一种模糊协方差学习网络的电子鼻鉴别食醋品种方法与流程
本发明涉及食醋品种鉴别领域,具体涉及一种模糊协方差学习网络的电子鼻鉴别食醋品种方法。
背景技术:
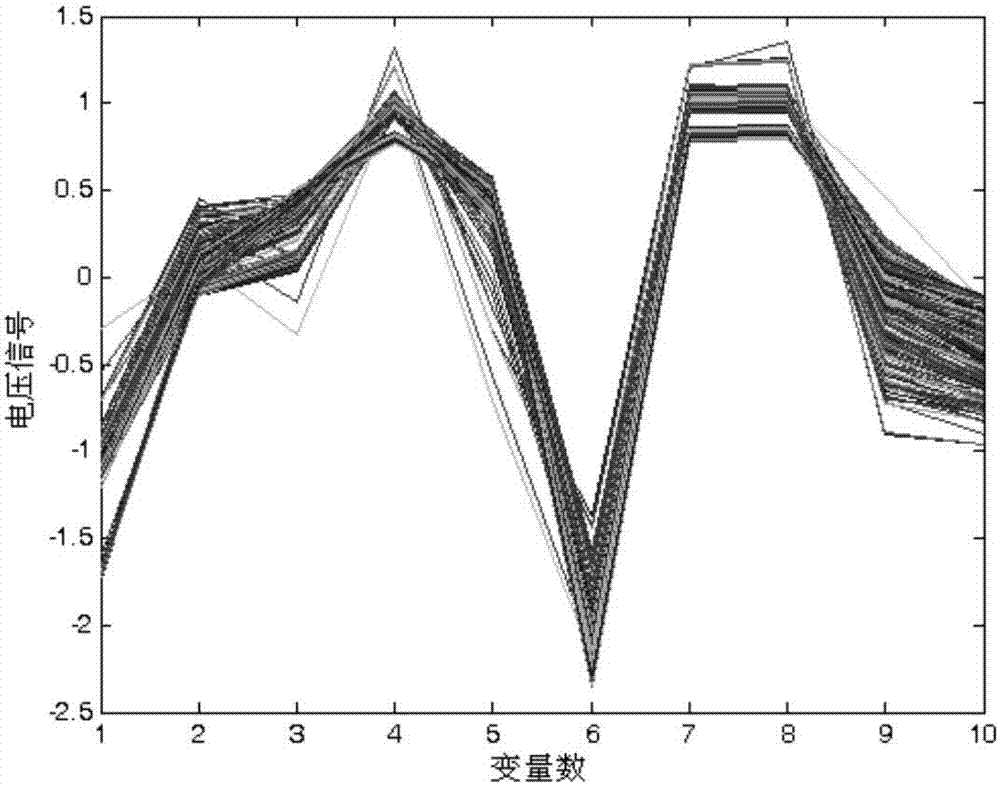
:食醋是很多家庭的调味品之一,现在市场上有各种各样的食醋,不同品牌的食醋以及不同酿造方法和不同酿造原料,则食醋的品质和风味不尽相同。随着广大消费者对食醋的品质有了更多的要求,对于食醋品质和品种的区分研究具有重要的研究意义和研究价值。一般来说,对气味辨别的方法是由一些经过训练,并且有着多年工作经验的人来进行,而对气味的客观测定方法一般是使用气相色谱法。但是这两种方法都有缺点:专业人员主观性更高,且培养专门从事鉴别的专业人员代价昂贵;采用气相色谱法进行实验,不仅过程复杂,而且他对实验的环境要求十分苛刻,用气相色谱法进行现场检测有一定的局限性。与这两种方法相比,电子鼻具有显著的优点,所以采用电子鼻技术对食醋进行快速、准确的定性分析,具有很大的应用潜力。张厚博等从传感器矩阵中获得数据(张厚博,梅笑冬,赵万,王彪,卢革宇.用于食醋品质预评价的电子鼻研究[j].传感器与微系统,2013,32(3):62-64.),再对这些数据使用主成分分析(pca)和线性判别分析(lda)对五种食醋的电子鼻数据进行分析和处理,可以较好的把不同品种的食醋进行分类,为食醋品质的预评价提供了一种便捷的方法。pca主要是将多维的电子鼻数据进行降维,但是降维只是数据的压缩,并不能很明显的提升食醋分类的准确率。lda用于提取电子鼻数据的判别分析信息,对于提升食醋分类的准确率有很大的帮助;但是,lda也是一种数据降维处理方法,并不是一种分类器。2014年,王巍巍等人设计了pca和bp混合神经网络算法的电子鼻系统(王巍巍,张赛男.基于pca与bp混合神经网络算法的电子鼻系统[j].传感器与微系统,2014,33(4):90-94.),先用pca将食醋的电子鼻数据降维,然后用用bp神经网络对pca所得到的新变量进行模式识别从而实现食醋品种的分类。虽然神经网络(bp)可通过学习样本数据能够实现非线性的分类,但是神经网络存在局部极小点、过学习等问题。技术实现要素:针对目前食醋品种分类所用电子鼻分类方法存在的问题,本发明提出了一种模糊协方差学习网络的电子鼻鉴别食醋品种方法,该方法提供了一种简单、方便、快速、准确的电子鼻食醋品种分类方法。本发明依据的原理:被测食醋样本挥发出的气体作用于电子鼻传感器阵列,引起传感器输出电压的变化;不同品种的食醋样本,因为其食醋酿造方法和酿造原料的不尽相同,从而引起其挥发出的气味存在差别,因而导致电子鼻传感器输出电压存在差异,根据此差异用合适的数据处理方法即可实现不同品种的食醋样本的分类。一种模糊协方差学习网络的电子鼻食醋品种分类方法,具体包括以下步骤:s1,利用电子鼻系统采集不同品种的食醋样本;s2,用标准正态变量变换处理进行预处理,再用主成分分析(pca)进行数据压缩和线性判别分析(lda)提取训练样本的鉴别信息;pca进行数据压缩得到的6维数据分为训练样本和测试样本,训练样本用来模式训练,测试样本用来检验模式识别正确率;s3,用一种模糊协方差学习网络进行食醋品种分类,具体步骤如下:s3.1,参数初始化:设置食醋品种数为c(+∞>c≥2),初始权重指数m0(+∞>m0>1),最大迭代数rmax,误差上限值ε,训练样本数为n1,测试样本数n2,设置初始类中心和初始模糊隶属度;s3.2,计算第r-1(r=1,2,…,rmax)次迭代时的距离范数其中为第r-1次迭代时第k(k=1,2,3,…,n2)个测试样本xk到类中心vi,r-1的距离,ai,r是第r次迭代时的第i个聚类中心的范数矩阵,d为测试样本的维数,vi,r-1为第r-1次迭代时第i类的类中心(i=1,2,……,c),uik,r-1为第r-1次迭代时测试样本xk属于第i类的模糊隶属度,sfi,r是第r次迭代时第i类的模糊协方差矩阵;s3.3,计算第r次迭代时的模糊隶属度值uik,r;其中隶属度值uik,r表示第r次迭代计算时第k个样本隶属于第i类的隶属度值,mr为第r次迭代时的权重指数,且mr=m0-rδm,δm=(m0-1)/rmax;s3.4,计算第r次迭代时的学习速率αik,r,s3.5,计算第r次迭代时的类中心vi,r其中vi,r为第r次迭代计算时第i类的类中心,vi,r-1为第r-1次迭代计算时第i类的类中心;s3.6,当maxi||vi,r-vi,r-1||<ε或者r=rmax-1时,迭代结束,否则返回s3.2,继续迭代计算;当迭代收敛后,根据最终的模糊隶属度uik,r判别测试样本xk属于哪一类,即xk属于哪个品种的醋。本发明的有益效果是:1、本发明采用模糊协方差学习网络进行食醋电子鼻信号的分类处理,由于采用模糊隶属度进行分类,使得在处理含噪声电子鼻信号方面要优于传统分类方法。2、本发明采用模糊协方差矩阵的距离范数,对于分类复杂分布形状的电子鼻信号具有优势,分类准确率得到很大提高。附图说明图1是本发明方法的流程图;图2是食醋样本经过标准正态变量变换处理(snv)处理后得到的数据图;图3是食醋样本经过pca压缩后得到的6维数据图;图4是测试样本经过lda处理后得到的数据图;图5是初始模糊隶属度图;图6是迭代收敛后的模糊隶属度图。具体实施方式下面结合附图和具体实施方式对本发明的装置及方法做进一步说明。如图1所示,用于食醋品种分类的方法主要步骤包括:步骤一、利用电子鼻系统采集不同品种的食醋样本。在室温20℃、湿度40%的环境下,将电子鼻通电,传感器预热10分钟后,向烧杯中倒入10ml食醋并将其放入箱体中,迅速盖上箱盖、计时;分别在60分钟、65分钟、70分钟的三个时间点利用labview编写的上位机程序进行电子鼻数据采集,取三次采集结果的平均值作为一个食醋样本数据;完成一次食醋样本采集后,打开箱盖使得各传感器恢复初始状态,然后重复采集食醋样本过程。数据说明:本例中对5类食醋(镇江陈醋、镇江香醋、山西陈醋、恒顺香醋、保宁醋),每类食醋有51个样本,共采集得到255个食醋电子鼻样本数据,将实验采集数据结果保存;每个样本为1×10(一次实验得到十个传感器响应数据)的向量,总样本为255×10的数据矩阵。步骤二、用标准正态变量变换处理(snv)进行预处理,再用主成分分析(pca)进行数据压缩和线性判别分析(lda)提取训练样本的鉴别信息。1、对步骤一的原始数据进行预处理及用主成分分析(pca)进行数据压缩把从步骤一中所得到的原始数据矩阵(255x10)进行标准归一化处理,结果为如图2所示;然后通过进行主成分分析(pca)处理,计算得到pca前6个特征值:39.6945、28.7220、10.5444、4.0413、0.4454、0.2454,pca的特征向量为10×6的数据矩阵,如表1所示;总样本为255×10的数据矩阵经过pca压缩后得到如图3所示的6维数据,即变换为255×6的数据矩阵。表1pca的特征向量1234561-0.1937-0.79290.03100.05350.15940.05662-0.2443-0.1355-0.3081-0.36600.17720.41853-0.03820.1644-0.6384-0.28057-0.46862-0.243384-0.175660.0188880.227440.091881-0.14014-0.2258550.183280.14437-0.3970.787330.203630.155096-0.345560.542670.26536-0.125480.261470.365977-0.163540.0273580.24850.11369-0.21355-0.268278-0.168870.0314880.255840.13074-0.11879-0.3012290.62227-0.0661530.29888-0.083701-0.442530.4627100.52430.06640.0164-0.32140.5818-0.4202将pca处理后的6维数据分为训练样本和测试样本,将每类食醋的51个样本中25个作为训练样本,剩余的26个样本作为测试样本;将训练样本用来模式训练,测试样本用来检验模式识别正确率;训练样本总数为n1=125个,每个样本为1×6的向量,得到125×6的数据矩阵;测试样本总数为n2=130个,每个样本为1×6的向量,得到130×6的数据矩阵。2、用线性判别分析(lda)提取训练样本的鉴别信息通过使用线性判别分析提取训练样本125×6数据矩阵的鉴别信息,计算得到了lda前4个特征值为:118.0375、14.0824、9.4818、0.6353,4个lda的鉴别向量组成6×4的数据矩阵,如表2所示;将测试样本130×6的数据矩阵投影到lda的鉴别向量上可得到变换后的测试样本为如图4的130×4的数据矩阵。表2lda的4个鉴别向量12341-0.2382-0.2553-0.0149-0.00522-0.76360.1297-0.0228-0.01533-0.11470.0765-0.33590.221940.4322-0.0776-0.5269-0.14865-0.3631-0.84720.58580.88096-0.16770.43380.51520.3902步骤三、用一种模糊协方差学习网络进行食醋品种分类,具体步骤如下:a、初始化:设置食醋品种数为c(+∞>c≥2),初始权重指数m0(+∞>m0>1),最大迭代数rmax,误差上限的值ε,训练样本数为n1,测试样本数n2,设置初始类中心vi,0和初始模糊隶属度uik,0;具体参数设置为:食醋品种数为c=5,初始权重指数m0=2,最大迭代数rmax=100,误差上限的值ε=0.00001,训练样本数为n1=125,测试样本数n2=130。初始类中心vi,0和初始模糊隶属度uil,0计算如下:vi,0=x_mean(i)(1)以训练样本每类均值作为每类的初始类中心,x_mean(i)为第i(i=1,2,3,4,5)类的训练样本的均值,vi,0为第i类的初始类中心,vj,0为第j(j=1,2,3,4,5)类的初始类中心;uil,0为第l(l=1,2,3,…,n1)个训练样本xl隶属于第i类的初始模糊隶属度,uil,0如图5所示。b、计算第r-1(r=1,2,…,rmax)次迭代时的距离范数其中:上式中为第r-1次迭代时第k(k=1,2,3,…,n2)个测试样本xk到类中心vi,r-1的距离,ai,r是第r次迭代时的第i个聚类中心的范数矩阵;d为测试样本的维数;xk为第k个测试样本,vi,r-1为第r-1次迭代时第i类的类中心(i=1,2,……,c),uik,r-1为第r-1次迭代时测试样本xk属于第i类的模糊隶属度,sfi,r是第r次迭代时第i类的模糊协方差矩阵。c、计算第r(r=1,2,……,rmax)次迭代时的模糊隶属度值uik,r;隶属度值uik,r表示第r(r=1,2,……,rmax)次迭代计算时第k个测试样本隶属于第i类的隶属度值,mr为第r次迭代时的权重指数,mr=m0-rδm;δm=(m0-1)/rmax;d、计算第r次迭代时的学习速率αik,re、计算第r次迭代时的类中心vi,r(i=1,2,……,c)其中vi,r为第r次迭代计算时第i(i=1,2,……,c)类的类中心,vi,r-1为第r-1次迭代计算时第i类的类中心;f、当maxi||vi,r-vi,r-1||<ε或者r=rmax-1时,迭代结束,否则返回步骤b继续迭代计算。当迭代收敛后,根据最终的模糊隶属度判别测试样本xk属于哪一类,即xk属于哪个品种的醋。计算结果:迭代收敛后的模糊隶属度uik,r如图6所示,若uik,r>0.5则判定测试样本xk属于第i类;根据图6的模糊隶属度可得食醋品种测试样本的分类准确率达100%。尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1