一种基于改进密度峰值的多粒度社区发现方法与流程
本发明属于社交网络分析、粒计算以及聚类分析等领域,尤其涉及一种基于改进密度峰值算法融合多粒度思想的社区结构发现方法。
背景技术:
社区结构是网络模块化与异质性的反映,表示真实网络可以看作是由许多不同类型节点组合形成的,如人际关系网络中的朋友圈子、引文网络中针对同一主题的相关论文、新陈代谢或蛋白质网络中的功能子团等等。深入研究网络的社区结构不仅有助于揭示错综复杂的真实网络是怎样由许多相对独立而又互相关联的社区形成的,使人们更好地理解系统不同层次的结构和功能特性,而且具有重要的实用价值。例如,社会网中的社区可用于揭示具有共同兴趣、爱好或社会背景的社会团体;蛋白质网络中的社区结构可用于发现生物系统中功能相关的结构单元;万维网中的社区结构可用于提高网络搜索的性能和准确性,实现信息过滤、热点话题跟踪和网络情报分析等。因此,社区发现是复杂网络领域中的一个非常重要的研究方向。
目前,社区发现研究的重点和焦点发生了一些变化,针对当前互联网技术推动下的在线社交网络等社会网络环境中的网络拓扑及社区结构的若干特点,社区发现的研究面临着若干挑战,如:要求探索同时属于多个社区的社区重叠性分析、大型网络局部社区的发现及分析、网络的多模式与多维性、网络节点角色含义的普适性研究、网络动态性分析研究。同时,当前存在的一些社区发现算法存在着这样一些问题,对大规模复杂网络难以处理,社区结构不稳定,要提前给定社区个数的方法存在很大误差,等等。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种得到较为稳定的社区结构、快速发现社交网络中潜在的社区结构的基于改进密度峰值的多粒度社区发现方法。本发明的技术方案如下:
一种基于改进密度峰值的多粒度社区发现方法,其包括以下步骤:
1)、采用改进的密度峰值聚类算法与改进的leadingtree思想,形成包含所有节点的最粗粒度下的大型社区;改进的密度峰值聚类算法改进在:对密度峰值聚类的距离度量公式替换为能代表社交成员间关系的拓扑结构距离;,leadingtree思想主要体现在:将社交的所有节点,通过leadingtree算法将真实社交网络中复杂的关系简化为联系强烈的从属拓扑结构。
2)、根据定义的粒化规则进行粒层的细化,采用分解机制将步骤1)最粗粒度下的大型社区分解为多个规模较小的社区;
3)、根据最终社区中心点集fct进行社区网络粒层的划分,同时进行最优求解粒层的寻优,粒层划分终止即寻优结束后,得到最终的社区结构。
进一步的,所述改进后的密度峰值聚类算法进行社交网络节点的聚类处理,得到γ中心点决策图,聚类后形成的引导树代表全局社区拓扑结构图,因为每个成员链接到与其可达且社会重要度比其更大的成员,该全局社区拓扑图视为最粗粒度的问题求解空间。
进一步的,步骤1)改进的密度峰值算法具体为:
设数据点i,其密度值ρi由以下公式(1)计算:
其中dij是节点i与节点j的距离,采用欧式距离来计算二维数据点的距离,dc是截断距离;数据点i的与密度吸引点即密度比它大且相对距离比它更大的点距离计算为公式(2):is表示数据集
其中,
将密度峰值算法中距离dij,采用社交网络中成员间的拓扑结构来替换,用节点间的拓扑距离来替代dij,社交网络的拓扑距离如下所示:
γ(i)和γ(j)分别代表社交网络节点i和节点j的邻接节点集,如果节点i和节点j之间不可达,则dij=∞;若节点i和节点j之间可达,但二者不存在其它公共节点,则dij=1;若节点i和节点j之间可达且存在多个公共节点,则dij<1。
进一步的,步骤2)根据定义的粒化规则进行粒层的细化,采用分解机制将步骤1)最粗粒度下的大型社区分解为多个规模较小的社区,具体包括如下步骤:
s21:采用冗余法从γ决策图中选择多个中心,构成潜在社区中心集合ct;
s22:计算ct中每个中心点引导的聚簇sc;
s23:对ct中的每个点,计算sc与从全局引导图t中截去sc剩余部分的相似度;
s24:根据具体网络的分布设定阈值thres,进行聚簇间相似程度的控制;
s25:从sc中选择相似度小于阈值thres且距离阈值thres最远的中心点作为一个社区中心,加入最终社区中心点集合fct,同时将改点从ct中移除,令t=t-sc;
s26:重复步骤s25,直至到达终止条件:ct中没有潜在中心的相似度小于阈值,完成真实社区中心节点的寻找。
进一步的,所述步骤s23计算sc(i)与t-sc(i)的相似度公式为:
similarity(sc,t-sc)=ri(sc,t-sc)*rc(sc,t-sc)α(5)
其中,ri(sc,t-sc)表示sc与t-sc的相对互连性,rc(sc,t-sc)表示sc与t-sc的相对近似度,α表示相对互连性与相对近似度之间的重要程度,取值范围为[0,1],α=1表示二者同等重要;
其中,ec(sc,t-sc)表示sc与t-sc的绝对互连性,sc与t-sc中相连边的总权重,ec(sc)和ec(t-sc)分别代表sc与t-sc内部的边权重和,
进一步的,所述最终社区中心集fct的计算过程:对于
本发明的优点及有益效果如下:
本发明提出一种基于改进密度峰值的多粒度社区发现方法,吸收了密度峰值聚类算法的优点,同时改进了密度峰值聚类算法的缺点,采用粒计算以及大范围寻优的思想构建一种任务分解求解机制,采用这种机制进行社交网络社区结构的发现,避免提前给定社区中心个数带来的不确定性问题,同时解决社区中心难以确定的问题,从一定程度上揭示了社交网络内部的层次关系,能快速准确地发现网络中具有的层次结构。具体的本发明有以下优点:
1、本发明能克服dpc聚类中易产生中心点选择失效引发的一系列归类错误问题。
2、本发明是基于改进密度峰值快速聚类的方法,结合密度峰值聚类算法的优点,能快速发现社交网络中潜在的社区结构。
3、本发明具有一定的扩展性,本方法提出的基于密度峰值算法和leadingtree思想的判别分解机制可视为一种任务处理的框架,可适用于一类问题的求解。
4、本发明采用基于粒计算的思想的方法进行社区结构的发现,通过结合粒计算层次结构的思想很好地刻画了社交网络中的社区结构,得到较为稳定的社区结构。
5、本发明给出的粒化机制能够形成多个粒层上的社区结构分布,每个粒层上的社区结构分布都具有可理解性。
附图说明
图1是本发明的优选实施例的技术框架;
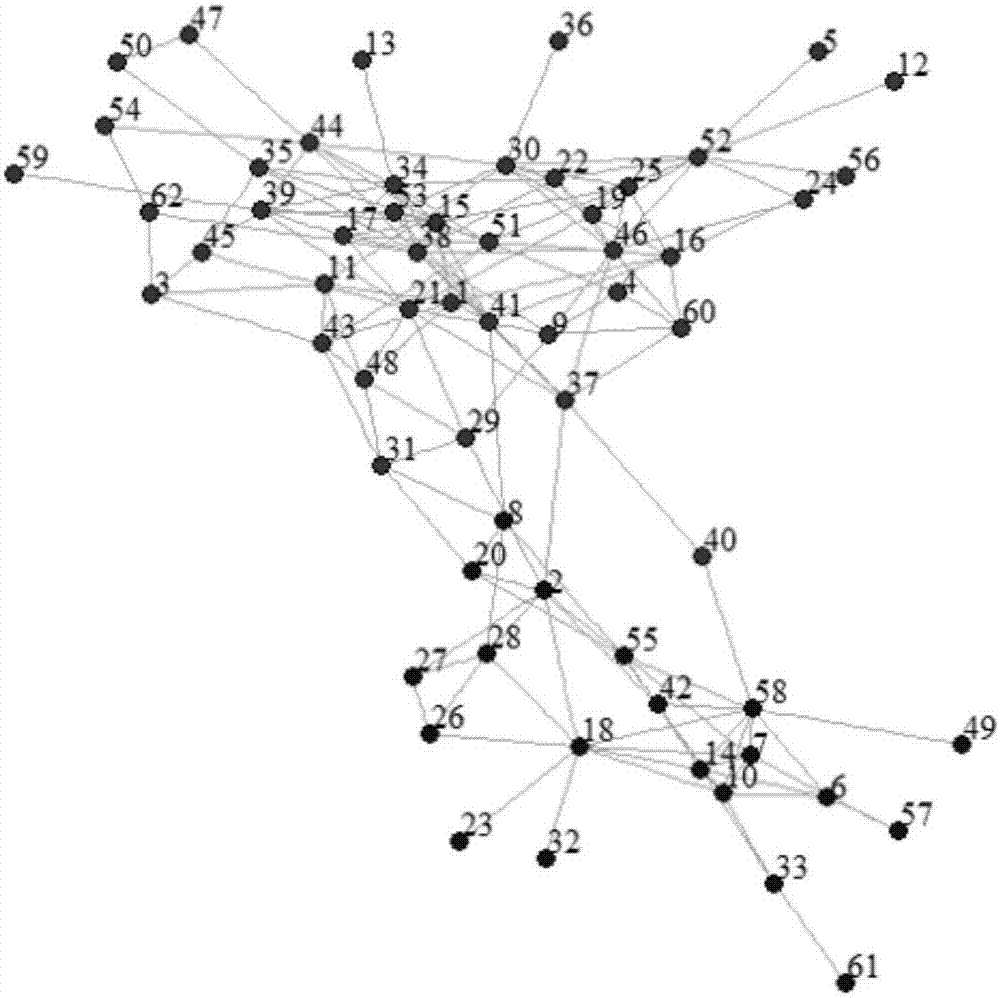
图2是本发明优选实施例中海豚关系网络真实拓扑结构;
图3是本发明优选实施例中海豚关系网络的全局社区结构;
图4是本发明优选实施例中海豚关系网络的社区结构由粗到细的演化;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
本发明如图1所示,本发明的具体操作步骤,核心步骤有三个:步骤一,采用改进的密度峰值聚类算法与leadingtree思想,形成包含所有节点的最粗粒度下的大社区;步骤二,通过步骤一得到了最初粒度下的社区划分,即所有成员同属一个大型社区,在步骤二中,主要讨论通过什么方法将最粗粒度下的大型社区,分解为多个规模较小的社区,该方法可称作粒化规则或分解机制;步骤三,根据最终社区中心点集fct进行社区网络粒层的划分,同时分析最优求解粒层,粒层划分终止后,可得到最终的社区结构。
进一步,所述改进密度峰值聚类算法的具体过程如下:
设数据点i,其密度值ρi由以下公式(1)计算:
其中dij是节点i与节点j的距离,通常采用欧式距离来计算二维数据点的距离,dc是截断距离,取值通常为1%到2%。
数据点i距密度吸引点(密度比它大且相对距离比它更大的点)距离计算为公式(2):
其中,
要将dpc应用到社交节点的聚类中,首先要解决的问题就是算法中距离公式的等价替换,因为在dpc原生算法中,多用于聚类二维的数据点,通过欧式距离来刻画数据点间的距离。本发明中,将密度峰值算法中距离dij,采用社交网络中成员间的拓扑结构来替换,用节点间的拓扑距离来替代dij。社交网络的拓扑距离如下所示:
γ(i)和γ(j)分别代表社交网络节点i和节点j的邻接节点集。如果节点i和节点j之间不可达,则dij=∞;若节点i和节点j之间可达,但二者不存在其它公共节点,则dij=1;若节点i和节点j之间可达且存在多个公共节点,则dij<1。
进一步,所述改进leadingtree继承的dpc算法聚类中心难以确定同时易发生归类错误的缺点,本发明提供以下技术方案进行改进:
采用上一步技术方案改进后的dpc算法,适用于社交网络的节点聚类。在进行社交网络节点的聚类处理后,可得到γ中心点决策图。根据leadingtree形成的引导树代表全局社区拓扑结构图,呈现出一定的聚簇性,因为每个成员链接到与其可达且社会重要度比其更大的成员,该全局社区拓扑图视为最粗粒度的问题求解空间;
技术方案给出一种粒化机制(分解机制)的描述,用以讨论将最粗粒度下的全局社区结构粒化为细粒度下的独立社区结构,同时对上面提到的pdc算法缺点进行改进。
根据γ中心点决策图,选择冗余的多个潜在社区中心,构成集合ct。γ中心点决策图,由γ=ρ×δ值由大到小排列,γ值越大,说明改点具有较大的局部密度,或较远的距离,或二者同时兼具,那么它可能成为社区中心的几率更大。
对于潜在社区中心集ct,计算ct中每个节点在全局社区结构图中所引领的节点,构成多个节点簇sc。
sc(i)={t∈t|nn(t)==ct(i),i∈(1,sizeof(ct))}(4)
对于潜在社区中心集ct中的每一个节点i,计算sc(i)与t-sc(i)的相似度,若两者的相似度小于设定阈值,则说明两个聚簇的相似小,可以分离独立成簇,节点i可能是一个真实的社区中心节点,将其存入最终社区中心集fct中,同时将节点i从潜在社区中心集ct移除,将由节点i引导的社区节点集从全局社区结构t中移除,重复该操作,直到ct中不存在小于设定阈值的潜在中心点存在。
该过程得简要描述为,每次从潜在社区中心集ct中,选择一个最可能是最终社区中心的节点,完成一次操作后,更新潜在社区中心集ct以及全局社区结构t,重复操作,直至找出ct中所有可能的最终社区中心节点。该方法的好处在于,检查了潜在社区集中每个节点成为最终社区中心的可能,不会漏选任何一个可能的最终社区中心点。同时,在分离全局社区结构t前,加入分离是否合理的判断,很好地解决了直接在leadingtree算法上进行分类易产生的归类错误的问题。具体实施步骤如下:
计算sc(i)与t-sc(i)的相似度:
similarity(sc,t-sc)=ri(sc,t-sc)*rc(sc,t-sc)α(5)
其中,ri(sc,t-sc)表示sc与t-sc的相对互连性,rc(sc,t-sc)表示sc与t-sc的相对近似度,α表示相对互连性与相对近似度之间的重要程度,取值范围为[0,1],α=1表示二者同等重要,在本技术中选择α=1。
其中,ec(sc,t-sc)表示sc与t-sc的绝对互连性,sc与t-sc中相连边的总权重,ec(sc)和ec(t-sc)分别代表sc与t-sc内部的边权重和。
计算ct中每个节点的相似性:
similarity(i)=similarity(sc(i),t-sc(i))(8)
根据具体的社交网络问题设定合适的阈值thres,该阈值由人工给定,在一定程度上能够较好的控制分类结果。
最终社区中心集fct的计算过程:对于
如图2所示,为实施例海豚关系网社区结构的发现的真实社区结构。海豚关系网也是社会网分析中常用的一个真实网络,图中节点代表一个海豚,边表示两个海豚之间接触频繁,共有62个节点、159条边。图中不同颜色的节点代表属于不同家族的海豚成员,较大的海豚家族包含42个成员节点,而较小的家族仅包含20个节点。
对图3所述的海豚关系网,进行步骤一的操作,得到适用于社交网络的密度峰值聚类算法的中间结果,同时采用leadingtree算法形成全局社区结构。通过技术方案中介绍的局部密度以及距离刻画公式,技术海豚关系网中每个节点的密度以及距离密度吸引点的距离,同时得到中间结果nn,即每个节点的密度吸引点集合,具有最大γ=ρ×δ值的点,视为全局社区结构唯一的中心点。根据下表所示的中间结果,生成全局社区结构引导图,如实施例用图3所示。
表1
根据冗余的思想,尽可能选择包含所有社区中心点的初始潜在中心点集。在具体的海豚关系网中,根据计算每个节点的γ=ρ×δ值,将γ由大到小排列,选择初始潜在中心集ct={46,15,14,38,34,52}。同时,给定相似度控制阈值thres=0.5,若两个社区的相似度不超过一半,则判定两个社区是独立的。
对
表2
从ct中选择similarity(i)<0.5且取得最大|similarity(i)-0.5|值的点作为最终社区中心点,将节点i加入fct,同时将节点i从ct中移除,将sc(i)从t中移除;循环操作,直至不存在更多的i∈ct使similarity(i)<thres终止。
在海豚关系网中,第一次操作后,fct={14};
循环进行第二次操作,判断是否触发终止条件,未触发,则fct={14,52};
循环进行第三次操作,判断是否触发终止条件,触发;程序终止。
三次循环操作过程如下表3所示:
表3
根据最终社区中心点集fct={14,52}对初始全局社区结构图进行划分,依次得到下一层细粒度上的多个小社区结构,可从多个划分粒层中选取适合问题求解的粒层,选择出最优的社区结构划分依次从同时分析最优求解粒层,粒层划分终止后,可得到最终的社区结构。海豚关系网实施例的粒化过程如图4所示,在第二粒层上可得到与真实网络中最为一致的社区结构,大家族41个节点,小家族21个节点。。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!