基于空间约束的行人重识别方法及设备与流程
本发明涉及智能视频分析技术领域,特别涉及一种基于空间约束的行人重识别方法及设备。
背景技术:
随着经济的快速发展和人口的流动,特别是在大城市,出现较多的人口密集区域,而这些人口密集区域正是安全问题频发的敏感区域,因此这些敏感区域也成为城市建设中的隐忧。为了杜绝重点敏感区域中各种盗窃、抢劫和打架等问题的发生,有关部门在相关位置安装了大量的摄像头,用于对这些区域进行实时监管,但由于距离较远或者清晰度等问题,在发生突发事件后并不能对嫌疑人进行准确的定位和追踪,并不能达到预期的效果。
传统的行人re-id的方法比较简单,都是针对多个镜头的视频图像进行导入,仅仅依靠特征比对来处理,并没有利用到有效的三维空间信息,甚至是时间信息,这些信息作为目标的连续性轨迹刻画是非常有价值的。
技术实现要素:
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的目的在于提出一种基于空间约束的行人重识别方法及设备。
为了实现上述目的,本发明一方面的实施例提供一种基于空间约束的行人重识别方法,包括如下步骤:
步骤s1,利用拍摄设备获取观测场景内的图像信息,并传输给智能前端,由所述智能前端对所述图像信息进行分析,提取场景内的行人特征,将所述行人特征绑定对应时间信息标签,并根据预先标定好的拍摄设备位置和角度以计算投影矩阵,以实现多个像素坐标到统一的三维坐标的转换;
步骤s2,所述智能前端根据步骤s1中得到行人特征,对相应的行人目标进行单镜头跟踪,生成行人目标跟踪轨迹,通过坐标映射转换为三维空间的坐标轨迹;
步骤s3,后台服务器接收来自所述智能前端返回的行人目标跟踪轨迹,对该行人目标跟踪轨迹进行聚合,得到聚合轨迹,包括:分别采用单镜头内部聚合和跨镜头聚合方式;
步骤s4,所述后台服务器根据步骤s3中得到的聚合轨迹,分别对每个单镜头下的行人目标跟踪轨迹进行采样,作为行人目标的特征基础gallery,并将跨镜头聚合的目标对应同一个galleryid;
步骤s5,所述后台服务器接收到待检索的行人图像,提取该行人图像的特征作为检索特征,将该检索特征与存储的多个特征基础gallery进行对比,查找对比成功的行人目标轨迹,并按照置信度进行排序,返回检索结果。
进一步,在所述步骤s1中,所述智能前端对所述图像信息进行分析,包括:所述智能前端基于gpu加速的dcnn算法,该算法分为两步训练:
首先训练行人检测器,然后进行网络压缩以减少层数和通道、权值聚合,并根据前面的检测结果重新训练,得到适用于当前视角的检测器;在行人检测算法基础上加入特定特征检测,对局部特性进行刻画,以作为整体特征的补充特征。
进一步,在所述步骤s3中,所述单镜头内部的聚合,包括如下步骤:内部聚合通过re-id处理由于遮挡、变形、光照问题导致的目标轨迹断续情况,通过特征比对实现连续轨迹刻画;
所述跨镜头的聚合,包括如下步骤:跨镜头聚合处理目标的跨镜头行为,根据目标投影的运动方向信息,在三维空间内寻找周围的摄像机覆盖,并根据最大可能性对摄像机赋予权值,基于该权值进行目标的re-id聚合,刻画跨镜头轨迹。
进一步,在所述步骤s4中,所述对每个单镜头下的行人目标跟踪轨迹进行采样,包括:通过目标轨迹进行序列采样的方法,该采样方法结合re-id置信度阈值完成执行。
进一步,在所述步骤s5中,所述查找对比成功的行人目标轨迹,并按照置信度进行排序,包括如下步骤:根据输入的待检索的行人图像,采用两级检索机制,首先得到最高置信度的目标位置,然后优先基于该目标周围进行检索。
本发明另一方面的实施例提供一种基于空间约束的行人重识别设备,包括:拍摄设备、智能前端和后台服务器,其中,所述拍摄设备与所述智能前端通信,所述智能前端进一步与所述后台服务器通信,所述拍摄设备用于采集观测场景内的图像信息;所述智能前端包括:壳体、工作指示灯、解码芯片、散热装置、供电单元和嵌入式板卡,所述解码芯片、供电单元和嵌入式板卡均位于所述壳体的内部,所述供电单元与工作指示灯、解码芯片、散热装置和嵌入式板卡连接,以进行供电,其中,所述工作指示灯位于所述壳体的外侧上部;所述散热装置位于所述壳体一侧,所述解码芯片与外部的网络摄像头和嵌入式板卡连接,
所述智能终端用于接收所述拍摄设备采集的观测场景内的图像信息对所述图像信息进行分析,提取场景内的行人特征,将所述行人特征绑定对应时间信息标签,并根据预先标定好的拍摄设备位置和角度以计算投影矩阵,以实现多个像素坐标到统一的三维坐标的转换,根据得到行人特征,对相应的行人目标进行单镜头跟踪,生成行人目标跟踪轨迹,通过坐标映射转换为三维空间的坐标轨迹;
所述后台服务器用于接收来自所述智能前端返回的行人目标跟踪轨迹,对该行人目标跟踪轨迹进行聚合,得到聚合轨迹,包括:分别采用单镜头内部聚合和跨镜头聚合方式,根据得到的聚合轨迹,分别对每个单镜头下的行人目标跟踪轨迹进行采样,作为行人目标的特征基础gallery,并将跨镜头聚合的目标对应同一个galleryid;并在接收到待检索的行人图像,提取该行人图像的特征作为检索特征,将该检索特征与存储的多个特征基础gallery进行对比,查找对比成功的行人目标轨迹,并按照置信度进行排序,返回检索结果。
进一步,所述智能前端用于对所述图像信息进行分析,包括:所述智能前端基于gpu加速的dcnn算法,该算法分为两步训练:
首先训练行人检测器,然后进行网络压缩以减少层数和通道、权值聚合,并根据前面的检测结果重新训练,得到适用于当前视角的检测器;在行人检测算法基础上加入特定特征检测,对局部特性进行刻画,以作为整体特征的补充特征。
进一步,所述后台服务器执行单镜头内部的聚合,包括:内部聚合通过re-id处理由于遮挡、变形、光照问题导致的目标轨迹断续情况,通过特征比对实现连续轨迹刻画;
所述后台服务器执行跨镜头的聚合,包括:跨镜头聚合处理目标的跨镜头行为,根据目标投影的运动方向信息,在三维空间内寻找周围的摄像机覆盖,并根据最大可能性对摄像机赋予权值,基于该权值进行目标的re-id聚合,刻画跨镜头轨迹。
进一步,所述后台服务器通过目标轨迹进行序列采样的方法,该采样方法结合re-id置信度阈值完成执行。
进一步,所述后台服务器根据输入的待检索的行人图像,采用两级检索机制,首先得到最高置信度的目标位置,然后优先基于该目标周围进行检索。
根据本发明实施例的基于空间约束的行人重识别方法及设备,智能前端集成轻量级的深度学习算法,实现对行人目标的有效检测,并直接抽取卷积层特征作为特征比对依据。采用基于空间约束的行人重识别方法根据目标的位置信息,在局部场景内实现全局优化,有效排除与检测目标比较近似的假目标。通过后台服务器存储前端回传的特征结果,该特征结果同时包含时间与三维位置标签,作为行人重识别算法的输入,然后将待检索的行人图像与其进行比对,以实现搜索查询。本发明通过三维空间约束提升行人搜索的准确性,并提供一种结构简单、监测精准、智能化程度高的智能前端,作为前端行人检测设备,实现行人的检测与特征提取,并将特征结果存储到后台服务器,由后台服务器统一进行检索查询。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的基于空间约束的行人重识别方法的流程图;
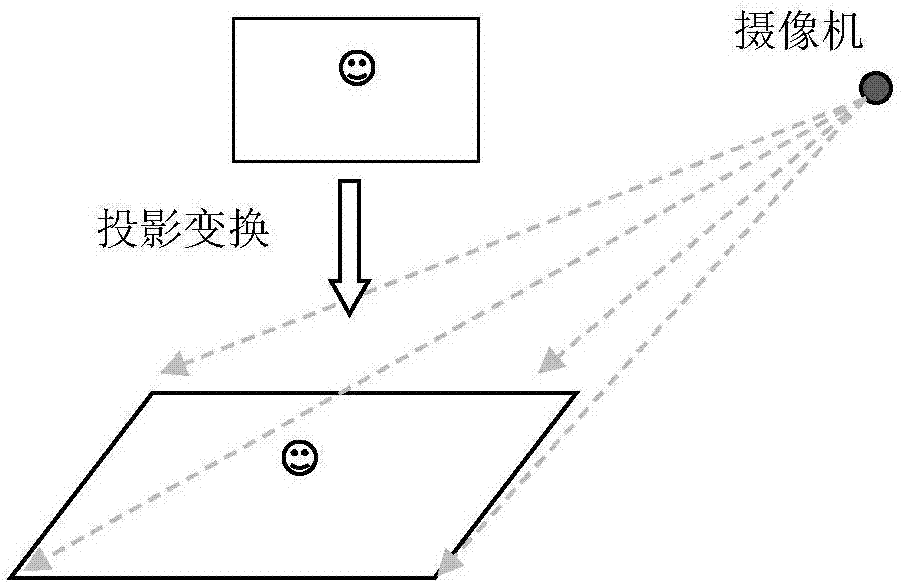
图2为根据本发明实施例的三维位置映射的示意图;
图3(a)和(b)为根据本发明实施例的轨迹聚合的示意图;
图4为根据本发明实施例的基于空间约束的行人重识别设备的结构图;
图5为根据本发明实施例的基于空间约束的行人重识别设备的示意图;
图6为根据本发明实施例的嵌入式板卡的示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本发明实施例提供一种基于空间约束的行人重识别方法及设备,可以解决传统re-id方法所存在的问题。
如图1所示,本发明实施例的基于空间约束的行人重识别方法,包括如下步骤:
步骤s1,利用拍摄设备获取观测场景内的图像信息,并传输给智能前端,由智能前端对图像信息进行分析,采用深度卷积网络(dcnn)实时提取场景内的行人特征,将行人特征绑定对应时间信息标签,并根据预先标定好的拍摄设备位置和角度以计算投影矩阵,以实现多个像素坐标到统一的三维坐标的转换,同时绑定到三维坐标标签,参考图2。
具体的,智能前端对图像信息进行分析,包括:智能前端采用nvidiatx1嵌入式板卡封装,有效集成基于gpu加速的深度卷积网络dcnn算法,该算法分为两步训练:
首先训练行人检测器,然后进行网络压缩以减少层数和通道、权值聚合,并根据前面的检测结果重新训练,得到适用于当前视角的检测器;在行人检测算法基础上加入特定特征检测,对局部特性(例如眼镜、背包、鞋子等)进行刻画,以作为整体特征的补充特征。即,智能前端提取的行人特征,包括整体特征和局部特征。
然后,对于每个拍摄设备,借助网络压缩,训练基于该视角的轻量级的深度网络,以便于在智能前端运行。每个目标检测结果标定对应的时间信息,同时借助事先标定好的相机位置和角度,计算投影矩阵,实现从像素坐标到三维位置的映射,同时绑定到三维坐标标签。然后,通过拍摄设备的三维位置和投影矩阵实现目标从像素空间到三维空间的映射,实现从多个像素坐标到统一的三维坐标之间的转换。
步骤s2,智能前端根据步骤s1中得到行人特征,通过集成视频目标跟踪方法对相应的行人目标进行单镜头跟踪,生成行人目标跟踪轨迹,通过坐标映射转换为三维空间的坐标轨迹。
步骤s3,后台服务器接收来自智能前端返回的行人目标跟踪轨迹,对该行人目标跟踪轨迹进行聚合,得到聚合轨迹,包括:分别采用单镜头内部聚合和跨镜头聚合方式。
(1)单镜头内部的聚合,包括如下步骤:内部聚合通过re-id处理由于遮挡、变形、光照问题导致的目标轨迹断续情况,通过特征比对实现连续轨迹刻画,如图3(a)所示。
(2)跨镜头的聚合,包括如下步骤:跨镜头聚合处理目标的跨镜头行为,根据目标投影的运动方向信息,在三维空间内寻找周围的摄像机覆盖,并根据最大可能性性对摄像机赋予权值,基于该权值进行目标的re-id聚合,刻画跨镜头轨迹,如图3(b)所示。
步骤s4,后台服务器根据步骤s3中得到的聚合轨迹,分别对每个单镜头下的行人目标跟踪轨迹进行采样,作为行人目标的特征基础gallery,并将跨镜头聚合的目标对应同一个galleryid。
在本步骤中,对每个单镜头下的行人目标跟踪轨迹进行采样,包括:通过目标轨迹进行序列采样的方法,该采样方法结合re-id置信度阈值完成执行。并且,设置跨镜头目标统一的galleryid管理方法。
步骤s5,后台服务器接收到待检索的行人图像,通过dcnn提取该行人图像的特征作为检索特征(比较依据),将该检索特征与存储的多个特征基础gallery进行对比,查找对比成功的行人目标轨迹,并按照置信度进行排序,返回检索结果。
具体的,查找对比成功的行人目标轨迹,并按照置信度进行排序,包括如下步骤:根据输入的待检索的行人图像,采用两级检索机制,首先得到最高置信度的目标位置,然后优先基于该目标周围进行检索。
综上,本发明实施例的基于空间约束的行人重识别方法,智能前端检测设备直接与拍摄设备(例如摄像头)连接,通过集成轻量级的深度学习算法,实现对行人目标的有效检测,并直接抽取卷积层特征作为特征比对依据。采用基于空间约束的行人重识别方法根据目标的位置信息,在局部场景内实现全局优化,有效排除与检测目标比较近似的假目标。通过后台服务器存储前端回传的特征结果,该特征结果同时包含时间与三维位置标签,作为行人重识别算法的输入,然后将待检索的行人图像与其进行比对,以实现搜索查询。
如图4所示,本发明实施例的基于空间约束的行人重识别设备,包括:拍摄设备100、智能前端200和后台服务器300,其中,拍摄设备100与智能前端200通信,智能前端200进一步与后台服务器300通信。
具体的,拍摄设备100用于采集观测场景内的图像信息。例如,拍摄设备100可以为相机等。
如图5所示,智能前端200包括:壳体1、工作指示灯6、芯片装置3、散热装置5、供电单元4和嵌入式板卡2。
供电单元4可以实现对设备整体进行供电。壳体1采用铝合金外壳,进行散热和设备承载。壳体1作为内部设备的容器,负责承载、防水、安装。
解码芯片3、供电单元4和嵌入式板卡2均位于壳体1的内部,供电单元4与工作指示灯6、解码芯片3、散热装置5和嵌入式板卡2连接,以进行供电。由供电单元4向真个设备进行供电。
此外,工作指示灯6位于壳体1的外侧上部。其中,工作指示灯6可以采用多个led灯。并且,多个led灯采用显示颜色不同的led灯,从而用户可以当前点亮的led灯的颜色判断设备的当前工作状态。
工作指示灯6可以指示系统的运行情况,包括:是否开机、网络连接情况、温度报警等。
散热装置5位于壳体1一侧,用于对壳体内部降温。在本发明的一个实施例中,散热装置5可以采用风扇实现,通过风扇实现物理散热,避免嵌入式板卡2设备温度过高。
参考图6,嵌入式板卡2采用nvidiatx1进行封装,借助于cuda并行为深度网络提供加速,该板卡运行的软件模块包括:整体和局部特征的行人检测器和特征提取;并行的视频目标跟踪模块;命令接收与结果回传模块;视频接入与硬解码模块。本发明采用基于硬件的解码模块来加速解码过程,减少设备的gpu占用,硬解码模块与摄像机之间采用rtsp方式进行接入,解码后的数据直接放入到嵌入式板卡缓冲区。
解码芯片3与外部的网络摄像头和嵌入式板卡2连接。解码芯片可以实现网络视频接入,实现对前端摄像机的实时视频流获取,解码得到视频图像。此外,本发明的解码芯片采用硬解码器,通过硬解码器进行视频流获取,避免占用嵌入式板卡2的cpu或gpu资源。解码后的图像数据同步到嵌入式板卡2指定的存储区,嵌入式板卡2可以直接读取。嵌入式板卡2为系统的嵌入式设备,搭载并运行行人检测、特征提取、特征比对等模块,实现上述功能。
智能终端用于接收拍摄设备100采集的观测场景内的图像信息对图像信息进行分析,采用深度卷积网络(dcnn)提取场景内的行人特征,将行人特征绑定对应时间信息标签,并根据预先标定好的拍摄设备100位置和角度以计算投影矩阵,以实现多个像素坐标到统一的三维坐标的转换,同时绑定到三维坐标标签。
在本发明的一个实施例中,智能前端200用于对图像信息进行分析,包括:智能前端200基于gpu加速的dcnn算法,该算法分为两步训练:
首先训练行人检测器,然后进行网络压缩以减少层数和通道、权值聚合,并根据前面的检测结果重新训练,得到适用于当前视角的检测器;在行人检测算法基础上加入特定特征检测,对局部特性(例如眼镜、背包、鞋子等)进行刻画,以作为整体特征的补充特征。
然后,对于每个拍摄设备100,智能前端200借助网络压缩,训练基于该视角的轻量级的深度网络,以便于在智能前端200运行。每个目标检测结果标定对应的时间信息,同时借助事先标定好的相机位置和角度,计算投影矩阵,实现从像素坐标到三维位置的映射,同时绑定到三维坐标标签。然后,通过拍摄设备100的三维位置和投影矩阵实现目标从像素空间到三维空间的映射,实现从多个像素坐标到统一的三维坐标之间的转换。
智能前端200根据得到行人特征,对相应的行人目标进行单镜头跟踪,生成行人目标跟踪轨迹,通过坐标映射转换为三维空间的坐标轨迹。
后台服务器300用于接收来自智能前端200返回的行人目标跟踪轨迹,对该行人目标跟踪轨迹进行聚合,得到聚合轨迹,包括:分别采用单镜头内部聚合和跨镜头聚合方式。
(1)单镜头内部的聚合,包括如下步骤:内部聚合通过re-id处理由于遮挡、变形、光照问题导致的目标轨迹断续情况,通过特征比对实现连续轨迹刻画;
(2)跨镜头的聚合,包括如下步骤:跨镜头聚合处理目标的跨镜头行为,根据目标投影的运动方向信息,在三维空间内寻找周围的摄像机覆盖,并根据最大可能性对摄像机赋予权值,基于该权值进行目标的re-id聚合,刻画跨镜头轨迹。
后台服务器300根据得到的聚合轨迹,分别对每个单镜头下的行人目标跟踪轨迹进行采样,作为行人目标的特征基础gallery,并将跨镜头聚合的目标对应同一个galleryid。
在本发明的一个实施例中,后台服务器300通过目标轨迹进行序列采样的方法,该采样方法结合re-id置信度阈值完成执行。并且,后台服务器300通进一步设置跨镜头目标统一的galleryid管理方法。
后台服务器300在接收到待检索的行人图像,提取该行人图像的特征作为检索特征,将该检索特征与存储的多个特征基础gallery进行对比,查找对比成功的行人目标轨迹,并按照置信度进行排序,返回检索结果。
具体的,后台服务器300根据输入的待检索的行人图像,采用两级检索机制,首先得到最高置信度的目标位置,然后优先基于该目标周围进行检索。
根据本发明实施例的基于空间约束的行人重识别方法及设备,智能前端集成轻量级的深度学习算法,实现对行人目标的有效检测,并直接抽取卷积层特征作为特征比对依据。采用基于空间约束的行人重识别方法根据目标的位置信息,在局部场景内实现全局优化,有效排除与检测目标比较近似的假目标。通过后台服务器存储前端回传的特征结果,该特征结果同时包含时间与三维位置标签,作为行人重识别算法的输入,然后将待检索的行人图像与其进行比对,以实现搜索查询。本发明通过三维空间约束提升行人搜索的准确性,并提供一种结构简单、监测精准、智能化程度高的智能前端,作为前端行人检测设备,实现行人的检测与特征提取,并将特征结果存储到后台服务器,由后台服务器统一进行检索查询。
此外,本发明提供的智能前端通过设置铝合金外壳作为内部设备的容器,实现承载、防水、安装的作用。并且在壳体的外侧上部设置多个led灯,从而用户可以当前点亮的led灯的颜色判断设备的当前工作状态,便于用户实时观察设备的工作状态。并且,在壳体的一侧设置风扇作为散热装置,可以实现物理散热,避免嵌入式板卡设备温度过高,降低壳体内各个器件的问题,提高器件的使用寿命和工作性能。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求及其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!