一种基于潜在主题的相似企业推荐方法与流程
本发明涉及推荐方法技术领域,尤其涉及一种基于潜在主题的相似企业推荐方法。
背景技术:
随着互联网技术的迅猛发展,互联网上的信息呈指数级爆炸增长趋势,一方面为我们获取信息提供了丰富的资源,同时也增大了获取准确有用信息的难度。为解决此信息过载的问题,提出了各种技术解决方案。
首先,当互联网用户有明确的信息获取需求时,搜索引擎能够根据用户提供的关键字,返回用户的问题的答案或解决方案,是用户主动获取信息的过程。
但是,当用户的信息获取需求不明确,用户无法提供给搜索引擎准备的关键字集合,搜索的方法已无法解决这种场景;同时互联网上巨大的信息资源无法到达可能的用户,是一种资源浪费,推荐相关技术是针对这种场景的一种解决方案。
利用群体智慧,协同过滤是一种行之有效的推荐方法,在视频、购物等推荐领域都有广泛的应用。协同过滤又可以分为基于item的协同过滤和基于用户的协同过滤,这两种方法的共同点都是利用用户对物品的行为,例如对视频的点击行为和对商品的购买行为来衡量物品之间的相似性,进而推荐相似相关的物品,尽管应用广泛,这种方法也有其缺点,基于item的协同过滤,倾向于推荐热门的物品,不利于解决长尾的物品;而基于用户的协同过滤,在用户的行为较少时推荐的物品的效果较差。
基于内容的推荐方法,是为物品打tag,然后基于tag的相似性,推荐相似物品。例如,音乐网站pandora就是采用的这样的推荐方法,请音乐领域的专业人士为歌曲在预先设定的维度打上对应的tag,再基于tag推荐相似的歌曲。这样的推荐方法准确度很高。不过,这样方法的缺点也很明显,打tag的过程代价极大,需要大量的专业人士,而且在打tag的过程中,很容易引入人员的偏见,不同的人的认知总会有各种各样的不同。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种基于潜在主题的相似企业推荐方法。
本发明通过以下技术方案来实现上述目的:
本发明包括以下步骤:
步骤一,输入企业信息,预处理企业各字段的信息,输入的企业信息主要包括企业的名称信息、企业的经营范围信息、企业的注册资本多少、企业的成立日期信息、企业所在的省市信息等,对输入的原始字段信息转化为统一的结构化信息,便于后续的相似性计算过程;
步骤二,采用狄利克雷分布,计算企业的潜在主题分布特征向量,主要利用企业的名称信息和企业的经营范围信息的文本信息来计算企业的潜在主题分布特征向量;
步骤三、计算企业的相似企业的候选集合,限定企业的区域范围和行业范围,同时降低不必要的计算开销;
步骤四、计算企业与候选企业的相似得分;以企业的潜在主题相似性的为主,辅以企业的注册资本、成立时间、省市信息等计算获取企业的相似性得分;潜在主题相似性采用欧氏距离度量,不同的维度采用线性加权求和;
步骤五、按照相似性得分从高到低排序相似企业,返回推荐结果列表。
本发明优选的,根据步骤二,所述计算企业的潜在主题分布的特征向量,具体包括如下步骤:
步骤a、获取全部企业的经营范围字段;
步骤b、对企业的经营范围字段预处理,主要包括:全角转换为半角,符号转换为统一的格式方便后续处理;过滤去特征标记符号及其中的文字,这样的符号中一般为常见的套语,对模型的训练有害无益,还有像‘一般经营项目’、‘许可经营项目’等这样的高频出现的字段需要过滤去;
步骤c、对预处理后的经营范围字段分词;
步骤d、集合所有的分词形成潜在主题的词表,保留分词长度大于一定阈值的分词,这样的词才有意义;保留分词的频率大于一定阈值的分词,是为提高模型训练的速度;
步骤e、输入所有的训练企业的数据,根据词表计算训练数据的样本特征向量;
步骤f、设置隐狄利克雷分布的参数,包括主题数目、迭代次数、随机初始状态;这些参数和词表信息一样对模型的最终效果都很重要;
步骤g、在模型参数设置完成、训练样本特征向量获取完成后,开始训练隐狄利克雷分布模型;
步骤h、输入测试企业的样本数据,根据模型词表计算测试企业的样本的特征向量;
步骤i、根据生成的隐狄利克雷分布模型和测试企业的样本向量信息计算测试企业的样本的潜在主题分布向量;
步骤j、输出企业的潜在主题分布向量。
本发明优选的,根据步骤四,包括以下步骤:
步骤a、计算企业间的潜在主题相似性,采用欧氏距离度量;
步骤b、计算企业间的资本相似性,将企业的注册资本统一转化为人民币尺度,计算企业资本差额的指数相似性;
步骤c、计算企业间的成立时间相似性,计算企业的成立时间差的指数相似性;
步骤d、计算企业间的省市相似性,同省和同市信息赋予一定的梯度相似性;
步骤e、采用线性加权平均计算企业间的最终的相似性得分,公式如下:w1*x1+w2*x2+w3*x3+w4*x4,(w1+w2+w3+w4=1)。
本发明的有益效果在于:
本发明提供一种基于潜在主题的相似企业推荐方法,针对相似企业的推荐的应用场景,采用了潜在主题相似的方法,由于每条企业数据,都有一定数量的文本特征,避免了协同过滤方法仅依靠用户行为的不足,也不用像tag方法那样需要大量的人力参与,而且这种方法还增加了相似文本之间的相似来计算主题间的相似,进而通过主题相似推荐相似的企业。
附图说明
图1是本发明所述基于潜在主题的相似企业推荐方法的流程结构示意图;
图2是本发明所述相似企业的推荐的流程结构示意图。
具体实施方式
下面结合附图对本发明作进一步说明:
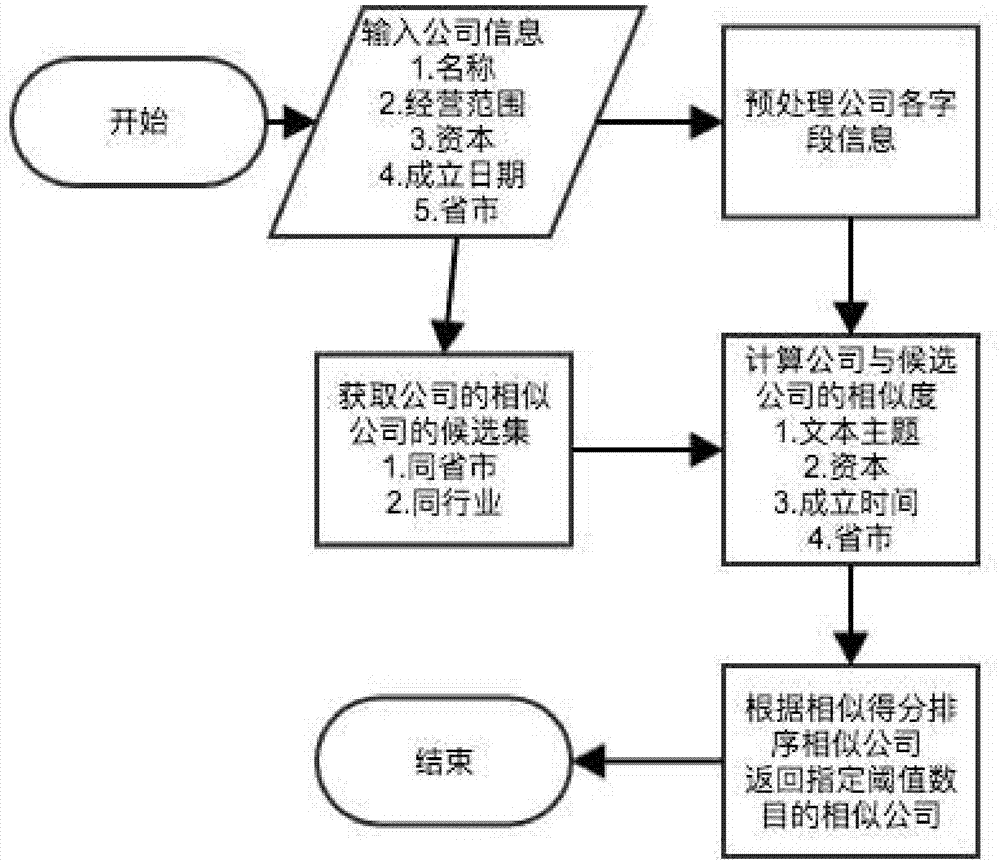
如图1所示:本发明包括以下步骤:
步骤一,输入企业信息,预处理企业各字段的信息,输入的企业信息主要包括企业的名称信息、企业的经营范围信息、企业的注册资本多少、企业的成立日期信息、企业所在的省市信息等,对输入的原始字段信息转化为统一的结构化信息,便于后续的相似性计算过程;
步骤二,采用狄利克雷分布,计算企业的潜在主题分布特征向量,主要利用企业的名称信息和企业的经营范围信息的文本信息来计算企业的潜在主题分布特征向量;
步骤三、计算企业的相似企业的候选集合,限定企业的区域范围和行业范围,同时降低不必要的计算开销;
步骤四、计算企业与候选企业的相似得分;以企业的潜在主题相似性的为主,辅以企业的注册资本、成立时间、省市信息等计算获取企业的相似性得分;潜在主题相似性采用欧氏距离度量,不同的维度采用线性加权求和;
步骤五、按照相似性得分从高到低排序相似企业,返回推荐结果列表。
根据步骤二,所述计算企业的潜在主题分布的特征向量,具体包括如下步骤:
步骤a、获取全部企业的经营范围字段;
步骤b、对企业的经营范围字段预处理,主要包括:全角转换为半角,符号转换为统一的格式方便后续处理;过滤去特征标记符号及其中的文字,这样的符号中一般为常见的套语,对模型的训练有害无益,还有像‘一般经营项目’、‘许可经营项目’等这样的高频出现的字段需要过滤去;
步骤c、对预处理后的经营范围字段分词;
步骤d、集合所有的分词形成潜在主题的词表,保留分词长度大于一定阈值的分词,这样的词才有意义;保留分词的频率大于一定阈值的分词,是为提高模型训练的速度;
步骤e、输入所有的训练企业的数据,根据词表计算训练数据的样本特征向量;
步骤f、设置隐狄利克雷分布的参数,包括主题数目、迭代次数、随机初始状态;这些参数和词表信息一样对模型的最终效果都很重要;
步骤g、在模型参数设置完成、训练样本特征向量获取完成后,开始训练隐狄利克雷分布模型;
步骤h、输入测试企业的样本数据,根据模型词表计算测试企业的样本的特征向量;
步骤i、根据生成的隐狄利克雷分布模型和测试企业的样本向量信息计算测试企业的样本的潜在主题分布向量;
步骤j、输出企业的潜在主题分布向量。
如图2所示,根据步骤四,包括以下步骤:
步骤a、计算企业间的潜在主题相似性,采用欧氏距离度量;
步骤b、计算企业间的资本相似性,将企业的注册资本统一转化为人民币尺度,计算企业资本差额的指数相似性;
步骤c、计算企业间的成立时间相似性,计算企业的成立时间差的指数相似性;
步骤d、计算企业间的省市相似性,同省和同市信息赋予一定的梯度相似性;
步骤e、采用线性加权平均计算企业间的最终的相似性得分,公式如下:w1*x1+w2*x2+w3*x3+w4*x4,(w1+w2+w3+w4=1)。
实施例一:
基于潜在主题的相似企业推荐的步骤如下:
输入企业信息,预处理企业各字段的信息,输入的企业信息主要包括企业的名称信息、企业的经营范围信息、企业的注册资本多少、企业的成立日期信息、企业所在的省市信息等。企业的名称中一般会有股份有限公司、有限公司、有限责任公司、股份公司、公司和城市名称信息,这些信息不能将公司区分开,特征没有判别能力,过滤去;企业的经营范围字段一般包含一般经营项目、许可经营项目、【*】、(*)、[*]字段,同公司名称字段类似,需要把这些字段过滤去,另外公司的经营范围字段的符号不统一,全角半角混杂,预处理统一转化为半角。企业的注册资本字段的也存在多种写法,有美元、xx万、xx人民币等,需要转化为统一标准。对输入的原始字段信息转化为统一的结构化信息,便于后续的相似性计算过程。
采用狄利克雷分布,计算企业的潜在主题分布特征向量;主要利用企业的名称信息和企业的经营范围信息的文本信息来计算企业的潜在主题分布特征向量。
计算企业的相似企业的候选集合,限定企业的区域范围和行业范围,同时降低不必要的计算开销。
计算企业与候选企业的相似得分;以企业的潜在主题相似性的为主,辅以企业的注册资本、成立时间、省市信息等计算获取企业的相似性得分;潜在主题相似性采用欧氏距离度量,不同的维度采用线性加权求和。
按照相似性得分从高到低排序相似企业,返回推荐结果列表
上述步骤中的第二步,计算企业的潜在主题分布的特征向量,具体可以分为如下步骤:
构建生成潜在主题的词表,企业的名称和经营范围字段包含有文本信息,由于企业名称会包含生僻、歧义的词,只使用企业的经营范围字段构建词表。首先,获取全部企业的经营范围字段。
对企业的经营范围字段预处理,主要包括:全角转换为半角,符号转换为统一的格式方便后续处理;过滤去特征标记符号及其中的文字,如【】、()等,这样的符号中一般为常见的套语,对模型的训练有害无益,还有像‘一般经营项目’、‘许可经营项目’等这样的高频出现的字段需要过滤去。
对预处理后的经营范围字段分词
集合所有的分词形成潜在主题的词表,保留分词长度大于一定阈值的分词,这样的词才有意义;保留分词的频率大于一定阈值的分词,是为提高模型训练的速度。
输入所有的训练企业的数据,根据词表计算训练数据的样本特征向量。使用企业的名称和经营范围字段的文本信息
设置隐狄利克雷分布的参数,如,主题数目、迭代次数、随机初始状态;这些参数和词表信息一样对模型的最终效果都很重要。
在模型参数设置完成、训练样本特征向量获取完成后,开始训练隐狄利克雷分布模型。
输入测试企业的样本数据,根据模型词表计算测试企业的样本的特征向量。
根据生成的隐狄利克雷分布模型和测试企业的样本向量信息计算测试企业的样本的潜在主题分布向量。
输出企业的潜在主题分布向量。
上述步骤中的第四步,具体可以分为如下步骤:
计算企业间的潜在主题相似性,采用欧氏距离度量。
计算企业间的资本相似性,将企业的注册资本统一转化为人民币尺度,计算企业资本差额的指数相似性。
计算企业间的成立时间相似性,计算企业的成立时间差的指数相似性。
计算企业间的省市相似性,同省和同市信息赋予一定的梯度相似性。
采用线性加权平均计算企业间的最终的相似性得分,公式如下:w1*x1+w2*x2+w3*x3+w4*x4,(w1+w2+w3+w4=1)。
综上所述,本发明提供一种基于潜在主题的相似企业推荐方法,针对相似企业的推荐的应用场景,采用了潜在主题相似的方法,由于每条企业数据,都有一定数量的文本特征,避免了协同过滤方法仅依靠用户行为的不足,也不用像tag方法那样需要大量的人力参与,而且这种方法还增加了相似文本之间的相似来计算主题间的相似,进而通过主题相似推荐相似的企业。
本领域技术人员不脱离本发明的实质和精神,可以有多种变形方案实现本发明,以上所述仅为本发明较佳可行的实施例而已,并非因此局限本发明的权利范围,凡运用本发明说明书及附图内容所作的等效结构变化,均包含于本发明的权利范围之内。
- 还没有人留言评论。精彩留言会获得点赞!