一种快速的自然场景文本检测方法与流程
本发明涉及图像处理领域,特别是用于文本检测的卷积神经网络的新型应用技术。
背景技术:
一直以来,文本都在人们的生活中发挥着重要的作用。文本中包含的丰富而精确的信息对基于视觉的应用来说非常重要,比如:图像检索、目标定位、人机交互、机器人导航以及工业自动化等等。自动的文本检测提供了一种获取、利用图片与视频中文本信息的方法,因而成为计算机视觉和文档分析领域的热门研究课题。
在计算机视觉领域,有诸多方法可以用于文本检测。传统的文本检测方法通常是基于纹理和连通域信息的,最常用的方法有笔划宽度变换(swt)、笔划特征变换(sft)和最大稳定极值区域(mser)法。这些方法都是通过人工选择特征,并不能很好地描述文本中的语义信息以适应文本的多样性。例如基于swt的算法对于边缘信息较少的模糊图像效果很差,基于mser的算法无法检测出不是mser区域的文字。另外人工设计的特征会带来大量的参数,这些参数往往需要针对不同的图像做出具体的调整,不具有普适性,算法的鲁棒性较差。而且在一些场景复杂的自然图像上,可能无法区分与文本类似的背景区域,检测效果不理想。与这些人工选择的特征相比,深度学习方法提取到的特征具有很大的优势。
深度学习网络在特征提取方面巨大的优越性使得其在目标检测、图像分类和语义分割上有出色的表现。一些优秀的深度网络,如:alexnet、vggnet、googlenet和resnet都得到了广泛的应用。有效的特征提取网络为目标检测等任务提供了坚实的基础。
基于深度学习的通用目标检测方法可以分为两大类:基于区域的方法和基于回归的方法。前者比如:fast-rcnn、faster-rcnn和r-fcn,这些方法能够获得很高的准确率,但运行速度较慢。后者比如:ssd和yolo,这些方法追求算法的实时性但也能获得尚可的检测结果。在这些方法中,ssd因其速度快、精度高而成为一种广泛应用的高效算法。
目前,有一些基于深度卷积网络的文本检测工作,如:将lstm与faster-rcnn相结合的算法,将rpn与fast-rnn相结合的算法,这些算法检测效果好,但速度较慢。另外,也有基于ssd的文本检测算法,能够在提高速度的同时满足精度要求。
技术实现要素:
本发明解决的技术问题包括:现有公开的训练文本数据库数量不充足的问题,现有技术中因网络参数过多而训练样本太少所产生的过拟合问题,从而准确检测出图像中文本信息。
本发明技术方案为一种快速的自然场景文本检测方法,该方法包括:
步骤1:获取充足的训练文本数据,对获取的训练文本进行人工标定文字的位置和类别,将每一幅训练样本进行图像处理,获得额外的训练样本,对所有的训练样本进行归一化处理;
步骤2:建立一个特征提取网络,根据该特征提取网络提取出各训练样本的高层次语义特征;
步骤3:根据步骤2提取的全局特征,输入检测器,识别出图像中文字的位置;
其特征在于,所述步骤2中包括1个输入模块、第一、二卷积模块、第一至第七共7个卷积网络、1个池化模块、1个反卷积模块、1个级联模块;其中输入模块作为第一卷积模块的输入,第一、二卷积模块、第一至第七卷积网络、池化模块依次级联;额外的第四卷积网络的输出作为反卷积模块的输入,反卷积模块的输出与第三卷积网络的输出共同作为级联模块的输入,所述级联模块是将反卷积模块与第三卷积网络的输出进行级联;所述级联模块、第五、七卷积网络、池化模块的输出作为整个特征提取网路的输出。
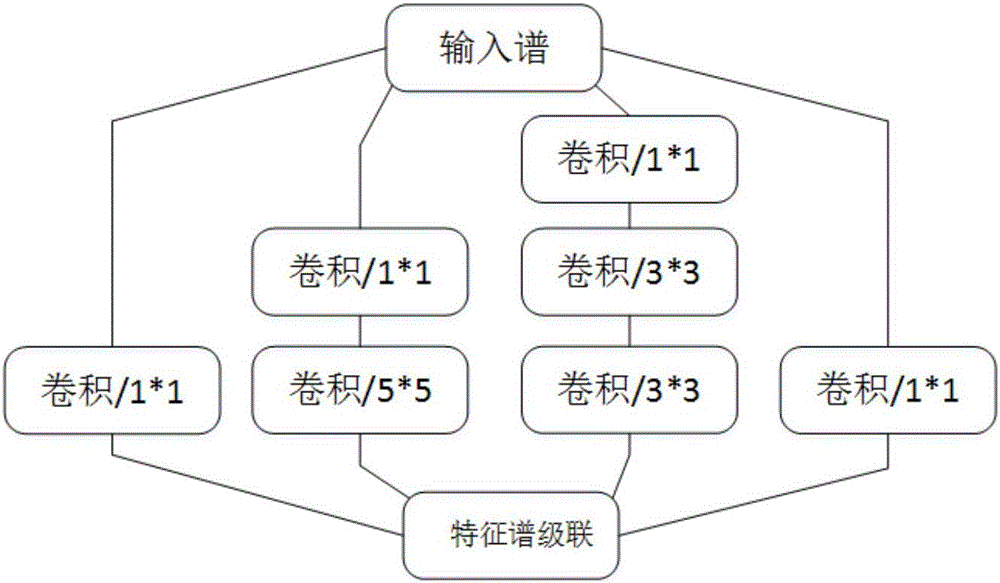
进一步的,所述第一至第七卷积网络包括输入谱端、特征谱级联端,所述输入谱端和特征谱级联端之间通过并联的多条卷积支路连接,每条卷积支路上包括1、2或3个卷积模块。所述卷积网络采用了多条支路并联的结构,不同支路上的卷积模块使用不同大小的卷积核,更好地利用了多尺度的特征信息,使得多尺度信息得以融合,有效提高了提取到的特征质量。
进一步的,所述第一卷积模块的卷积核的大小为3*3、步长为1、填充为1,第二卷积模块的卷积核大小为1*1,步长为1,填充为0。所述第一、二卷积模块位于整个特征提取网络的前端,用于提取底层的边缘特征,选用较小的卷积核能够在更好地提取图像中的细节特征的同时,显著减少网络的参数,加快运行速度。
进一步的,第一卷积网络包括并联的4条卷积支路,第一条卷积支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块;第二条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为5*5,步长为1,填充为2的卷积模块;第三条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,2个卷积核大小为3*3,步长为1,填充为1的卷积模块;第四条卷积支路上包括1个核的大小为3*3,步长为1,填充为1的池化模块,1个卷积核大小为1*1,步长为1,填充为0的卷积模块;
第二、三卷积网络与第一卷积网络的结构相同;
第四卷积网络包括并联的3条卷积支路,第一条卷积支路上包括1个核大小为3*3,步长为2,填充为0的池化模块;第二条支路上包括1个卷积核大小为3*3,步长为2,填充为1的卷积模块;第三条支路上包括1个卷积核大小为1*1,步长为1,填充为1的卷积模块,1个卷积核大小为3*3,步长为2,填充为0的卷积模块;
第五卷积网络包括并联的4条卷积支路,第一条卷积支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块;第二条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为7*1,步长为1,横向填充为3的卷积模块,1个卷积核大小为1*7,步长为1,纵向填充为3的卷积模块;第三条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,2个卷积核大小为7*1,步长为1,横向填充为3的卷积模块;第四条卷积支路上包括1个核的大小为3*3,步长为1,填充为1的池化模块,1个卷积核大小为1*1,步长为1,填充为0的卷积模块;
第六卷积网络包括并联的3条卷积支路,第一条卷积支路上包括1个核大小为3*3,步长为2,填充为0的池化模块;第二条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为3*3,步长为2,填充为0的卷积模块;第三条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为7*1,步长为1,横向填充为3的卷积模块,1个卷积核大小为3*3,步长为2,填充为0的卷积模块;
第七卷积网络包括并联的4条卷积支路,第一条卷积支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为3*1,步长为1,横向填充为1的卷积模块;第二条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为1*3,步长为1,纵向填充为1的卷积模块;第三条支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为3*3,步长为1,填充为1的卷积模块,1个卷积核大小为3*1,步长为1,横向填充为1的卷积模块;第四条卷积支路上包括1个卷积核大小为1*1,步长为1,填充为0的卷积模块,1个卷积核大小为3*3,步长为1,填充为1的卷积模块,1个卷积核大小为1*3,步长为1,纵向填充为1的卷积模块。
所述第一至第七卷积网络均采用多条卷积支路并联的结构,采用多种尺度和形状的卷积核,能够针对不同尺度和形状的的文本目标进行特征提取。
本文提出一个快速的特征提取小网络,使用inception模块,采用小卷积核,减少参数,缩小网络,加快运行速度。添加一个反卷积层用于融合多尺度信息,提高检测精度。检测阶段采用基于ssd的检测框架,对预置框的宽高比例进行改进,采用了适应文本特征的比例。本发明提出的方法在公开数据集上进行测试,验证了方法的有效性和实时性。
附图说明
图1为本发明网络结构图;
图2为inception结构示意图;
图3为本发明的检测结果图。
具体实施方式
首先,集合了几个公开数据库——icdar2013、hust-tr400、svt中的训练数据,得到约800张训练图片,拍摄以及从网络上搜集到不同背景、光照、字体的图像样本约2000张。之后对2916张训练样本进行人工标注。在权威的公开数据库icdar2013测试集上进行的。在训练时将样本的大小归一化到448*448。
本发明主要可以分为卷积神经网络的学习和测试两个部分,全部工作可以分为以下5个步骤:
步骤一、特征提取网络预训练:在imagenet数据库上对设计的特征提取小网络进行预训练。由于网络参数较多而样本较少,为了避免过拟合,在训练时随机地将图像从300*300裁剪到224*224,用以网络训练,以增加样本数。设置初始学习率为0.1,每迭代2*105次学习率乘以0.1。按照0.3的丢失率随机丢弃30%的参数。
步骤二、构建文本检测数据库并进行标注:首先针对提出的问题,建立一个包含不同光照、背景、字体的自然场景文本的数据库,包含2916张训练样本和233张测试样本,这些图像样本部分取自公开的数据库,部分来自于拍摄以及网络上的收集。所有的图像大小都归一化到448*448。
步骤三、对数据库中的未标注图像进行人工标注文本的groundtruth,通过画框同时标注出目标位置(左上角坐标和宽高)和类别标签,在这里,目标只有一类,即文本。
步骤四、训练文本检测网络:将文本检测网络在步骤二提出的数据库上进行微调训练。该步骤包括以下几个关键点:
1.设置6种不同宽高比的预置框,分别为:1,2,3,5,7,和10。修改检测类别数为2(文本标签为1,背景为0)。
2.检测层的卷积核大小设置为宽为5,高为1,以适应文本特征。
3.设置初始学习率为0.0001,每迭代2*104次学习率乘以0.1。在该过程中使用随机梯度下降法优化公式(1)中定义的能量损失函数,最终得到深度网络模型。
步骤五、对学习好的模型进行测试:该步骤中,将归一化的测试图像输入网络模型中,网络输出为文本目标的位置和文本的置信度打分,部分测试结果如图3所示;
在icdar数据集上进行测试,对比fasttextboxes、ssd和本文方法的准确率、召回率和运行时间,得到如下表所示的结果:
对比结果表明,在准确率和召回率相当的情况下,本文提出的网络能够显著加快运行速度。
- 还没有人留言评论。精彩留言会获得点赞!