一种基于聚类分析的文档数据分类方法与流程
本发明涉及一种基于聚类分析的文档数据分类方法,含有多主题的弱监督文档数据处理技术领域。
背景技术:
如今互联网技术正处于高速蓬勃发展之中,随之而来的是信息量的爆发。web文档的数量正呈现出指数级增长的趋势,文档数据的管理和分类已然成为一个重要的研究课题。文档分类技术是一种高效地对未分类文档进行归类的技术,该方法根据用户提交给分类装置的样例文档,对文档库中未被分类的文档进行快速、准确地分类。一种行之有效的策略是将分类过程看成学习的过程,使用机器学习的技术对用户提交的样例文档进行学习,最终得到一个分类模型。最后使用这个经过训练得到的模型对文档进行分类。
一篇文档通常具备大量的词汇,并对应多种主题。现有的文档分类技术往往受限于大量文本词汇所带来的维度灾难,并使用相同的特征在所有主题上进行训练学习。而不同主题通常更关注于不同的特征,使用相同的特征对其进行预测往往无法取得较好的结果。
技术实现要素:
发明目的:针对目前文档分类问题中,现有技术使用相同的特征在不同的主题上进行预测而产生的性能不足问题。本发明提出一种基于聚类分析的文档数据分类方法,旨在利用聚类分析,挖掘特征空间中针对文档的不同主题的不同隐藏性质,并为每一种主题特化出其独特的特征,再结合主题之间的联系性,对该特征进行更新,从而为每一种主题生成维度更低、更具判别性的特征,通过在该特征上训练分类器来提高文档分类装置的性能。
技术方案:一种基于聚类分析的文档数据分类方法,为了能够针对文档的不同主题,提取该主题最关注的特征信息以更好地区分和判别文档的主题,本发明通过聚类分析技术以获取这一特征,并对文档进行更好更有效的分类。该方法包括以下步骤:(1)用户从已有的文档库中选择样例文档,其中每个文档都具备多个主题;(2)将选取的文档的初始特征针对每一种主题转化为新的特征;(3)对每一类主题,在新的特征上学习得到分类模型;(4)基于最终分类模型对文档存储设备中待分类文档进行分类,并返回分类结果;(5)如果用户对分类结果满意,则执行步骤6,否则从文档库中选择更多的查询图像进行反馈,执行步骤2;(6)结束。
有益效果:不同于现有的文档分类方法使用同一特征空间在所有的主题上进行预测的方式,本发明基于聚类分析技术对每种主题分别考虑其特征构成。通过聚类分析能够有效挖掘数据内在性质的特性,为每一种主题生成维度更低、并更具判别性的特征,再考虑主题间的联系性将这些特征进一步更新,从而使学习系统更具稳定性和鲁棒性。
附图说明
图1是文档分类装置的工作流程图;
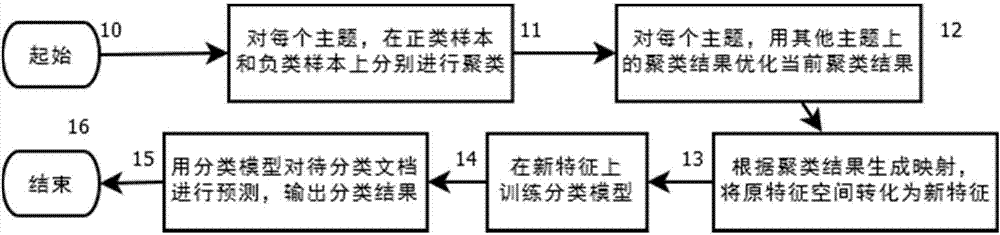
图2是本发明方法的流程图;
图3是第一层聚类分析的流程图;
图4是第二层聚类分析的流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,文档存储设备中存放的是待分类的文档,另有一个包含大量具备多种主题的文档的文档库,文档库中的每篇文档均与一个或多个主题相关联。用户从文档库中选取n篇已分类文档提交给文档分类装置。文档的初始特征由一种常用的方法生成,即使用所有可能出现在文档中的词作为特征项。在实际应用中,由于将所有的词作为特征项使得特征向量的维度过大而为训练过程带来极大的计算量,故使用了一些常用的特征降维技术进行降维处理,如词频(termfrequency,记为tf)、词频-逆文档词频(termfrequency-inversedocumentfrequency,记为tf-idf)等。该文档分类装置通过本发明提出的方法将选取的文档的初始特征针对每一种主题转化为新的特征。对每一类主题,在新的特征上学习得到分类模型。基于最终分类模型对文档存储设备中待分类文档进行分类,并返回分类结果,如图1所示。如果用户对所得结果不满意,可以从文档库中选取更多的样例文档反馈给文档分类装置。
本发明涉及的方法如图2所示。步骤10是起始动作。假设用户选取的查询文档对应于集合d={(xi,yi)|1≤i≤n},其中yi为文档样本xi所对应的主题集合,
步骤14为每个主题在得到的新特征上训练分类模型,并在步骤15中,利用得到的分类模型为待分类文档进行分类预测,最终输出分类结果。在输出分类结果后,即进入步骤16所示的结束状态。
图3给出了图2中步骤11的详细描述,是对每个主题上的第一层聚类分析。图3中的步骤1100是起始状态。步骤1101至1107构成了一个循环体,循环的每一轮中针对第t个主题进行聚类分析。其中,步骤1103首先对于主题t,将样本划分为正类样本集合s+与负类样本集合s-,如果样本与主题t相关联,则样本属于正类样本集合,否则属于负类样本集合。然后步骤1104为两个样本集合计算其聚类数nt,即
步骤1105和步骤1106分别对正类样本集合s+与负类样本集合s-进行聚类分析,各聚nt个类。当所有主题上的聚类完成后,随即进入步骤1108的结束状态。
图4给出了图2中步骤12的详细描述,是对每个主题已有的第一层聚类分析结果上进行的第二层聚类分析。图4中的步骤1200是起始状态。步骤1201至1204构成了一个循环体,循环的每一轮中针对第t个主题对步骤11中得到的聚类结果进行处理。步骤1203中根据聚类结果计算得到两两样本之间的相似度,以相似度矩阵wt来表示。如果样本xi与xj属于同一个聚类簇,那么wtij=1,否则wtij=0。步骤1205至1209构成了一个循环体,循环的每一轮中对第t个主题上的聚类结果进行更新。步骤1207中对两两样本之间的相似度进行更新,得到新的相似度矩阵wt′,样本xi与xj之间的相似度由所有主题上的相似度矩阵加权和得到,如下所示
其中,λt是归一化系数,δtk是主题t与主题k之间的相似度。步骤1208对更新后的相似度矩阵wt′进行图像分割,从而得到更新后的聚类结果。当所有主题上的聚类分析结果得到更新之后,随即进入步骤1210的结束状态。
本发明给出了一种基于聚类分析的文档分类的方法,该方法通过两层聚类分析,为每类主题生成其独特的维度更低、并更具判别性的特征,基于这种特征进行学习和训练,可以提高模型训练效率,提高学习系统的有效性、稳定性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!