基于深度学习的图像检索方法及装置与流程
本发明涉及计算机技术领域,具体涉及基于深度学习的图像检索方法及装置。
背景技术:
以往用户往往基于文字进行相关内容的检索,但随着大数据时代的到来,互联网图像资源的迅猛增长,人们对图像对检索方式提出了更高的要求,如何在大规模的图像资源中快速有效地检索到用户需要的图像是目前亟需解决的关键问题,尤其是在网络购物、商标检索、外观专利检索邻域,基于图像的检索显得尤为重要。
以商标为例,我国商标申请量呈逐年增长趋势,截至2016年全国商标申请量达352万件。商标近似查询量是由商标申请量决定,随着申请量的增长,全国对商标近似查询需求也呈同样的增长趋势。但是,整体看我国商标申请通过率不高,商标局2015年全年共审查商标2338966件,其中驳回883650件(包含整体驳回和部分驳回),驳回率达到38%,如此高的驳回率高表明行业在商标近似判断环节存在较大提升空间。现有的商标检索方法大多通过文字检索来比较相似案例,检索效率低,漏检情况严重。
现有的图像检索方法大多通过如gabor滤波器、sift算法等方法提取图像的特征,通过特征间的距离来进行相似度的比较。这些方法运算量大且耗时较长,检索效率低。
技术实现要素:
针对现有技术中的缺陷,本发明提供的基于深度学习的图像检索方法及装置,提高了相似图像的检索精度和图像检索效率。
第一方面,本发明提供了一种基于深度学习的图像检索方法,包括:
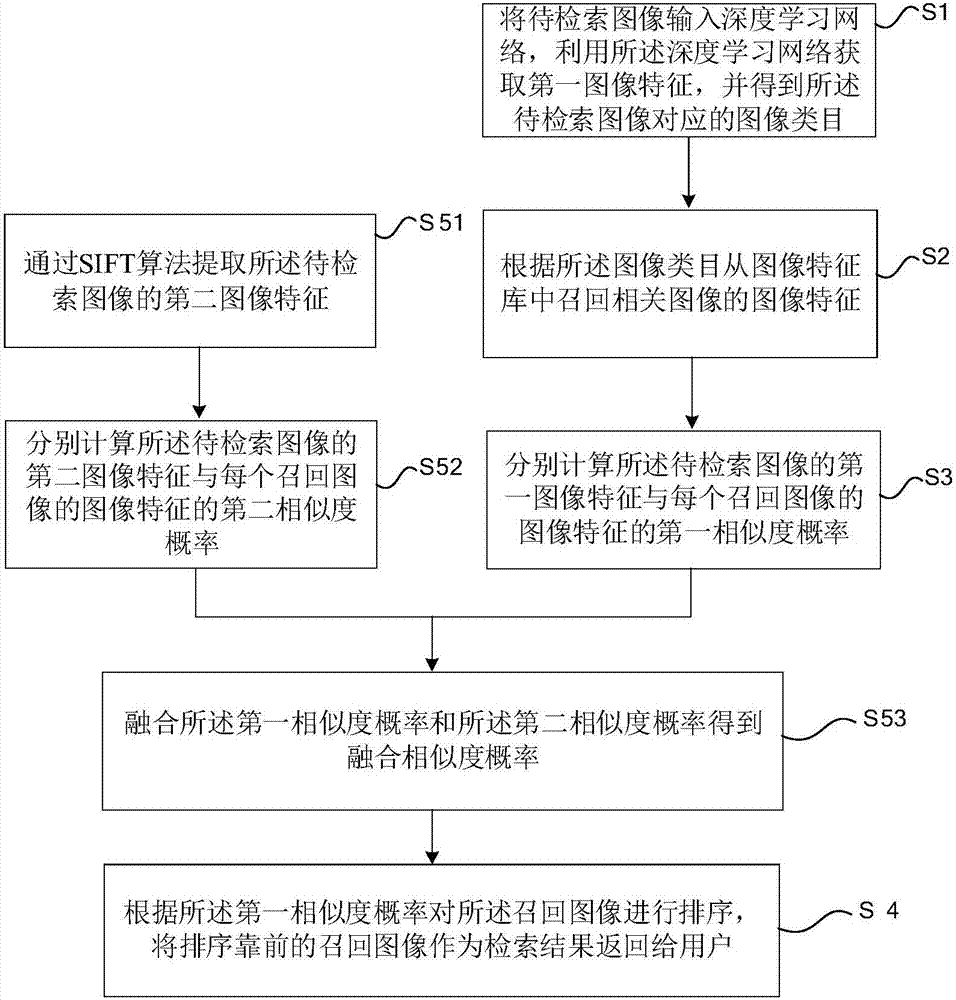
将待检索图像输入深度学习网络,利用所述深度学习网络获取第一图像特征,并得到所述待检索图像对应的图像类目;
根据所述图像类目从图像特征库中召回相关图像的图像特征;
分别计算所述待检索图像的第一图像特征与每个召回图像的图像特征的第一相似度概率;
根据所述第一相似度概率对所述召回图像进行排序,将排序靠前的召回图像作为检索结果返回给用户。
优选地,还包括:
通过sift算法提取所述待检索图像的第二图像特征,
分别计算所述待检索图像的第二图像特征与每个召回图像的图像特征的第二相似度概率,
融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率;
所述根据所述第一相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果,包括:
根据所述融合相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果。
优选地,所述融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率,包括:
自适应动态调整融合权重;
根据所述融合权重融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率。
优选地,所述自适应动态调整融合权重包括:
根据所述召回图像的图像质量和所述图像特征库中所述图像类目下的图像数量调整融合权重。
优选地,所述深度学习网络的输出层为smv。
优选地,所述根据所述第一相似度概率对所述召回图像进行排序,将排序靠前的召回图像作为检索结果返回给用户,包括:
根据所述第一相似度概率对所述召回图像进行排序;
利用排序模型优化排序结果,其中,所述排序模型通过机器学习方法训练得到;
将排序靠前的召回图像作为检索结果返回给用户。
优选地,还包括:
根据用户对所述检索结果的点击情况,对所述检索结果中的图像进行标注;
将标注后的图像作为样本,利用机器学习方法优化所述排序模型。
优选地,还包括:
获取新增的图像,将新增图像输入所述深度学习网络,得到所述新增图像的图像特征存入所述图像特征库。
第二方面,本发明提供了一种基于深度学习的图像检索装置,包括:
图像处理模块,用于将待检索图像输入深度学习网络,利用所述深度学习网络获取第一图像特征,并得到所述待检索图像对应的图像类目;
图像召回模块,用于根据所述图像类目从图像特征库中召回相关图像的图像特征;
相似度计算模块,用于分别计算所述待检索图像的第一图像特征与每个召回图像的图像特征的第一相似度概率;
图像排序模块,用于根据所述第一相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果。
第三方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面中任一所述的方法。
本发明提供的基于深度学习的图像检索方法及装置,利用深度学习网络提取图像特征计算图像之间的相似度,泛化能力强,图像之间的相似度更高,有助于提高相似图像的检索精度;利用预先训练的深度学习网络对待检索图像进行分类,减少图像召回的数量,降低了需要比对计算的图像数量,大大提高了图像检索效率,实现了在线实时搜索查询图像的功能。
附图说明
图1为本发明实施例所提供的一种基于深度学习的图像检索方法的流程图;
图2为本发明实施例所提供的一种基于深度学习的图像检索方法的优选实施例的流程图;
图3为本发明实施例所提供的一种基于深度学习的图像检索装置的结构框图;
图4为为本发明实施例所提供的一种基于深度学习的图像检索装置的优选实施例的结构框图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只是作为示例,而不能以此来限制本发明的保护范围。
需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
如图1所示,本实施例提供了一种基于深度学习的图像检索方法,包括:
步骤s1,将待检索图像输入深度学习网络,利用所述深度学习网络获取第一图像特征,并得到所述待检索图像对应的图像类目。
其中,第一图像特征包括但不限于图像的形状、纹理、颜色等。
其中,图像类目是人为根据图像的自然相似性归类得到的,例如图像类目可以包括人、植物、动物、工具、山、水果等等。
其中,输入的深度学习网络的待检索图像格式为224×224×3的图像像素,对于不满足输入格式的图像可以做格式转换的预处理。输出的第一图像特征为一个一维向量,包括4096个特征数字编码。
步骤s2,根据所述图像类目从图像特征库中召回相关图像的图像特征。
其中,图像特征库中包括图像以及每幅图像对应的图像特征,每幅图像均标记有其对应的图像类目。为了方便图像的检索和召回,同一类目的图像存储在同一地址中。
其中,图像特征库中图像的图像特征可以通过预先训练的深度学习网络提取。
其中,根据获得的图像类目生成布尔检索模型来进行图像的召回。当然在具体应用时,也可以根据具体应用的需求获取图像的其它属性,结合其它属性和图像类目生成布尔检索模型来进行图像的召回,例如,在商标图像的检索过程中,每个商标图像会有对应的商标分类和商标状态等信息(即图像的其它属性),可以从商标分类、商标状态等信息中选择一个或多个属性,结合商标图像的图像类目生成布尔检索模型。
步骤s3,分别计算所述待检索图像的第一图像特征与每个召回图像的图像特征的第一相似度概率。
其中,第一图像特征和图像特征通过向量的形式表示,第一相似度概率可以是第一图像特征与图像特征的相似度距离,通过欧式距离公式计算得到,具体计算方法为现有技术,在此不再赘述。
步骤s4,根据所述第一相似度概率对所述召回图像进行排序,将排序靠前的召回图像作为检索结果返回给用户。
两个图像的相似度概率越大,两个图像越相似。将相似度概率较大的图像返回给用户,供用户查看哪些是与待检索图像相同或相似的图像。
深度学习的本质是通过多层非线性变换,从大数据中自动学习特征,深层的结构使其具有极强的表达能力和学习能力,擅长提取复杂的全局特征和上下文信息,深度学习还有一个优势就是特征的综合表述,高层抽象和特征分级能力。因此,本实施例提供的基于深度学习的图像检索方法,利用深度学习网络提取图像特征计算图像之间的相似度,泛化能力强,图像之间的相似度更高,有助于提高相似图像的检索精度。
另外,本实施例提供的基于深度学习的图像检索方法,利用预先训练的深度学习网络对待检索图像进行分类,减少图像召回的数量,降低了需要比对计算的图像数量,大大提高了图像检索速度,实现了线上实时搜索查询图像的功能。
优选地,上述实施例中的深度学习网络包括以下三种网络架构:vggnet,resnet和inceptionv3。对上述三种网络架构的深度学习算法分别进行封装,在使用本实施的方法时,根据实际需求从上述三种深度学习网络中选择一种进行计算。当优先考虑计算速度时选用vggnet,当优先考虑检索精度时选用resnet,当综合考虑计算速度和检索精度时选用inceptionv3。针对图像特征提取,封装了三种独立的算法,使得系统可以根据用户实际需求方便快捷地选择一种较为合适的算法。
其中,深度学习网络的输出层为smv,通过输出层smv输出图像的图像类目。
其中,深度学习网络的包含fc7层,通过fc7层提取图形近似度特征。
其中,深度学习网络通过以下方法训练得到:
步骤s101,采集大量的图像并根据图像中的内容标注图像类目,将标注后的图像作为训练样本,形成训练集;
步骤s102,将训练集中的图像输入预先架构好的深度学习网络,利用深度学习网络获取输入图像的图像特征和预测的图像类目;
步骤s103,将预测的图像类目与标注的图像类目进行比对,调整深度学习网络的内部参数。其中,参数的具体调节方法为深度学习常用的方法,在此不再赘述。
步骤s104,重复步骤步骤s102和步骤s103,直到训练的深度学习网络满足预测图像类目的准确率。其中,可以将采集的图像中的部分图像作为测试集,用于对深度学习网络进行测试,检测其是否达到要求。
通过训练好的深度学习网络提取训练集中图像的图像特征,并将图像、图像特征和图像类目关联存入图像特征库。
对于新增到图像特征库中的图像,将新增图像输入所述深度学习网络,得到新增图像的图像特征和图像类目,将新增图像、图像特征和图像类目关联存储到图像特征库中。用机器标注的方式代替人工标注的方式,主要是提升效率。
如图2所示,在上述任一方法实施例的基础上,本实施例提供的基于深度学习的图像检索方法,在步骤s4之前还包括:
步骤s51,通过sift算法提取所述待检索图像的第二图像特征。
步骤s52,分别计算所述待检索图像的第二图像特征与每个召回图像的图像特征的第二相似度概率。
步骤s53,融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率;
相应的,所述步骤s4的优选实施例方式包括:根据所述融合相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果。
其中,所述步骤s53的优选实施方式包括:
步骤s531,自适应动态调整融合权重。具体为:根据所述召回图像的图像质量和所述图像特征库中所述图像类目下的图像数量调整融合权重。其中,自适应的动态调节融合权重,公式如下:
α=q·n
其中,α为融合权重,q代表图像质量(主要是图像清晰度),n为某一图像类目在图像特征库中的图像数量。计算图像质量的方法为现有技术,在此不再赘述。
步骤s532,根据所述融合权重融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率,具体融合公式为:
pmix=(1-α)psift+αpdnn
其中,pmix为融合相似度概率,pdnn为第一相似度概率,psift为第二相似度概率。
由于深度学习网络需要通过大量的样本图像进行训练才可以保证提取精度,因此,在对小样本图像进行特征提取时,sift特征(通过sift算法提取的图像特征)要优于dnn特征(通过深度学习网络提取的图像特征),还有在一些图像极端的情况下(如图像质量很差),sift特征的稳定性要优于dnn特征,而在样本充足且样本质量较时,dnn特征具有较高的精度且很强的泛化能力。
基于sift算法和深度学习算法各自的优劣,本实施例中,通过融合深度学习网络提取的图像特征和sift提取的图像特征,对召回图像进行排序,以降低因图像样本量的大小和图像质量的优劣带来的对排序精度的影响,提高了图像检索的准确度。在图像的样本量较少、图像质量较差的情况下,sift特征的融合权重要高于dnn特征,在图像的样本量充足、图像质量较好的情况下,dnn特征远优于sift特征,此时dnn特征的融合权重要高一些,通过自适应动态调整融合权重,进一步地提高了图像检索的准确度,同时提高了算法的普适性。
基于上述任一方法实施例,为了提高排序精度,所述步骤s4的优选实施方式包括:
步骤s41,根据所述第一相似度概率对所述召回图像进行排序;
步骤s42,利用排序模型优化排序结果,其中,所述排序模型通过机器学习方法训练得到;
其中,通过机器学习方法训练得到排序模型的方法称为学习排序(ltr,learningtorank),ltr学习排序是一种监督学习的排序方法,ltr已经被广泛应用到文本挖掘的很多领域,比如ir中排序返回的文档,推荐系统中的候选产品、用户排序,机器翻译中排序候选翻译结果等等,机器学习方法很容易融合多种特征,而且有成熟深厚的理论基础,参数是通过迭代优化出来的,有一套成熟理论解决稀疏、过拟合等问题。
步骤s43,将排序靠前的召回图像作为检索结果返回给用户。
机器识别的近似图像和人工判断的近似图形有一定的偏差,因此,基于上述方法实施例,基于深度学习的图像检索方法还包括:根据用户对所述检索结果的点击情况,对所述检索结果中的图像进行标注,将用户点击的所述检索结果中的图像标注为正样本,将用户未点击的所述检索结果中的图像标注为负样本;将标注后的图像作为样本,利用机器学习方法优化所述排序模型。
用户每一次得到检索结果后,会点击浏览检索结果中真正与待检索图像相同或相似的图片,通过用户点击情况对图片进行标注,将标注图像作为负反馈不断优化排序模型,提高了排序准确度,使得反馈给用户的图片更加接近用户的检索目标。另外,利用真实用户的点击操作实现排序模型的优化,在使用过程中获取大量的样本数据,大大降低了模型优化的成本和人力投入。
一幅图像通过深度学习网络,可以输出多个可能的图像类目,其输出按概率大小进行排列。通过步骤s1预测的图像类目越多,图像召回的精度就越高。但是,在图像相似度环节需要计算的时间就很长,当检索服务超过2秒时,用户体验就会变差。因此,在兼顾检索精度的基础上要考虑检索的速度。考虑到性能和准确度的平衡,图像类目的预测数目采取动态调整的策略,不仅减少预测数目,还有扩大预测数目,以达到性能和精度的平衡。本实施例中,所述步骤s2,包括:选取输出概率最大的图像类目进行图像召回,若图像特征库中,该图像类目下的图像数量小于预设的th1时,则选取输出概率第二的图像类目进行图像召回,若此时召回图像的数量依然小于th1,则继续选取输出概率第二的图像类目进行图像召回,依次类推增加召回的图像类目,直到召回图像的数量大于th1,若此时,召回的图像数量大于预设的th2时,则从召回图像中删除输出概率最小的图像类目;确定好需要召回的图像类目,从图像特征库中召回相关图像的图像特征。其中,th1的优选值为为100000,th2的优选值为250000。
本实施例提供的基于深度学习的图像检索方法可以各种图像检索领域,如相似网络商品的检索,相似外观专利的检索,相似商标的检索。下面以检索商标图像为例子,使用上述实施方法进行商标图像检索的步骤包括:用户上传一张商标图像后,调用图形识别服务获取图形的要素与特征,用图形的要素加商标的属性进行召回,按照提取的图形特征与索引里原有图形特征进行相似度计算,返回最相似的图形商标。
步骤s10,将待检索图像输入深度学习网络,利用所述深度学习网络获取第一图像特征,并得到所述待检索图像对应的图像类目。
其中,待检索图像是用户上传一张商标图像。
其中,商标图像的图像类目由商标局确定。
其中,商标图像周边空白一般较大,用户上传图像后,裁减图像空白前、后,发现搜索出来的图像不一样,用户认为这些白边是无用的信息,应该返回相同的搜索结果。但是虽然白边是无用的信息,但是这些特征里面还有空间位置信息。目前同一张图片因为人为裁剪的尺寸不同(空白区域面积不同),在主体相同的情况下出现搜索结果大幅波动。因此,本实施例的方法中还包括对商标图像的预处理:在将图像特征存入图像特征库的时候自动去掉白边,同时搜索的时候自动去掉这些白边,这样不但不同裁剪方式可以返回相同的搜索结果,同时只对商标主体计算特征,会同时提高搜索近似度。
步骤s20,根据所述图像类目从图像特征库中召回相关图像的图像特征。
其中,图像特征库中包括每幅商标图像对应的图像特征,每幅商标图像的图像特征均标记有其对应的图像类目。为了方便商标图像的检索和召回,同一类目的图像存储在同一地址中。
除了图像特征库以外,还预先构建了一个与图像特征库关联的商标信息数据库,用于存储每个商标的信息,包括商标图像、商标类别、法律状态等一系列信息。图像特征库中每个商标都有唯一标识码,图像特征库中商标对应的图像特征也标记有相应的唯一标识码。
其中,图像特征库中的商标图像的图像特征可以通过预先训练的深度学习网络提取。
其中,根据获得的图像类目生成布尔检索模型来进行商标图像的召回。每个商标图像会有对应的商标分类(由商标局确定)和商标状态等信息,可以从商标分类、商标状态等信息中选择一个或多个属性,结合商标图像的图像类目生成布尔检索模型,以达到进一步缩小召回范围的目的。
步骤s30,分别计算所述待检索图像的第一图像特征与每个召回图像的图像特征的第一相似度概率。
步骤s40,根据所述第一相似度概率对所述召回图像进行排序,将排序靠前的召回图像作为检索结果返回给用户。
其中,获取召回图像的唯一标识码,然后在商标信息数据库中找到唯一标识码对应的商标信息返回给用户,供用户查看哪些是与待检索的商标图像相同或相似的商标图像,并且客户可以浏览该商标的相关信息。
本实施例提供的商标图像检索方法,利用深度学习网络提取图像特征计算图像之间的相似度,泛化能力强,商标图像之间的相似度更高,有助于提高相似商标图像的检索精度。
另外,本实施例提供的商标图像检索方法,利用预先训练的深度学习网络对待检索图像进行分类,减少图像召回的数量,降低了需要比对计算的图像数量,大大提高了商标图像检索速度,实现了线上实时搜索查询商标图像的功能。
优选地,上述实施例中的深度学习网络包括以下三种网络架构:vggnet,resnet和inceptionv3。对上述三种网络架构的深度学习算法分别进行封装,在使用本实施的方法时,根据实际需求从上述三种深度学习网络中选择一种进行计算。当优先考虑计算速度时选用vggnet,当优先考虑检索精度时选用resnet,当综合考虑计算速度和检索精度时选用inceptionv3。针对图像特征提取,封装了三种独立的算法,使得系统可以根据用户实际需求方便快捷地选择一种较为合适的算法。
其中,深度学习网络通过以下方法训练得到:
步骤s101,采集大量的图像并根据图像中的内容标注图像类目,将标注后的图像作为训练样本,形成训练集;
步骤s102,将训练集中的图像输入预先架构好的深度学习网络,利用深度学习网络获取输入图像的图像特征和预测的图像类目;
步骤s103,将预测的图像类目与标注的图像类目进行比对,调整深度学习网络的内部参数。其中,参数的具体调节方法为深度学习常用的方法,在此不再赘述。
步骤s104,重复步骤步骤s102和步骤s103,直到训练的深度学习网络满足预测图像类目的准确率。其中,可以将采集的图像中的部分图像作为测试集,用于对深度学习网络进行测试,检测其是否达到要求。
通过训练好的深度学习网络提取训练集中图像的图像特征,并将图像、图像特征和图像类目关联存入图像特征库。
由于巨大的商标申请量,每年都会新增很过商标图像,为了保证新增的商标图像能够及时录入商标图像的图像特征库,对于新增到图像特征库中的图像,将新增图像输入所述深度学习网络,得到新增图像的图像特征和图像类目,将新增图像、图像特征和图像类目关联存储到图像特征库中。用机器标注的方式代替人工标注的方式,提升了商标入库的效率。商标图像有些类目的图像样本量很小,有些样本量很大。
由于深度学习网络需要通过大量的样本图像进行训练才可以保证提取精度。由于商标图像的特殊性,有些类目的商标图像有几万张,而有些类目的商标图像几十年就几张图像。因此,对于小样本量的商标类目,很难通过训练得到较好的深度学习模型,这会降低分类精度,且有些商标申请时间较早,商标的图像质量较差,无法提取较好的特征。因此,在上述任一方法实施例的基础上,本实施例提供的基于深度学习的图像检索方法,在步骤s40之前还包括:
步骤s501,通过sift算法提取所述待检索图像的第二图像特征。
步骤s502,分别计算所述待检索图像的第二图像特征与每个召回图像的图像特征的第二相似度概率。
步骤s503,融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率;
相应的,所述步骤s40的优选实施例方式包括:根据所述融合相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果。
其中,所述步骤s503的优选实施方式包括:
步骤s5031,自适应动态调整融合权重。具体为:根据所述召回图像的图像质量和所述图像特征库中所述图像类目下的图像数量调整融合权重。其中,自适应的动态调节融合权重,公式如下:
α=q·n
其中,α为融合权重,q代表图像质量(主要是图像清晰度),n为某一图像类目在图像特征库中的图像数量。计算图像质量的方法为现有技术,在此不再赘述。
步骤s5032,根据所述融合权重融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率具体融合公式为:
pmix=(1-α)psift+αpdnn
其中,pmix为融合相似度概率,pdnn为第一相似度概率,psift为第二相似度概率。
由于深度学习网络需要通过大量的样本图像进行训练才可以保证提取精度,因此,在对小样本图像进行特征提取时,sift特征(通过sift算法提取的图像特征)要优于dnn特征(通过深度学习网络提取的图像特征),还有在一些图像极端的情况下(如图像质量很差),sift特征的稳定性要优于dnn特征,而在样本充足且样本质量较时,dnn特征具有较高的精度且很强的泛化能力。
基于sift算法和深度学习算法各自的优劣,本实施例中,通过融合深度学习网络提取的图像特征和sift提取的图像特征,对召回图像进行排序,以降低因图像样本量的大小和图像质量的优劣带来的对排序精度的影响,提高了图像检索的准确度。在图像的样本量较少、图像质量较差的情况下,sift特征的融合权重要高于dnn特征,在图像的样本量充足、图像质量较好的情况下,dnn特征远优于sift特征,此时dnn特征的融合权重要高一些,通过自适应动态调整融合权重,进一步地提高了图像检索的准确度,同时提高了算法的普适性。
基于上述任一方法实施例,为了提高排序精度,所述步骤s40的优选实施方式包括:
步骤s401,根据所述第一相似度概率对所述召回图像进行排序;
步骤s402,利用排序模型优化排序结果,其中,所述排序模型通过机器学习方法训练得到;
步骤s403,将排序靠前的召回图像作为检索结果返回给用户。
机器识别的近似图像和人工判断的近似图形有一定的偏差,因此,基于上述方法实施例,基于深度学习的图像检索方法还包括:根据用户对所述检索结果的点击情况,对所述检索结果中的图像进行标注,将用户点击的所述检索结果中的图像标注为正样本,将用户未点击的所述检索结果中的图像标注为负样本;将标注后的图像作为样本,利用机器学习方法优化所述排序模型。
用户每一次得到检索结果后,会点击浏览检索结果中真正与待检索图像相同或相似的商标,通过用户点击情况对商标图片进行标注,将标注图像作为负反馈不断优化排序模型,提高了排序准确度,使得反馈给用户的图片更加接近用户的检索目标。另外,利用真实用户的点击操作实现排序模型的优化,在使用过程中获取大量的样本数据,大大降低了模型优化的成本和人力投入。
由于商标驳回样本是最权威的图形商标近似样本,且随着时间不断积累,数量会不断增加。如果能让模型不断学习驳回样本,就可以让模型的识别能力不断进化。因此,本实施例的方法还在充分利用了商标局给出的驳回商标,将驳回商标和搜索图像组成相似样本对,通过深度神经网络算法达到识别最相似图像的分类,从而提高分类和相似度的精度。
基于与上述基于深度学习的图像检索方法相同的发明构思,本实施例提供了一种基于深度学习的图像检索装置,如图3所示,包括:
图像处理模块,用于将待检索图像输入深度学习网络,利用所述深度学习网络获取第一图像特征,并对所述待检索图像进行要素预测得到图像类目;
图像召回模块,用于根据所述图像类目从图像特征库中召回相关图像的图像特征;
第一相似度计算模块,用于分别计算所述待检索图像的第一图像特征与每个召回图像的图像特征的第一相似度概率;
图像排序模块,用于根据所述第一相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果。
优选地,如图4所示,本实施例的图像检索装置还包括第二相似度计算模块和特征融合模块,其中,第二相似度计算模块用于通过sift算法提取所述待检索图像的第二图像特征,分别计算所述待检索图像的第二图像特征与每个召回图像的图像特征的第二相似度概率;所述特征融合模块用于融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率。相应的,所述图像排序模块具体用于根据所述融合相似度概率对所述召回图像进行排序,返回排序靠前的召回图像作为检索结果。
优选地,所述特征融合模块包括融合权重计算子模块和融合子模块,所述融合权重计算子模块用于自适应动态调整融合权重;所述融合子模块用于根据所述融合权重融合所述第一相似度概率和所述第二相似度概率得到融合相似度概率。
优选地,所述融合权重计算子模块具体用于:根据所述召回图像的图像质量和所述图像特征库中所述图像类目下的图像数量调整融合权重。
优选地,所述深度学习网络的输出层为smv。
优选地,所述图像排序模块包括图像排序子模块,排序优化模块和结果返回模块,所述图像排序子模块用于根据所述第一相似度概率对所述召回图像进行排序;所述排序优化模块用于利用排序模型优化排序结果,其中,所述排序模型通过机器学习方法训练得到;所述结果返回模块用于将排序靠前的召回图像作为检索结果返回给用户。
优选地,还包括点击结果统计模块和负反馈优化模块,所述点击结果统计模块用于根据用户对所述检索结果的点击情况,对所述检索结果中的图像进行标注;所述负反馈优化模块用于将标注后的图像作为样本,利用机器学习方法优化所述排序模型。
优选地,还包括图像新增模块:获取新增的图像,将新增图像输入所述深度学习网络,得到所述新增图像的图像特征存入所述图像特征库。
本实施例提供的系统与上述方法出于相同的发明构思,具有相同的有益效果,此处不再赘述。
基于与上述方法相同的发明构思,本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法实施例中任一所述的方法,其有益效果已在方法实施例中说明,在此不在赘述。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!