一种基于斜率关联度的显著变量选择方法与流程
本发明属于时间序列分析
技术领域:
,更为具体地讲,涉及一种基于斜率关联度的显著变量选择方法。
背景技术:
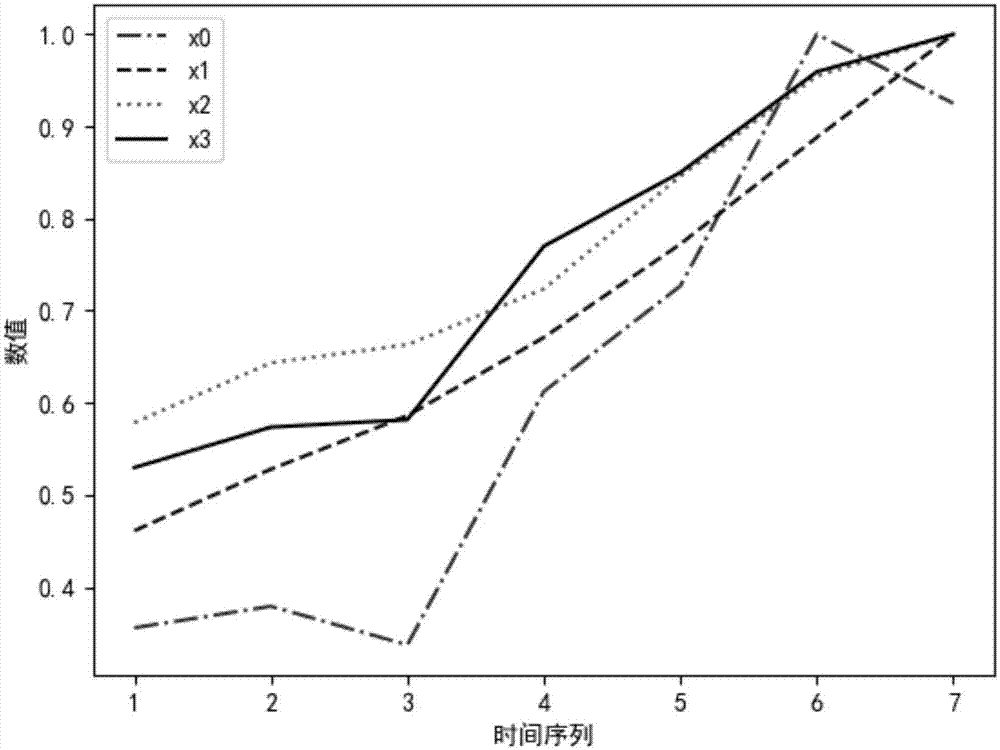
:随着计算机软件和硬件的快速发展,人们对日常生活中积累的数据信息的关注和分析也日趋增加,这些数据中大多都是与时间相关的,可以简要说是与时间序列相关的。例如,气象预报中降雨量数据序列、股票价格波动数据序列、某产品的交易或销售数据序列等等,这些数据按照时间先后组成时间序列数据。从统计意义上讲,所谓时间序列就是将某一个指标在不同时间上的不同数值,按照时间的先后顺序排列而成的数列。这种数列由于受到各种偶然因素的影响,往往表现出某种随机性,彼此之间存在着统计上的依赖关系。而从这些时间序列数据中挖掘出隐含的有价值的数据信息,有利于揭示或预测时间序列事件变化规律,从而发现历史序列数据和现今及未来数据之间的联系及相互关系,即以某种标准来度量时间序列之间的相似性,并以此为基础来分析时间序列数据之间的相似性问题目前,灰色关联分析被广泛采用,其中,邓氏关联度是最早最为经典的关联度模型。按照邓氏关联度的定义和基本思想,关联度体现的实际上是两序列曲线之间的几何相似程度,如果相似程度大,则关联度高,反之亦然。但是通常会出现以下问题:两序列在无量纲处理(如初值化、均值化等)前可能非常相似,即关联度很大,但经处理后并不相似,此时关联度就小,前后结果并不一致。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种基于斜率关联度的显著变量选择方法,通过计算斜率关联度来分析时间序列相似性,克服传统邓氏关联度模型存在的无量纲化后不能保序等问题。为实现上述发明目的,本发明一种基于斜率关联度的显著变量选择方法,其特征在于,包括以下步骤:(1)、分析历史数据,确定以特征序列作为目标变量的历史数据而构成的时间序列,以及以影响因素序列作为各影响因素的历史数据而构成的时间序列;(2)、对特征序列和影响因素序列进行异常值和缺失值处理,得到完整历史时间序列;(3)、对完整历史时间序列进行定量分析,并运用斜率关联模型计算出每个影响因素和目标变量之间的关联度;(3.1)、计算变量的斜率:其中,k=0表示目标变量,k=1,2,3,…,n,表示影响因素,n为影响因素总个数,xk(t)表示第k个变量对应的完整时间序列的第t个样本数据,δxk(t)表示第k个变量对应的完整时间序列的第t+1个样本数据和第t个样本数据的差值,σk表示第k个变量的标准差;(3.2)、计算第j个影响因素与目标变量的关联系数δij(t):其中,i=0表示目标变量,j=1,2,3,…,n,表示影响因素;(3.3)、计算第j个影响因素与目标变量的关联度γij:其中,m表示完整历史时间序列中样本数据总量;(3.4)、重复步骤(3.1)~(3.3),计算出所有影响因素与目标变量的关联度;(4)、对得到的所有关联度从大到小排序,再根据预设阈值ε,选出关联度较大的前n+ε个关联度,组成关联度序列;(5)、将关联度序列中对应的n+ε个影响因素进行专家经验论证、定性分析,最终确定n个影响因素作为选择的显著变量。本发明的发明目的是这样实现的:本发明一种基于斜率关联度的显著变量选择方法,利用斜率关联度模型,通过先计算各变量时间序列的斜率,再计算出关联度系数,得到关联度,并组成关联序,反映了关联度从大到小的排列,它的几何意义在于,曲线同一时刻变化的斜率越接近,则关联度越大,最后我们对关联度较大的影响因素作为选择的显著变量,而显著变量越大表示时间序列的相似度越高。同时,本发明基于斜率关联度的显著变量选择方法还具有以下有益效果:(1)、通过计算斜率关联度来分析时间序列相似性,克服传统邓氏关联度模型存在的无量纲化后不能保序等问题。(2)、同时通过实验结果可以发现,斜率关联度模型的准确度要比传统的邓氏关联度模型的准确度高;附图说明图1是本发明基于斜率关联度的显著变量选择方法流程图;图2是各影响因素和目标变量之间的时间序列走势图;具体实施方式下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。实施例图1是本发明基于斜率关联度的显著变量选择方法流程图。在本实施例中,如图1所示,本发明一种基于斜率关联度的显著变量选择方法,包括以下步骤:s1、分析历史数据,确定特征序列和影响因素序列;特征序列为目标变量的历史数据构成的时间序列,影响因素序列为各影响因素的历史数据所构成的时间序列。在本实施例中,通过分析某公司近7年历史数据,为了简单说明,选取了三个指标x1、x2、x3,从x1、x2、x3中找出与目的变量x0关系最为密切的指标,如表1所示;序号x0x1x2x3199.698382105913032106.26959711781411394.510653121414314171.581219818945203.6814040154920916280.2416146174823607259.251818018312460表1s2、对特征序列和影响因素序列进行异常值和缺失值处理,得到完整历史时间序列;由于经济波动、自然灾害和数据保存不规范等等原因,特征序列和影响因素序列存在异常值和缺失值,对后面的分析有很大的影响,因此需要先进行预处理,本实施例中,对于特征序列和影响因素序列中的异常值采用删除后插值的方法进行处理,对于特征序列和影响因素序列中的缺失值采用插值的办法进行处理。其中,插值可采用均值插值、拉格朗日插值等方法,本实施例中采用均值插值法。如表1所示,变量x2因为保存数据不规范,数据存在缺失的情况,因此,需要采用均值插值法,前后各取一个数据做平均值计算,最后得到完整时间序列。s3、对完整历史时间序列进行定量分析,并运用斜率关联模型计算出每个影响因素和目标变量之间的关联度;s3.1、计算变量的斜率:其中,k=0表示目标变量,k=1,2,3,…,n,表示影响因素,n为影响因素总个数,xk(t)表示第k个变量对应的完整时间序列的第t个样本数据,δxk(t)表示第k个变量对应的完整时间序列的第t+1个样本数据和第t个样本数据的差值,σk表示第k个变量的标准差;s3.2、计算第j个影响因素与目标变量的关联系数δij(t):其中,i=0表示目标变量,j=1,2,3,…,n,表示影响因素;s3.3、计算第j个影响因素与目标变量的关联度γij:其中,m表示完整历史时间序列中样本数据总量;s3.4、重复步骤s3.1~s3.3,计算出所有影响因素与目标变量的关联度;在本实施例中,结合表1,时间序列为:x0=[99.69,106.26,94.5,171.58,203.68,280.24,259.25]x1=[8382,9597,10653,12198,14040,16146,18180]x2=[1059,1178,1214,1382,1549,1748,1831]x3=[1303,1411,1431,1894,2091,2360,2460]通过步骤s3.1~s3.3的计算,可得:γ01=0.866,γ02=0.880,γ03=0.898;s4、对得到的所有关联度从大到小排序,再根据预设阈值ε,选出关联度较大的前n+ε个关联度,组成关联度序列;在本实施例中,关联度排序为:γ03>γ02>γ01;那么对应的影响因素排序为x3>x2>x1;本例中,设置n=1,ε=1,则选出关联度较大的前两个影响因素—x3和x2初步组成关联度序列。s5、将关联度序列中对应的n+ε个影响因素进行专家经验论证、定性分析,最终确定n个影响因素作为选择的显著变量,显著变量越大表示时间序列的相似度越高。实例验证结合表1所示,x3代表的统调最大负荷为所有地方电厂投入使用后所能承担的用电负荷,反映了一个地区的供电能力大小,供电能力直接体现的就是x0代表的投资额度的大小。而x2代表的全社会用电量,指当年该地区所有用电量的之和,代表该地区对电力的需求,并不能直接反应x0代表的投资额度。所以将x3选为显著变量更为的符合实际。经过定量分析和定性分析,最后选出的显著变量为:x3为了更好的说明本发明的优势,下面将和传统的邓氏关联度做对比。首先,列出两种方法的关联度对比,如表2所示:表2其中,邓氏关联度方法关联度排序为:x1>x3>x2;本发明提出的方法关联度排序为:x3>x2>x1;从以下三点来分析:1.通过曲线分析,如图2,点画线代表x0,折线代表x1,虚线代表x2,实线代表x3。从图中,明显可以看出,实线和点画线的几何形状、走向趋势最为相似,即x3与x0最关联。2.邓氏关联度方法认为的关联度最大的变量是x1(gdp),通过以上定性分析可知,gdp代表该地区对电力的需求,并不能直接反应电网基建投资额度。而x3(统调最大负荷)为所有电厂投入使用后所能承担的用电负荷,反映了一个地区的供电能力大小,供电能力直接体现的就是电网基建投资的大小。通过定性分析发现x3与目标变量的相似性最高。3.若改变邓氏关联度方法初值化、均值化等操作,它的结果会发生改变,造成了不确定性,而本发明提出的方法的结果不会受到影响。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1