一种异常检测方法及系统与流程
本发明涉及异常检测技术领域,特别是涉及一种异常检测方法及系统。
背景技术:
近年来,随着越来越多人群踩踏、恐怖袭击以及其他公共安全事件的发生,作为群体行为监控、分析、预警基础的人群异常事件的检测已经成为智能监控领域中急需解决的问题之一。然而,由于对人群中异常事件的界定并没有一个统一的标准,且几乎不可能列出人群中所有可能会出现的异常事件,因此人群异常事件的检测并不是一个典型的分类问题。而且,人群运动具有典型的复杂性和不可预测性:(1)人群场景类型繁多,如楼梯间、广场、商场、地铁站等。这些场景中不仅人群密度从稀少到稠密,而且运动速度也存在很大的差异。因此寻找一个泛化能力强的统一视频特征描述符是人群异常检测的一大难点。(2)人群的运动方式也经常发生各种变化且相互遮挡严重。显然通过跟踪每个个体来分析群体行为是很困难的,而简单地整体分析又会使得检测的精确度不高。(3)群体中的个体不仅受其他个体等各种外在环境的影响,还受其预期目的地和心理活动等各种内在因素的影响,这进一步增大了群体分析的难度。(4)群体行为不仅复杂多变且随着时间的增长会出现很多全新的行为,所以寻找一个能实时更新的异常检测模型也是主要目标之一。
技术实现要素:
本发明实施例提供一种异常检测方法,以解决现有技术对人群中异常事件的检测效果不佳的问题。
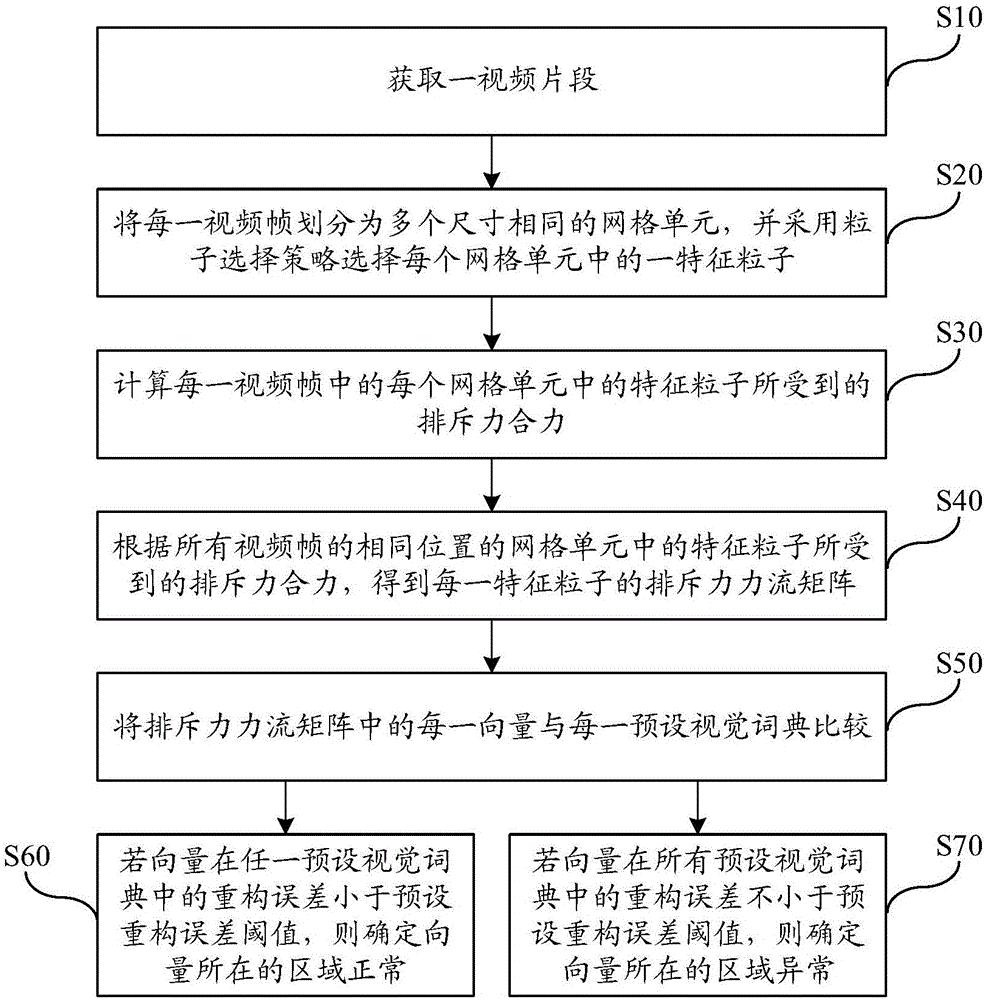
第一方面,提供一种异常检测方法,包括:获取一视频片段,其中,所述视频片段包含多个视频帧;将每一视频帧划分为多个尺寸相同的网格单元,并采用粒子选择策略选择每个所述网格单元中的一特征粒子;计算所述每一视频帧中的每个所述网格单元中的特征粒子所受到的排斥力合力;根据所有所述视频帧的相同位置的所述网格单元中的特征粒子所受到的排斥力合力,得到每一所述特征粒子的排斥力力流矩阵,其中,所述排斥力力流矩阵中的向量为所述每一视频帧中的每个所述网格单元中的特征粒子所受到的排斥力合力;将所述排斥力力流矩阵中的每一向量与每一预设视觉词典比较,其中,所述预设视觉词典包括多个视觉单词,所述视觉单词表示正常情况下的粒子的排斥力合力;若所述向量在任一所述预设视觉词典中的重构误差小于预设重构误差阈值,则确定所述向量所在的区域正常;若所述向量在所有所述预设视觉词典中的重构误差不小于预设重构误差阈值,则确定所述向量所在的区域异常。
第二方面,提供一种异常检测系统,包括:第一获取模块,用于获取一视频片段,其中,所述视频片段包含多个视频帧;选择模块,用于将每一视频帧划分为多个尺寸相同的网格单元,并采用粒子选择策略选择每个所述网格单元中的一特征粒子;计算模块,用于计算所述每一视频帧中的每个所述网格单元中的特征粒子所受到的排斥力合力;第二获取模块,用于根据所有所述视频帧的相同位置的所述网格单元中的特征粒子所受到的排斥力合力,得到每一所述特征粒子的排斥力力流矩阵,其中,所述排斥力力流矩阵中的向量为所述每一视频帧中的每个所述网格单元中的特征粒子所受到的排斥力合力;比较模块,用于将所述排斥力力流矩阵中的每一向量与每一预设视觉词典比较,其中,所述预设视觉词典包括多个视觉单词,所述视觉单词表示正常情况下的粒子的排斥力合力向量;第一确定模块,用于若所述向量在任一所述预设视觉词典中的重构误差小于预设重构误差阈值,则确定所述向量所在的区域正常;第二确定模块,用于若所述向量在所有所述预设视觉词典中的重构误差不小于预设重构误差阈值,则确定所述向量所在的区域异常。
这样,本发明实施例中,通过将特征粒子的排斥力合力与由正常情况下粒子的排斥力合力组成的预设视觉词典进行比较,若向量在任一预设视觉词典中的重构误差小于预设重构误差阈值,则确定向量所在的区域正常;若向量在所有预设视觉词典中的重构误差不小于预设重构误差阈值,则确定向量所在的区域异常,从而可准确检测人群中的异常事件。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例的异常检测方法的流程图;
图2是本发明实施例的异常检测方法的采用粒子选择策略选择每个网格单元中的一特征粒子的步骤的流程图;
图3是本发明实施例的异常检测方法的深度光流跟踪的示意图;
图4是本发明实施例的异常检测方法的计算每一视频帧中的每个网格单元中的特征粒子所受到的排斥力合力的步骤的流程图;
图5是本发明实施例的异常检测方法的将排斥力力流矩阵中的每一向量与每一预设视觉词典比较的步骤的流程图;
图6是本发明实施例的异常检测方法的更新预设视觉词典的步骤的流程图;
图7是本发明实施例的异常检测系统的结构框图;
图8是本发明实施例的异常检测方法的检测结果的示意图;
图9是umn数据集中异常检测性能的对比分析的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开一种异常检测方法。如图1所示,该方法包括如下的步骤:
步骤s10:获取一视频片段。
其中,该视频片段是按照预设时间间隔将视频分割得到的。视频片段包含多个视频帧。例如,按照一个视频片段中包含30帧视频分割。
步骤s20:将每一视频帧划分为多个尺寸相同的网格单元,并采用粒子选择策略选择每个网格单元中的一特征粒子。
例如,将一帧视频划分为20×20像素的网格,应当理解的是,网格相互之间无重叠。由于每一网格都是有无数个粒子(像素)构成,要对每一个粒子进行分析处理,会导致处理非常缓慢,不能及时反映当前情况,因此,选择每个网格单元中的一特征粒子来代表该网格中的所有粒子的状态。
步骤s30:计算每一视频帧中的每个网格单元中的特征粒子所受到的排斥力合力。
每一特征粒子受到周围的多个粒子的影响,从而调整自己的运动状态等。因此,通过本步骤计算特征粒子所受到的排斥力合力。该排斥力合力可模拟实际的人群个体间相互作用的结果。
步骤s40:根据所有视频帧的相同位置的网格单元中的特征粒子所受到的排斥力合力,得到每一特征粒子的排斥力力流矩阵。
其中,排斥力力流矩阵包括向量。根据步骤s40可知排斥力力流矩阵中的向量为每一视频帧中的每个网格单元中的特征粒子所受到的排斥力合力。虽然这些特征粒子的排斥力合力可以在一定程度上反映出各种不同场景下人群的运动情况,但是只根据这些离散的力值很难区分出场景中人群的正常和异常行为。因此,采用一种称之为力流的方法来构建排斥力力流矩阵,以便模拟场景中人群间虚拟排斥力随时间的变化,即模拟视频中人群的运动情况。
例如,步骤s10中得到的每个视频片段包含m个视频帧,步骤s20中将每一视频帧分割成具有n=b×b块的网格单元。因此力流矩阵f∈rm×n中的每一个元素就是图像块中选定的特征粒子的速度,每一列x={x1,...,xn}∈rm×n是连续m帧的相同位置网格中所有特定粒子受力的变化情况,即可以看作是初级视觉单词。力流矩阵即提取的人群运动底层特征。
步骤s50:将排斥力力流矩阵中的每一向量与每一预设视觉词典比较。
其中,预设视觉词典包括多个视觉单词。视觉单词表示正常情况下的粒子的排斥力合力。正常情况下的粒子的排斥力合力可模拟视频中正常情况下人群运动特征的向量。将所有的视觉单词集合到一起也就形成了包含各种人群运动特征的预设视觉词典。该预设视觉词典可预先通过正常情况下的视频训练得到。
步骤s60:若向量在任一预设视觉词典中的重构误差小于预设重构误差阈值,则确定向量所在的区域正常。
预设重构误差阈值是根据经验值设定的。在人群异常事件检测中,根据稀疏编码理论,正常事件通常具有稀疏的重构系数及较小的重构误差。相反的,由于异常事件与由正常视频训练得到的预设词典中的视觉单词都极不相似,所以异常事件具有稠密的重构系数和较大的重构误差。基于上述的原理,采用向量的重构误差与预设重构误差阈值进行比较来检测异常事件。
上述的稀疏编码通常被用来寻找一组“超完备”基向量,以便更高效地表示输入数据,也就是用这些基向量的线性组合
在检测时,依次根据每一个预设词典计算向量相应的重构误差。一旦这个向量在这个预设词典中的重构误差小于预设重构误差阈值,即该向量能被某个预设词典稀疏表示,那么就认为这个向量表示正常情况,该向量对应的特征粒子所在的区域没有异常出现。
步骤s70:若向量在所有预设视觉词典中的重构误差不小于预设重构误差阈值,则确定向量所在的区域异常。
若向量在所有预设视觉词典中的重构误差不小于预设重构误差阈值,即所有预设词典都不能稀疏表示该向量,那么就认为该向量表示异常情况,也就说明该向量对应的特征粒子所在的区域出现异常
具体的,如图2所示,步骤s20包括如下具体的过程:
步骤s201:采用深度光流跟踪每一视频帧中的所有像素的运动轨迹,获取所有像素的速度。
深度光流(deepflow)是一种稠密光流算法。它混合了一种结合变分法的匹配算法以计算光流。这种方法不仅可以有效地处理群体中的大尺度运动而且还能提供更加稳定的轨迹跟踪。通过本步骤,获得所有像素的速度。
步骤s202:将初始视频帧的每个网格单元中的中心点像素,作为初始视频帧的每个网格单元中的特征粒子。
对于初始视频帧,由于像素的速度可能均为0,因此,将每个网格单元中的中心点像素作为该网格单元中的特征粒子。如图3所示,为本发明实施例的异常检测方法的深度光流跟踪的示意图。其中,(a1)和(b1)表示一个视频帧的图像。(a2)和(b2)表示深度光流跟踪后的稠密光流图。(a3)和(b3)表示选定粒子的平流图。
步骤s203:对于除初始视频帧以外的视频帧的每个网格单元,遍历网格单元中的每一像素的速度。
通过本步骤,获取每个网格单元中的每一像素的速度。
步骤s204:将每一网格单元中的每一像素的速度按照从大到小的顺序排序。
例如,对于视频帧fj中的网格单元
步骤s205:获取网格单元中的速度最大的所有像素点,并通过k-means算法计算得到网格单元中的速度最大的所有像素点的中心点像素,作为网格单元中的特征粒子。
具体的,选择网格单元
具体的,步骤s20中的当前时刻第二对象的恐慌情绪值可采用上述的步骤s10的过程获得。
具体的,如图4所示,步骤s30包括:
步骤s301:获取每一视频帧中与特征粒子相邻的其他粒子。
在群体中,每一个行人的运动很容易受到其相邻行人的影响,因此,通过该步骤获取其他粒子,相当于模拟获取相邻行人的状态。
步骤s302:按照第一规则获取每一视频帧中特征粒子与其他粒子之间的排斥力。
具体的,第一规则为:
其中,j表示与特征粒子i相邻的其他粒子。fij表示特征粒子i与其他粒子j之间的排斥力。
τ是特征粒子i与其他粒子j的即将碰撞时间,即按现有状态,从当前时刻开始计时,两个粒子之间发生碰撞所需要的时间。τ0是预设碰撞时间下限,一般为在个体间无屏蔽状态下可以观察到相互作用的即将碰撞时间的最大值。一般τ0=3s。k为常数,可根据具体情况(例如参考现有文献)确定。该排斥力可模拟根据相互作用能量的定义,当行人间发生相互作用时,行人i和j之间的排斥力。
根据实践经验,在处理该类场景时,以上公式中的参数设置为k=1.5。
步骤s303:根据视频帧中特征粒子与其他粒子之间的排斥力,按照第二规则,获取视频帧中的特征粒子的排斥力合力。
具体的,第二规则为:
其中,fi表示特征粒子i的排斥力合力。ω表示与特征粒子i相邻的其他粒子j的集合。
通过上述的步骤,可得到视频帧中的特征粒子的排斥力合力。
具体的,如图5所示,步骤s50包括:
步骤s501:按照第三规则计算得到向量在一预设视觉词典中的重构系数。
具体的,第三规则为:
其中,βi表示向量x在预设视觉词典di中的重构系数。
步骤s502:根据重构系数,按照第四规则计算得到向量的重构误差。
具体的,第四规则为r(x,βi,di)=∑γ{||x-diβi||}。
其中,r(x,βi,di)表示向量的重构误差。如前所述,x表示向量,di表示预设视觉词典,γ取值为0或者1,当γ为0时,表示对于视觉单词x,第i个预设词典di没被选择,当γ为1时,表示对于视觉单词x,第i个预设词典di被选择。
步骤s503:将向量的重构误差与每一预设视觉词典的预设重构误差阈值比较。
通过步骤s50的比较,可以得到如下的结果:
(1)若r(x,βi,di)<λ,则向量所在的区域正常(即步骤s60)。i=1,2,...,s。s表示预设词典的数量。预设词典集合d={d1,d2,...,ds}。λ表示预设重构误差阈值,其决定了该第四规则的敏感度。根据实践经验,预设重构误差阈值λ=0.08。
(2)若r(x,βi,di)≥λ,则向量所在的区域异常(即步骤s70)。
因此,通过上述的比较,可最终确定向量所在的区域是否异常,从而可精确检测出人群异常事件。
此外,由于预设词典是通过预先训练得到的。该训练方法与上述的检测方法相同。具体的,可使用测试视频的前n帧正常视频片段训练。例如,采用前500帧进行预设词典的训练。该训练方法如下:
在得到某一特定场景的力流矩阵之后,训练得到每组预设视觉词典d={d1,d2...,ds}。s表示预设视觉词典的数量。其中,di∈rm×d,d<<n。m表示视频帧的数量,d表示每一视频帧的网格单元的数量。n表示每一视频帧的网格单元的数量的上限。为防止过拟合,每一个预设视觉词典di应该是一个凸的封闭有界的集合。
采用如下的规则训练预设视觉词典:
其中,di是第i个预设词典。
例如,根据实践经验,在处理该类场景时,t0=3s,λ=0.08。在训练过程中,由于排斥力合力f是基于人群正常平稳运动视频计算得到的,因此f值比较小且波动稳定。如果检测视频帧对应的f明显增大,则表明人群出现了异常。在得到每一帧所有网格单元的特征粒子的排斥力合力之后,使用连续帧间相同网格单元中特征粒子的力的变化情况(即力流)表示视频中人们的运动情况。为了构造视觉单词,将力流按照t=30帧的长度将力流分割成一段一段的力流矩阵(即将视频分割成视频片段),该矩阵的每一行都是一个初级的视觉单词。在训练阶段共约有3100个视觉单词,然后通过稀疏重构训练得到包含42个词典的预设视觉词典。
此外,虽然该预设视觉词典预先经过了训练,可很好地反映正常情况的粒子的排斥力合力。但是,在实际检测过程中,会产生预设词典的表示能力退化或概念漂移的问题。因此,在检测的过程中,还需对该预设词典进行更新。如图6所示,本发明实施例的方法还包括如下的步骤:
步骤s01:建立每一预设视觉词典对应的单词池。
应当理解的是,建立的单词池没有视觉单词,随着检测过程的进行,该单词池中存储视觉单词。
步骤s02:若向量在一预设视觉词典中的重构误差小于预设重构误差阈值,则将向量存储到预设视觉词典对应的单词池中。
若向量在一预设视觉词典中的重构误差小于预设重构误差阈值,则表明向量所在的区域正常,由于,预设视觉词典中的视觉单词都是表示正常情况,因此,将这个向量存储到预设视觉词典对应的单词池中,以便后续的步骤,可将该向量更新预设视觉词典中的视觉单词。
步骤s03:若单词池的中的向量超过单词池的预设单词量,则建立与单词池对应的预设视觉词典完全相同的备用词典。
具体的,可先建立一个空的备用词典,然后将预设词典中的视觉单词都复制到对应的备用词典中。
步骤s04:按照第五规则更新备用词典。
具体的,第五规则为
其中,d'i表示更新后的预设视觉词典。
步骤s05:将更新后的备用词典中的所有视觉单词存储到对应的预设视觉词典中,得到更新后的预设视觉词典。
步骤s06:若向量在至少两个预设视觉词典中的重构误差小于预设重构误差阈值,则将所有单词池中的向量更新所有预设视觉词典。
通过该步骤,预设视觉词典可以随着检测的过程实时更新,而不至于跟不上场景的变化可以保证预设词典的表示能力。
该更新的过程与检测过程同时进行,并且通过步骤s05和s06得到的更新后的预设视觉词典实时用于检测过程,使检测速度可以进一步得到提高,避免采用单一模式的预设词典带来的计算量巨大和难以维护的问题。
本发明还公开了一种异常检测系统。如图7所示,该系统包括:
第一获取模块701,用于获取一视频片段。
其中,视频片段包含多个视频帧。
选择模块702,用于将每一视频帧划分为多个尺寸相同的网格单元,并采用粒子选择策略选择每个网格单元中的一特征粒子。
计算模块703,用于计算每一视频帧中的每个网格单元中的特征粒子所受到的排斥力合力。
第二获取模块704,用于根据所有视频帧的相同位置的网格单元中的特征粒子所受到的排斥力合力,得到每一特征粒子的排斥力力流矩阵。
其中,排斥力力流矩阵中的向量为每一视频帧中的每个网格单元中的特征粒子所受到的排斥力合力。
比较模块705,用于将排斥力力流矩阵中的每一向量与每一预设视觉词典比较。
其中,预设视觉词典包括多个视觉单词,视觉单词表示正常情况下的粒子的排斥力合力向量。
第一确定模块706,用于若向量在任一预设视觉词典中的重构误差小于预设重构误差阈值,则确定向量所在的区域正常。
第二确定模块707,用于若向量在所有预设视觉词典中的重构误差不小于预设重构误差阈值,则确定向量所在的区域异常。
下面以具体的应用例对本发明实施例的方法做进一步说明。
该应用例基于umn数据集的实验分析。如图8所示,umn数据集包含三个不同的场景,共11段视频序列,视频帧的总数为7740帧,分辨率为320×240像素。每一段视频序列在开始时群体运动行为表现正常,一段时间后人群开始恐慌逃散。从图8中,可以看出,采用本发明实施例的方法检测出的表示发生异常的较深颜色的矩形框与实际情况的表示发生异常的较深颜色的矩形框的位置基本一致,说明本发明实施例的方法的检测结果与实际情况基本吻合。如图9所示,为umn数据集中异常检测性能的对比分析的示意图。其中,rfm+gd表示本发明的方法,即排斥力模型+分组词典,src表示稀疏重构代价方法,sfm表示社会力模型方法,opticalflow表示深度流方法。通过该示意图,可以看出本发明实施例的方法可以保证更低的误报率。
综上,本发明实施例,基于排斥力模型提取视频中人群运动特征,能够及时准确的反应出群体间相互排斥力的变化,因此能精确地实时反映出人群运动的时空特征;此外,随着新视频的不断增加和视频场景的动态变化,通过预设词典局部和全局更新,可以有效地解决随着新视频的不断增加和视频场景的动态变化而导致的预设词典表示能力退化或概念漂移问题。
- 还没有人留言评论。精彩留言会获得点赞!