一种基于storm流计算框架的食品安全网络舆情分析方法与流程
本发明涉及食品安全大数据处理技术领域,尤其涉及一种基于storm流计算框架的食品安全网络舆情分析方法。
背景技术:
随着经济的发展,人们的生活质量不断提高,对食品的要求也从“裹腹”向“健康、营养”过渡。我国目前建立了较为完备的食品质量安全标准,但对于食品安全的网络监控和基于互联网的食品安全分析并不多。食品安全分析是食品安全管理的重要组成部分,其功能主要在于对食品安全风险的预防预测。影响食品安全的因素复杂多变,对于食品安全监管的难度系数也越来越大,建立有效的食品安全网络舆情分析机制,及时发现安全隐患是一项迫切任务。
现有的数据处理框架有storm、mapreduce、sparkstreaming等。
mapreduce:mapreduce是一种面向大数据并行处理的计算框架。主要分为map阶段和reduce阶段这两个阶段,每个阶段都是用键值对作为输入和输出。map阶段是从文件流读取信息,按关键字形成key/value键值对。reduce阶段是对map阶段的结果进行汇总,将具有相同key值的分为一类进行统一处理。mapreduce是一种分布式框架,可以降低服务器的压力,提高运算效率,但是mapreduce是一种离线数据处理框架,无法满足实时性要求高的业务。
sparkstreaming:sparkstreaming是一个类似于mapreduce的分布式计算框架,其核心在于其弹性分布式数据集。它与mapreduce相比的优势就在于它是一种实时计算框架,能同时运行大量的结点,进行海量数据的处理。主要原理是将实时输入的数据流以时间片δt为单位切分成块,然后把每块数据作为一个rdd(弹性分布式数据集),并使用rdd提供的接口实现数据的批量处理,最终将处理的结果生成一个sparkjob等待汇总。sparkstreaming具有吞吐量大、实时性高的优点,但事务机制并不完善,数据容易丢失出错。
综上所述,本发明结合scrapy与storm框架并通过优化storm框架中的single‐pass算法提供一种食品安全网络舆情分析系统。
技术实现要素:
为了解决现有技术所存在的问题,本发明提供一种基于storm流计算框架的食品安全网络舆情分析方法,通过scrapy爬虫框架爬取有关食品安全的网页,然后对提取出来的网页文件的文本内容进行分词以及向量化,对向量化后的文本数据进行分布式聚类,对同一类聚类结果做进一步处理,获取该类的倾向度结果,再根据倾向度结果判断舆情变化的趋势,从而进行监控和预警。
本发明采用如下技术方案来实现:一种基于storm流计算框架的食品安全网络舆情分析方法,包括以下步骤:
s1、利用scrapy爬虫框架对网络媒体资源进行网络爬虫,获取有关食品安全网页的url,根据url将相应的网页数据下载并进行分析,最后将数据保存到hbase数据库中;
s2、spout节点从hbase数据库读取数据放入网络拓扑结构topology,并且随机分发给第一层bolt节点进行计算和处理;
s3、第一层bolt节点获取数据后对文本数据进行向量化,将文本数据进行分词和计算该词汇的权重;
s4、对第一层bolt节点向量化后的文本数据进行文本聚类,并将同一类的文本数据发送到相同的bolt节点中;
s5、对同一类的文本数据作进一步处理,生成事件,提取事件中的舆情信息,根据舆情信息计算出文本分类的舆情倾向度。
所述步骤s3通过汉语分词系统对文本的标题以及摘要进行分词;根据食品分类的规则,在数据库中建立食品类别表,将标题以及摘要分词后的结果与数据库中食品类别表进行对比确定标题或摘要中出现的食品,统计确定为食品的词汇出现的频率,出现频率最高的食品词汇的父类作为事件的分类;继续通过汉语分词系统对整篇文章进行分词,确定该文章出现的时间、地点、评价、转发量及评论数;最后对文本进行向量化。
所述步骤s5在第二层bolt节点中对同一类的文本数据进行进一步处理,生成事件。第二层bolt节点首先提取由第一层bolt节点获得的事件发生的时间、地点、类别以及舆情;根据舆情计算得出舆情倾向度,创建正向倾向词库、中立倾向词库、反向倾向词库共三个倾向数据库,并向三个倾向数据库导入相应的词汇;利用汉语分词系统对文本数据中评价的内容进行分词,将分词后的结果与三个倾向数据库进行对比,获取评价内容中正向倾向、中立倾向、反向倾向的个数,计算出个体对象舆情倾向度;然后基于同一类不同对象的倾向度计算某个文本分类的整体舆情倾向度。
从以上技术方案可知,本发明首先利用scrapy爬虫框架爬取有关食品安全的网页,然后对提取出来的网页文件的文本内容进行分词以及向量化,对向量化后的文本数据进行分布式聚类,对同一类聚类结果进行进一步的处理,获取该类的倾向度结果,由此达到网络监控的效果。与现有技术相比,本发明具有如下优点和有益效果:
1、本发明通过scrapy爬虫框架爬取有关食品安全的网页,然后对提取出来的网页文件的文本内容进行分词以及向量化,对向量化后的文本数据进行分布式聚类,对同一类聚类结果做进一步处理,获取该类的倾向度结果,再根据倾向度结果判断舆情变化的趋势,从而进行监控和预警。
2、本发明还对storm框架的single‐pass算法进行了优化,在数据处理的第一层bolt节点先对数据进行分类,然后将相同类别的数据传到相同的节点,并根据类中的转发量、评价数计算出预警值,提高了运算效率以及数据的可信性。
3、本发明通过对网络舆情进行分析以实现对食品安全的监控,利用storm分布式流计算框架,提高了数据处理的效率,解决了以往时效性较差的缺点。
附图说明
图1为storm框架的数据交互图;
图2为storm框架中的topology拓扑结构图;
图3为spout节点与bolt节点的数据交互图;
图4为本发明食品安全网络舆情分析流程图。
具体实施方式
下面结合附图及实施例对本发明做进步详细的描述,但本发明的实施方式不限于此。
实施例
本发明提供了一种基于storm流计算框架的食品安全网络舆情分析方法,采用storm框架与优化后的single‐pass算法相结合进行食品安全网络监控。storm是一个分布式、高容错的实时计算系统。storm具有低延迟、高性能、可扩展等优势,令持续不断的流计算变得容易,弥补了hadoop批处理所不能满足的实时要求。
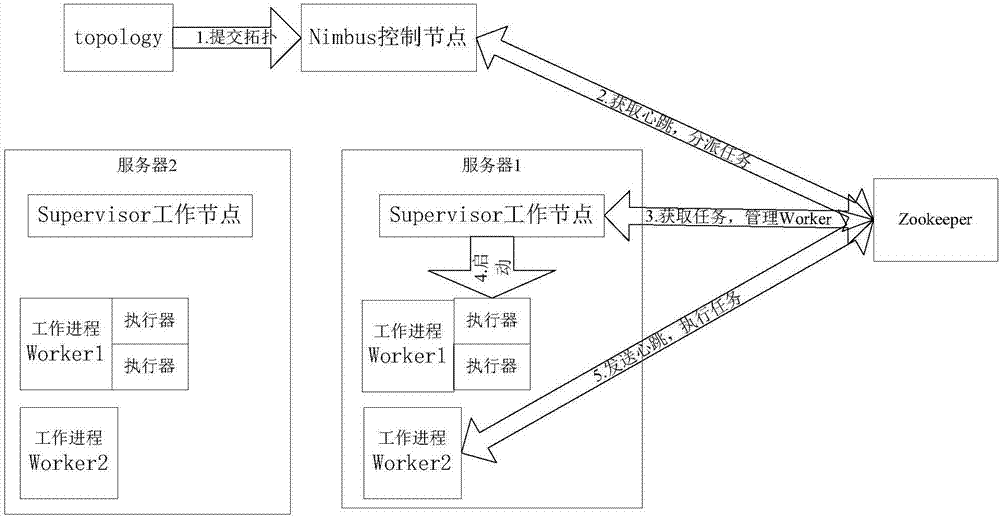
在本发明中所使用的storm分布式集群主要由一个控制节点和一群工作节点组成,使用zookeeper进行管理。控制节点上包括nimbus组件,nimbus组件负责响应分布在系统集群中的节点,分配工作给集群上的服务器以及监测故障。工作节点包括supervisor组件,supervisor组件负责监听分配给它的那台服务器的工作,根据需要启动或关闭工作进程worker。
zookeeper是完成supervisor组件和nimbus组件之间协调的服务,nimbus组件和supervisor组件实际运行的工作进程worker都是把心跳保存在zookeeper上。nimbus组件也是根据zookeerper上的心跳和任务的运行状况,进行工作调度和任务分配的,图1为本系统的storm数据交互图。
在本发明中,事先会将分析有关食品安全的网页文件数据的逻辑封装进storm中的网络拓扑结构topology。topology是管理控制节点和工作节点的拓扑结构,是一组由spout(数据源)和bolt(数据操作)通过随机分组shufflegrouping进行连接的图,图2为topology拓扑结构图。
本发明的topology拓扑结构包含了控制节点(nimbus组件)和工作节点(supervisor组件)。nimbus组件负责响应分布在系统集群中的工作节点,分配工作给集群上的服务器和监测故障。supervisor组件负责监听分配给它的那台服务器的工作,根据需要启动或关闭工作进程worker,nimbus组件和supervisor组件通过zookeeper进行协调工作。
topology通过spout节点从外部的数据源读取数据并且随机分发给第一层的bolt节点进行计算和处理,而该层bolt节点会将处理后的结果继续发送给下一层bolt节点,从而将任务分成多个部分并行处理,实现了海量数据分析,提高了数据计算与分析的性能。
为了实现对数据的分布式处理,本发明对storm的single‐pass算法进行了优化,在数据处理的第一层bolt节点对数据进行分类,将相同类别的数据传给相同的bolt节点,再对同一类的数据进行分析处理,提高了数据的可靠性以及数据处理的效率。
第一层bolt节点主要是对读取到的文本数据进行分词处理并进行向量化以实现数据的分布式处理。具体来说,第一层bolt节点会利用ictclas汉语分词系统和食品分类表对数据源中的文本进行分词处理,然后使用自编码神经网络和tf_idf算法对分词处理后的词汇进行向量化,实现聚类的分类。首先对标题和摘要进行分词处理,匹配在文本中出现频率最高的词汇与食品分类表(事先存储在数据库)中的子类别,得到该文本的食品分类以及其在食品分类表中的父类。同理,利用ictclas汉语分词系统,从文章中提取该事件发生的时间、地点、评价、转发量、评价数,最后利用余弦相似度算法计算处理后文本数据之间的余弦相似度,形成节点微簇,并将同一类传到同一个bolt节点中。
而第二层bolt节点主要是对同一类数据的进一步分析处理。第二层bolt节点对同一类的食品进行处理,根据评价以及评论数、转发量得出单个个体的倾向度,然后将同一类的个体倾向度进行统计,得到该类的预警值。
在本实施例中,基于storm流计算框架的食品安全网络舆情分析方法,如图4,具体包括如下步骤:
s1、利用scrapy爬虫框架对新闻、贴吧、微博等网络媒体资源进行网络爬虫;
scrapy是一个强大的爬虫框架,能够轻易爬取海量的数据。首先是获取有关食品安全网页的url,调度器scheduler会将url交给下载器downloader进行下载,下载器将相应的网页数据下载并交给spider进行分析。分析后的结果有两种:一种是需要进一步抓取的链接url,例如“下一页”的链接,这些链接会被传回调度器scheduler然后由下载器继续下载;另一种是需要保存的数据,这些数据会传输到项目管道组件itempipeline,项目管道组件itempipeline会对数据进行后期的处理。最后将处理完的数据保存到hbase数据库中。
s2、spout节点读取hbase数据库中的数据,并与bolt节点的数据进行交互;
spout节点从hbase数据库读取数据放入网络拓扑结构topology,并且随机分发给第一层bolt节点进行计算和处理。此时spout节点有两种类型:可靠和不可靠。当bolt节点接收数据失败时,可靠的spout节点会进行重发;而不可靠的spout节点不会考虑接收成功与否,只发送一次。图3为spout节点与bolt节点的数据交互。
s3、对数据进行向量化;
第一层bolt节点获取数据后要对文本数据进行向量化,即将文本数据进行分词和计算该词汇的权重。本发明通过ictclas汉语分词系统对文本的标题以及摘要进行分词。根据食品分类的规则,在数据库中建立食品类别表。将标题以及摘要分词后的结果与数据库中食品类别表进行对比(模糊查询)确定标题或摘要中出现的食品,统计确定为食品的词汇出现的频率,出现频率最高的食品词汇的父类作为事件的分类。继续通过ictclas汉语分词系统对整篇文章进行分词,确定该文章出现的时间、地点、评价、转发量、评论数。最后利用tf_idf对文本进行向量化。在本发明中采用vsm形式表示文本,具体形式如下:
d={(t1,w1),(t2,w2),(t3,w3),…}(1)
其中t1、t2、t3为文本数据的特征内容,w1、w2、w3为该文本数据的权重。将所有与数据库匹配成功的词汇提取出来计算其出现的频率tfn就是该特征内容的权重。特征文本数据的出现频率计算公式如下:
其中tn为某特征词汇出现的次数,c为按分词系统分词后的总词汇数。特征文本数据的权重计算公式如下:
其中n为所有特征词汇的总数。
s4、对文本数据进行聚类分发
本步骤需要对第一层bolt节点向量化后的文本数据进行分类,并将同一类的文本数据发送到相同的bolt节点中。本发明使用的是余弦相似度算法来进行文本聚类,公式如下:
余弦相似度是用向量空间中两个词频向量的夹角的余弦值作为衡量两个分类间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,两个文本数据属于同一类的可能性越大。余弦值越接近‐1,就表明夹角越接近180度,也就是两个向量相差越远,两个文本数据属于同一类的可能性越小。
s5、对同一类的文本数据作进一步处理,生成事件,提取事件中的舆情信息,根据舆情信息计算出文本分类的舆情倾向度。
在文本聚类之后,在第二层bolt节点中对同一类的文本数据进行进一步处理,生成事件。首先提取由第一层bolt节点获得的事件发生的时间、地点、类别(按食品分类表所得的食品分类)以及舆情(包含评价、转发量、评论数)。根据舆情计算得出舆情倾向度,首先创建三个倾向数据库,分别为正向倾向词库、中立倾向词库、反向倾向词库,并向三个倾向数据库导入相应的词汇。利用ictclas汉语分词系统对文本数据中评价的内容进行分词,将分词后的结果与三个倾向数据库进行对比,获取评价内容中正向倾向、中立倾向、反向倾向的个数,分别为pos、neu、neg。
个体对象舆情倾向度计算公式如下:
其中c为评论的人数、r为转发量。对同一个类的不同对象进行相同处理,得出同一类不同对象的倾向度p1、p2、p3……pn,计算某个类的整体倾向度,公式如下:
其中n为该文本分类所包含的对象数量,pi为第i个对象的个体对象舆情倾向度。
某个类的倾向判断公式
根据文本分类的舆情倾向度计算结果,采用人工筛选的方法,设定五个预警等级。当文本分类的倾向度大于1500时,判断为一级预警,当文本分类的倾向度大于1000小于1500时,判断为二级预警,当文本分类的倾向度大于500小于1000时,判断为三级预警,当文本分类的倾向度大于0小于500时,判断为四级预警,当文本分类的倾向度小于0时,判断为五级预警。预警级数越高表示该类食品越需要引起关注。
下面以检索《今日头条》的美食专栏作为本专利的具体例子。
第一步、利用scrapy爬虫框架爬取目标网站”http://www.toutiao.com/ch/news_food/”,然后提取该网页的文本内容以及下一个需要提取的url,最后通过数据管道将文本数据以json格式输出到hbase数据库。
第二步、利用storm框架中的spout节点从hbase数据库中读取json数据并解析,将解析后的数据随机分发给第一层bolt节点。
第三步、首先在数据库中创建表:食品类别表,然后对报道的标题与摘要进行分词处理,将提取出词汇与数据库中的食品类别表进行模糊查询,统计确定为食品词汇出现的频率,将出现次数最高的词汇作为下一层bolt节点的分类标志。
第四步、利用strom框架的supervisor节点将第一层bolt节点的文本数据进行向量化处理,使用余弦相似度算法将相似的食品词汇归为同一类然后统一分发到第二层的bolt节点。
第五步、第二层的bolt节点将同一类的文本数据中的标题、摘要、内容进行分词,提取其中诸如“实惠”或者“蟑螂”等词汇与事先建立的正向倾向表与负向倾向表进行对比,得出该报道为正向倾向或者是负向倾向以及通过公式(5)、(6)、(7)根据评价数以及转发量等计算出本类的整体倾向度。
如上所述,便可较好地实现本发明。
- 还没有人留言评论。精彩留言会获得点赞!