神经网络计算装置及包含该计算装置的处理器的制作方法
本发明涉及人工智能技术领域,尤其涉及一种神经网络的计算装置以及包含该计算装置的神经网络处理器。
背景技术:
深度学习是机器学习领域的重要分支,在近些年来取得了重大突破。采用深度学习算法训练的神经网络模型在图像识别、语音处理、智能机器人等应用领域取得了令人瞩目的成果。
深度神经网络通过建立模型模拟人类大脑的神经连接结构,在处理图像、声音和文本等信号时,通过多个变换阶段分层对数据特征进行描述。随着神经网络复杂度的不断提高,神经网络技术在实际应用过程中存在占用资源多、运算速度慢、能量消耗大等问题,因此该技术在嵌入式设备或低开销数据中心等领域应用时存在严重的能效问题和运算速度瓶颈。采用硬件加速器替代传统软件计算的方法成为了提高神经网络计算效率的一种行之有效方式。目前主流的硬件加速方式包括通用图形处理器、专用处理器芯片和现场可编程逻辑阵列(fpga)等。
然而,由于神经网络处理器属于计算密集型和访存密集型处理器,一方面,神经网络模型中包括大量乘法加法运算及其他非线性运算,需要神经网络处理器保持高负载运行,以保障神经网络模型的运算需求;另一方面,神经网络运算过程中存在大量的参数迭代,计算单元需要对存储器进行大量访问,这极大增加了对处理器的带宽设计需求,同时增加了访存功耗。
因此,需要对现有的神经网络处理器进行改进,以解决计算电路硬件开销高、片上访存带宽大的问题。
技术实现要素:
本发明的目的在于克服上述现有技术的缺陷,提供一种应用于神经网络的计算装置以及包含该计算装置的处理器。
根据本发明的第一方面,提供了一种神经网络计算装置。该计算装置包括脉动阵列处理单元和主处理器,所述主处理器用于控制神经网络中的计算元素向所述脉动阵列处理单元的装载以及在所述脉动阵列处理单元中的传递,所述脉动阵列处理单元由多个处理单元构成,每个处理单元对接收的计算元素执行相关运算和/或将接收到的计算元素传递给下一个处理单元,其中,所述计算元素包括神经元数据和对应的权重值。
在本发明的一个实施例中,所述脉动阵列处理单元包括采用一维矩阵形式串接的多个处理单元。
在本发明的一个实施例中,所述主处理器控制所述神经元数据向所述脉动阵列处理单元的装载和流动并控制所述对应的权重值预先存储在所述脉动阵列处理单元的相应处理单元中。
在本发明的一个实施例中,所述脉动阵列处理单元采用二维矩阵形式,其中,各处理单元采用相同的结构,每个处理单元仅与相邻的处理单元耦合。
在本发明的一个实施例中,所述主处理器控制所述神经元数据从二维矩阵的行方向装载并沿行方向流动,并且控制所述对应的权重值从二维矩阵的列方向装载并沿列方向流动。
在本发明的一个实施例中,各处理单元包括:
数据旁路单元:其第一端用于接收入所述神经元数据并将其输出给乘法器,第二端用于将接收到的所述神经元数据直接输出;
权重旁路单元:其第一端用于接入接收所述权重值并将其输出给乘法器,第二端用于将接收到的所述权重值直接输出;
乘法器:用于从所述数据旁路单元接收神经元数据以及从所述权重旁路单元接收权重值并执行乘法运算;
累加器:用于累加来自于所述乘法器的输出并将累加结果从该处理单元输出。
在本发明的计算装置中,还包括数据寄存器,其用于存储所述数据旁路单元接收的神经元数据。
在本发明的计算装置中,还包括权重寄存器,其用于存储所述权重旁路单元接收的权重值。
在本发明的计算装置中,所述主处理器还用于根据相关运算的特点和计算单元的资源使用情况决定是否由所述脉动阵列处理单元执行当前的运算。
根据本发明的第二方面,提供了一种神经网络处理器。该处理器包括:计算单元,其包括根据本发明的计算装置;存储单元,其用于存储神经元数据、权重值和指令;控制单元,其用于获得保存在所述存储单元的指令并发出控制信号。
与现有技术相比,本发明的优点在于:通过在神经网络处理器中采用脉动阵列的计算单元结构,提升了神经网络处理器的运算效率,降低了对处理器的带宽需求。
附图说明
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
图1示出了现有技术中神经网络的拓扑示意图;
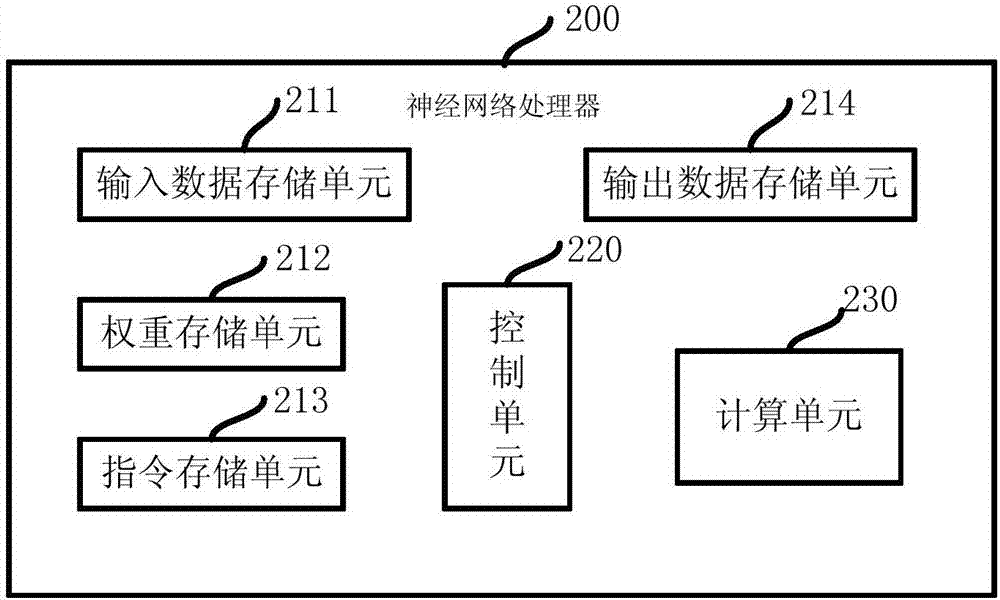
图2示出了根据本发明一个实施例的神经网络处理器的示意框图;
图3示出了根据本发明一个实施例的神经网络处理器中的计算单元的脉动阵列结构图;
图4示出了利用本发明的一个实施例的二维矩阵形式的脉动阵列结构图;
图5示出了根据本发明一个实施例的脉动阵列结构中每个处理单元的结构框图;
图6示出了根据本发明另一实施例的一维矩阵形式的脉动阵列结构图。
具体实施方式
为了使本发明的目的、技术方案、设计方法及优点更加清楚明了,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示的现有技术中神经网络的通用拓扑图,神经网络是对人脑结构和行为活动进行建模形成的数学模型,通常分为输入层、隐藏层和输出层等结构,每一层均由多个神经元节点构成,本层的神经元节点的输出值(在本文中称为神经元数据或节点值),会作为输入传递给下一层的神经元节点,逐层连接。神经网络本身具有仿生学特征,其多层抽象迭代的过程与人脑及其他感知器官有着类似的信息处理方式。
神经网络多层结构的第一层输入值为原始图像(在本发明中的“原始图像”指的是待处理的原始数据,不仅仅是狭义的通过拍摄照片获得的图像),典型地,对于神经网络的每一层,可通过对该层的神经元数据(在本文中有时也简称数据)和其对应的权重值进行计算来得到下一层的神经元数据。例如,假设
为了提高处理速度,可采用定制的处理器来实现神经网络中运算,参见图2示出的根据本发明一个实施例的适用于神经网络模型的处理器。
概括而言,该实施例中的神经网络处理器200基于存储-控制-计算的结构。存储结构用于存储参与计算的数据、神经网络权重及处理器的操作指令;控制结构用于解析操作指令,生成控制信号,该信号用于控制处理器内数据的调度和存储以及神经网络的计算过程;计算结构用于参与该处理器中的神经网络计算操作,保证数据在计算单元中能够正确地与相应权重进行计算。计算结构、控制结构和存储结构之间可互相通信。
具体而言,存储结构用于存储神经网络处理器外部传来的数据(例如,原始特征图数据)或用于存储处理过程中产生的数据,包括处理过程中产生的处理结果或中间结果,这些结果可以来自于神经网络处理器内部的运算部件或其他外部运算部件。此外,存储结构还可用于存储参与计算的指令信息(例如,载入神经元数据至计算单元、计算开始、计算结束、或将计算结果存储至存储单元等)。相应地,在图2的实施例中,存储结构进一步细分为输入数据存储单元211、权重存储单元212、指令存储单元213和输出数据存储单元214,其中,输入数据存储单元211用于存储参与计算的神经元数据,该数据包括原始特征图数据和参与中间层计算的数据;权重存储单元212用于存储已经训练好的神经网络权重;指令存储单元213用于存储参与计算的指令信息,指令可被控制单元220解析为控制流来调度神经网络的计算;输出数据存储单元214用于存储计算得到的神经元响应值。通过将存储单元进行细分,可将数据类型基本一致的数据集中存储,以便于选择合适的存储介质并可简化数据寻址等操作。本发明所使用的存储单元可以是静态随机存储器(sram)、动态随机存储器(dram)、寄存器堆等常见存储介质,也可以是3d存储器件等新型的存储类型。
控制单元220用于获取保存在指令存储单元的指令并进行解析,进而根据解析得到的控制信号来控制计算单元230进行神经网络的相关运算。控制单元完成指令译码、数据调度、过程控制等工作。
计算单元230(或称计算装置)用于根据从控制单元220获得的控制信号来执行相应的神经网络计算,计算单元与各存储单元相连,以获得数据进行计算并将计算结果写入到存储单元。在该实施例中,计算单元是该处理器的核心运算部件,可完成神经网络中的大部分计算,如,卷积操作、池化操作等。例如,卷积操作的具体过程是:将一个k*k大小的二维权重卷积核对特征图进行扫描,在扫描过程中权重与特征图内对应的特征元素求内积,并将所有内积值求和,得到一个输出层特征元素。当每个卷积层具有n个特征图层时,会有n个k*k大小的卷积核与该卷积层内特征图进行卷积操作,n个内积值求和得到一个输出层特征元素。因此,提高计算单元的计算速度对提升整个神经网络处理器的速度至关重要。
图3示出了根据本发明一个实施例的神经网络处理器中计算单元的结构图。该计算单元采用基于脉动阵列的结构,由主处理器310和脉动阵列处理单元320组成,其中,主处理器用于完成神经网络中的大部分运算,而当主处理器判断当前的计算适合于利用本发明的脉动阵列处理单元执行时,则主处理器310负责向脉动阵列处理单元320从入端载入待计算元素,例如,数据和权重,完成相关计算之后,将处理的结果数据从出端传送回主处理器310。例如,在该实施例中,处理单元1、6、11、16可作为入端从主处理器310接收输入信息,处理单元5、10、15、20可作为出端向主处理器310传回结果信息。
在图3的实施例中,脉动阵列处理单元320采用二维矩阵组织方式,包括行阵列和列阵列,且每个处理单元只与相邻的处理单元相连,即处理单元只与相邻的处理单元进行通信。主处理器310可以控制待计算元素从脉动阵列的上方和左方输入,不同的类型的数据可从不同的方向输入至脉动阵列处理单元320,例如,可将权重从上方输入并控制其在列方向上进行脉动传播,而将数据从左侧输入并控制其在行方向上进行脉动传播,或者将数据从上方输入,将权重从左侧输入。本发明不对计算元素的输入方向和传播方向进行限制。此外,本文中的“左”,“右”,“上”,“下”等是指本发明的各个部分,这些术语指的是图中所示出的相应方向,不应解释为对本发明的物理实现的限制。
在本发明的实施例中,每个处理单元,即每个计算节点,采用相同的内部结构。图4示出了根据本发明的一个实施例的一个处理单元的电路结构图。
参见图4所示,一个处理单元包括数据寄存器410、数据旁路单元420、权重寄存器430、权重旁路单元440、乘法器450和累加器460。权重旁路单元440包括三个端口,一端用于接收权重值,该权重值可以来自于相邻的处理单元或来自于主处理器(例如,对于作为入端的处理单元),另一端连接至权重寄存器430和乘法器450,用于将权重值传送到权重寄存器430暂存或传送至乘法器进行相关的乘法运算,权重旁路单元440的第三端直接接入到权重输出,用于当权重值不需要参与本处理单元的运算,仅需要进行脉动传播时,直接输出到下一个相邻的处理单元或输出给主处理器,由主处理器将最终的计算结果存储到图2示出的对应的存储单元,其中,数据旁路单元420可采用通用的数据选择器芯片实现,通过选通信号控制权重的输出路径。与权重旁路单元类似,数据旁路单元也包括三个端口,分别用于接收输入数据、将数据传送到数据寄存器410和乘法器450、将接收的数据直接输出给下一级处理单元。
对于需要在本处理单元计算的数据和权重,在乘法器450中进行乘法运算,乘法运算的结果接入至累加器460中进行累加。
累加器460可接收上一个处理单元的部分和输入,并将该部分和与乘法器450的输出相加之后,得到的结果输出给下一个处理单元的累加器。当一个处理单元作为入端时,累加器460初始化为0,当处理单元作为出端时,累加器460的计算结果传回给主处理器。
基于本发明的计算单元可专用于以向量乘加为主的计算过程,例如,卷积运算,以提高神经网络运算速度。在一个实施例中,主处理器可预先设定规则,确定哪些类型的运算由脉动阵列处理单元完成,哪些运算由主处理器自身或其它的加速装置来完成。在另一个实施例中,即使当前运算适合由脉动处理单元执行,主处理器也可以根据计算单元中的资源使用情况,动态地决策是由脉动阵列单元执行或由其它的加速装置执行。例如,当脉动阵列单元处于高负荷时,可由主处理器本身完成当前的计算,以降低等待时间或避免降低处理速度。
结合图2,本发明基于脉动阵列的处理器的计算过程包括:
步骤s1,控制单元对存储单元寻址,读取并解析下一步需要执行的指令;
步骤s2,根据解析指令得到的存储地址从存储单元中获取输入数据;
步骤s3,将数据和权重分别从输入存储单元和权重存储单元载入至基于脉动阵列的计算单元;
步骤s4,脉动阵列的各处理单元完成各自的相关运算并将结果进行脉动传播,关于该步骤的具体计算过程,后面将结合附图5进行详述;
步骤s5,计算单元从出端的处理单元将计算结果输出给主处理器以进一步存储到输出存储单元中。
下面结合图5,以采用3*3卷积核对4*4图层进行卷积操作为例阐述本发明提供的基于脉动阵列计算单元的执行过程。4*4图形分割为4个数据块,分别载入至脉动阵列的不同行中,大小为3*3的四个不同权重分别载入至脉动阵列的不同列中。
例如,在图5中,将4*4图形分割为4个数据块,分别是
在第一个周期,数据块0的数据12和权重w0,0同时进入处理单元pe00,其中,数据12从pe00的左边载入并从左向右流动,权重w0,0从pe00的上方载入并从上向下流动,即,在第一个周期结束时,处理单元pe00的计算结果为12*w0,0;
在第二个周期,数据12向右流动进入至处理单元pe01,权重w1,0载入至处理单元pe01,同时数据9载入至处理单元pe00和pe10,权重w0,0向下流动至处理单元pe10,权重w0,1载入至处理单元pe00,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1,处理单元pe01的计算结果为12*w1,0,其他处理单元类似,在此不再详述;
在第三个周期,数据12、9、9向右流动进入至处理单元pe02、pe01和pe11,权重w0,0、w0,1和w1,0向下流动至处理单元pe20、pe10和pe11中,权重w0,2、w1,1和w2,0载入至处理单元pe00、pe01和pe02中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2;
在第四个周期,数据12、9、9、6、6和4向右流动至处理单元pe03、pe02、pe12、pe01、pe11和pe21中,权重w0,0、w0,1、w1,0、w0,2、w1,1和w2,0向下流动至处理单元pe30、pe20、pe21、pe10、pe11和pe12中,数据4、3、2和2载入至处理单元pe00、pe10、pe20和pe30中,权重w0,3、w1,2、w2,1、w3,0载入至处理单元pe00、pe01、pe02和pe03中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2+4*w0,3;
在第五个周期,数据9、9、6、6、4、4、3、2和2向右流动至pe03、pe13、pe02、pe12、pe22、pe01、pe11、pe21和pe31中,权重w0,1、w1,0、w0,2、w1,1、w2,0、w0,3、w1,2、w2,1和w3,0向下流动至处理单元pe30、pe31、pe20、pe21、pe22、pe10、pe11、pe12和pe13中,数据2、2、7和7载入至处理单元pe00、pe10、pe20和pe30中,权重w0,4、w1,3、w2,2和w3,1载入至处理单元pe00、pe01、pe02和pe03中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2+4*w0,3+2*w0,4;
在第六个周期,数据6、6、4、4、3、2、2、2、2、7和7向右流动至处理单元pe03、pe13、pe23、pe02、pe12、pe22、pe32、pe01、pe11、pe21和pe31中,权重w0,2、w1,1、w2,0、w0,3、w1,2、w2,1、w3,0、w0,4、w1,3、w2,2和w3,1向下流动至处理单元pe30、pe31、pe32、pe20、pe21、pe22、pe23、pe10、pe11、pe12和pe13中,数据7、7、9和1载入至处理单元pe30、pe20、pe10和pe00,权重w0,5、w1,4、w2,3和w3,2载入至处理单元pe00、pe01、pe02和pe03中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2+4*w0,3+2*w0,4+7*w0,5;
在第七个周期,数据4、3、2、2、2、2、7、7、7、7、9和1向右流动至处理单元pe03、pe13、pe23、pe33、pe02、pe12、pe22、pe32、pe01、pe11、pe21和pe31中,权重w0,3、w1,2、w2,1、w3,0、w0,4、w1,3、w2,2、w3,1、w0,5、w1,4、w2,3和w3,2向下流动至处理单元pe30、pe31、pe32、pe20、pe21、pe22、pe23、pe10、pe11、pe12和pe13中,数据9、1、5和5载入至处理单元pe00、pe10、pe20和pe30中,权重w0,6、w1,5、w2,4和w3,3载入至处理单元pe00、pe01、pe02和pe03中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2+4*w0,3+2*w0,4+7*w0,5+9*w0,6;
在第八个周期,数据2、2、7、7、7、7、9、1、9、1、5和5向右流动至处理单元pe03、pe13、pe23、pe33、pe02、pe12、pe22、pe32、pe01、pe11、pe21和pe31中,权重w0,4、w1,3、w2,2、w3,1、w0,5、w1,4、w2,3、w3,2、w0,6、w1,5、w2,4和w3,3向下移动至处理单元pe30、pe31、pe32、pe20、pe21、pe22、pe23、pe10、pe11、pe12和pe13中,数据5、5、8和8载入至处理单元pe00、pe10、pe20和pe30中,权重w0,7、w1,6、w2,5和w3,4载入至处理单元pe00、pe01、pe02和pe03中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2+4*w0,3+2*w0,4+7*w0,5+9*w0,6+5*w0,7;
在第九个周期,数据4、3、2、2、2、2、7、7、7、7、9和1向右移动至处理单元pe03、pe13、pe23、pe33、pe02、pe12、pe22、pe32、pe01、pe11、pe21和pe31中,权重w0,5、w1,4、w2,3、w3,2、w0,6、w1,5、w2,4、w3,3、w0,7、w1,6、w2,5和w3,4向下移动至处理单元pe30、pe31、pe32、pe20、pe21、pe22、pe23、pe10、pe11、pe12和pe13中,数据9、1、5和5接入至处理单元pe00、pe10、pe20和pe30中,权重w0,8、w1,7、w2,6和w3,5载入至处理单元pe00、pe01、pe02和pe03中,此时对于数据块0和权重0,处理单元pe00的计算结果为12*w0,0+9*w0,1+6*w0,2+4*w0,3+2*w0,4+7*w0,5+9*w0,6+5*w0,7+8*w0,8,处理单元pe01中的计算结果为12*w1,0+9*w1,1+6*w1,2+4*w1,3+2*w1,4+7*w1,5+9*w1,6+5*w1,7。
至第九个周期,处理单元pe00中已得到权重0和数据块0进行卷积的结果,在第十个周期,处理单元pe01中将得到数据块0和权重1的计算结果,相应地,在后续周期中,处理单元pe10中将得到数据1和权重0的计算结果,类似地,处理单元pe32中将得到数据块3和权重2的计算结果,处理单元pe33中将得到数据块3和权重3的计算结果。这种流水线式的数据和权重的载入方式和计算方式能够有效的提高运算效率。上述每个时钟周期的数据以及权重的载入和流动可通过主处理器来控制。
在本发明的另一实施例中,采用一维矩阵形式的脉动阵列组织形式,参见图6所示。在这种情况下,主处理器可将待计算的权重值可预先存储到不同的处理单元中并保持到最后一个数据完成与相应权重的计算之后,再加载下一组权重值,而主处理器采用流水线的方式将数据载入到脉动阵列处理单元并控制其从左向右流动。应理解的是,在本发明中,无论是一维矩阵形式的脉动阵列还是二维形式的脉动阵列,其包含的处理单元数量均可根据对计算量和处理速度的需求来选择,并不限于本发明附图所示的数量。
包含本发明计算单元的处理器可应用了各种电子设备,例如、移动电话、嵌入式电子设备,用于神经网络模型的训练等。
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 还没有人留言评论。精彩留言会获得点赞!