融合红外可见光的特高压线路绝缘子串深度学习识别方法与流程
本发明涉及一种绝缘串子提取方法,尤其是涉及一种融合红外可见光的特高压线路绝缘子串深度学习识别方法。
背景技术:
特高压输电线路有效配置了区域电网间能源的同时,也带来了新的运维难题:特高压输电线路多为高杆塔架设,地面巡检人员很难发现高杆塔上螺栓脱落等销钉级缺陷;在使用无人机进行抵近杆塔巡检,无人机拍摄大量的视频和照片数据,如果完全采用人工对无人机采集数据进行检查识别缺陷存在效率低的难题。在采用卷积神经网络算法对无人机采集数据进行自动识别特高压线路绝缘子串的同时又遇到无人机采集数据背景复杂的问题,为此本专利通过对无人机红外可见光融合图像进行处理,针对带电状态下特高压线路绝缘子串特征有别于背景中其他干扰,有效的从融合图像中的提取出带电状态下特高压线路绝缘子串的可见光下图片信息。
随着无人机(uav)在电力巡线作业中的应用推广,对无人机巡检图像的信息挖掘或目标识别需求也越来越强烈。传统的电力部件识别流程常使用经典的机器学习算法,如支持向量机(svm)、随机森林或adaboost,结合梯度、颜色或纹理等浅层特征来对电力部件进行识别,难以充分利用无人机巡检图像的信息,并且难以达到较高的准确率。卷积神经网络(cnn)在目标识别中表现优异,在很多目标识别场景之中成为首选算法。基于区域的卷积神经网络(rcnn)通过使用cnn从图像中提取可能含有目标的区域来检测并识别目标,但是计算复杂,难以满足识别海量电力巡检图片的需求。fastr-cnn和fasterr-cnn利用cnn网络提取图像特征,后接一个区域提议层,优化了提取可能含有目标区域的方式并改进识别目标的分类器,使目标的检测和识别几乎实时。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种融合红外可见光的特高压线路绝缘子串深度学习识别方法。
本发明的目的可以通过以下技术方案来实现:
一种融合红外可见光的特高压线路绝缘子串深度学习识别方法,包括:
对待识别物体的可见光图像进行yuv编码,并得到可见光图像的y分量、u分量和v分量;
将可见光图像的y分量和红外图像进行融合处理后得到融合后,将之结合可见光图像的u分量和v分量得到融合图像;
使用训练好的faster-rcnn模型对融合图像进行检测,提取出待识别物体中的绝缘子串。
所述对待识别物体的可见光图像进行yuv编码具体包括:
采用仿射变换对可见光图像进行配准;
将配准后图像转换到yuv空间。
可见光图像的y分量和红外图像的融合处理过程采用小波融合方法。
可见光图像的y分量和红外图像进行融合处理具体为:
y'=w1×y+w2×ir
其中:y为可见光图像的y分量,ir为红外图像,w1为可见光图像的权重,w2为红外图像的权重,y'为融合后的y分量。
所述可见光图像的权重和红外图像的权重均为0.5.
所述faster-rcnn模型包括rpn卷积神经网络和fast-rcnn卷积神经网络。
所述使用训练好的faster-rcnn模型对融合图像进行检测,提取出待识别物体中的绝缘子串,包括:
利用rpn卷积神经网络从融合图像中识别出绝缘子串的候选区域;
利用fast-rcnn卷积神经网络从绝缘子串的候选区域识别出绝缘子串。
与现有技术相比,本发明具有以下优点:
1)在无人机电力线巡检的红外可见光融合图像部件检测中使用fasterr-cnn算法流程,进行多种类别的电力小部件识别定位可以达到每张近80ms的识别速度和92.7%的准确率。
2)可见光图像的权重和红外图像的权重均为0.5时图像信息量最大,效果较好。
3)通过与yuv彩色空间变换、小波变换融合方法所得到的融合图像比较,结果表明,本发明采用的图像融合方法获得的图像清晰度有较大改善,从而构建绝缘子样本库。
附图说明
图1为本发明方法的主要步骤流程示意图;
图2为rpn卷积神经网络的结构示意图;
图3为faster-rcnn模型的整体模型结构示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
一种融合红外可见光的特高压线路绝缘子串深度学习识别方法,如图1所示,包括:
对待识别物体的可见光图像进行yuv编码,并得到可见光图像的y分量、u分量和v分量,
在yuv彩色空间中,每一个颜色有一个亮度信号分量y,和两个色度信号分量u和v。亮度是强度的感觉,它和色度是分离的,如果只有y信号分量而没有u、v分量,那么这样表示的图像就是黑白灰度图像。强度改变就可以不影响颜色改变。将这三个分量组合就可以产生一个全彩色图像。
对待识别物体的可见光图像进行yuv编码具体包括:
采用仿射变换对可见光图像进行配准;
将配准后图像转换到yuv空间。
将可见光图像的y分量和红外图像进行融合处理后得到融合后,将之结合可见光图像的u分量和v分量得到融合图像;
可见光图像的y分量和红外图像的融合处理过程采用小波融合方法。
可见光图像的y分量和红外图像进行融合处理具体为:
y'=w1×y+w2×ir
其中:y为可见光图像的y分量,ir为红外图像,w1为可见光图像的权重,w2为红外图像的权重,y'为融合后的y分量。
可见光图像的权重一般选取0.1~0.9,红外图像的权重和可见光图像的权重之和为1,优选的,可见光图像的权重和红外图像的权重均为0.5,此时图像信息量最大,效果较好。
使用训练好的faster-rcnn模型对融合图像进行检测,提取出待识别物体中的绝缘子串。faster-rcnn模型包括rpn卷积神经网络和fast-rcnn卷积神经网络。
使用训练好的faster-rcnn模型对融合图像进行检测,提取出待识别物体中的绝缘子串,包括:
利用rpn卷积神经网络从融合图像中识别出绝缘子串的候选区域;
利用fast-rcnn卷积神经网络从绝缘子串的候选区域识别出绝缘子串。
此外,构建fasterrcnn模型的网络结构;分别训练一个rpn卷积神经网络和一个fast-rcnn卷积神经网络,(a)采用训练好的rpn网络处理样本,得到绝缘子粗候选区域。(b)将粗候选区域送入训练好的fast-rcnn网络做判别,依据输出向量判断候选区域是否是最优绝缘子区域,并最终识别出绝缘子串。
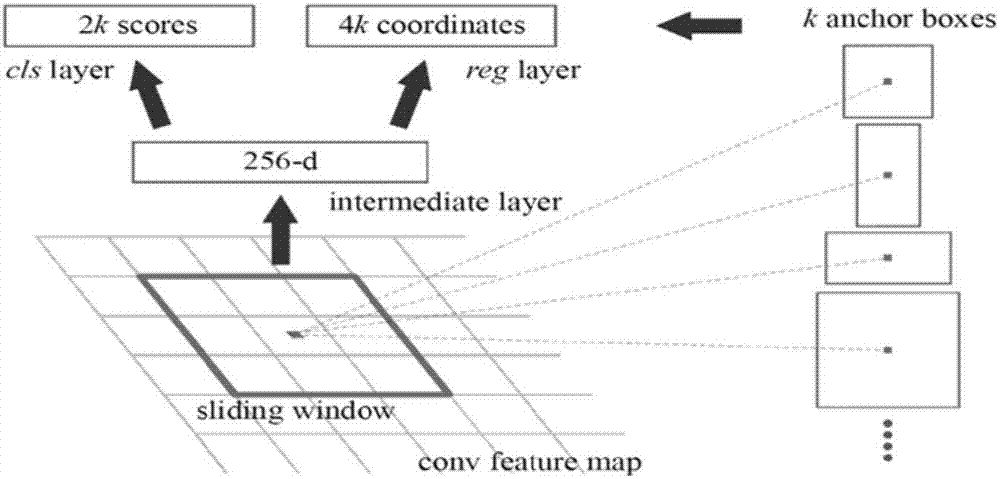
faster-rcnn模型的基本结构仍然是卷积神经网络,通过在卷积神经网络最后一层特征图后添加一个叫做rpn(regionproposalnetwork)的网络来实现该部分功能,rpn结构如图2所示。rpn网络以特征图上的每个点为中心,使用不同面积和长宽比的滑动窗口来采集特征图特定区域内的特征。rpn通过一个滑动窗口(图中红色框)连接在最后一个卷积层输出的特征映射上,然后通过全连接层调整到256-d的向量,作为输出层的输入。同时每个滑动窗对应k个anchorboxes,在本方法中使用3个尺寸和3个比例的3*3=9个anchor。每个anchor对应原图上一个感受野,通过这种方法提高尺度不变性。
faster-rcnn模型的整体模型结构如图3所示,通过调整网络结构,经过分阶段的训练,把整个目标检测识别流程全部整合到了神经网络中。模型的输入为原始图像,经过多层卷积得到特征图后,由rpn网络和全连接网络分别完成目标的检测和识别功能。模型的训练过程分为4步:
1)使用预训练的cnn模型初始化网络参数,训练rpn网络;
2)使用第一步中产生的roi区域训练fastrcnn分类网络;
3)固定卷积层参数,调整rpn参数;
4)固定卷积层参数,调整全连接层参数。
本申请针对复杂背景条件下的绝缘子区域的提取算法的设计,由于绝缘子图像颜色特征易于周围环境融为一体,对在可见光下的正确分割带来较大的难度,而红外图像对温度较为敏感,绝缘子的温度一般高于周围环境,因此从红外图像入手,融合可见光图像,能较好的除去复杂背景,提高fasterrcnn算法检测效率,且rpn和fast-rcnn通过共享卷积层参数,是系统更加简单,计算量小,漏检率低,满足系统实时性要求。
- 还没有人留言评论。精彩留言会获得点赞!