一种生产数据驱动的动态作业车间调度规则智能选择方法与流程
本发明涉及制造企业作业车间排产调度技术应用领域,更具体地,涉及到一种生产数据驱动的动态作业车间调度规则智能选择方法。
背景技术:
作业车间调度问题(jsp)是最重要的生产调度问题,具有多目标性、动态随机性、计算复杂性等特点,并已被证明是np难问题。经过几十年的发展,研究人员己经提出许多用于解决作业车间调度问题的算法,包括基于分支定界、数学规划等运筹学理论的调度方法,基于调度规则的调度方法,基于瓶颈的调度方法,基于人工神经网络、遗传算法、群体智能等智能计算理论的调度方法。在各种调度方法中,基于调度规则的调度算法以低的计算时间复杂度、便于理解等特点而广泛应用于实际生产作业调度过程中。
但对于具有加工环境动态性、加工订单不确定性、设备故障不确定等综合复杂性的实际生产车间调度问题,上述己提出的调度算法和固定调度规则的方法大多基于对问题的理想化约简模型而来,故在实际应用中仍具有寻优效率低、调度性能差、调度不灵活的局限性,难以适应作业车间生产状态动态变化的情况。作业车间调度问题的特点要求调度系统能够迅速、有效地适应生产加工环境的变化,并快速合理地进行生产过程调度决策,为此须寻求一种更加先进的新方法来有效解决实际作业车间生产调度问题。
随着信息技术在生产制造过程中的广泛应用,制造系统积累了大量的订单、设备、调度方案、生产状态和生产性能指标等与生产调度相关的数据,利用这些历史生产数据和实时生产数据,建立基于数据的生产过程调度方法不失为一种可行有效的技术方案,然而目前鲜有基于生产数据驱动的作业车间排产调度方法的研究成果可供实际生产选用。
技术实现要素:
针对上述背景技术中现有解决作业车间排产调度技术方法的不足和欠缺,本发明的目的是提供一种生产数据驱动的动态作业车间调度规则智能选择方法,基于生产数据驱动的生产过程调度方法首先利用已有历史调度信息获取多种调度环境下的调度知识,然后在此基础上构建基于生产数据的调度决策模块,该调度决策模块能够快速地响应新的调度环境生成新的调度方案。基于生产数据驱动的调度方法对于解决具有动态性和不确定性的作业车间调度问题具有重要意义。
为了实现上述目的,本发明所采用的技术方案主要包括以下过程:
步骤1:基于multi-pass算法仿真技术建立作业车间生产调度仿真平台,其中包括预置调度目标集、调度规则集和生产状态参数集,多次运行该仿真平台生成一批调度问题对应的最优调度方案集,其中包括了用于调度知识学习的样本数据集;
步骤2:对获得的样本数据集进行约简和筛选处理,形成调度参数集;
步骤3:设计不同调度目标下用于调度知识学习的bp神经网络模型;
步骤4:提出一种改进的萤火虫算法优化bp神经网络模型的训练,获得nfa-bp模型;
步骤5:将各调度目标下的nfa-bp模型集合成一个智能调度模块,并与作业车间mes系统进行集成,由mes数据api提供当前作业车间关键生产状态数据给智能调度模块,用以指导在线排产调度;
步骤6:人工调整在线排产调度的偏差并适时调整调度知识库,即更新调度参数集,另外智能调度模块进行在线优化学习;
步骤7:适应了真实车间生产状况的智能调度模块根据当前作业冲突决策点输出最优调度规则。
在上述技术方案的基础上,步骤1中的样本数据具体包括:
1)生产状态参数集数据workinfo-set,其中包括作业车间的加工任务信息和车间设备信息数据;
2)调度规则集schedulerule-set;
3)调度目标集scheduleperformance-set。
在上述技术方案的基础上,步骤2中对样本数据集进行约简和筛选处理主要包括:
1)对生产状态参数集数据workinfo-set中的生产状态参数进行基于重要性权重比较的筛选处理后形成关键生产状态参数集key-workinfo-set,其中具体操作为:a.对状态参数做归一化处理;b.求各个状态参数的重要性权重;c.设置权重阈值θ,选取状态参数的重要性权重大于θ的状态参数获得关键生产状态参数集key-workinfo-set,并用主成分分析法计算workinfo-set中状态参数的贡献率大小以检验入选key-workinfo-set中参数的合理性,若偏差较大可重新取合适阈值θ进行再次生产状态参数筛选。
2)对schedulerule-set中的调度规则进行性能评价,剔除性能较差的调度规则后形成候选规则集candidate-schedulerule-set,其中具体通过以下准则进行调度规则性能评价:
a.基于工件流经时间方差准则,评价计算式为下式:
b.基于工件交货期拖期时间方差准则,评价计算式为下式:
其中,fi表示工件i的流经时间,即工件加工的生命周期;ti表示工件i的拖期时间,j表示工件数,i=1,2…j。
在上述技术方案的基础上,求各个生产状态参数的重要性权重通过以下算式计算获得:
公式说明:
在上述技术方案的基础上,步骤3中设计不同调度目标下用于调度知识学习的bp神经网络模型,其主要包括:
1)设计bp神经网络模型为一个双隐藏层的四层前馈网络结构;
2)神经网络输入层的维数根据不同调度目标下的关键生产状态参数集key-workinfo-set中元素个数n确定;
3)神经网络输出层的维数根据训练样本中候选规则集candidate-schedulerule-set中元素个数m确定,输出值为"0"或"1",值为"1"表示该调度规则为当前调度时刻的最优调度规则,值为"0"则不是,显然任何情况下只允许输出值集合有且只有一个"1",并与candidate-schedulerule-set元素进行一一映射可得所选择的调度规则;
4)神经网络隐藏层维数通过多次仿真确定,且保持前一隐藏层的维数大于后一层的维数;
5)神经网络训练算法采用改进的萤火虫算法(newfireflyalgorithm),神经网络的权和阈值的初值由改进的萤火虫算法(nfa)初始化确定;
6)神经网络学习常数设置为η=0.05;
7)神经网络目标函数选为交叉熵函数,不要求样本具有正态分布特性,其为适用于不平衡样本的分类目标函数;
8)神经网络隐藏层和输出层的传递函数选为单极性的sigmoid函数,其函数值域为[0,1].
在上述技术方案的基础上,神经网络隐藏层维数通过多次仿真确定,这具体通过以下策略实现:
1)利用经验公式
2)构造初始神经网络,将隐藏层节点数区间内的整数作为隐藏层节点个数分别对训练样本进行训练;
3)记录训练误差绘制成曲线图,曲线图中最低点的误差值所对应的区间内的某一值,就是理想的隐藏层维数。
在上述技术方案的基础上,步骤4提出一种改进的萤火虫算法(newfireflyalgorithm)优化bp神经网络模型的训练,获得nfa-bp模型,这主要包括:
1)为提高萤火虫算法(fa)的全局收敛能力和增强算法的鲁棒性,将标准萤火虫算法(fa)改进为一种变步长的萤火虫算法(nfa);
2)利用改进的萤火虫算法(nfa)优化bp神经网络的训练,主要步骤如下:
a.根据输入样本和输出要求确定神经网络结构;
b.初始化bp神经网络,确定每层维数,计算权值和阈值个数;
c.将权值和阈值视为萤火虫个体,萤火虫个体编码长度等于一个网络权值和阈值的个数和,每个萤火虫个体包含了一个网络全部的权值和阈值信息,初始化萤火虫算法参数;
d.进入改进的萤火虫算法迭代更新过程,改进的萤火虫算法nfa的适应度函数选为bp神经网络目标函数,搜索适应度最优的个体;
e.将最优个体传回bp神经网络进行训练并用测试数据进行验证,获得nfa-bp神经网络模型。
在上述技术方案的基础上,改进的萤火虫算法(newfireflyalgorithm)算法设计如下:
1)对标准萤火虫算法做了萤火虫位置更新步长方面的改进,其步长设置如下式:
其中,num表示当前迭代次数,αmin为最小的步长,其取值范围为[0,1],xgbest(num)是目前为止全局最优位置,xi,best(num)为第i个萤火虫目前为止求出的最优位置,另外式中的max_iter表示算法运行的最大迭代次数,该改进算法的思想是:在算法执行期间,每一次迭代都要为每个萤火虫更新步长,更新的依据是考虑每个萤火虫直到目前搜索到的最优位置,以及目前为止搜索到的全局最优位置。
2)改进后的萤火虫算法步骤为:
step1:初始化萤火虫种群{x1,x2,……,xn},以及算法相关参数;
step2:计算每个萤火虫的亮度{l1,l2,……,ln};
step3:根据式(4)更新每个萤火虫的步长值;
step4:更新解空间;
step5:如果已到最大迭代次数(或是达到bp神经网络目标函数的最小值)则结束算法,否则转向step2。
在上述技术方案的基础上,步骤6人工调整在线排产调度的偏差并适时调整调度知识库,即更新调度参数集,另外智能调度模块进行在线优化学习,这主要包括:
1)人工对智能调度模块输出不符合实际作业车间生产情况的调度规则予以及时在模块调度规则集candidate-schedulerule-set中更换成更合适的新调度规则;
2)人工对智能调度模块关键生产状态参数集key-workinfo-set中对实际作业车间生产调度无显著波动影响的参数予以替换成实际影响更为重要的车间状态参数;
3)人工对智能调度模块输出的不满足当前生产作业需求的调度规则予以及时调整优化;
4)在经人工调整得出最优调度规则后,智能调度模块基于mes数据api提供的当前关键生产状态数据进行在线学习,优化、更新nfa-bp神经网络的权值、阈值。
在上述技术方案的基础上,步骤7中适应了真实车间生产状况的智能调度模块根据当前作业冲突决策点对应的生产状态参数进而输出最优调度规则,其中作业冲突决策点是指:
1)在同一时刻,当一个工件能选择的加工设备数x>=2的时间点tx;
2)在同一时刻,当一台设备能选择的待加工工件数y>=2的时间点ty;
3)其他作业车间突发事件(设备发生故障,紧急插单,追加订单等)发生的时间点to。
与现有技术相比本发明的有益效果如下:
1.本发明提供的基于生产数据(车间状态参数数据)驱动的动态作业车间调度规则智能选择方法,实际排产调度时有着较低的计算时间复杂度,而且输出的调度规则综合考虑了实际车间作业状态,能够随着生产时间的推移自适应地调整车间的调度规则,对车间变化了的调度请求,动态响应及时准确,调度结果更优,相较于传统人工排产调度的凭经验低效率执行车间调度工作,往往造成调度方案不能及时响应加工任务请求和难以充分利用车间的生产资源造成生产的严重浪费,本发明提供方法相较人工排产调度更科学更高效;相较于一般智能排产调度算法(遗传算法、蚁群算法等)计算时间复杂度高,且只适应于静态作业车间调度,无法满足生产规模大车间状态复杂多变的调度情况,本发明的方法可很好地适用于大规模、动态车间调度任务。
2.本发明所提供的基于生产数据(车间状态参数数据)驱动的动态作业车间调度规则智能选择方法,相较于一般的基于专家系统的作业车间调度规则选择方法,创新之处在于结合了影响作业调度相关的生产数据用以客观、准确地指导实际调度,而专家系统多建立在领域内专家经验基础之上,多存在主观性强、决策依赖部分属性、多源知识冲突和知识滞后等问题。
3.本发明所提供的基于生产数据(车间状态参数数据)驱动的动态作业车间调度规则智能选择方法,相较于单一调度目标固定调度规则的作业车间调度方法能根据车间实际调度需求转换不同调度目标下的nfa-bp神经网络进行相应调度规则的智能输出,调度规则的自适应性方面大大优于单一调度目标固定调度规则的调度方法。
4.本发明所提供的基于生产数据(车间状态参数数据)驱动的动态作业车间调度规则智能选择方法,其中对于调度知识(生产状态参数集数据和调度规则集数据)进行学习的bp神经网络采用了考虑最优位置变步长的萤火虫算法进行训练优化,可以很好地改善一般bp神经网络学习速度慢、收敛易陷于局部最优解、预测误差大的问题,可提高bp神经网络的学习效率和预测精度。
5.本发明所提供的基于生产数据(车间状态参数数据)驱动的动态作业车间调度规则智能选择方法,其中采用基于multi-pass算法仿真技术搭建的作业车间生产系统仿真平台可以方便、快捷生成不同规模job-shopscheduling问题的生产作业状态数据和相应的最优调度规则数据,这些数据即作为不同调度目标下nfa-bp神经网络进行调度知识学习的样本数据,相较于一般采用遗传算法等智能算法求解多种基准作业车间调度问题的最优调度方案然后组成神经网络的离线训练数据或是依据调度模型运用启发式规则和从实际调度案例数据中获取训练数据而言本发明采用的样本训练数据获取方法不仅方便、快捷,更能保证样本数据与调度问题的相关性。
附图说明
图1为本发明实施例中生产数据驱动的动态作业车间调度规则智能选择方法的流程图;
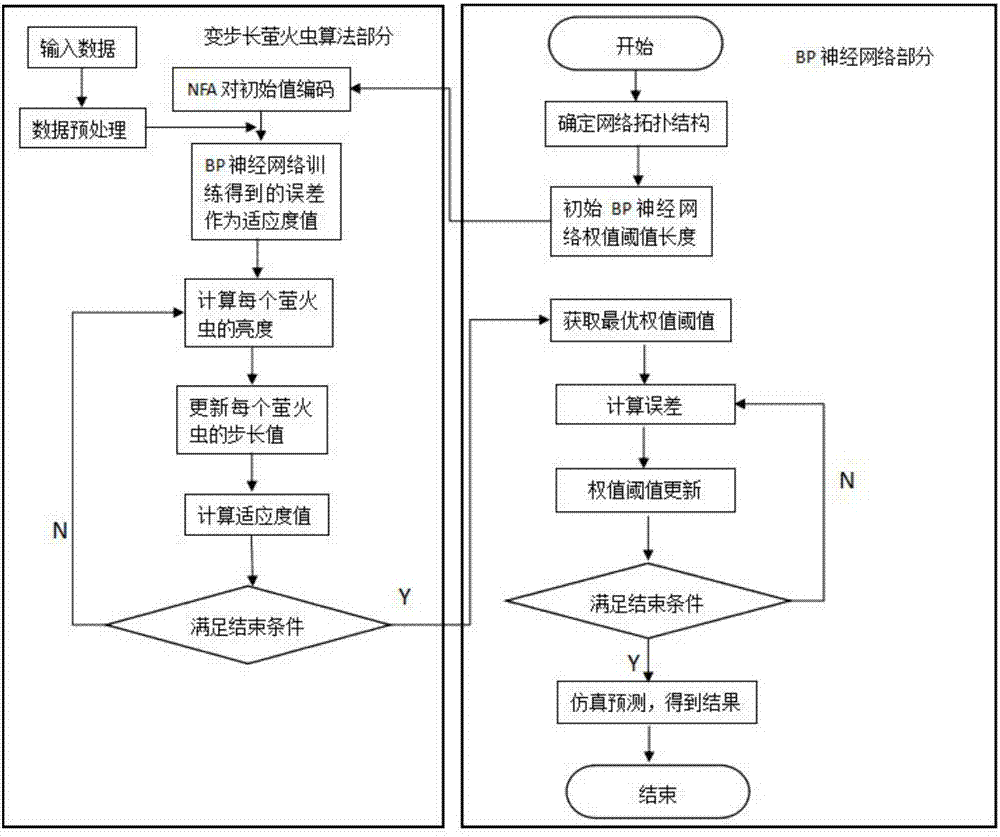
图2为改进的萤火虫算法优化训练bp神经网络的算法流程图;
图3为设计的基于某调度目标的双隐层四层前向bp神经网络结构图。
具体实施方式
下面结合附图及具体实施例对本发明做进一步的详细描述。
参见图1,本发明提供的一种生产数据驱动的动态作业车间调度规则智能选择方法具体实施流程包括:
步骤1:基于multi-pass算法仿真技术建立作业车间生产调度仿真平台,其中包括预置调度目标集、调度规则集和生产状态参数集,多次运行该仿真平台生成一批调度问题对应的最优调度方案集,其中包括了用于调度知识学习的样本数据集;
步骤2:对获得的样本数据集进行约简和筛选处理,形成调度参数集,其中包括关键生产状态参数集和候选调度规则集,关键生产状态参数集定义了mes要采集的车间状态数据,而关键生产状态参数集和候选调度规则集则定义了调度知识库;
步骤3:设计不同调度目标下用于调度知识学习的bp神经网络模型;
步骤4:提出一种改进的萤火虫算法优化bp神经网络模型的训练,获得nfa-bp模型;
步骤5:将各调度目标下的nfa-bp模型集合成一个智能调度模块,并与作业车间mes系统进行集成,由mes数据api提供当前作业车间关键生产状态数据给智能调度模块,用以指导在线排产调度;
步骤6:人工调整在线排产调度的偏差并适时调整调度知识库,即更新调度参数集,另外智能调度模块进行在线优化学习;
步骤7:适应了真实车间生产状况的智能调度模块根据当前作业冲突决策点输出最优调度规则。
实施例:
阶段一,样本数据的获取。作业车间调度的仿真模型以经典的ft10(mt10)问题为例,其规模为10*10,即包含10种工件,10台加工设备,有确定的工件加工时间信息和加工路径信息。基于multi-pass仿真技术建立作业车间生产调度仿真平台,可以通过例如西门子的专业生产系统仿真软件siemenstecnomatixplantsimulation11tr3实现,该仿真平台以基于ft10的作业车间调度为模型参数输入,以模型初始化与订单信息、实验控制等多个模块作为控制参数输入,并使用simtalk语言等软件模块实现多种调度规则,仿真平台分为五大部分:作业车间调度模型、模型初始化与订单信息管理、调度规则实现、工件流动控制和实验控制与输出,其中实验控制及输出模块主要功能是实现multi-pass过程和控制仿真实验,显示仿真实验的运行状态,记录作业车间的生产线状态和最优调度规则结果。在仿真平台中预置的调度规则集schedulerule-set={fifo、spt、sio、srpt、cr、ds、edd、mdd、mod},调度目标集scheduleperformance-set={meft、meta、nt、makespan},生产状态参数数25个,譬如有nj在制品数量、meum设备利用率平均值……sdtd工件交货期标准差等生产状态参数共25个。通过运行基于multi-pass的作业车间调度仿真平台,可以得到期望的多组样本数据,每组样本数据包含调度目标信息p、生产状态参数数据ai、调度规则信息rule,如图1所示。
阶段二,样本数据处理。对通过作业车间调度仿真平台获得的样本数据集进行约简和筛选处理,这主要包括:
对workinfo-set中的生产状态参数进行基于重要性比较的筛选处理后形成关键生产状态参数集key-workinfo-set,其中具体操作为a.对状态参数做归一化处理—b.求各个状态参数的重要性权重—c设置权重阈值θ,选取权重大于θ的状态参数进而获得关键生产状态参数集key-workinfo-set,并用主成分分析法检验阈值设置的合理性,其中求各个状态参数的重要性权重通过以下算式计算获得:
公式说明:
2)对schedulerule-set中的调度规则进行性能评价,剔除性能较差的调度规则后形成候选规则集candidate-schedulerule-set,其中具体通过以下准则进行调度规则性能评价:
a.基于工件流经时间方差准则,评价计算式为下式:
b.基于工件交货期拖期时间方差准则,评价计算式为下式:
其中,fi表示工件i的流经时间,即工件加工的生命周期;ti表示工件i的拖期时间,j表示工件数,i=1,2…j。
例如通过上述参数数据约简、筛选方法,可将原本在调度目标makespan下的25个生产状态参数进一步精减为8个对调度有显著影响的关键生产状态参数,故形成该调度目标下的关键生产状态参数集key-workinfo-set_p1={mist,mest,sdst,maso,meso,sdso,mitd,metd},应用同样的方法可得其他调度目标下的关键生产状态参数集key-workinfo-set_pk,另外利用调度规则性能评价准则可剔除预置调度规则集中性能较差的调度规则,形成作业调度的候选规则集candidate-schedulerule-set。
阶段三,调度规则智能选择。首先设计和建立不同调度目标下用于调度知识学习的bp神经网络模型,如图3所示,其主要包括:
1)设计bp神经网络模型为一个双隐藏层的四层前馈网络结构;
2)神经网络输入层的维数根据不同调度目标下的关键生产状态参数集key-workinfo-set中元素个数n确定;
3)神经网络输出层的维数根据训练样本中候选调度规则集candidate-schedulerule-set中元素个数m确定,输出值为"0"或"1",值为"1"表示该调度规则为当前调度时刻的最优调度规则,值为"0"则不是,显然任何情况下只允许输出值集合有且只有一个"1",并与candidate-schedulerule-set元素进行一一映射可得所选择的调度规则;
4)神经网络隐藏层维数通过多次仿真确定,且保持前一隐藏层的维数大于后一层的维数,具体策略参见前述说明书相应内容;
5)神经网络训练算法采用改进的萤火虫算法(newfireflyalgorithm),神经网络的权和阈值的初值由改进的萤火虫算法(nfa)初始化确定;
6)神经网络学习常数设置为η=0.05;
7)神经网络目标函数选为交叉熵函数,不要求样本具有正态分布特性,其为适用于不平衡样本的分类目标函数;
8)神经网络隐藏层和输出层的传递函数(激活函数)选为单极性的sigmoid函数,其函数值域为[0,1].
关于上述bp神经网络模型的训练(调度知识学习)通过改进的变步长萤火虫算法(newfireflyalgorithm)来优化获得nfa-bp神经网络模型,其算法流程如图2所示,这主要包括:
1)为提高萤火虫算法(fa)的全局收敛能力和增强算法的鲁棒性,将标准萤火虫算法(fa)改进为一种变步长的萤火虫算法(nfa),关于萤火虫算法的改进及其算法流程参见前述说明书相应内容;
2)利用改进的萤火虫算法(nfa)优化bp神经网络的训练,主要步骤如下:
a.根据输入样本和输出要求确定神经网络结构;
b.初始化bp神经网络,确定每层维数,计算权值和阈值个数;
c.将权值和阈值视为萤火虫个体,萤火虫个体编码长度等于一个网络权值和阈值的个数和,每个萤火虫个体包含了一个网络全部的权值和阈值信息,初始化萤火虫算法参数;
d.进入改进萤火虫算法迭代更新过程,搜索适应度最优(nfa的适应度函数选为bp神经网络目标函数)的个体;
e.将最优个体传回bp神经网络进行训练并用测试数据进行验证,获得nfa-bp神经网络模型。
在获得不同调度目标下nfa-bp神经网络模型后,将各调度目标下的nfa-bp神经网络模型集合成一个智能调度模块,并与作业车间mes系统进行集成,指导在线调度;同时人工调整在线排产调度的偏差并适时调整调度知识库,即更新调度参数集,另外智能调度模块进行在线优化学习,这主要包括:1)人工对智能调度模块输出不符合实际作业车间生产情况的调度规则予以及时在模块调度规则集candidate-schedulerule-set中更换成更合适的新调度规则;2)人工对智能调度模块关键生产状态参数集key-workinfo-set中对实际作业车间生产调度无波动影响的参数予以替换成实际影响更为重要的车间状态参数;3)人工对智能调度模块输出的不满足当前生产作业需求的调度规则予以及时调整优化;4)在经人工调整得出最优调度规则后,智能调度模块基于mes数据api提供的当前关键生产状态数据进行在线学习,优化、更新nfa-bp神经网络的权值、阈值。
经过一定时间在线运行和学习优化后,适应了真实车间生产状况的智能调度模块根据车间制造执行系统mes的数据api提供的当前作业冲突决策点对应的关键生产状态参数值进而输出最优调度规则,其中作业冲突决策点是指:
1)在同一时刻,当一个工件能选择的加工设备数x>=2的时间点tx;
2)在同一时刻,当一台设备能选择的待加工工件数y>=2的时间点ty;
3)其他作业车间突发事件(设备发生故障,紧急插单,追加订单等)发生的时间点to。
本领域的技术人员可以对本发明实施例进行各种修改和变型,倘若这些修改和变型在本发明权利要求及其等同技术的范围之内,则这些修改和变型也在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种新的解决作业车间调度问题的排产算法的制造方法与工艺
- 一种基于帝国主义竞争的算法解决车间工人调度问题的制造方法与工艺
- 一种改进的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种求解并行机作业车间调度的混合启发式转移瓶颈算法的制造方法与工艺
- 针对多目标柔性作业车间调度问题的含救济算子的混合遗传算法的制造方法与工艺
- 一种解决作业车间调度问题的排产算法的制造方法与工艺
- 一种改良的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种解决作业车间多个订单交付周期存在冲突问题的算法的制造方法与工艺
- 一种求解多工艺路线作业车间调度的分层优化算法的制造方法与工艺
- 一种混合粒子群禁忌搜索算法求解作业车间调度问题的制造方法与工艺
- 一种改进的布谷鸟搜索算法解决作业车间调度问题的制造方法与工艺
- 针对作业车间生产问题的排产算法的制造方法与工艺
- 一种新的解决作业车间调度问题的排产算法的制造方法与工艺
- 一种基于帝国主义竞争的算法解决车间工人调度问题的制造方法与工艺
- 一种改进的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种求解并行机作业车间调度的混合启发式转移瓶颈算法的制造方法与工艺
- 针对多目标柔性作业车间调度问题的含救济算子的混合遗传算法的制造方法与工艺
- 一种解决作业车间调度问题的排产算法的制造方法与工艺
- 一种改良的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种解决作业车间多个订单交付周期存在冲突问题的算法的制造方法与工艺
- 针对作业车间生产问题的排产算法的制造方法与工艺
- 一种新的解决作业车间调度问题的排产算法的制造方法与工艺
- 一种基于帝国主义竞争的算法解决车间工人调度问题的制造方法与工艺
- 一种改进的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种求解并行机作业车间调度的混合启发式转移瓶颈算法的制造方法与工艺
- 针对多目标柔性作业车间调度问题的含救济算子的混合遗传算法的制造方法与工艺
- 一种解决作业车间调度问题的排产算法的制造方法与工艺
- 一种改良的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种解决作业车间多个订单交付周期存在冲突问题的算法的制造方法与工艺
- 一种求解多工艺路线作业车间调度的分层优化算法的制造方法与工艺