一种数据集分类可用性的评估方法与流程
本发明主要涉及数据集的分类可用性研究,具体涉及一种对机器学习分类任务所使用的训练数据集进行质量评估的方法。
背景技术:
随着经济和科技的不断发展,现实世界中各方面的数据量也急剧增长。数据已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。在大数据的时代背景下,数据驱动的智能系统就成为了人工智能和机器学习的前沿重要研究课题。从现存的数据分类算法来看,很多算法都是基于大规模的学习样本来训练得到分类参数。但当今时代下,许多学习样本存在数据量大、类别繁多、价值密度低等特点,严重制约了相应的智能数据分类系统的应用与推广,并且使用低质量的学习样本集合也会影响分类系统的准确性。为了提升机器学习分类器的性能,训练数据集的可用性评价就成为了必要的技术。在此问题的驱动下,本文的研究目标是提出一种数据集分类可用性的评估方法。
大数据普遍存在,正在成为信息社会的重要财富,同时也带来了巨大的挑战,数据可用性问题就是大数据的重要挑战之一。随着数据的爆炸性增长,劣质数据也随之而来,数据可用性受到严重影响,对信息社会形成严重威胁,引起了学术界和工业界的共同关注。一个正确的大数据集合至少应满足以下五个性质:一致性、完整性、精确性、时效性、实体同一性。评估数据是否达到预期应用场景的质量要求,就可以通过这五个方面来进行判断。
一致性:数据集合中每个信息都不包含语义错误或相互矛盾的数据。精确性:数据集合中每个数据都能准确表述现实世界中的实体。完整性:数据集合中包含足够的数据来回答各种查询和支持各种计算。时效性:信息集合中每个信息都与时俱进,不陈旧过时。实体同一性:同一实体在各种数据源中的描述统一。根据以上五个性质,我们可以如下定义数据可用性:一个数据集合满足上述五个性质的程度是该数据集合的可用性。本文提出的一种数据集分类可用性的评估方法,评价对象是应用于机器学习分类算法的训练数据集。
粒计算是信息处理的一种新的概念和计算范式,是研究基于多层次粒结构的思维方式、问题求解方法、信息处理模式及其相关理论、技术和工具的学科。粒计算方法主要用于对不确定信息的处理,强调对现实世界问题多视角、多层次的理解和描述,从而得到对问题的粒结构表示。本文提出的一种数据集分类可用性的评估方法,借鉴了粒计算的思想,从数据集的特征和类别的视角出发对其进行粒化。然后根据样本在所划分信息粒上的分布情况,来计算原始数据集的分类可用性。
技术实现要素:
本发明的目的在于提出一种对机器学习的训练数据集进行分类可用性评估的方法。对原始数据集进行预处理并构建信息系统,计算各类别样本在各特征列上的中心点得到初始数据粒,并通过构造样本分布的置信区间来划分信息粒,根据样本对所划分信息粒的命中率来评估该数据集的分类可用性。本发明提出的分类可用性的评估方法,还可以评价每个特征对于分类效果的贡献程度。
本发明的技术方案如下:
步骤1,对输入的原始数据集x进行预处理,然后统计处理后的数据集u的基本信息。得到一个信息系统s=(u,a,v,f),记样本个数为n、特征维数为m、标识列的复杂度为k。
其中u={x1,x2,…,xn}表示样本集合,a={a1,a2,…,am}表示属性集合,v是属性a的值域,f:u×a→v是一个使得{f(x,a)∈va|x∈u,a∈a}成立的函数,f(x,a)表示样本x在属性a上的取值。
步骤2,根据步骤1标识列的复杂度为k,即数据集有k类样本记为c={c1,c2,…,ck},作为初始的数据粒。计算每一类样本c在每个属性a上的均值
步骤3,对于
由此可以构造出每一类样本c在每个属性a上的置信区间集合{n(c,a)|c∈c,a∈a},从而由信息系统s经过划分得到的k个信息粒记为n={n1(c1,a),n2(c2,a),…,nk(ck,a)}。
步骤4,信息系统s中的样本总数为n特征维度为m,属性a上命中信息粒集合n的样本数为na,则该属性的分类可用度为
分类可用度ea代表了属性a对于分类任务的贡献程度,分类可用性e代表了数据集x作为机器学习分类任务训练数据集的可用程度。
附图说明
读者在参照附图阅读了本发明的具体实施方式以后,将会更清楚地了解本发明的各个方面。其中,
图1为本发明一种数据集分类可用性的评估方法的流程图,同时也为摘要附图;
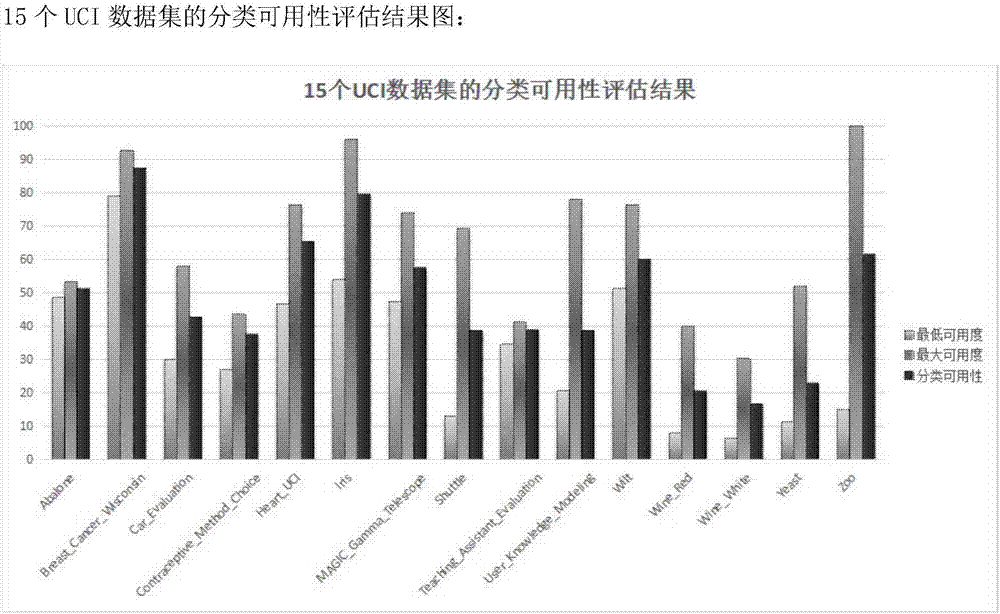
图2为15个uci数据集的分类可用性评估的结果图;
图3为被评数据集在3种分类器上的分类准确率与分类可用性的对比图。
具体实施方式
步骤1,对输入的原始数据集x进行预处理,然后统计处理后的数据集u的基本信息。得到一个信息系统s=(u,a,v,f)。
步骤1所述的对原始数据集x进行预处理的方法为,去除含缺失值的记录,利用箱型图分析异常值并去除,将非数值型的特征值数值化,得到处理后的数据集u。统计数据集u的基本信息,记样本个数为n、特征维数为m、标识列的复杂度为k,得到一个信息系统s=(u,a,v,f)。
信息系统s=(u,a,v,f)中,u={x1,x2,…,xn}表示样本集合,a={a1,a2,…,am}表示属性集合,v是属性a的值域,f:u×a→v是一个使得{f(x,a)∈va|x∈u,a∈a}成立的函数,f(x,a)表示样本x在属性a上的取值。
步骤2,根据原始数据集的标识列复杂度k,可将k类样本记为c={c1,c2,…,ck},作为初始的数据粒。计算每一类样本c在每个属性a上的均值o(c,a),即信息系统s中各初始数据粒的中心点。
步骤2所述的对初始数据粒进行样本中心点计算的方法为,根据原始数据集的标识列复杂度k,即数据集有k类样本记为c={c1,c2,…,ck},c1∪c1…∪ck=u作为初始的数据粒。计算每一类样本在每个属性上的均值,即对于
其中n(c)表示类别c的样本数,f(x,a)表示样本x在属性a上的取值,则信息系统s中各初始数据粒的中心点为{o(c,a)|c∈c,a∈a}。
步骤3,根据步骤2所得各初始数据粒的中心点o(c,a),以及样本x在属性a上取值的最大值和最小值
步骤3所述的根据初始数据粒中心点构造置信区间的方法为,对于
将步骤2所得到的各初始数据粒的中心点o(c,a)以及
得到一个新的有序数组,此数组中的相邻元素
置信区间ni(ci,a)的含义是,属于类别ci的样本x在属性a上的取值分布在该区间上的期望概率最高。即对于
从而可将信息系统s=(u,a,v,f)按照置信区间划分得到k个信息粒,记为n={n1(c1,a),n2(c2,a),…,nk(ck,a)}。
步骤4,计算信息系统s中属性a上命中信息粒集合n的样本比率为
步骤4所述的根据步骤3所划分的样本信息粒进行分类可用度计算的方法为,在信息系统s=(u,a,v,f)中对于任意属性a∈a定义函数ga(x),当ga(x)=1时表示样本x命中信息粒集合n={n1(c1,a),n2(c2,a),…,nk(ck,a)},定义如下式:
对所有的x∈u统计属性a∈a上命中信息粒集合n的样本数na,如下式:
信息系统s中的样本总数为n特征维度为m,将属性a的分类可用度记为ea,原数据集x的分类可用性记为e,计算公式如下:
分类可用度ea代表了属性a对于分类任务的贡献程度,分类可用性e代表了数据集x作为机器学习分类任务训练数据集的可用程度。
- 还没有人留言评论。精彩留言会获得点赞!