一种自然语言的识别方法及系统与流程
本发明涉及自然语言处理、搜索引擎、智能机器人等领域,特别涉及一种自然语言的识别方法及系统。
背景技术:
中文分词算法应用大概分为三大类:第一类是基于字符串匹配,即扫描字符串,如果发现字符串的子串和词典中的词相同,就算匹配,比如机械分词方法。这类分词通常会加入一些启发式规则,比如“正向/反向最大匹配”、“长词优先”等;第二类是基于统计以及机器学习的分词方法,它们基于人工标注的词性和统计特征,对中文进行建模,即根据观测到的数据(标注好的语料)对模型参数进行训练,在分词阶段再通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。常见的序列标注模型有hmm和crf。这类分词算法能很好处理歧义和未登录词问题,效果比前一类效果好,但是需要大量的人工标注数据,以及较慢的分词速度;第三类是通过让计算机模拟人对句子的理解,达到识别词的效果,由于汉语语义的复杂性,难以将各种语言信息组织成机器能够识别的形式,目前这种分词系统还处于试验阶段。
现有的中文分词算法,多是堆砌罗列,如“分词1+分词2+分词3+分词......”,来对自然语言进行匹配,帮助计算机识别语义。
现有的中文分词算法存在以下缺点:
1、一条条罗列分词组合耗时耗力;
2、组合一条条相对分散,知识点缺乏系统整合;
3、分词的匹配规则,一条条修改增减不方便。
技术实现要素:
为了克服现有的中文分词算法中分词组合耗时耗力、知识点缺乏系统整合和修改不方便的缺点,本发明提供了一种知识矩阵分词系统,该系统不仅对分词进行结构化处理,使得省时省力、便于修改,而且用主题分词设定语义环境,全面梳理相关的各类情况,将知识点体系化,减少分词组合错漏情况,从而提高自然语言识别处理能力。
为实现上述目的,一方面,本发明提供了一种自然语言的识别方法,该方法包括以下步骤:对获取的自然语言进行划分,确定第一分词、第二分词和第三分词;根据第一分词、第二分词和第三分词与预先建立的三维矩阵进行匹配,确定并调用相应的匹配规则,从而实现自然语言的识别;所述三维矩阵包括矩阵名称、第一分词、第二分词、第三分词及匹配规则,其中第一分词设为主题分词,第二分词设为x轴分词,第三分词设为y轴分词,所述x轴分词与所述y轴分词交叉产生各种分词组合。
优选地,三维矩阵只有一个主题分词作为分词参与语义识别匹配,所述主题分词为三维矩阵使用的环境、核心分词。
优选地,当所述自然语言同时包含第一分词、第二分词和第三分词时,则调用对应的匹配规则。
另一方面,本发明提供了一种自然语言的识别系统,该系统包括:
划分模块,用于对获取的自然语言进行划分,确定第一分词、第二分词和第三分词;
识别模块,用于根据第一分词、第二分词和第三分词与预先建立的三维矩阵进行匹配,确定并调用相应的匹配规则,从而实现自然语言的识别;所述三维矩阵包括矩阵名称、第一分词、第二分词、第三分词及匹配规则,其中第一分词设为主题分词,第二分词设为x轴分词,第三分词设为y轴分词,所述x轴分词与所述y轴分词交叉产生各种分词组合,则调用对应的匹配规则。
优选地,三维矩阵只有一个主题分词作为分词参与语义识别匹配,所述主题分词为三维矩阵使用的环境、核心分词。
优选地,当所述自然语言同时包含第一分词、第二分词和第三分词时,则调用对应的匹配规则。
本发明通过将分词进行结构化处理,x轴分词与y轴分词交叉产生各种分词组合,省时省力;三维矩阵用主题分词设定语义环境,全面梳理相关的各类情况,将知识点体系化,减少分词组合错漏情况;三维矩阵简洁直观,具有可视化易修改特点,通过x轴分词与y轴分词的增减,调整匹配规则及内容。
附图说明
图1是本发明实施例提供的一种自然语言的识别方法流程示意图;
图2是本发明实施例提供的一种自然语言的识别系统结构框图。
具体实施方式
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
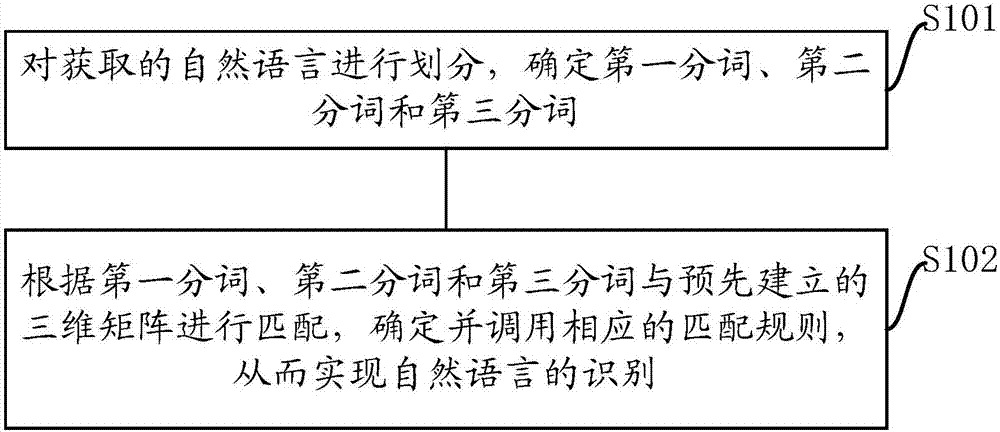
图1是本发明实施例提供的一种自然语言的识别方法流程示意图。如图1所示,访识别方法包括步骤s101-s102:
步骤s101,对获取的自然语言进行划分,确定第一分词、第二分词和第三分词。
自然语言可以是一句中文,例如“股小量,你和女朋友关系好不好?”,第一分词可以设置为主题分词,第二分词可以设置为x轴分词,第三分词可以设置为y轴分词;其中,x轴分词和y轴分词作为分词参与语义识别匹配。
步骤s102,根据第一分词、第二分词和第三分词与预先建立的三维矩阵进行匹配,确定并调用相应的匹配规则,从而实现自然语言的识别;所述三维矩阵包括矩阵名称、第一分词、第二分词、第三分词及匹配规则,其中第一分词设为主题分词,第二分词设为x轴,第三分词设为y轴,所述x轴分词与所述y轴分词交叉产生各种分词组合。
具体地,三维矩阵(如表1所示)包括矩阵名称a、主题分词t、x轴分词(x1,x2,x3,x4,x5,...)、y轴分词(y1,y2,y3,y4,y5,...)及匹配规则gij等内容组成,x轴分词和y轴分词交叉产生各种分词组合。其中,知识矩阵名称a不作为分词匹配;主题分词t,每个三维矩阵有且只有一个主题分词,一般是知识矩阵使用的环境、核心分词等,作为分词参与语义识别匹配;x轴分词,一组分词(x1,x2,x3,x4,x5,...),作为分词参与语义识别匹配;y轴分词,一组分词(y1,y2,y3,y4,y5,...),作为分词参与语义识别匹配;匹配规则gij,调用的规则内容,当一句话(中文自然语言)同时包含分词t、x、y时,调用对应的规则gij来匹配,辅助智能机器人学习训练。
表1
在一个例子中,预设的三维矩阵如表2所示,获取的一句中文为:
问:股小量(主题分词t),和你女朋友(分词x)关系(分词y)好不好?
答:小冰是个骂人狂,学了几亿句骂人的话!不像本尊,玉树临风,带股民赚钱!(规则gij)
表2
图2是本发明实施例提供的一种自然语言的识别系统结构框图。如图2所示,该自然语言的识别系统,包括划分模块210和识别模块220:
划分模块210,用于对获取的自然语言进行划分,确定第一分词、第二分词和第三分词。
识别模块220,用于根据第一分词、第二分词和第三分词与预先建立的三维矩阵进行匹配,确定并调用相应的匹配规则,从而实现自然语言的识别;所述三维矩阵包括矩阵名称、第一分词、第二分词、第三分词及匹配规则,其中第一分词设为主题分词,第二分词设为x轴分词,第三分词设为y轴分词,所述x轴分词与所述y轴分词交叉产生各种分词组合,则调用对应的匹配规则。三维矩阵只有一个主题分词作为分词参与语义识别匹配,所述主题分词为三维矩阵使用的环境、核心分词。当所述自然语言同时包含第一分词、第二分词和第三分词时,则调用对应的匹配规则。
本发明实施例不仅可以对分词进行结构化处理,使得省时省力、便于修改,而且用主题分词设定语义环境,全面梳理相关的各类情况,将知识点体系化,减少分词组合错漏情况,从而提高自然语言识别处理能力。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!