,而问题分类由于其特殊的应用场景,又有别于普通分类问题,对于问题分类的现有研究主要基于两种算法:基于规则的分类方法、基于机器学习的分类方法。
基于规则的问题分类方法利用专家知识给每个问题类型预设一组规则,当待解决问题符合这些规则时,判定该问题属于该类别,该方法有较高的准确性和针对性,解释性强,但主要缺点是人工建立和维护规则库的工作量很大,依赖于专家知识,灵活性差。
基于机器学习的问题分类方法建立分类模型,并通过训练数据集训练得到模型参数,进而利用该模型对未知类型问题进行分类。该方法一般涉及svm、朴素贝叶斯、最大熵等算法,方法具有很强的适应性及很好的性能,是现在主流的问题分类方法。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种基于pgm的问题分类方法。
本发明通过以下技术方案来实现上述目的:一种基于pgm的问题分类方法,包括建模和推理;所述建模通过手工分类训练数据集,并将已分类的标记数据集带入概率图模型,构建有向无环网(dag)网络结构,计算各观测节点的先验概率和条件概率,得到模型条件概率分布(cpd),所述推理根据已有网络结构及cpd,基于gibbs算法进行贝叶斯推理,进而得到问题分类。
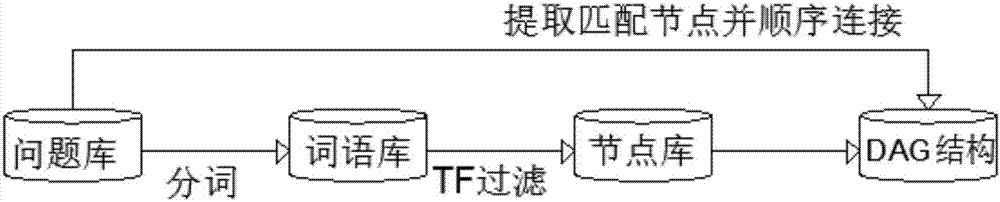
优选的,步骤a,分词并筛选,用中科院nlpir汉语分词系统对数据集中的语句进行分词处理,其分词正确率可以达到97.58%,分词后去除其中的助动词、语气词、连接词等虚词;
步骤b,问题分类体系,根据对数据集中数据的分析,并结合现有分类方法的经验,将数据分为6个大类,73个小类;
步骤c,构建概率图模型,构建概率图g,其中g=<u,v>,u是节点的集合,每个节点代表一个词语或者一个分类,v是边的集合,每条有向边代表一个句子中两个词的前后关系,边上的值代表该边对应的前后关系组合出现的次数;
步骤d,基于贝叶斯推理的分类方法,上述步骤利用训练数据集,构建了概率图模型dag结构并得到了条件概率分布cpd,至此完成了模型构建阶段任务,将待分类数据代入概率图模型并根据概率理论推测某种情况出现的概率,是推理阶段需要完成的任务。
优选的,所述步骤a中,避免将每个语句中的词都加入概率图中,对分词之后的结果进行计数,计算每个词的tf值,设定tf超过一定阈值的词参与构建概率图网络。
优选的,所述步骤b中,具体分类过程进行两个概率图模型的训练,一个是基于6个大类的概率图模型,一个是基于73个小类的概率图模型。
优选的,所述步骤c中,根据训练数据集中标记的分类结果,计算各个分类的先验概率,并且根据概率图g中各个有向边的连接关系和权值计算各词对各个分类的条件概率以及词之间的条件概率,从而得到概率图模型的dag结构和条件概率分布cpd。
优选的,所述步骤d中,贝叶斯推理的分类包括gibbs采样和概率图模型的贝叶斯推理过程,gibbs采样其过程可假设系统由n个变量组成,不妨定义系统状态x(x1,x2,…,xn),并且对于任何一个变量xi,都能直接从条件分布p(xi|x1,x2,…,xi-1,xi+1,…xn)中为其采样,贝叶斯推理过程以待分类问题分词作为输入,将分类为输出,将概率图模型中其他节点作为非证据节点进行随机采样,通过计算概率图中节点的条件概率,更新各个节点状态,直到达到系统规定的采样阈值次数,进而计算各个分类的概率值,根据最大后验概率假设,选择概率值最大的一个分类作为输入问题的分类结果。
本发明的有益效果是:该基于pgm的问题分类方法设计合理,建立概率图模型,并利用训练数据对模型进行训练,用训练好的模型进行问题分类,与现有问题分类算法相比,该方法既有基于规则问题分类方法解释性强的特点,又具有基于机器学习问题不依赖专家知识,自动学习的优势。
附图说明
图1为本发明基于pgm的问题分类示意图;
图2为本发明概率图构建流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1和2,一种基于pgm的问题分类方法,包括建模和推理;所述建模通过手工分类训练数据集,并将已分类的标记数据集带入概率图模型,构建有向无环网(dag)网络结构,计算各观测节点的先验概率和条件概率,得到模型条件概率分布(cpd),所述推理根据已有网络结构及cpd,基于gibbs算法进行贝叶斯推理,进而得到问题分类。
一种基于pgm的问题分类方法,具体包括以下步骤。
步骤a,分词并筛选,用中科院nlpir汉语分词系统对数据集中的语句进行分词处理,其分词正确率可以达到97.58%,分词后去除其中的助动词、语气词、连接词等虚词;
步骤b,问题分类体系,根据对数据集中数据的分析,并结合现有分类方法的经验,将数据分为6个大类,73个小类;
步骤c,构建概率图模型,构建概率图g,其中g=<u,v>,u是节点的集合,每个节点代表一个词语或者一个分类,v是边的集合,每条有向边代表一个句子中两个词的前后关系,边上的值代表该边对应的前后关系组合出现的次数;
步骤d,基于贝叶斯推理的分类方法,上述步骤利用训练数据集,构建了概率图模型dag结构并得到了条件概率分布cpd,至此完成了模型构建阶段任务,将待分类数据代入概率图模型并根据概率理论推测某种情况出现的概率,是推理阶段需要完成的任务。
其中,所述步骤a中,避免将每个语句中的词都加入概率图中,对分词之后的结果进行计数,计算每个词的tf值,设定tf超过一定阈值的词参与构建概率图网络,所述步骤b中,具体分类过程进行两个概率图模型的训练,一个是基于6个大类的概率图模型,一个是基于73个小类的概率图模型,具体定义如下表所示:
所述步骤c中,根据训练数据集中标记的分类结果,计算各个分类的先验概率,并且根据概率图g中各个有向边的连接关系和权值计算各词对各个分类的条件概率以及词之间的条件概率,从而得到概率图模型的dag结构和条件概率分布cpd,所述步骤d中,贝叶斯推理的分类包括gibbs采样和概率图模型的贝叶斯推理过程,gibbs采样其过程可假设系统由n个变量组成,不妨定义系统状态x(x1,x2,…,xn),并且对于任何一个变量xi,都能直接从条件分布p(xi|x1,x2,…,xi-1,xi+1,…xn)中为其采样,贝叶斯推理过程以待分类问题分词作为输入,将分类为输出,将概率图模型中其他节点作为非证据节点进行随机采样,通过计算概率图中节点的条件概率,更新各个节点状态,直到达到系统规定的采样阈值次数,进而计算各个分类的概率值,根据最大后验概率假设,选择概率值最大的一个分类作为输入问题的分类结果。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!