一种文本校对错误词库的自动构造方法和装置与流程
本发明属于文字处理领域,涉及一种文本自动校对处理技术,具体涉及一种用于文本校对的错误词库的自动构造方法和装置。
背景技术:
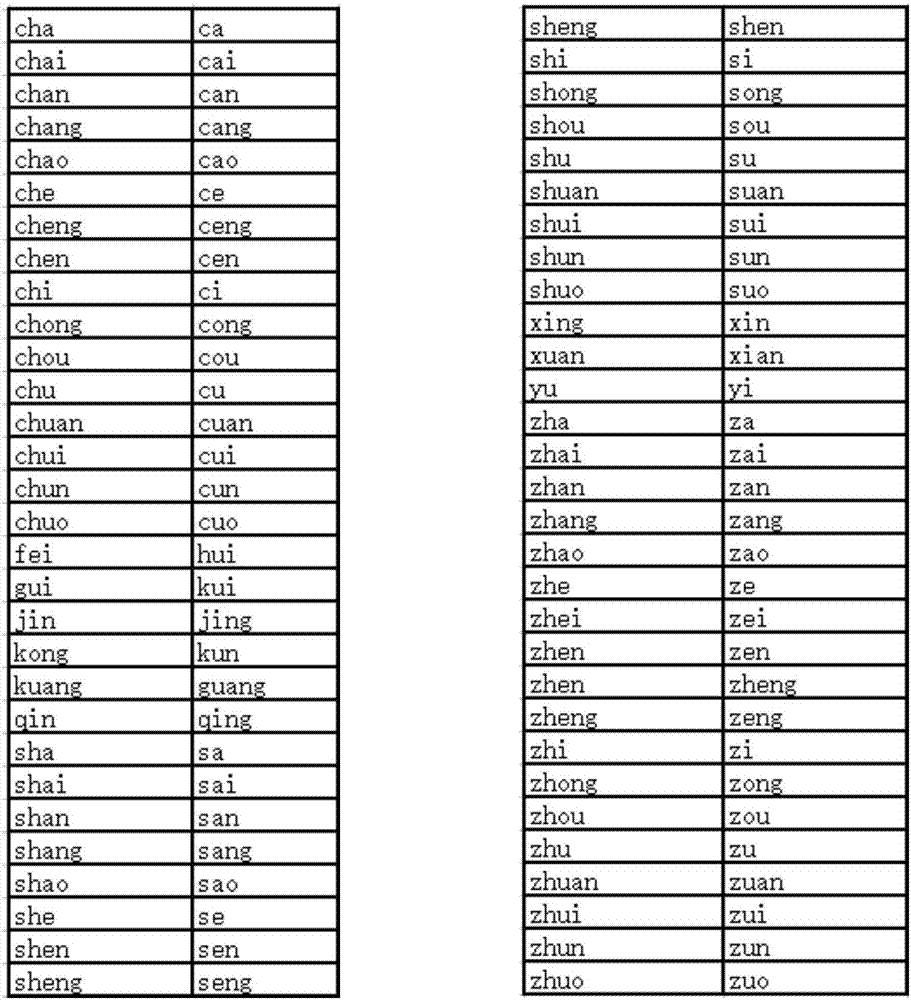
:随着现代激光照排技术和电子出版业的迅速发展,如何保证所传达的信息正确无误成为研究的重要方面之一。目前人们使用计算机进行写作、编辑和排版等工作,不可避免地会出现些文字错误,例如多字、漏字、易位、英文单词拼写错误、不规范标点等。因此,需要有专门的校对系统对文稿进行校对。从长远发展来看,信息化是将来社会发展的趋势,人们面临的电子信息和文稿日益增多,像电子期刊、电子报纸等,而传统的手工校对需要校对人员对文本进行逐字逐句的阅读、检查,从成本和效率两个方面都不能适应电子文本数量迅猛增长的趋势。因此,对一个准确度高、效率高的自动校对系统的需求越来越迫切。自动校对具有很重要的实用价值,有着广泛的应用领域。在出版业,文本自动校对的实现可以太大减轻校对人员的工作量,将他们从繁琐无味的工作中解脱出来,加快出版节奏推动整个出版业的迅速发展;在文字识别方面。需要用查错、纠错技术对语音识别,ocr(opticalcharacterrecognition)光学文字识别等识别结果进行修改:在文字编辑方面,例如word等很多文本编辑系统中都提供有自动查错技术,对输入的文本进行自动报错;在人机接口方面,例如数据库查询、自然语言接口等人机接口中要求有一定的容错性能;在辅助教学等系统中需要对输入的句子进行分析,查找出其中的错误,并给出可能的正确答案等。而在文本自动校对技术中,常用的方法为:收集对文字进行校对的修改信息;根据所述修改信息建立易错词表;根据易错词表查找文字中的可疑字并进行提示。因此,错误词库的构建对于文本自动校对技术的发展至关重要,词库数量多少直接影响着文本自动校对结果的准确率。而现有技术中,易错词表的收集主要依赖人工为主,存在着效率低、覆盖面不全以及词库规模受限等问题。技术实现要素:本发明提供一种文本校对错误词库的自动构造方法和装置,用以解决现有技术中错误词表收集过多依赖人工方式、效率低、覆盖面窄以及词库规模受限等缺点,进一步提高文本自动校对的准确率。本发明的构思在于,首先,构建一个大规模的正确词库表,包括各种通用的新华词典、汉语分词词表、成语词典库、古诗词名句以及各种专业领域词库(比如外交、计算机、医药等),并将每个词按照在词库中的先后顺序进行编号;针对计算机系统字库中的每一个汉字,构造一系列的字表,主要有拼音编码表、偏旁部首表和五笔字型编码表;创建字字之间的相关度系统矩阵表;依次枚举正确词库中的每一个词,并针对每一个词中的每个汉字依次进行其他汉字替换,计算替换一个汉字后的错误词语与正确词语的相似度;将词语匹配相似度的数值从大到小进行排序,设定词语匹配的相似度阈值,大于阈值的词语作为候选对象补充至错误词库。由此得到了一种文本校对错误词库的自动构造方法和装置。本发明中一种文本校对错误词库的自动构造方法,包括如下步骤:步骤一,构建一个大规模的正确词库表,并将每个词按照在正确词库表中的先后顺序进行编号;步骤二,针对计算机系统字库中的每一个汉字,构造一系列的字表;步骤三,根据构造的字表创建字字之间的相关度系统矩阵表;步骤四,依次枚举正确词库表中的每一个词,并针对每一个词中的每个汉字依次进行其他汉字替换,根据相关度系统矩阵表计算替换一个汉字后的错误词语与正确词语的词语匹配相似度;步骤五,将词语匹配相似度的数值从大到小进行排序,设定词语匹配的相似度阈值,将大于阈值的词语作为候选对象补充至错误词库。较佳地,所述的正确词库表包括:新华词典、汉语分词词表、成语词典库、古诗词名句以及特定专业领域词库;较佳地,所述的字表包括:拼音编码表、偏旁部首表和五笔字型编码表;较佳地,所述的相关度系统矩阵表,是指计算不同词之间相对应位置处汉字的相关度值,规则如下:1)两个字相同,相关度为2;2)两个字不同,但拼音相同或相近,则相关度为1;3)两个字不同,但字形相近,即汉字主体部首结构相同,则相关度为1;4)两个字不同,但五笔编码相同或相近,则相关度为1;5)否则,相关度为0。较佳地,所述的字形相近的判断方法,包括人工辅助方法、ocr识别方法和机器自动图像匹配识别方法;较佳地,所述的人工辅助方法,主要包括如下步骤:1)人工将所有汉字的偏旁部首进行拆分;2)指定汉字本身的主体结构部首,形成汉字偏旁部首构成表;3)当判断是否为字形相近时,读取每个汉字的偏旁部首构成和主体结构部首,并进行比较;4)当待比较的两个汉字的主体结构部首相同时则判断为字形相近,否则判断为字形不相近。较佳地,所述的ocr识别方法,主要包括如下步骤:1)将每个汉字经过电脑编辑排版后打印输出;2)接着将打印后的每个汉字经过扫描处理后进行ocr识别;3)在ocr识别结果集合中选择排名靠前的文字对象,作为该汉字对应的字形相近候选字存储在子集合中;4)通过判断两个汉字是否属于同一个子集合来判断他们是否为字形相近。较佳地,所述的机器自动图像匹配识别方法,主要包括:1)提取易错字、形近字图像集合中每个字符图像的多维的方向线素特征;2)根据每个字符图像的多维的方向线素特征,通过最大最小距离法对字符图像进行图像聚类。较佳地,所述的词语匹配相似度的数值,当词语匹配相似度的数值相同时,候选词语的优先级次序如下:1)音同且形近;2)音近且形近;3)形近;4)音同;5)音近。基于同一发明构思,本发明还提供了一种文本校对错误词库的自动构造装置,包括:正确词库表构造模块,负责构建一个大规模的正确词库表,并将每个词按照在正确词库表中的先后顺序进行编号;汉字字表构造模块,负责针对计算机系统字库中的每一个汉字,构造一系列的字表;相关度系统矩阵表构造模块,负责依据汉字字表构造模块产生的字表,创建字字之间的相关度系统矩阵表;词语匹配相似度计算模块,负责依次枚举正确词库表构造模块产生的正确词库表中的每一个词,并针对每一个词中的每个汉字依次进行其他汉字替换,根据相关度系统矩阵表计算替换一个汉字后的错误词语与正确词语的相似度;错误词语选择模块,负责将词语匹配相似度计算模块计算得到的词语匹配相似度的数值从大到小进行排序,设定词语匹配的相似度阈值,将大于阈值的词语作为候选对象补充至错误词库。本发明的有益效果如下:由于本发明中,在生成正确词语相对应的错误词语时,使用了字词匹配算法,其中涉及到了字形和拼音比较,通过枚举的方法,找到了最接近的词语错误示例。因此,构造出的错误词语跟正确词语的匹配度较高,更符合人为主观错误类型。由于本发明中,提供了一种通过正确词库自动构造错误词库的方法,使得错误词库的收集不再主要依赖人工为主,具有以下优势:1)该方法提高了错误词库的构造效率,缩短了词库构造周期。2)扩大了错误词语覆盖面。每一个词可能有多种不同的错法,而依靠人工收集可能只能针对已经出现的有限错误问题进行整理,收集其中的一种或者两种,比如“天翻地覆”,可以被错写为“天翻地复”、“天幡地覆”、“天番地覆”、“夫翻地复”和“夭翻地复”等,而本方法可以在理论上收集所有可能出错的情况。3)提高了错误词库中的词条数目规模,进而提高了文本自动校对的准确率。4)具有很好地扩展性。随着时代的发展,很多新的词语会出现在人们的日常生活中,尤其是一些网络热词,比如“洪荒之力”、“老司机”以及“友谊的小船”等。当这些新词出现后,通过该方法可以补充到正确词库中,自动构造出相应的错误词语,可以很快地更新到文本自动校对系统中;另外,当有新的生僻汉字出现时,补充到汉字字表中,同样可以达到自动生成错误词语的目的。附图说明图1为实施例中所述的文本校对错误词库的自动构造方法流程示意图;图2为所有的汉字拼音相同或者相近的情况示意图;图3为部分同音字汉字集合示意图;图4为部分形近字汉字集合示意图;图5为实施例中所述的文本校对错误词库的自动构造装置结构示意图。具体实施方式下面结合附图对本发明的具体实施作出说明。如图1所示,一种文本校对错误词库的自动构造方法包括如下步骤:s101,首先构建一个大规模的正确词库表,并将每个词按照在该正确词库表中的先后顺序进行编号。所述的正确词库表包括新华词典、汉语分词词表、成语词典库、古诗词名句以及特定专业领域词库,比如外交、计算机、医药等。s102,针对计算机系统字库中的每一个汉字,构造一系列的字表。所述的构造的字表,包括拼音编码表、偏旁部首表和五笔字型编码表。a.创建所有汉字的拼音编码表,其中每一个字都有一个或多个拼音表,比如:告:91;哥:92;歌:92;搁:92;戈:92;鸽:92;胳:92。如果两个汉字的拼音符合图2所示的对应关系即可判别为音同或者音近,图3为相应的部分同音字汉字集合示意图。b.创建所有汉字的偏旁部首表,将每个汉字的拆成所有偏旁部首的组合。比如:侥:亻:尧:侦:亻:贞:侧:亻:则:侨:亻:乔:侩:亻:会:侮:亻:每:便:亻:更:促:亻:足:俄:亻:我:俏:亻:肖。同时创建正确词库的倒排索引表,每个词都包含若干个字,将每个字的拼音和部首展开,形成一个词到拼音、部首的表。如:“战线”的拼音编码是:375,337;“战线”的部首是:占,戈,纟,戋。(1)拼音编码倒排索引,倒排索引表中的每一项为拼音编码,和所有包含这个拼音编码的词的编号。(2)偏旁部首倒排索引,倒排索引表中的每一项为部首,和所有包含这个部首的词的编号。c.五笔输入相似码词典的构造。五笔输入相似码词典的构造是在五笔字型编码表的基础上,将编码相同或者相近的字词进行组织并以特定的格式存储,包括同码候选词和近码候选词。同码候选词从五笔字型码表直接得到,而近码候选词是在五笔字型编码表的基础上,通过构造特定的五笔字形编码相似函数获得。s103,根据构造的字表,创建字字之间的相关度系统矩阵表。所述的相关度系统矩阵表,是指计算不同词之间相对应位置处汉字的相关度值,根据以下规则计算得到:1)两个字相同,相关度为2;2)两个字不同,但拼音相同或相近,则相关度为1;3)两个字不同,但字形相近,即汉字主体部首结构相同,则相关度为1;4)两个字不同,但五笔编码相同或相近,则相关度为1;在判断五笔编码是否相同时,可利用前文所述的五笔输入相似码词典进行判断;5)否则,相关度为0。由于汉字的拼音类型固定,且数量不多,因此,拼音相同或者相近判断方法较为简单。相比之下,字形相似的判断比较复杂。在本实施例中,字形相近的判断方法,包括人工辅助、ocr识别和机器自动图像匹配识别方法。a.人工辅助字形相近判断方法。主要包括如下步骤:1)人工将所有汉字的偏旁部首进行拆分;2)指定汉字本身的主体结构部首,形成汉字偏旁部首构成表;3)当判断是否为字形相近时,读取每个汉字的偏旁部首构成和主体结构部首,并进行比较;4)当待比较的两个汉字的主体结构部首相同时则判断为字形相近,否则判断为字形不相近。b.ocr识别字形相近判断方法。主要包括如下步骤:1)将每个汉字经过电脑编辑排版后打印输出;2)接着将打印后的每个汉字经过扫描处理后进行ocr识别;3)在ocr识别结果集合中选择排名靠前的文字对象,作为该汉字对应的字形相近候选字存储在子集合中;4)通过判断两个汉字是否属于同一个子集合来判断他们是否为字形相近。c.机器自动图像匹配识别字形相近判断方法。1)提取易错字形近字图像集合中每个字符图像的多维的方向线素特征;方向线素特征是一种典型的结合了结构特征和统计特征的一种表征汉字的方法,在该方法中首先利用汉字的轮廓做处理,考察轮廓像素点的八邻域中的像素点在水平,垂直,主对角线和次对角线上的分布情况。如有符合水平,垂直,主对角线或次对角线四个方向中的任一种情况,则该像素对应方向上的方向线素值(权重)就会增加一个单位。方向线素特征同时反映了字符的结构和统计特征,比较全面地代表汉字字符信息。2)根据每个字符图像的多维的方向线素特征,通过最大最小距离法对字符图像进行图像聚类。因为基于方向的特征反映了汉字的属性,故本实施例中采用字符的方向线素特征来记录字符图像的字形特征。提取每张字符图像多维的方向线素特征,然后对这些字符图像的方向线素特征进行聚类。经过上述方法得到的形近字集合,如图4为部分形近字汉字集合示意图。s104,依次枚举正确词库中的每一个词,并针对每一个词中的每个汉字依次进行其他汉字替换,根据相关度系统矩阵表计算替换一个汉字后的错误词语与正确词语的相似度。相似度计算法具体如下:step1:初始化匹配矩阵;令矩阵的行数和列数分别为两个匹配词的长度m和n。根据字的相关度表得到每两个字的相关度r,填充矩阵中每个点。r(i,j)即为第i行、第j列的相关度的值。如:匹配“待任道”和“待人之道”,则m=3,n=4,匹配矩阵如表1所示。表1.匹配矩阵待人之道待2000任0100道0002step2:计算每个点的最大相关度rmax,得到最大相关度矩阵。其计算方法为:rmax(i,1)=r(0,0),(i=1...m);rmax(1,j)=r(0,0),(j=1...n);rmax(i,j)=max(rmax(i-1,j),rmax(i,j-1),rmax(i-1,j-1))+r(i,j);如:匹配“待任道”和“待人之道”,则匹配矩阵的最大相关度矩阵如表2所示。表2.最大相关度矩阵待人之道待2222任2333道2335step3:计算相似度rs=rmax(m,n)/(2*max(m,n))。比如:“待任道”和“待人之道”的相似度为5/8=0.625。s105,将词语匹配相似度的数值从大到小进行排序,设定词语匹配的相似度阈值,将大于阈值的词语作为候选对象补充至错误词库。如果相似度大于τ,则判断为错误词语;否则排除。此处,选择τ=75%。当词语相似度数值τ相同时,候选词语的优先级次序如下:1)音同且形近。即两汉字间不仅读音相同而且字形相似,此种情况下汉字间的相似度最高。例如:杨-扬织-职枳帜伴-拌绊2)音近且形近。3)形近。即两个汉字间形近但音不同,比如:崇-祟凋-调绸妙-纱抄4)音同。比如:差-岔姹镲叉刹嵖茶传-串舡船舛喘圌遄川钏氚椽穿5)音近。下面以词语“老当益壮”为例,详细说明上述错误词的构建过程。步骤一,搜索正确词语中每个汉字的形近字。词语“老当益壮”中,搜索到的每个字的形近字如下:老-考铑佬孝姥当-挡档珰裆铛益-盖壮-状妆步骤二,在每个字的形近字中,找出符合音同且形近的汉字。读音为“lao”的同音字集合为:“老耢佬唠劳崂酪醪铑姥嫪捞涝橑痨牢烙”。因此,与“老”同时满足音同行近的汉字是:“铑”、“佬”和“姥”.读音为“dang”的同音字集合为:“裆谠荡菪蟷噹凼党当铛宕挡愓欓档璫珰筜砀”。因此,“挡档珰裆铛”均为“当”的同音形近字。同理,“益”没有同音形近字,“状”和“妆”均是“壮”的同音形近字。步骤三,利用找到的形近字构建错误词。由于音同且形近的汉字间的相似度最高,而且替换后具有良好的视觉效果和较高的迷惑性,因此首先利用汉字的同音且形近的字做形似字替换生成错误词。替换的原则是只用词语中某一个汉字的相似字做替换生成一个错误词。因此,词语“老当益壮”的错误词构建结果如下:(1)利用“老”的同音且形近字替换:“铑当益壮”、“佬当益壮”、“姥当益壮”;(2)利用“当”的同音且形近字替换:“老挡益壮”、“老档益壮”、“老珰益壮”、“老裆益壮”、“老铛益壮”;(3)利用“壮”的同音且形近字替换:“老当益妆”、“老当益状”。步骤四,选取生成的错误词加入错误词库中。在本实施例中,我们可以根据需要对错误词语进行多种替换变形,下面分别为2种、4种、8种和16种替换方式的例子。(1)2种替换。如表3所示。表3.2种替换排头俳头严冬俨冬今宵今霄他们他扪(2)4种替换。如表4所示。表4.4种替换(3)8种替换。如表5所示。表5.8种替换一路平安一路平按一路平案一路平桉一路平胺一路平鞍一路平垵一路枰安一蹶不振一蹶不赈一蹶不震一蹶不震一镢不振一噘不振一撅不振一橛不振不辨真伪不辨真沩不辨真为不辨稹伪不辨缜伪不辨镇伪不辩真伪不辫真伪主干道住干道柱干道注干道驻干道主杆道主秆道主竿道(4)16种替换。如表6所示。表6.16种替换不谋其政不谋旗政不谋期政不谋棋政不谋欺政不谋淇政不谋琪政不谋祺政五彩缤纷伍彩缤纷五睬缤纷五菜缤纷五踩缤纷五采缤纷五彩缤芬五彩缤份交互式交冱式交枑式交沍式佼互式姣互式狡互式皎互式倨傲无礼剧傲无礼居傲无礼据傲无礼椐傲无礼琚傲无礼裾傲无礼踞傲无礼不谋蜞政不谋骐政不谋鲯政不谋其正不谋其症不谋其眐不谋其证不谋其钲五彩缤分五彩缤吩五彩缤坋五彩缤枌五彩缤汾五彩缤粉五彩膑纷五彩镔纷绞互式胶互式跤互式郊互式饺互式交互拭交互试交互轼锯傲无礼倨嗷无礼倨熬无礼倨璈无礼倨磝无礼倨遨无礼倨傲抚礼崛傲无礼当然,如果对每个正确词语中多个汉字同时替换,可以得到更多的错误词语组合,这样得到的错误词库的规模会更大。基于同一发明构思,本发明还提供了一种文本校对错误词库的自动构造装置,如图5所示,包括:正确词库构造模块,负责构建一个大规模的正确词库表,并将每个词按照在正确词库表中的先后顺序进行编号;汉字字表构造模块,负责针对计算机系统字库中的每一个汉字,构造一系列的字表;相关度系统矩阵表构造模块,负责依据汉字字表构造模块产生的字表,创建字字之间的相关度系统矩阵表;词语匹配相似度计算模块,负责依次枚举正确词库构造模块产生的正确词库中的每一个词,并针对每一个词中的每个汉字依次进行其他汉字替换,根据相关度系统矩阵表计算替换一个汉字后的错误词语与正确词语的相似度;错误词语选择模块,负责将词语匹配相似度计算模块计算得到的词语匹配相似度的数值从大到小进行排序,设定词语匹配的相似度阈值,将大于阈值的词语作为候选对象补充至错误词库。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1