智能机器人及人机交互方法与流程
本发明涉及机器人领域,尤其涉及一种智能机器人及人机交互方法。
背景技术:
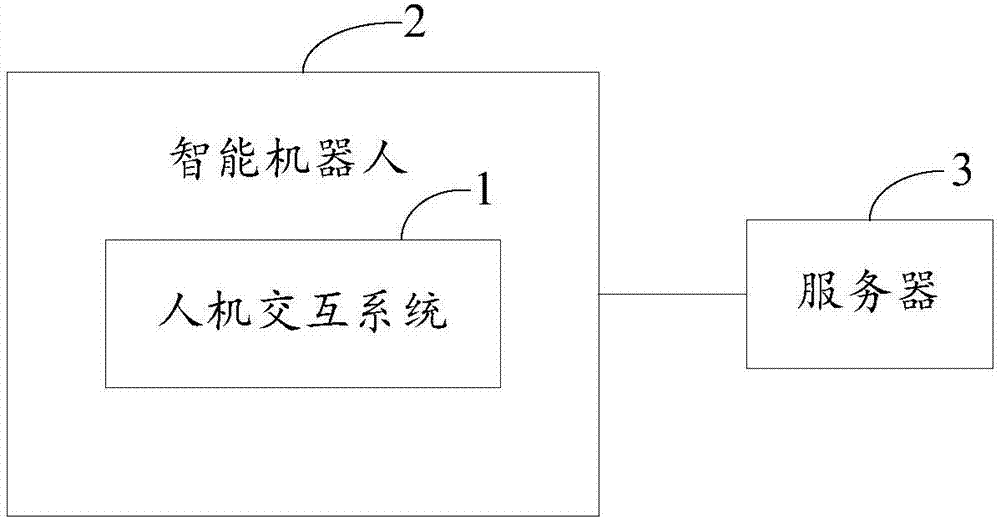
:现有技术中,机器人与人之间的交互主要涉及简单的人机对话,或在人的指令下完成特定的工作内容。然而,能够使机器人从社会的伦理道德、法律法规、天文地理及人际关系(如,家庭关系、同事关系、朋友关系)等方面深入地理解用户的情感和情绪的问题并与用户进行交互的方案却很少。技术实现要素:鉴于以上内容,有必要提供一种智能机器人及人机交互方法以深入地理解用户的情感和情绪的问题并与用户进行交互。一种智能机器人,包括摄像单元、语音采集单元、输出单元及处理单元,该处理单元用于:获取来自该语音采集单元获取的语音信息及该摄像单元获取的图像信息;从获取的语音信息及图像信息中识别一目标对象;确定出与该目标对象对应的基本信息及相关事件信息,并将该目标对象的基本信息与该相关事件信息进行关联;从该目标对象对应的相关事件信息中提取关键信息;根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别,根据所提取的关键信息检索预设的公共基础知识库以获取与该关键信息相关联的检索结果,并利用深度学习算法根据该检索结果及该目标对象的情绪类别确定出一反馈模型,其中,该反馈模型是指用于控制该智能机器人与该目标对象进行交互的指令集;及通过该输出单元执行该反馈模型。优选地,该处理单元从该语音信息中识别一声纹特征及从该图像信息中识别脸部特征,并根据该声纹特征及该脸部特征识别对应的目标对象。优选地。该处理单元控制该语音采集单元采集该目标对象的语音信息作为该目标对象的相关事件信息。优选地,该处理单元识别所获取的语音信息,将所识别的语音信息转化为文本数据,提取出该文本数据中的关键信息,并将该文本数据中的关键信息作为该相关事件的关键信息。优选地,该处理单元控制该摄像单元获取该目标对象的图片信息作为该目标对象的相关事件信息。优选地,该处理单元获取该图片信息中包含的面部表情信息及肢体动作特征信息,对所获取的面部表情信息进行面部表情特征提取后确定出面部表情特征参数,对所获取的肢体动作信息进行肢体特征提取后确定出肢体特征参数,并将该面部表情特征参数及肢体特征参数作为该相关事件信息的关键信息。优选地,该处理单元还用于设定该智能机器人的情感方向,该处理单元从该目标对象的相关事件信息中提取关键信息,根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别,根据所提取的关键信息检索预设的公共基础知识库,并利用深度学习算法根据检索结果、该目标对象的情绪类别及设定的该智能机器人的情感方向确定出对应的反馈模型。优选地,该输出单元包括语音输出单元及表情输出单元,该执行模块通过控制该语音输出单元输出语音信息,及通过该表情输出单元输出表情动作的方式执行该反馈模型。一种人机交互方法,应用在一智能机器人中,该方法包括步骤:获取一语音采集单元获取的语音信息:获取一摄像单元获取的图像信息;从获取的语音信息及图像信息中识别一目标对象;确定出与该目标对象对应的基本信息及相关事件信息,并将该目标对象的基本信息与该相关事件信息进行关联;从该目标对象对应的相关事件信息中提取关键信息;根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别,根据所提取的关键信息检索预设的公共基础知识库以获取与该关键信息相关联的检索结果,并利用深度学习算法根据该检索结果及该目标对象的情绪类别确定出一反馈模型,其中,该反馈模型是指用于控制该智能机器人与该目标对象进行交互的指令集;及通过一输出单元执行该反馈模型。优选地,该方法在步骤“从获取的语音信息及图像信息中识别一目标对象”还包括:从该语音信息中识别一声纹特征及从该图像信息中识别脸部特征,并根据该声纹特征及该脸部特征识别对应的目标对象。优选地,该方法在步骤“确定出与该目标对象对应的基本信息及相关事件信息,并将该目标对象的基本信息与该相关事件信息进行关联”中包括:控制该语音采集单元采集该目标对象的语音信息作为该目标对象的相关事件信息。优选地,该方法还包括步骤:识别所获取的语音信息,将所识别的语音信息转化为文本数据,提取出该文本数据中的关键信息,并将该文本数据中的关键信息作为该相关事件的关键信息。优选地,该方法在步骤“确定出与该目标对象对应的基本信息及相关事件信息,并将该目标对象的基本信息与该相关事件信息进行关联”中包括:控制该摄像单元获取该目标对象的图片信息作为该目标对象的相关事件信息。优选地,该方法还包括步骤:获取该图片信息中包含的面部表情信息及肢体动作特征信息,对所获取的面部表情信息进行面部表情特征提取后确定出面部表情特征参数,对所获取的肢体动作信息进行肢体特征提取后确定出肢体特征参数,并将该面部表情特征参数及肢体特征参数作为该相关事件信息的关键信息。优选地,该方法还包括步骤:通过控制一语音输出单元输出语音信息,及通过一表情输出单元输出表情动作的方式执行该反馈模型。本案中的智能机器人及人机交互方法能够深入地理解用户的情感和情绪的问题并与用户进行交互,提高了用户的体验感。附图说明图1为本发明一实施方式中人机交互系统的应用环境图。图2为本发明一实施方式中智能机器人的功能模块图。图3为本发明一实施方式中人机交互系统的功能模块图。图4为本发明一实施方式中基本信息表的示意图。图5为本发明一实施方式中人机交互方法的流程图。主要元件符号说明人机交互系统1智能机器人2服务器3摄像单元22语音采集单元23压力感测器24输出单元25味道感测器26通信单元27处理单元28存储单元29语音输出单元251表情输出单元252运动驱动单元253显示单元254感知模块101识别模块102分析模块103执行模块104设置模块105基本信息表t1步骤s501~s506如下具体实施方式将结合上述附图进一步说明本发明。具体实施方式请参考图1,所示为本发明一实施方式中人机交互系统1的应用环境图。该人机交互系统1应用在一智能机器人2中。该智能机器人2与一服务器3通信连接。该人机交互系统1用于控制该智能机器人2与用户进行交互。请参考图2,所示为本发明一实施方式中智能机器人2的功能模块图。该智能机器人2包括摄像单元22、语音采集单元23、压力感测器24、输出单元25、味道感测器26、通信单元27、处理单元28及存储单元29。该摄像单元22摄取智能机器人2周围环境的图像并将摄取的图像传送给处理单元28。例如,该摄像单元22可以摄取智能机器人2周围的人、动物或静止物体的画面,及将获取的人、动物或静止物体的画面传送给该处理单元28。本实施方式中,该摄像单元22可以为一摄像头、3d光场相机等。该语音采集单元23用于接收智能机器人2周围的语音信息并将接收的语音信息传送给处理单元28。在本实施方式中,该语音采集单元23可以为麦克风、麦克风阵列等。该压力感测器24用于检测用户对该智能机器人2的按压力信息及将检测出的按压力信息传送给处理单元28。该输出单元25包括语音输出单元251、表情输出单元252、运动驱动单元253及显示单元254。该语音输出单元251用于在该处理单元28的控制下输出语音信息。在本实施方式中,该语音输出单元251可以为扬声器。表情输出单元252用于在该处理单元28的控制下输出表情动作。在一实施方式中,该表情输出单元252包括设于机器人头部可开合的眼帘和嘴巴及设于眼帘内可转动的眼球。该运动驱动单元253用于在该处理单元28的控制下控制该智能机器人2的控制下驱动该智能机器人2移动。在一实施方式中,该运动驱动单元253包括两轴或四轴驱动轮。该显示单元254用于显示表情图像,如高兴、苦恼、忧郁表情等。该味道感测器26用于检测气味信息。该通信单元27用于供该智能机器人2与一服务器3(如图1所示)通信连接。在一实施方式中,该通信单元27可以为wifi通信模块、zigbee通信模块及bluetooth通信模块。该存储单元29用于存储该智能机器人2的程序代码及数据资料。例如,该存储单元29可以存储预设人脸图像、预设语音及人机交互系统1。本实施方式中,该存储单元29可以为该智能机器人2的内部存储单元,例如该智能机器人2的硬盘或内存。在另一实施方式中,该存储单元29也可以为该智能机器人2的外部存储设备,例如该智能机器人2上配备的插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)等。本实施方式中,该处理单元28可以为一中央处理器(centralprocessingunit,cpu),微处理器或其他数据处理芯片,该处理单元28用于执行软件程序代码或运算数据。请参考图3,所示为本发明一实施方式中人机交互系统1的功能模块图。本实施方式中,该人机交互系统1包括一个或多个模块,所述一个或者多个模块被存储于该存储单元29中,并被该处理单元28所执行。人机交互系统1包括感知模块101、识别模块102、分析模块103、执行模块104及设置模块105。在其他实施方式中,该人机交互系统1为内嵌在该智能机器人2中的程序段或代码。该感知模块101获取来自该语音采集单元23获取的语音信息及该摄像单元22获取的图像信息。该识别模块102用于从获取的语音信息及图像信息中识别一目标对象。在一实施方式中,该识别模块102对获取的语音信息进行语音信号预处理,例如进行去噪处理,使得语音识别时更加准确。在一实施方式中,该识别模块102从语音信息中识别一声纹特征及从图像信息中识别脸部特征,并根据该声纹特征及该脸部特征识别该目标对象。该目标对象包括人及动物。例如,该存储单元29中存储一第一对应关系表(图中未示),该第一对应关系表中定义了声纹特征、脸部特征及目标对象的对应关系,该识别模块102根据识别出的声纹特征、脸部特征及该第一对应关系表确定该目标对象。在另一实施方式中,该识别模块102也可以仅从获取的语音信息中识别该目标对象。例如,该存储单元29中存储一第二对应关系表(图中未示),该第二对应关系表中定义了声纹特征及目标对象的对应关系。该识别模块102根据识别出的声纹特征及该第二对应关系表确定该目标对象。在其他实施方式中,该识别模块102也可以仅从获取的图像信息中识别该目标对象。例如,该存储单元29中存储一第三对应关系表(图中未示)。该第三对应关系表中定义该脸部特征与该目标对象的对应关系,该识别模块102根据识别出的脸部特征及该第三对应关系表确定该目标对象。在一实施方式中,该识别模块102将获取的图像与存储在存储单元29中的图片集进行比对确定出获取的图像中的脸部特征,该识别模块102根据识别出的脸部特征及该第三对应关系表确定该目标对象。在一实施方式中,该目标对象还包括静止物体,例如桌子,椅子,房子等物体。该识别模块102还用于将通过从该摄像单元22中获取的图片与一存储在存储单元29中的图片集进行比对,并根据比对结果确定出该图片中包含的静止物体。其中,该图片集中的每一幅图片对应包含一静止物体。例如,该识别模块102将获取的图片与存储的图片集进行比对后确定该图片中的物体与存储的图片集中一幅图片所包含的房子一致时,该识别模块102识别出该获取的图片中的目标对象为房子。该识别模块102还用于确定出与该目标对象相关的信息,例如,基本信息及相关事件信息,并将该目标对象的基本信息与该相关事件信息进行关联。在一实施方式中,所述相关的信息包括,但不限于,该目标对象的基本信息、及与该目标对象相关的事件信息。在一实施方式中,当目标对象为人时,该目标对象的基本信息包括,但不限于,用户的姓名、年龄、身高、体重、体型(例如,大体型、中体型、小体型)。当目标对象为物体时,该目标对象的基本信息包括,但不限于,目标对象的名称、位置、功能属性等。例如,该存储单元29存储一基本信息表t1(参考图4),该基本信息表t1定义了目标对象与基本信息的对应关系。该识别模块102根据该目标对象及该基本信息表t1确定出与该目标对象对应的基本信息。在一实施方式中,与该目标对象相关的事件信息可以是指发生在某个时间或某个地点的与该目标对象相关的事件。在一实施方式中,当识别出目标对象时,该识别模块102控制该语音采集单元23采集该目标对象的语音信息作为该目标对象的相关事件信息。在另一实施方式中,当识别出目标对象时,该识别模块102控制该摄像单元22获取该目标对象的图片信息作为相关事件信息。在其他实施方式中,当识别出目标对象时,该识别模块102同时将通过语音采集单元23采集的语音信息及通过摄像单元22摄取的图片信息作为该目标对象的相关事件信息。该分析模块103用于从该目标对象对应的相关事件信息中提取关键信息。例如,当该目标对象的相关事件信息为语音信息时,该分析模块103识别所获取的语音信息,将所识别的语音信息转化为文本数据,提取出该文本数据中的关键信息,及将该文本数据中的关键信息作为该相关事件的关键信息。本实施方式中,该文本数据中的关键信息包括关键词、关键字、或关键语句。当该当目标对象的相关事件信息为图片信息时,该分析模块103获取该图片信息中包含的面部表情信息及肢体动作特征信息,对所获取的面部表情信息进行面部表情特征提取后确定出面部表情特征参数,对所获取的肢体动作信息进行肢体特征提取后确定出肢体特征参数,并将该面部表情特征参数及肢体特征参数作为该相关事件信息的关键信息。该分析模块103根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别,根据所提取的关键信息检索预设的公共基础知识库以获取与该关键信息相关联的检索结果,并利用深度学习算法根据该检索结果及该目标对象的情绪类别确定出一反馈模型。本实施方式中,该反馈模型是指用于控制该智能机器人2与该目标对象进行交互的指令集。本实施方式中,该公共基础知识库可以包括,但不限于人文伦理知识库、法律法规知识库、道德情操知识库、宗教知识库、天文地理知识库。在一实施方式中,该公共基础知识库存储在该智能机器人2的存储单元29中。该智能机器人2可以直接访问该存储单元29中的公共基础知识库。在其他实施方式中,该公共基础知识库存储在服务器3中。该智能机器人2通过通信单元27访问该服务器3中的公共基础知识库。本实施方式中,该深度学习算法包括,但不限于,“神经词袋模型”、“递归神经网络”、“循环神经网络”、“卷积神经网络”。本实施方式中,该目标对象的情绪类别包括高兴、悲伤、愤怒、平和、暴躁等情绪。例如,当用户微笑着对智能机器人2说“这些花真漂亮啊!”时,该感知模块101通过该语音采集单元23获取用户的语音信息,及通过该摄像单元22获取包含用户的图像信息。该识别模块102根据用户的语音信息识别出用户的声纹特征及根据用户的图像信息识别出用户的脸部特征。该识别模块102根据该识别出的声纹特征及脸部特征识别出目标对象为用户。该识别模块102确定出用户的基本信息,及将用户发出的语音信息“这些花真漂亮啊!”及用户微笑的图像信息作为用户的相关事件信息,并将用户的基本信息与用户的相关事件信息进行关联。该分析模块103从用户发出的语音信息“这些花真漂亮啊!”提取出关键信息为“花”、“漂亮”,及从用户微笑的图像信息中提取出关键信息为“微笑表情”。该分析模块103根据所提取的该些关键信息“花、漂亮、微笑表情”利用神经网络分析算法确定该目标对象的情绪类别为高兴。该分析模块103根据所提取的上述关键信息检索预设的公共基础知识库,并利用深度学习算法根据检索结果及高兴的情绪类别确定出对应的反馈模型。在一实施方式中,该设置模块105用于设定该智能机器人2的情感方向。在一实施方式中,该设定的情感方向包括励志型、安慰型、讽刺型、幽默型等。该分析模块103从该目标对象的相关事件信息中提取关键信息,根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别,根据所提取的关键信息检索预设的公共基础知识库,并利用深度学习算法根据检索结果、该目标对象的情绪类别及该设定的智能机器人2的情感方向确定出对应的反馈模型。本实施方式中,该情绪类别包括,但不限于,高兴、愤怒、悲伤、愉快等情绪。在一实施方式中,该感知模块101还用于通过该压力感测器24感测用户输入的按压力,及通过该味道感测器26检测该智能机器人2周围环境的气味信息。该分析模块103还用于根据所提取的关键信息检索预设的公共基础知识库以获取与该关键信息相关联的检索结果,并利用深度学习算法根据该检索结果、该目标对象的情绪类别、该感测的按压力及该感测的气味信息确定出对应的反馈模型。该执行模块104用于通过该输出单元25执行该反馈模型。在一实施方式中,该执行模块104通过该输出单元25输出语音信息及输出表情动作的方式来执行该反馈模型以实现该智能机器人2与目标对象之间的交互。具体的,该执行模块104通过语音输出单元251输出语音信息、通过表情输出单元252输出表情动作的方式执行该反馈模型。例如,当用户微笑着对智能机器人2说“这些花真漂亮啊!”时,该识别模块102识别出该目标对象为用户。该分析模块103从用户发出的语音信息“这些花真漂亮啊!”提取出关键信息为“花”、“漂亮”,及从用户微笑的图像信息中提取出关键信息为“微笑表情”。该分析模块103根据所提取的该些关键信息“花、漂亮、微笑表情”利用神经网络分析算法确定该目标对象的情绪类别为高兴。该分析模块103根据所提取的关键信息“花、漂亮、微笑表情”检索预设的公共基础知识库,并利用深度学习算法根据检索结果及高兴的情绪类别确定出对应的反馈模型。该反馈模型为控制该智能机器人2输出语音信息“这些花真的很漂亮,我也很喜欢!”及输出笑容的表情动作的指令。该执行模块104通过语音输出单元251输出“这些花真的很漂亮,我也很喜欢!”的语音信息及通过表情输出单元252控制设于智能机器人2头部中的眼帘和嘴巴开合及设于眼帘内的眼球转动输出笑容表情动作,从而实现该智能机器人2与用户进行交互。在其他实施方式中,该执行模块104还通过运动驱动单元253控制该智能机器人2以预设移动的方式及控制该显示单元254显示一预设表情图像的方式来执行该反馈模型以实现该智能机器人2与目标对象之间的交互。请参考图5,所示为本发明一实施方式中人机交互方法的流程图。该方法应用在智能机器人2中。根据不同需求,该流程图中步骤的顺序可以改变,某些步骤可以省略或合并。该方法包括如下步骤。s501:获取来自语音采集单元23获取的语音信息及摄像单元22获取的图像信息。s502:从获取的语音信息及图像信息中识别一目标对象。在一实施方式中,该智能机器人2对获取的语音信息进行语音信号预处理,例如进行去噪处理,使得语音识别时更加准确。在一实施方式中,该智能机器人2从语音信息中识别一声纹特征及从图像信息中识别脸部特征,并根据该声纹特征及该脸部特征识别该目标对象。该目标对象包括人及动物。在一实施方式中,该目标对象还包括静止物体,例如桌子,椅子,房子等物体。该智能机器人2还用于将通过从该摄像单元22中获取的图片与一存储在存储单元29中的图片集进行比对,并根据比对结果确定出该图片中包含的静止物体。s503:确定出与该目标对象对应的基本信息及相关事件信息,并将该目标对象的基本信息与该相关事件信息进行关联。在一实施方式中,所述相关信息包括,但不限于,该目标对象的基本信息、及与该目标对象相关的事件信息。在一实施方式中,当目标对象为人时,该目标对象的基本信息包括,但不限于,用户的姓名、年龄、身高、体重、体型(例如,大体型、中体型、小体型)。当目标对象为物体时,该目标对象的基本信息包括,但不限于,目标对象的名称、位置、功能属性等。例如,该存储单元29存储一基本信息表t1(参考图4),该基本信息表t1定义了目标对象与基本信息的对应关系。该智能机器人2根据该目标对象及该基本信息表t1确定出与该目标对象对应的基本信息。在一实施方式中,与该目标对象相关的事件信息可以是指发生在某个时间或某个地点的与该目标对象相关的事件。该智能机器人2可以控制该语音采集单元23采集该目标对象的语音信息作为该目标对象的相关事件信息。在另一实施方式中,该智能机器人2可以控制该摄像单元22获取该目标对象的图片信息作为相关事件信息。在其他实施方式中,该智能机器人2同时将通过语音采集单元23采集的语音信息及通过摄像单元22摄取的图片信息作为该目标对象的相关事件信息。s504:从该目标对象对应的相关事件信息中提取关键信息。例如,当该目标对象的相关事件信息为语音信息时,该智能机器人2识别所获取的语音信息,将所识别的语音信息转化为文本数据,提取出该文本数据中的关键信息,及将该文本数据中的关键信息作为该相关事件的关键信息。当该当目标对象的相关事件信息为图片信息时,该智能机器人2获取该图片信息中包含的面部表情信息及肢体动作特征信息,对所获取的面部表情信息进行面部表情特征提取后确定出面部表情特征参数,对所获取的肢体动作信息进行肢体特征提取后确定出肢体特征参数,并将该面部表情特征参数及肢体特征参数作为该相关事件信息的关键信息。s505:根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别,根据所提取的关键信息检索预设的公共基础知识库以获取与该关键信息相关联的检索结果,并利用深度学习算法根据该检索结果及该目标对象的情绪类别确定出一反馈模型。本实施方式中,该反馈模型是指用于控制该智能机器人2与该目标对象进行交互的指令集。本实施方式中,该公共基础知识库可以包括,但不限于人文伦理知识库、法律法规知识库、道德情操知识库、宗教至少库、天文地理知识库。在一实施方式中,该公共基础知识库存储在该智能机器人2的存储单元29中。该智能机器人2可以直接访问该存储单元29中的公共基础知识库。在其他实施方式中,该公共基础知识库存储在服务器3中。该智能机器人2通过通信单元27访问该服务器3中的公共基础知识库。本实施方式中,该深度学习算法包括,但不限于,“神经词袋模型”、“递归神经网络”、“循环神经网络”、“卷积神经网络”。本实施方式中,该目标对象的情绪类别包括高兴、悲伤、愤怒、平和、暴躁等情绪。例如,当用户微笑着对智能机器人2说“这些花真漂亮啊!”时,该对智能机器人2通过该语音采集单元23获取用户的语音信息,及通过该摄像单元22获取包含用户的图像信息。该对智能机器人2根据用户的语音信息识别出用户的声纹特征及根据用户的图像信息识别出用户的脸部特征。该对智能机器人2根据该识别出的声纹特征及脸部特征识别出目标对象为用户。该对智能机器人2确定出用户的基本信息,及将用户发出的语音信息“这些花真漂亮啊!”及用户微笑的图像信息作为用户的相关事件信息,并将用户的基本信息与用户的相关事件信息进行关联。该对智能机器人2从用户发出的语音信息“这些花真漂亮啊!”提取出关键信息为“花”、“漂亮”,及从用户微笑的图像信息中提取出关键信息为“微笑表情”。该对智能机器人2根据所提取的该些关键信息“花、漂亮、微笑表情”利用神经网络分析算法确定该目标对象的情绪类别为高兴。该对智能机器人2根据所提取的上述关键信息检索预设的公共基础知识库,并利用深度学习算法根据检索结果及高兴的情绪类别确定出对应的反馈模型。s506:通过输出单元25执行该反馈模型。在一实施方式中,该智能机器人2通过该输出单元25输出语音信息及输出表情动作的方式来执行该反馈模型以实现该智能机器人2与目标对象之间的交互。具体的,该智能机器人2通过语音输出单元251输出语音信息、通过表情输出单元252输出表情动作的方式执行该反馈模型。例如,当用户微笑着对智能机器人2说“这些花真漂亮啊!”时,该智能机器人2识别出该目标对象为用户。该智能机器人2从用户发出的语音信息“这些花真漂亮啊!”提取出关键信息为“花”、“漂亮”,及从用户微笑的图像信息中提取出关键信息为“微笑表情”。该智能机器人2根据所提取的该些关键信息“花、漂亮、微笑表情”利用神经网络分析算法确定该目标对象的情绪类别为高兴。该智能机器人2根据所提取的关键信息“花、漂亮、微笑表情”检索预设的公共基础知识库,并利用深度学习算法根据检索结果及高兴的情绪类别确定出对应的反馈模型。该反馈模型为控制该智能机器人2输出语音信息“这些花真的很漂亮,我也很喜欢!”及输出笑容的表情动作的指令。该智能机器人2通过语音输出单元251输出“这些花真的很漂亮,我也很喜欢!”的语音信息及通过表情输出单元252控制设于智能机器人2头部中的眼帘和嘴巴开合及设于眼帘内的眼球转动输出笑容表情动作,从而实现该智能机器人2与用户进行交互。在其他实施方式中,该智能机器人2还通过运动驱动单元253控制该智能机器人2以预设移动的方式及控制该显示单元254显示一预设表情图像的方式来执行该反馈模型以实现该智能机器人2与目标对象之间的交互。在一实施方式中,该方法还包括步骤:设定该智能机器人的情感方向;从该目标对象的相关事件信息中提取关键信息;根据所提取的关键信息利用神经网络分析算法确定该目标对象的情绪类别;根据所提取的关键信息检索预设的公共基础知识库;及并利用深度学习算法根据检索结果、该目标对象的情绪类别及该设定的智能机器人2的情感方向确定出对应的反馈模型。在一实施方式中,该设定的情感方向包括励志型、安慰型、讽刺型、幽默型等。在一实施方式中,该方法还包括步骤:通过压力感测器24感测用户输入的按压力;通过该味道感测器26检测智能机器人2周围环境的气味信息;及根据所提取的关键信息检索预设的公共基础知识库,并利用深度学习算法根据检索结果、该目标对象的情绪类别、该感测的按压力及该感测的气味信息确定出对应的反馈模型。以上实施例仅用以说明本发明的技术方案而非限制,尽管参照以上较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换都不应脱离本发明技术方案的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1