用于机器学习物质识别算法的通用拉曼光谱特征提取方法与流程
本发明涉及拉曼光谱,尤其是涉及用于机器学习物质识别算法的通用拉曼光谱特征提取方法。
背景技术:
拉曼光谱是以拉曼散射效应为基础的,具有分子指纹信息的振动光谱,每种物质都有区别于其他物质的独特光谱信息。因此,拉曼光谱技术可对物质进行检测分析,在材料、化学、物理、环保和生命科学等领域均有应用。目前流行的表面增强拉曼光谱(sers)技术[1]和后续发展起来的核壳隔绝纳米粒子增强拉曼光谱(shiners)技术[2],大幅度提高了拉曼光谱检测的灵敏度,降低了噪音和背景的干扰,极大地提高了拉曼检测技术的普适性和应用性。基于sers技术的拉曼光谱仪器具有灵敏度高、样品制备简单、准确度高、检测速度快、成本低和通用性强等优势,因此在痕量物质检测中表现出巨大潜力和广阔的市场前景。例如在食品安全领域中,探测水产品中是否含有孔雀石绿、牛奶中是否含有三聚氰胺和水果表面是否有农药残留等。
传统的拉曼谱图识别技术采用与标准谱图进行模板匹配的方法[3],通过相似度阈值判定样本是否含有目标物质。例如文献[4]针对纺织纤维建立各种纯组分纤维的拉曼光谱特征峰表,并将未知样品与该表进行逐一匹配并计算相似度,进而完成快速识别。文献[5]选择光谱特征峰位置上的最大小波系数作为参数,利用简单反向匹配思路计算相似度,简单高效的识别物质。文献[6]对标准品谱图进行编码,然后利用改进的字符串匹配算法将待测谱图的编码与标准编码进行匹配,根据相似度判定样品类别。这类方法通常运用于单纯体系,对未知光谱样本逐一进行物质识别;但由于相邻拉曼峰相互“淹没”的情况时有发生,往往无法保证在复杂体系中的识别效果。随着sers光谱仪器的推广和应用,在实际现场测试中产生了大量复杂体系下的拉曼光谱样本,这对拉曼谱图的分析算法提出了新需求:设计适用于拉曼谱图批量分析的通用算法,满足复杂体系下的不同目标物质的自动快速检测需求。而机器学习方法的兴起,正为拉曼谱图的大规模分析开拓新途径[7]。机器学习是一门人工智能科学,主要研究计算机程序如何随着经验积累自动提高性能。近年涌现不少优秀的机器学习方法[8],包括adaboost、支持向量机(svm)、多层神经网络和随机森林等。不少学者把拉曼谱图的物质识别(定性分析)问题转换成机器学习的分类问题,即定义若干目标物质为不同类别,然后根据已有的拉曼标准谱图来训练机器学习分类器,最后使用训练好的分类器确定待测光谱属于何种类别(识别目标物质)。例如文献[9]采用最小二乘svm模型并进行多重迭代优化,可以对分别掺入了葵花籽油、大豆油、玉米油和橄榄油的拉曼光谱检测样本进行快速准确的分类识别。支持向量机svm模型也可用于细菌样本拉曼谱图的分类和识别[10],而且基于相关核的svm模型比基于线性核的svm模型具有更好的分析能力。
机器学习分类方法对拉曼光谱进行物质识别过程中,有一个很关键的步骤:如何对拉曼光谱进行特征提取。特征提取是将拉曼谱图的数据表示成机器学习模型可以接受的数学特征(即特征向量)。如果提取的特征向量丢失了原始光谱中的重要信息,或含有大量干扰信号,将会严重影响物质分类识别结果的准确性。但是现有的特征提取算法往往针对目标物质或特定体系进行设计,未考虑空白拉曼光谱(不含目标物质的光谱样本)对物质分类识别的影响,因此通用性不强[9][10][11][12]。例如文献[11]所提取特征向量仅包含代表食用油不饱和度特征的两个特征峰相关信息,只适用于食用油的快速鉴别。
现有谱图预处理方法大多属于半自动算法,需根据仪器、样品特征和测量环境的变化来调节参数,对操作人员有较高的要求,无法支持不同目标物质光谱的批量处理。例如滑动窗口多项式法[13]利用窗口内的光谱值计算出一个新数值以替代窗口中心位置的原始光谱值,可以快捷消除噪音,但其效果依赖于窗口尺寸和多项式阶数的选择。多项式拟合方法[14][15]在多次迭代中不断消除高频的拉曼峰,进而估计光谱的荧光背景,但由于采用固定的最小二乘拟合阶数,自适应性不高。
传统的拉曼谱图识别技术采用与标准谱图进行模板匹配的方法[3],通过相似度阈值判定样本是否含有目标物质。这类方法通常运用于单纯体系,对未知光谱样本逐一进行物质识别,可以准确识别阴性样本(不含目标物质)和阳性样本(含有目标物质)。但由于相邻拉曼峰相互“淹没”的情况时有发生,往往无法保证在复杂体系中的识别效果。为了实现光谱的批量处理,多种机器学习算法[9][10]被用于对拉曼光谱进行分类和识别。它们面向特定物质的检测应用,支持样本数据量不大,但可获得较好的定性分析结果。其中采用的特征提取方法针对目标物质来设计,只选择该物质独有特性(如特征峰)构成的特征向量进行训练和预测,无法应对复杂体系下的多种目标物质的识别需求,缺乏扩展性和通用性。因此,本发明提出一种适用范围更广、效率更高的特征提取方法,以满足实际物质监测应用的需求。
现有特征提取方法[11][12]普遍采用经典的最大最小归一化算法将特征数据固定在[0,1]区间。该方法往往会丢失峰值信号的强度信息,导致提取的特征分类效果不佳。特别是当面对空白样本时,由于[0,1]特征向量无法区分低强度峰值信号和高强度峰值信号,分类器常常错误地将空白样本识别成含目标物质的样本。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提供更好的特征向量归一化算法,准确刻画空白样本的特征,使得机器学习算法可以识别阴性样本(不含目标物质)的用于机器学习物质识别算法的通用拉曼光谱特征提取方法。
本发明包括以下步骤:
1)谱图自动预处理;
在步骤1)中,所述谱图自动预处理包括消除噪音和扣除荧光背景,实际测试中,拉曼光谱样本通常以二维数据的形式表达,其中横坐标是波数,纵坐标是该波数对应的光谱信号强度。拉曼光谱样本采集往往会受到诸多因素的影响,由激光产生的荧光背景(主要因素)、由射线产生的毛刺峰和仪器的固有噪声等。为了对拉曼光谱进行准确的物质识别,必须尽可能消除这些因素的影响,使用自动的光谱预处理算法,在复杂体系下利用自适应迭代的思想扣除荧光背景,而不会使拉曼信号受到损失或者产生局部形变,所述自动的光谱预处理算法的主要流程是:
(1)搜索原始光谱数据s的局部极大值点;
(2)在相邻局部极大值点间使用插值方法,获得荧光背景的估计曲线b;
(3)更新光谱数据s=b,对步骤(1)、(2)进行循环迭代;迭代终止条件满足,即可获得荧光背景曲线b,在无人工干预的情况下,采用的谱图自动预处理方法可以准确可靠的消除复杂体系下的拉曼光谱荧光背景,处理异常数据。其效果可以媲美商用的自适应迭代最小二乘法(airpls)。
2)获取谱图的特征向量;
在步骤2)中,所述获取谱图的特征向量可采用将峰值信号处理为冲激信号,应用极大极小信号自适应缩放算法,将扣除荧光背景后的光谱的峰值信号处理为冲激信号,所述极大极小信号自适应缩放算法通过极小值和极大值来划分峰信号的范围,并采用自适应的信号缩放来减少相邻峰之间的影响;所述极大极小信号自适应缩放算法对离峰值点越远的部分进行越大的缩放,这样的做法使得最后的处理结果中,远离峰值点的峰值数据的作用减弱,突出了峰值及其附近的数据的影响,有效消除了峰值信号以外的干扰因素,具体实施方法如下:
1)使用平滑算法对光谱s-b进行平滑处理,并使用小波阈值(waveletshrinkage)消除高频白噪声。
2)在处理后的光谱数据中找出所有极小值点。相邻的两个极小值点确定一个数据段。
3)在相邻的极小值点之间寻找极大值点的位置,据此把相应数据段划分为左右两侧。
4)左侧光谱数据统一减去左侧极小值,右侧光谱数据统一减去右侧极小值。若出现左右两侧不连续的情况,需要对较高的一侧数据进行适当缩放。
5)分别对左右两侧数据进行操作以形成峰值冲激信号。假设某侧信号为{x1,x2,...,xn},其对应波数位置为{l1,l2,...,ln},并且x1是局部极大值,n是其信号个数,则更新
3)特征向量的归一化处理;
在步骤3)中,所述特征向量的归一化处理可采用固定的数学区间,使用平均归一化(让所有特征数据以0为中心)和反正切(arc-tangent)归一化将信号归一化到固定的数学区间(-1,1)。具体做法是:根据需求截取指定范围的冲激信号并保存在向量data中,记信号总数为lz;则归一化后的特征向量z的计算公式为,
本发明的归一化方式能更好地保留峰值信号信息,提升分类精度。更为重要的是,它首次准确刻画了空白样本的特征,有效避免将空白样本误判含有目标物质的现象。而现有的特征提取方法采用的经典[0,1]区间最大最小归一化方法,往往会放大空白样本的所有峰值,因此,无法准确识别空白样本。
为了在复杂体系下对拉曼谱图进行快速准确的物质分类识别,本发明提出一种适用于机器学习物质识别算法的通用拉曼光谱特征提取方法。本发明将拉曼光谱的特征表述成等长且取值范围相同的特征向量,为使用机器学习算法(如svm等)进行物质分类和识别打下良好基础。
与现有的特征提取方法相比,本发明的优点如下:
1)可以对任意指定范围的拉曼光谱进行特征提取,所提取的特征向量适用于多种机器学习算法,通用性强,不受目标物质或测试体系的限制;
2)可以自动去除噪声和荧光背景的干扰,同时保留峰值信号的位置和强度等信息;
3)可以有效识别包含各种目标物质的光谱;
4)可以准确提取空白光谱特征,有效识别和准确区分阴性和阳性样品,更好的满足物质检测的实际需求;
5)本发明的特征提取方法不涉及复杂计算,而且对存储空间需求不大,因此时间和空间复杂度低,便于运用于光谱数据的批量处理和分析。
6)采用自适应的谱图预处理方法,自动消除复杂体系下光谱样本的噪音和荧光背景(无需人工干预),为拉曼光谱的批量分析处理奠定数据基础。
7)极大极小信号自适应缩放算法首次被运用到在特征提取过程中,将峰值信号处理为冲激信号以获得谱图的特征向量。这种算法通用性好,所获得的特征向量适用于不同的机器学习分类器,并可以得到满意的物质分类识别结果。
8)首次对特征向量采用反正切归一化算法,准确刻画了空白光谱样本特征,提高目标物质识别的准确率。
附图说明
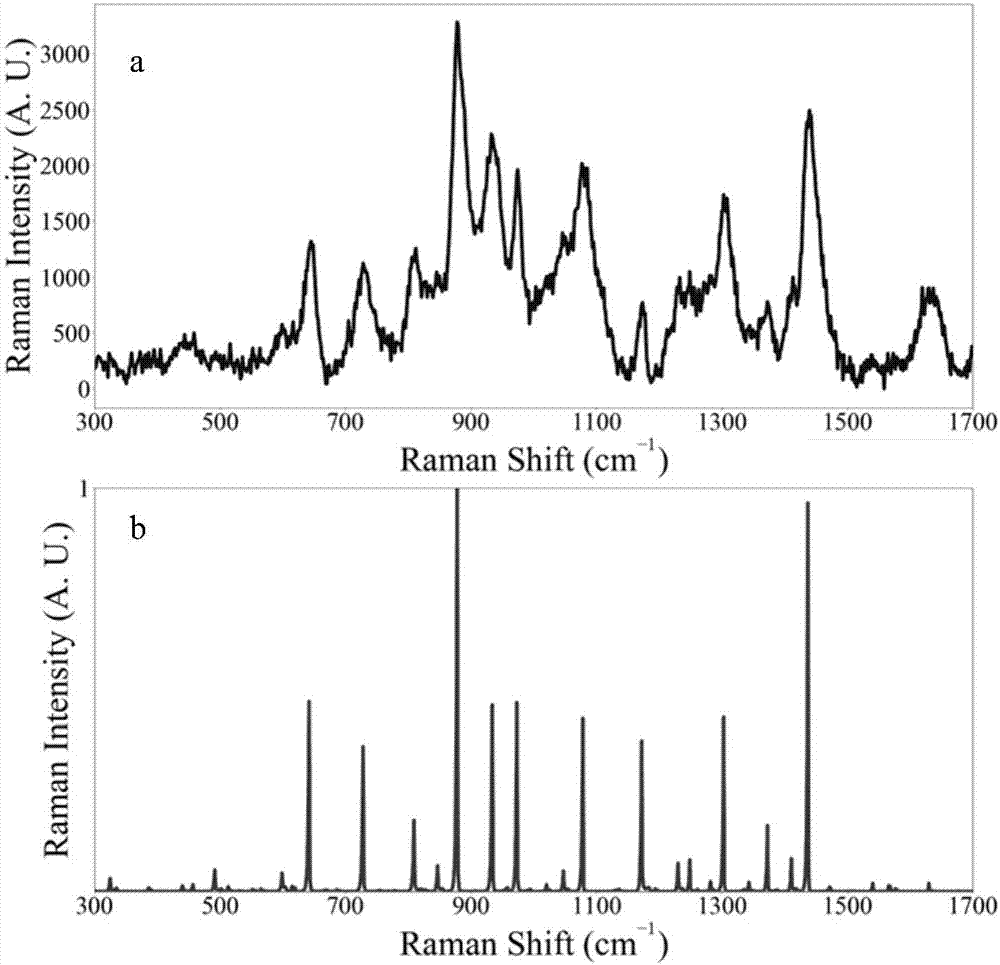
图1为本发明的特征提取方法结果示例(苋菜红的特征峰如虚线显示)。
图2为本发明采用[0,1]最大最小归一化算法(空白光谱样本的特征提取结果)。在图2中,a为blank(withoutbackground),b为feature。
图3为本发明采用[0,1]最大最小归一化算法(亮蓝光谱样本的特征提取结果)。在图3中,a为brilliantblue(withoutbackgrount),b为feature。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
本发明包括以下步骤:
第一步:谱图自动预处理:消除噪音和扣除荧光背景;
实际测试中,拉曼光谱样本通常以二维数据的形式表达,其中横坐标是波数,纵坐标是该波数对应的光谱信号强度。拉曼光谱样本采集往往会受到诸多因素的影响,例如由激光产生的荧光背景(主要因素)、由射线产生的毛刺峰和仪器的固有噪声等。为了对拉曼光谱进行准确的物质识别,必须尽可能的消除这些因素的影响。本发明使用自动的光谱预处理算法[16],在复杂体系下利用自适应迭代的思想扣除荧光背景,而不会使拉曼信号受到损失或者产生局部形变。该算法的主要流程是:
(1)搜索原始光谱数据s的局部极大值点;
(2)在相邻局部极大值点间使用插值方法,获得荧光背景的估计曲线b;
(3)更新光谱数据s=b,对步骤(1)、(2)进行循环迭代;
迭代终止条件满足,即可获得荧光背景曲线b。在无人工干预的情况下,本发明采用的谱图自动预处理方法可以准确可靠的消除复杂体系下的拉曼光谱荧光背景,处理异常数据。其效果可以媲美商用的自适应迭代最小二乘法(airpls)[17]。
第二步:获取谱图的特征向量:将峰值信号处理为冲激信号
应用极大极小信号自适应缩放算法[18],将扣除荧光背景后的光谱的峰值信号处理为冲激信号。该算法通过极小值和极大值来划分峰信号的范围,并采用自适应的信号缩放来减少相邻峰之间的影响。算法对离峰值点越远的部分进行了越大的缩放,这样的做法使得最后的处理结果中,远离峰值点的峰值数据的作用减弱,突出了峰值及其附近的数据的影响,有效消除了峰值信号以外的干扰因素。具体实施方法如下:
(1)使用平滑算法对光谱s-b进行平滑处理,并使用小波阈值(waveletshrinkage)消除高频白噪声[19][20]。
(2)在处理后的光谱数据中找出所有极小值点。相邻的两个极小值点确定一个数据段。
(3)在相邻的极小值点之间寻找极大值点的位置,据此把相应数据段划分为左右两侧。
(4)左侧光谱数据统一减去左侧极小值,右侧光谱数据统一减去右侧极小值。若出现左右两侧不连续的情况,需要对较高的一侧数据进行适当缩放。
(5)分别对左右两侧数据进行操作以形成峰值冲激信号。假设某侧信号为{x1,x2,...,xn},其对应波数位置为{l1,l2,...,ln},并且x1是局部极大值,n是其信号个数,则更新
第三步:特征向量的归一化处理:固定的数学区间
使用平均归一化(让所有特征数据以0为中心)和反正切(arc-tangent)归一化将信号归一化到固定的数学区间(-1,1)。具体做法是:根据需求截取指定范围的冲激信号并保存在向量data中,记信号总数为lz。则归一化后的特征向量z的计算公式为,
本发明的归一化方式能更好地保留峰值信号信息,提升分类精度。更为重要的是,它首次准确刻画了空白样本的特征,有效避免将空白样本误判含有目标物质的现象。而现有的特征提取方法采用的经典[0,1]区间最大最小归一化方法,往往会放大空白样本的所有峰值,因此,无法准确识别空白样本。
实验验证:
为了验证本发明的特征提取方法有效性,使用高意(photop)pt2000仪器从现场测试采集1521个拉曼光谱样本进行测试。含有11种目标物质样本(均为酸性/碱性色素)和不含任何目标物质的样本都进行了标注,光谱测试样本的列表如表1所示。
表1
首先,使用本发明的特征提取方法获得所有样本的特征向量(波数范围300cm-1到1700cm-1),选取一部分作为分类器的训练样本(标准谱图),其余部分作为待测样本(未知谱图)。然后,分别使用自适应超图分类器[21]和rbf核svm分类器[22]进行目标物质的分类识别。结果证明,两中分类方法均获得了90%以上的准确率。这说明本发明的特征提取方法适用于机器学习算法,而且可以有效识别各种目标物质及区别空白样本。
作为对比,在特征向量归一化步骤中采用[0,1]区间最大最小归一化算法,并同样使用自适应超图和svm方法进行实验。结果是,有相当一部分的空白样本被错误识别为含有某目标物质的样本,导致总体的物质识别准确率下降。其原因是[0,1]区间最大最小归一化方法丢失了峰值强度的重要信息,使得空白样本的特征向量与低浓度标准光谱的特征向量可能存在较大相似性,因此容易造成误判。在图2和3中,亮蓝样本的峰强度远远高于空白样本的峰强度,但最大最小归一化后就无法区分了。但本发明采用的反正切归一化算法,可以保留峰值强度信息(如图1所示),即原始峰越强,归一化后的值越高。因此,机器学习分类器就可以准确区分出空白样本和含目标物质的样本。
满足复杂体系下拉曼谱图的预处理需求:采用谱图预处理的自动算法,消除噪音和荧光背景,同时避免拉曼信号受到损失或者产生局部形变。
为了在复杂体系下对拉曼谱图进行快速准确的物质分类识别,本发明提出一种适用于机器学习物质识别算法的通用拉曼光谱特征提取方法。本发明将拉曼光谱的特征表述成等长且取值范围相同的特征向量,为使用机器学习算法(如svm等)进行物质分类和识别打下良好基础。
- 还没有人留言评论。精彩留言会获得点赞!