一种自适应可能C均值聚类的茶叶中红外光谱分类方法与流程
本发明涉及茶叶品种分类领域,具体涉及一种自适应可能c均值聚类的茶叶中红外光谱分类方法。
背景技术:
茶叶是茶树的叶子经过一定工艺加工而成,人们喜欢将茶叶泡成饮品饮用。随着出口贸易市场的开放和国内市场流通的增多,快速准确的茶叶品种鉴别方法变得至关重要。然而传统的茶叶鉴别方法一般是由经验丰富的业内人士人工鉴别,效率和准确率都比较低下。
中红外光谱检测技术作为一种快速无损检测技术,近年来应用于食品的检测分析中。中红外光谱的波数范围在4000cm-1~400cm-1之间,大多数的无机化合物和有机化合物的化学键振动的基频均在此区域。不同的分子中官能团、化合物的类别和化合物的立体结构,其中红外吸收光谱不尽相同。中红外光谱技术以其方便、快速、高效、无损、低成本等特点成为检测食品和药品的有效检测技术。
改进型可能c-均值(ipcm)聚类方法(zhang,j.-s.,leung,y.-w.,improvedpossibilisticc-meansclusteringalgorithms,ieeetrans.fuzzysystems,2004,12(2):209-217)解决了模糊c均值聚类(fcm)对噪声敏感和可能c-均值聚类(pcm)一致性聚类的缺点;但ipcm的目标函数中使用的是欧氏距离,在使用基于欧氏距离的ipcm处理不规则聚类形状的数据时,聚类准确率会受到影响。
用中红外光谱仪采集多个品种茶叶的中红外光谱数据在进行数据降维后,各品种茶叶数据的边界往往是不规则形状的,如果用基于欧氏距离的ipcm来聚类分析茶叶的中红外光谱数据则效果往往不理想。
技术实现要素:
本发明是针对现有的ipcm聚类方法在聚类茶叶中红外光谱数据时存在的缺点,提出一种自适应可能c均值聚类的茶叶中红外光谱分类方法,相比原有的ipcm聚类方法,本发明的一种自适应可能c均值聚类的茶叶中红外光谱分类方法采用基于模糊协方差矩阵的自适应距离测度来代替ipcm聚类方法中的欧氏距离测度。本发明具有检测速度快,检测准确率高,绿色无污染,所需茶叶样本少等优点。
本发明依据的原理:研究表明茶叶的中红外漫反射光谱包含了茶叶内部的组分信息,不同品种茶叶所对应的中红外漫反射光谱不同,因而可以采用聚类方法将不同品种的茶叶中红外光谱进行分类。
一种自适应可能c均值聚类的茶叶中红外光谱分类方法,具体包括以下步骤:
s1,茶叶样本中红外光谱采集:针对不同种类茶叶样本,用中红外光谱仪对茶叶样本进行检测,获取茶叶样本中红外漫反射光谱信息,将光谱信息存储在计算机里;中红外漫反射光谱信息是指光谱的波数范围为4001.569~401.1211cm-1,采集到每个茶叶样本的光谱是1868维的数据;将茶叶样本分为训练样本和测试样本,设置类别数为c,训练样本数为nr,测试样本数为n。
s2,用多元散射矫正(msc)对茶叶样本中红外光谱预处理。
s3,对茶叶样本中红外光谱进行降维处理和鉴别信息提取:利用主成分分析(pca)将在s2中获得的茶叶样本中红外光谱数据压缩;然后利用线性判别分析(lda)提取茶叶样本的鉴别信息。
s4,对s3中包含鉴别信息的测试样本用自适应可能c均值聚类方法以鉴别测试样本中的茶叶品种;
s4.1,初始化:设置权重指数m、w,类别数c,其中m>1、w>1;设置循环计数r的初始值和最大迭代次数rmax;设置迭代最大误差参数ε;运行模糊c均值聚类得到的模糊隶属度值和类中心值分别作为初始的模糊隶属度值uik(0)和类中心值νi(0);
s4.2,计算第r(r=1,2,…,rmax)次迭代时的典型值:
s4.3,计算第r次迭代时的模糊隶属度值uik(r):
s4.4,计算第r次迭代时第i类的类中心值νi(r):
s4.5,循环计数增加,即r=r+1;若满足条件:||v(r)-v(r-1)||<ε或r>rmax则计算终止,否则继续s4.2,根据计算得到的模糊隶属度值和典型值,实现不同种类茶叶分类。
本发明的有益效果:
1、本发明的一种自适应可能c均值聚类的茶叶中红外光谱分类方法,利用样本到类中心的距离范数,在聚类边界不规则的中红外光谱数据方面要优于改进型可能c-均值(ipcm)聚类方法,具有聚类准确率高,聚类速度快的优点。
2、本发明采用样本隶属于类别的典型值,在聚类包含噪声数据的中红外光谱数据方面优于模糊c均值聚类(fcm),可快速实现不同品种的中红外光谱的快速和准确鉴别。
附图说明
图1是本发明的流程图;
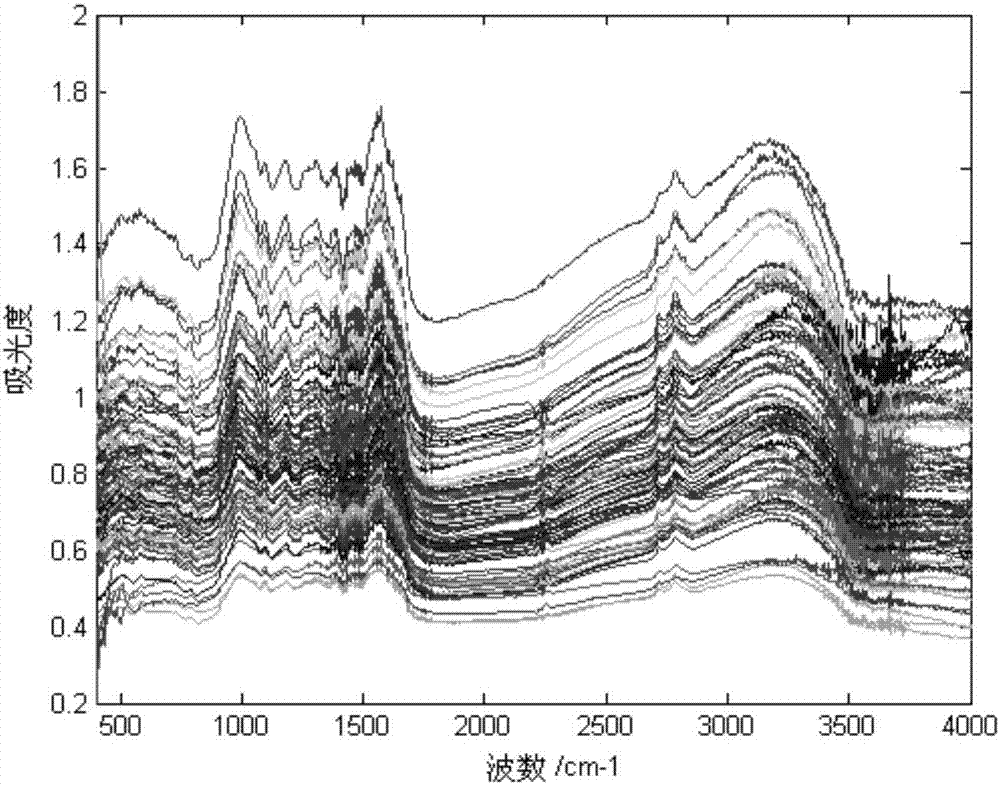
图2是茶叶的中红外光谱图;
图3是msc处理后的茶叶中红外光谱图;
图4是茶叶的中红外光谱经lda提取鉴别信息后得到的测试样本数据图;
图5是初始的模糊隶属度值;
图6是一种自适应可能c均值聚类方法产生的模糊隶属度;
图7是一种自适应可能c均值聚类方法产生的典型值。
具体实施方式
下面结合附图和具体实施方式对本发明的装置及方法做进一步说明。
如图1所示,一种自适应可能c均值聚类的茶叶中红外光谱分类方法,包括步骤:
步骤一、茶叶样本中红外光谱采集:针对不同种类茶叶样本,用中红外光谱仪对茶叶样本进行检测,获取茶叶样本中红外漫反射光谱信息,将光谱信息存储在计算机里。
实验过程中尽量保持室内的温度和湿度基本一致,中红外漫反射光谱信息是指光谱的波数范围为4001.569~401.1211cm-1,采集到每个茶叶样本的光谱是1868维的数据;将茶叶样本分为训练样本和测试样本,设置类别数c,训练样本数为nr和测试样本数为n。
步骤二、用多元散射矫正(msc)对茶叶样本中红外光谱预处理:
用多元散射矫正(msc)预处理,有效地减少茶叶样本的散射影响,增强了与茶叶样本相关的光谱吸收信息,提高茶叶鉴别的识别率;
步骤三、对茶叶样本中红外光谱进行降维处理和鉴别信息提取:
利用主成分分析(pca)将在步骤二中获得的茶叶样本中红外光谱数据压缩;然后用线性判别分析(lda)提取茶叶样本的鉴别信息。
步骤四、对步骤三中包含鉴别信息的测试样本,使用自适应可能c均值聚类方法,以鉴别测试样本中的茶叶品种。
步骤四的具体过程如下:
a、初始化过程:设置权重指数m(m>1)和权重指数w(w>1),类别数c;设置循环计数r的初始值和最大迭代次数为rmax;设置迭代最大误差参数ε;运行模糊c均值聚类得到的模糊隶属度值和类中心值分别作为初始的模糊隶属度值uik(0)和类中心值νi(0);
b、计算第r(r=1,2,…,rmax)次迭代时的典型值:
其中:tik是样本xk隶属于类别i的典型值,tik(r)是第r次迭代计算的典型值,
c、计算第r次迭代时的模糊隶属度值uik(r)
其中,uik是样本xk隶属于类别i的模糊隶属度值,uik(r)是第r次迭代计算的模糊隶属度值;
d、计算第r次迭代时的第i类的类中心值νi(r)
其中νi(r)是第r次迭代计算的类中心vi的值,由c个类中心值组成类中心矩阵v(r)=[ν1(r),ν2(r),…,νc(r)];
e、循环计数增加,即r=r+1;
若满足条件:||v(r)-v(r-1)||<ε或r>rmax,则计算终止,否则继续步骤b;根据以上计算结果可得到模糊隶属度值和典型值并利用它们最终实现不同种类茶叶分类。
本发明的一种自适应可能c均值聚类的茶叶中红外光谱分类方法适用于对茶叶品种的鉴别,例如:毛尖、竹叶青、龙井、铁观音等茶叶品种的鉴别。因为不同品种茶叶,其内部组分不同,因此漫射中红外光谱也有所不同,为实现茶叶品种的鉴别提供了条件。为方便叙述,选取峨眉山茶叶、乐山市优质竹叶青和劣质竹叶青为实验对象。
实施例1
步骤一、茶叶样本中红外光谱采集:将ftir-7600型傅里叶中红外光谱分析仪开机预热1个小时,扫描次数为32,光谱扫描的波数4001.569cm-1~401.1211cm-1,扫描间隔为1.928cm-1,分辨率为4cm-1;茶叶样本为:峨眉山茶叶、乐山市优质竹叶青和劣质竹叶青。茶叶经研磨粉碎,再用40目筛进行过滤后,各取0.5g分别与溴化钾1:100均匀混合;每个样本取混合物1g进行压膜,然后用光谱仪扫描3次,取3次的平均值作为样本光谱数据。采集光谱时环境温度和相对湿度保持相对稳定,每种茶叶采集32个样本,共获得96个样本,每个样本为一个1868维的数据。每个品种的茶叶样本选取22个为测试集,则测试样本数n为66;剩余10个样本为训练集,则训练样本数nr为30;测试集为待鉴别的茶叶样本,训练集为已知品种的茶叶样本;设置类别数c=3;茶叶样本的中红外光谱如图2所示。
步骤二、对茶叶样本中红外光谱预处理:用多元散射校正(msc)对茶叶样本中红外光谱进行预处理,预处理后的茶叶中红外光谱图如图3所示。
步骤三、对茶叶样本中红外光谱进行降维处理和鉴别信息提取:利用主成分分析(pca)将在步骤二中获得的茶叶样本中红外光谱数据压缩;然后用线性判别分析(lda)提取茶叶样本的鉴别信息。
因为前14个主成分累计可信度大于98%,所以采用主成分分析方法(pca)将茶叶样本中红外光谱进行特征分解得到前14个特征向量和14个特征值;每个特征向量都是1868维的数据,特征值为:λ1=293.91、λ2=129.02、λ3=19.00、λ4=14.88、λ5=6.43、λ6=3.82、λ7=2.00、λ8=1.4、λ9=1.07、λ10=0.63、λ11=0.40、λ12=0.32、λ13=0.27、λ14=0.23;将茶叶样本中红外光谱投影到14个特征向量上得到14维的数据,即从1868维压缩到14维。
设置鉴别向量数为2,采用线性判别分析(lda)提取步骤三中14维数据的鉴别信息后得到包含鉴别信息的训练样本和测试样本数据,其中测试样本数据如图4所示。
步骤四、对步骤三中包含鉴别信息的测试样本用一种自适应可能c均值聚类方法以鉴别测试样本中的茶叶品种:
a、初始化过程:设置权重指数m(m>1)和权重指数w(w>1),类别数c;设置循环计数r的初始值和最大迭代次数为rmax;设置迭代最大误差参数ε;运行模糊c均值聚类得到的模糊隶属度值和类中心值分别作为初始的模糊隶属度值uik(0)和类中心值νi(0)。
初始化的数值设置:由步骤一可知:类别数c=3(即三个类别),测试样本数n=66;设置权重指数m=2,w=2,迭代次数初始值r=0和最大迭代数rmax=100,误差上限值ε=0.00001,测试样本的维数d为2;对步骤四的两组一维测试数据进行模糊c均值聚类(fcm),fcm运行终止后的聚类中心作为一种自适应可能c均值聚类方法的初始聚类中心,则初始聚类中心νi(0)为:ν1(0)=(-0.1580,0.0403)、ν2(0)=(-0.0020,0.0049)、ν3(0)=(0.1194,-0.0056);初始的模糊隶属度值uik(0)如图5所示。
b、由公式(1)-(4)计算第r(r=1,2,…,rmax)次迭代时的典型值。
c、由公式(5)计算第r次迭代时的模糊隶属度值uik(r)。
d、由公式(6)计算第r次迭代时第i类的类中心值νi(r)。
e、循环计数增加,即r=r+1;若满足条件:||v(r)-v(r-1)||<ε或r>rmax则计算终止,否则继续步骤b;根据以上计算结果可得到模糊隶属度值和典型值并利用它们最终实现不同种类茶叶分类。
实验结果为:迭代终止时r=51,
以上所述对本发明进行了简单说明,并不受上述工作范围限值,只要采取本发明思路和工作方法进行简单修改运用到其他设备,或在不改变本发明主要构思原理下做出改进和润饰的等行为,均在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!