一种基于日志结构合并树的两阶段合并方法与流程
本发明是关于一种基于日志结构合并树的两阶段合并方法,属于信息存储技术领域。
背景技术:
随着web2.0时代的到来,数据规模呈爆炸式增长,传统的关系型数据库已经很难满足海量数据存储时代的需求,而具有读写速度快,易于扩展,成本低廉等特征的非关系型数据库开始被广泛应用。按存储方式和存储内容,非关系型数据库可以分为列存储、文档存储、键值存储、图存储和对象存储等多种类型,其中,键值存储简单,非常适合不涉及过多数据关系和业务关系的业务数据,在各大互联网公司业务中已称为主流的存储方式。键值存储通常有哈希表、b树及其变体、日志结构合并树三种架构。日志结构合并树主要对大量写入的场景进行优化,同时也提供合理的读性能和范围查询功能,并且有leveldb和rockdb等成熟的开源系统可以使用,通常用于存储应用产生的海量数据。日志结构合并树的概念于上世纪90年代被提出,近年来开始被大规模使用,说明这种存储方式能够在大数据时代发挥其主要优势。宏观来看,日志结构合并树由两个或两个以上存储结构组成,其中,上层是一个常驻内存的结构称为c0,c0空间较小,可以采用任何一种有序结构存储数据,如跳跃表等;下层部署另一个部件负责管理外存空间称为c1,c1通常采用b树等对磁盘友好的有序结构,空间通常比c0大很多,c1中经常被访问的结点或数据也将会被缓存在内存中。按照需要,有些日志结构合并树可以在外存中设置更多层次,如c2、c3等,一般下层空间是其相邻上层的n倍,通过设置多层可以使整个日志结构合并树的空间实现指数级增长。
合并操作是日志结构合并树的关键模块,负责将数据从内存移动到外存以及外存空间的维护。为加快数据写入,日志结构合并树采用多层次的组织结构,上层空间较小,下层空间通常是其上一层空间的数倍,以指数级的方式进行增长。当写入新数据时,数据首先进入内存填充buffer(缓存器),buffer装满后进入日志结构合并树的上层空间。随着数据量不断增大,上层空间不足,其中的数据需要不断向下合并至下层空间。为平衡读取操作的开销,日志结构合并树保证数据按key顺序的方式存储,使得访问数据能够快速被定位。然而,指数级的空间增长方式给数据库带来写放大,即来自上层用户要求写入的量远远小于数据库实际的写入量。如图1所示,leveldb系统实现了日志结构合并树的多层结构,下层空间是相邻上层空间的n倍,内存中以跳跃表方式缓存数据,在数据量到达一定阈值时写入第0层,每层中数据存放在多个大小相近的文件中,除第0层外数据在文件内和文件间是严格有序的,即将每层的有序结构以文件方式保存。为加快数据持久化到外存的速度,第0层的数据直接来自内存持久化,所以数据在文件内有序,文件间不保证顺序。当外存中某一层的大小超过限定值,leveldb系统将执行合并操作。合并操作首先在目标层(如lk层)中选取一个文件,然后在其下一层(lk+1)找出与之覆盖键值范围相同的其他文件,将来自两层的文件均读入内存进行归并排序,最后将产生的数据写入lk+1层,在这个过程中,任何读写均是对已持久化的数据的重复操作。由于合并操作是为了将数据进行下压,所以对上层一个文件的读写是不可避免的,减小读写放大率只能从下层入手。而日志结构合并树存在的高读写放大率问题还将导致访问延迟抖动明显,不适合在非耐久性设备中应用等问题,在实际应用中往往不能提供高质量的存储服务。
综上所述,现有日志结构合并树的数据合并方法是单阶段的合并方法,即选择少数的上层数据和很多的下层数据进行合并,这种合并方法较为简单,但是会带来严重的写放大和存储服务性能下降的问题。
技术实现要素:
针对上述问题,本发明的目的是提供一种基于日志结构合并树的两阶段合并方法,能够提高存储服务性能下降且能够减小日志结构合并树存在的高读写放大率。
为实现上述目的,本发明采取以下技术方案:一种基于日志结构合并树的两阶段合并方法,其特征在于,包括以下步骤:1)根据不均衡得分,在开源系统中选出空间分布最不合理的一层;2)根据轮询原则,选出空间分布最不合理的一层中的目标文件;3)链接阶段:将目标文件按照覆盖相同键值范围的下层文件分割碎片,将每一碎片与对应键值范围的下层文件进行链接,并为每一下层文件均增加用于记录链接信息的链接元数据,记为slicelink;4)检查每一下层文件的slicelink数量,若所有下层文件的slicelink数量均不超过预设阈值,则进入步骤2),直到存在下层文件的slicelink数量超过预设阈值,则进入步骤5);5)合并阶段:将slicelink数量超过预设阈值的下层文件以及与该下层文件碎片链接的对应键值范围的目标文件分别读入开源系统的内存中进行合并,生成新文件后写入下层文件所在层中。
进一步,所述步骤3)中将目标文件按照覆盖相同键值范围的下层文件分割碎片,将每一碎片与对应键值范围的下层文件进行链接,并为每一下层文件均增加用于记录链接信息的链接元数据,具体过程为:①将目标文件标记为冻结状态,通过开源系统表缓存中的目标文件元数据记录目标文件的键值范围;②在开源系统的表缓存中获取与目标文件覆盖相同键值范围的若干下层文件;③根据每一下层文件的键值范围将目标文件分割成若干碎片,并将每一碎片与对应键值范围的下层文件进行链接;④为目标文件引入用于记录目标文件被链接次数的引用计数;⑤在开源系统的内存中为每一下层文件均增加用于记录链接信息的slicelink,其中,链接信息包括所链接碎片的来源和键值范围。
进一步,所述步骤4)中的预设阈值根据日志结构合并树的扇出进行设置。
进一步,所述步骤5)中将slicelink数量超过预设阈值的下层文件以及与该下层文件碎片链接的对应键值范围的目标文件分别读入开源系统的内存中进行合并,生成新文件后写入下层文件所在层中,具体过程为:a)根据slicelink数量超过预设阈值的下层文件中每一slicelink记录的碎片来源,确定该下层文件中每一碎片链接的冻结状态目标文件;b)根据上述slicelink记录的碎片键值范围和对应冻结状态目标文件的元数据,得到该下层文件中每一碎片的键值范围覆盖的目标文件数据块;c)将该下层文件和目标文件数据块分别读入开源系统的内存后进行一次归并排序生成新文件,并将新文件写入该下层文件所在层中;d)检测冻结状态目标文件的引用计数,当引用计数为0时,该冻结状态的目标文件即能够被回收并删除。
进一步,在对下层文件进行读操作处理时采用小粒度读操作,即先读取下层文件的slicelink,若所需读取的数据不在该slicelink中,则再去该下层文件中进行搜索。
本发明由于采取以上技术方案,其具有以下优点:1、本发明合并操作中的链接阶段和合并阶段是两个不连续的过程,通过对slicelink的数量预设阈值,去除了合并操作需要立即执行的特性,从而允许下层文件掌握主动权,仅当下层文件积累了足够的slicelink后才触发真正的i/o操作,这种情况下合并和移动一个文件所需要额外进行的i/o量约为1倍,有效降低了i/o放大率,进一步提高存储服务性能。2、本发明根据slicelink记录的链接信息和目标文件的元数据记录的目标文件键值范围,只需将与下层文件碎片链接的对应键值范围的目标文件数据块读入内存中即可,减小了日志结构合并树存在的高读写放大率。3、本发明通过对目标文件进行冻结并引入引用计数,能够避免对目标文件的重复读写,进一步解决了写放大和存储服务性能下降问题。4、虽然本发明的两阶段合并方法对读操作带来了一定影响,引入了额外的小粒度读操作,但是由于开源系统针对文件索引和布隆过滤器进行了有效的缓存,实际上这些额外的读基本上只涉及内存读操作。尤其是应用在固态硬盘为存储介质的存储系统上时,由于设备随机读性能已经得到很大提高,所以本发明的两阶段合并方法对读性能的损耗并不大,可以广泛应用于信息存储技术领域中。
附图说明
图1是现有leveldb系统的存储架构和合并操作示意图;
图2是本发明的原理示意图;
图3是本发明链接阶段的原理示意图;
图4是本发明合并阶段的原理示意图,其中,图4(a)为合并阶段前的原理示意图,图4(b)为合并阶段后的原理示意图。
具体实施方式
以下结合附图来对本发明进行详细的描绘。然而应当理解,附图的提供仅为了更好地理解本发明,它们不应该理解成对本发明的限制。
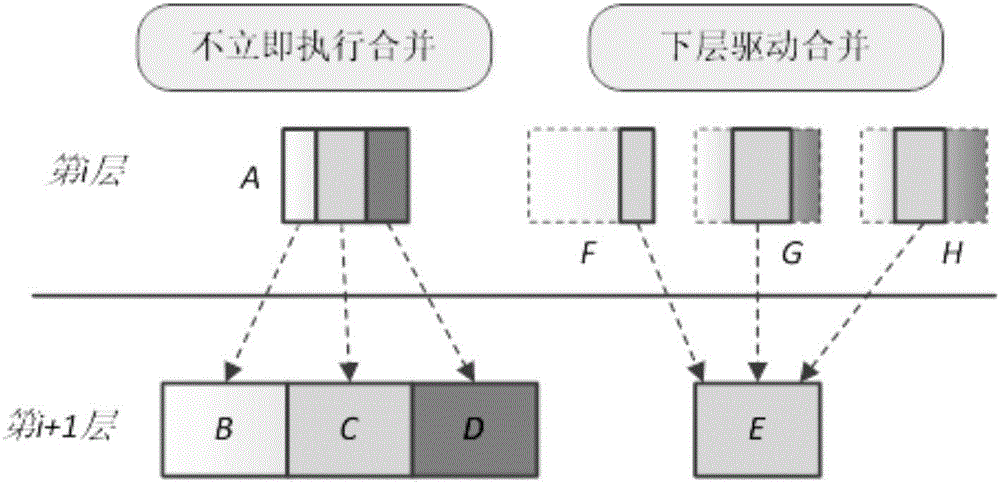
如图1所示,两阶段合并方法可以分为链接阶段和合并阶段两个步骤,当一个上层文件a被合并进程选中称为目标文件时开始进入链接阶段,这一阶段合并操作不需要立即执行,而是将上层文件a根据键值范围进行切分。假设上层文件a需要与下层文件b、c和d进行合并,则需要将上层文件a划分为三个碎片(slice),每一碎片的键值范围分别对应下层文件b、c和d。当下层的某一文件e上链接有足够多的碎片时(如下层文件e有来自上层文件f、g和h的碎片)开始进入合并阶段,此时合并进程将下层文件e和其所链接的三个碎片读出到内存中进行归并排序,随后生成若干个新的文件写回下层中。
如图2~4所示,本发明提供的基于日志结构合并树的两阶段合并方法,包括以下步骤:
1、根据不均衡得分(compactionscore),在leveldb系统中选出空间分布最不合理的一层,其中,不均衡得分为现有技术,在此不做赘述。
2、根据轮询原则(round-robin),选出空间分布最不合理的一层(第i层)中的目标文件a,其中,轮询原则为现有技术,在此不做赘述。
3、链接阶段:将目标文件a按照覆盖相同键值范围的下层文件b、c和d分割碎片,将每一碎片与对应键值范围的下层文件b、c和d进行链接,并增加用于记录链接信息的链接元数据,记为slicelink,具体过程为:
1)将目标文件a标记为冻结状态,通过leveldb系统表缓存中的目标文件a元数据记录目标文件a的键值范围。
2)在leveldb系统的表缓存中获取与目标文件a覆盖相同键值范围的下层文件b、c和d。
3)根据下层文件b、c和d的键值范围将目标文件a分割成三个碎片(图3中的1、2和3),并将三个碎片与对应键值范围的下层文件b、c或d进行链接。
此时考虑键值范围中的间隔问题,假设下层文件b的键值范围为[ksmallest,kbh](记为kr1),下层文件c的键值范围为[kbh,kch](记为kr2),下层文件d的键值范围为[kch,klargest](记为kr3),其中,ksmallest表示该层的最小键值,kbh表示下层文件b内的最大键值,kch表示下层文件c内的最大键值,klargest表示该层的最大键值。可以看出,kr1、kr2和kr3中包括下层文件b、c和d之间的间隔,所以当目标文件a按照下层文件b、c和d的键值范围分割碎片后,任一碎片均可以链接到kr1、kr2或kr3这三个键值范围中的任意一个(例如图3中碎片1链接到键值范围为kr1的下层文件b)。
4)为目标文件引入引用计数,用于记录目标文件a被链接的次数。
当目标文件a进入链接阶段时,合并进程会将其标记为冻结状态,这一操作在逻辑上是将目标文件a从日志结构合并树中去除,冻结状态的目标文件a不会在下一次合并时被选中,且需要为其引入一个新的元数据:引用计数,用于记录这个文件被链接的次数。
5)在leveldb系统的内存中为下层文件b、c和d增加用于记录链接信息的链接元数据(slicelink)a1、a2和a3,其中,slicelinka1、a2和a3上记录的链接信息包括所链接碎片的来源和键值范围。
4、检查每一下层文件的slicelink数量,若所有下层文件的slicelink数量均不超过预设阈值,则进入步骤2,直到存在下层文件的slicelink数量超过预设阈值,则进入步骤5。
预设阈值需要根据日志结构合并树的扇出进行设置,假设日志结构合并树的扇出为n,则目标文件分割碎片后,平均每一碎片的空间大小平均为1/n,理论上当阈值设置为n时,合并阶段下层文件所链接的碎片总大小约等于其自身。
5、合并阶段:将slicelink数量超过预设阈值的下层文件e(下层文件e为下层文件b、c和d中的某一个)以及与该下层文件e碎片链接的对应键值范围的目标文件分别读入leveldb系统的内存中进行合并,生成新文件后写入下层文件e所在层中,具体过程为:
1)根据slicelink数量超过预设阈值的下层文件e中每一slicelink记录的碎片来源,确定下层文件e中每一碎片链接的冻结状态目标文件,本发明实施例的下层文件e中每一碎片链接的冻结状态目标文件为三个f、g和h(其中包括目标文件a,为了方便内容叙述采用f、g和h表示)。
2)根据上述slicelink记录的碎片键值范围和对应冻结状态目标文件的元数据,得到下层文件e中每一碎片的键值范围覆盖的目标文件数据块。
假设下层文件e上链接的碎片为f3、g1和h2,分别来自冻结状态的目标文件f、g和h。因为每一目标文件中的数据均按照数据块的形式存储,每一目标文件通常包含若干数据块,所以通过slicelink中记录的碎片键值范围和目标文件自身的元数据,合并进程不需要将冻结状态的目标文件f、g和h整体读出,只需要读出碎片f3、g1和h2覆盖的相应目标文件的数据块即可。
3)将下层文件e和目标文件数据块分别读入leveldb系统的内存后进行一次归并排序生成新文件e’和e”(以此为例),并将新文件写入下层文件e所在层中,其中,归并排序为现有技术,在此不做赘述。
4)检测冻结状态目标文件的引用计数,当引用计数为0时,该冻结状态的目标文件即能够被回收并删除。
由于将碎片f3、g1和h2进行了合并,所以冻结状态的目标文件f、g和h的被链接次数需要减少,即引用计数需减一,当冻结状态的目标文件f、g或h的引用计数减为0时,该冻结状态的目标文件f、g或h即能够被回收并删除。
在一个优选的实施例中,在对下层文件e进行读操作处理时采用小粒度读操作,即先读取下层文件e的slicelink,若所需读取的数据不在该slicelink中,则再去下层文件e中进行搜索。
由于在链接阶段处理和合并阶段处理中,冻结状态的目标文件不再受到leveldb系统的正常流程管理,实际上,该冻结状态的目标文件中的数据逻辑上已经属于所链接的下层文件。因为日志结构合并树的数据流动方式决定了上层文件的数据版本永远比下层文件的数据版本新,所以与下层文件的数据相比在slicelink中的数据应该拥有更高的读优先级。因此,当用户需要读取下层文件e中的数据时,leveldb系统首先需要读取下层文件e的slicelink,若所需读取的数据不在该slicelink中,则再去下层文件e中进行搜索。
虽然本发明的两阶段合并方法对读操作带来了一定影响,但是leveldb系统已经对文件索引和布隆过滤器均进行了有效的缓存,实际上这些额外的读操作基本上只涉及内存读操作,尤其是当存储系统应用在ssd为存储介质的存储系统上时,由于该存储系统的随机读性能已经得到很大提高,所以本发明的两阶段合并方法对读性能的损耗并不大。
上述各实施例仅用于说明本发明,其中各部件的结构、连接方式和制作工艺等都是可以有所变化的,凡是在本发明技术方案的基础上进行的等同变换和改进,均不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!