一种基于大数据的经济活动人口识别方法与流程
本发明涉及一种基于海量匿名加密时间序列定位数据的经济活动人口的识别的方法,根据个体的时间和空间位置数据构建海量的个体出行轨迹;通过空间聚类将个体的出行轨迹划分为若干区域,对其长时间的驻留点进行判断和提取;通过样本训练学习获得各种经济活动人口的日常出行模式特征及其相关的参数取值;对全样本个体出行轨迹进行识别,判断其是否属于经济活动人口,以及属于哪一类经济活动人口;对样本数据进行扩样,获得全社会的经济活动人口数量和分布。
背景技术:
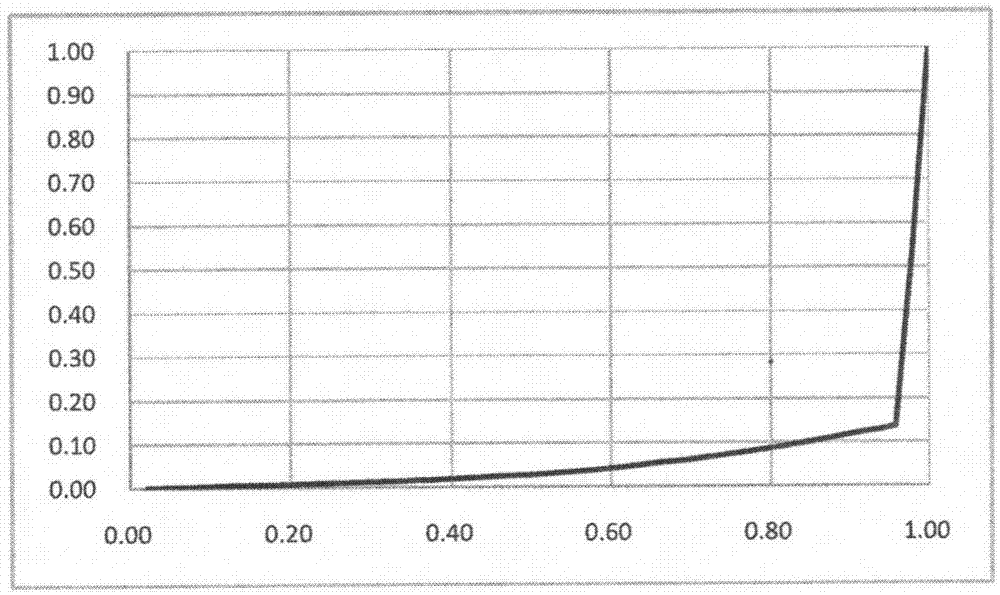
:经济活动人口指的是所有年龄在16岁及以上,在一定时期内为各种经济生产和服务活动提供劳动力供给的人口。这些人被视为实际参加或要求参加社会经济活动的人口,也称为现实的人力资源,是就业人口和失业人口之和。经济活动人口的调查和统计对于社会经济稳定和发展状况的分析和预测具有重要的现实意义。传统对于经济活动人口的统计往往依赖大样本和长时间的抽样调查,这种调查方法在时间和人力物力方面的消耗都非常大,而且其抽样比例并不高,统计的时效性也会存在滞后的问题,严重降低了经济活动人口调查的实用性。近年来,随着信息技术的发展,数据信息量呈现爆炸式增长,数据来源越来越多,数据量也越来越庞大。其中,由手机、wifi、物联网等信息传感器记录的数据已经成为大数据分析中最重要的数据来源,其较为完备的个体出行记录为大数据分析,尤其是交通大数据分析,提供了很好的数据支持。以手机为例,至2017年9月,手机用户达到14.1亿,超过现阶段人口总量13.827亿,手机终端设备持续产生的信号信息,形成了记录用户出行的一系列数据集,为分析城市人群出行、滞留等行为活动提供了重要的数据来源。技术实现要素:本发明的目的是:利用大数据及其分析技术训练和识别经济活动人口的日常出行行为特征,以此为基础判断识别总样本中的经济活动人口,分析其时序变化特征,实时监测经济活动人口的变化。为了达到上述目的,本发明的技术方案是利用移动终端个体在指定时间范围和空间范围内的活动数据集(即移动终端个体与固定位置传感器的通信记录),构成个体出行轨迹,对出行轨迹进行插值扩充节点,建立个体出行轨迹;通过空间聚类方法将个体的出行空间划分为若干区域,提取其长时间驻留地点;选取样本个体的出行轨迹,对其进行训练,学习获得各种经济活动人口的出行活动的空间分布特征及其相关参数;对全样本的数据进行分析,识别判断出样本中的经济活动人口;最后采样固定比例进行扩样,得到实时的经济活动人口总数。具体而言,本发明提供的一种基于大数据的经济活动人口识别方法包括以下步骤:步骤1、从传感器运营商获取匿名加密移动终端传感器数据,匿名加密移动终端传感器数据在时间与空间上连续,不同移动终端对应不同的epid;步骤2、依次提取每个epid在指定时间段内与传感器的通信信令记录,按时间顺序排序,建立与当前epid相对应的个体出行轨迹数据集;从时间起点t0出发,以t时间为间隔对个体出行轨迹数据集的空间位置进行插值,构建由真实点和插值点构成的个体出行时空序列;步骤3、基于dbscan算法,设计基于距离的空间聚类算法,对样本的个体出行时空序列数据上的插值点进行空间聚类,提取出节点的节点聚类簇,从中提取出节点聚类簇中的核心点作为当前个体的驻留点,以个体在节点聚类簇内驻留的时间作为节点聚类簇的大小;步骤4、对经济活动和非经济活动类型进行划分,选取其中的典型样本的出行时空序列数据,统计其在指定时间段内的聚类数量、聚类大小、聚类中心点所在位置,挖掘不同活动类型的个体的空间出行活动特征,获得不同活动类型的典型特征参数及其上下界误差范围,作为个体活动类型的判别依据;步骤5、遍历个体出行时空序列,依据步骤4获得的判别依据,对每个个体的经济活动类型进行判断和识别;步骤6、对得到的经济活动个体进行扩样,得到经济活动人口的总体统计数据,完成对于经济活动人口的动态监测,并更新数据库。优选地,在所述步骤1中,匿名加密移动终端传感器数据包括:用户个体唯一编号epid、通信动作类型type、通信动作发生时刻time、传感器所处大区regioncode、传感器具体编号sensorid,其中,传感器所处大区regioncode及传感器具体编号sensorid构成了传感器编号。优选地,所述步骤2包括:步骤2.1、提取个体出行轨迹数据集中,所有的固定位置传感器编号regioncode-sensorid及其对应的经纬度坐标lon-lat,将经纬度坐标lon-lat转换为地理坐标x-y;步骤2.2、遍历个体出行轨迹数据集,将其按触发通信时间timestamp顺序排列;步骤2.3、从时间起点开始遍历出行数据,相邻的每3个通信记录点拟合一条二次曲线,二次曲线的x轴为个体出行轨迹的时间,y轴为通信记录点的x-y坐标,若个体的出行轨迹包含n个通信记录点,则总共需要拟合出2n-4条二次曲线;步骤2.4、从时间起点t0出发出发,按时间间隔t计算个体在每个时间点的x-y坐标,相同时间x(t0+nt)和y((t0+nt)构成一个插值点,除首尾两段外,其余通信点之间都存在2条拟合曲线,在此之间的插值点的x-y坐标由两条曲线的计算结果求平均得到;步骤2.5、将所有插值点和记录点按时间顺序排序,构成初步的个体的出行时空序列数据;步骤2.6、对步骤2.5得到的出行时空序列数据进行分割,以记录点为端点,平均分割所有两两记录点之间的插值点,将插值点归属到离其最近的记录点,将记录点中的传感器编号赋给插值点,表明插值点也是潜在的会于该传感器通信的点;步骤2.7、从步骤2.5得到的出行时空序列数据中删除所有的记录点,从而使得到的个体出行时空序列完全由赋有传感器编号的插值点组成。优选地,所述步骤3包括:步骤3.1、从数据库中读取已由步骤2得到的个体出行时空序列,从时间起点开始遍历,以每个节点为中心,查找其前后邻域中的n1个临近节点,前后各个;步骤3.2、假设当前遍历到节点n,则其前后临近点的边界为节点和统计从节点到节点的分段距离和式中,di表示节点到节点区间内,从节点i到节点i+1之间的距离,即区间内相邻节点之间的距离,该距离以欧式距离计算;步骤3.3、根据得到的节点n邻域内的分段距离和,计算以节点n为中心的邻域的节点密度ρ,步骤3.4、判断以节点n为中心的邻域的节点密度ρ是否大于临界阈值thr-ρ,若大于临界阈值thr-ρ,则当前邻域内为密度可达,将该邻域标注为一个节点n的节点聚类簇,令其密度相连,将其内部所有的节点都标注为聚类节点,记录下其外部前后的一个节点的空间坐标;若小于临界阈值thr-ρ,则舍弃当前邻域,继续遍历下一个节点;步骤3.5、采用步骤3.2至步骤3.4遍历完整个个体出行时空序列后,从头开始遍历每个判定的节点聚类簇,判断:1)相邻的节点聚类簇所包含的节点之间是否有交集,若存在交集,则该两个节点聚类簇之间密度可达,将这两个节点聚类簇合并为一个,令其密度相连,重新计算合并后的节点聚类簇的节点密度,并统计节点聚类簇内的节点数量;2)每个节点聚类簇内的插值点数量是否小于阈值thr-n,若小于阈值thr-n,则表明个体在该节点聚类簇内的停留时间太短,达不到驻留标准,舍弃该节点聚类簇;步骤3.6、遍历每个留存下来的节点聚类簇,计算每个节点聚类簇的加权中心点c,其中权重w为节点聚类簇内节点距离其加权中心点c的序号差,若节点聚类簇内节点数为m,则第1个和第m个节点的权重w最小,第个节点的权重w最大,设聚类中心点c的x轴坐标为xc,聚类中心点c的y轴坐标为yc,则有:式中,n1表示节点聚类内的节点数量,xi表示节点聚类内节点i的x坐标,yi表示节点聚类内节点i的y坐标。优选地,所述步骤4包括:步骤4.1、将经济活动与非经济活动人口分类,其中,经济活动人口划分为职住分离白天全职型、职住分离夜间全职型、职住分离轮岗全职型、职住分离白天兼职型、职住分离夜间兼职型、职住分离混合型、厂区居住型、公司居住型、教师、在校高中大学学生、自由职业者、失业者;非经济活动人口分为:在校初中小学生、退休人员、居家无劳动能力者;步骤4.2、选取若干已明确活动特征的个体出行时空序列作为样本;步骤4.3、计算样本的个体出行时空序列的洛伦兹曲线和基尼系数;步骤4.4、计算出指定时间段内各个样本的空间聚类特征,包括聚类数量、聚类大小、聚类中心点所在位置;步骤4.5、以聚类覆盖的时间为大小,统计每天各种大小的聚类的平均数量,以聚类大小为x坐标,聚类数量为y坐标,计算聚类大小分布;步骤4.6、提取聚类点中心所在地,依照区域功能将其划分为不同的驻留地类型,个体平均有每天在上述地点的累积聚类时间,将其按照固定顺序排列,以累积时间的长短作为累积量,计算个体日常生活中驻留地类型的分布特征;步骤4.7、根据得到的各个典型出行时间序列样本的出行活动特征,包括洛伦兹曲线、基尼系数、聚类大小分布和驻留地类型分布,计算各种经济活动类型的人群日常空间活动的平均出行特征及其上下界误差范围,作为对后续步骤中对大量样本的识别判断的统计基础。优选地,所述步骤4.3包括:步骤4.3.1、遍历样本个体出行时空序列,读取其中的节点及其通信传感器编号;步骤4.3.2、统计每条出行时空序列中与每个通信传感器发生通信行为的节点的数量,该节点包括记录点和插值点,对传感器以节点数量从小到大排序,画出个体出行时空序列的洛伦兹曲线;洛伦兹曲线的定义为:设全球各个国家/地区的(x1,x2,...,xn),(y1,y2,...,yn)分别为根据“人均所有量”从低到高排序得到的相应的国家/地区的人口和碳排放所有量占全球总数的比例。(xi,yi)表示国家i的人口比例和所有量比例。则以点绘制散点图得到洛伦兹曲线。洛伦兹曲线的两端分别为(0,0)点和(1,1)点。在本发明中,由于传感器本身是均质的,所以不需要考虑平均的概念,因此在本发明中,设各个传感器的(x1,x2,..,xn),(y1,y2,...,yn)分别为根据“通信节点数量”从低到高排序得到的相应的传感器和通信节点数量占全球总数的比例。因此(x1,x2,...,xn)的数值都为1/n,(y1,y2,...,yn)为各个传感器的通信节点数占总节点数的比例,仍然以绘制洛伦兹曲线;步骤4.3.3、根据洛仑兹曲线得到的各个传感器根据“通信节点数量”从低到高排序得到的相应的传感器和通信节点数量占全球总数的比例,计算个体出行时空序列中传感器分布的基尼系数。基尼系数的表达方式有很多种,本发明采用最典型的计算方法:基尼系数的值等于洛伦兹曲线与45°直线所围成面积占45度直线与x轴,x=1所围成的面积的比。由于45°直线与x轴,x=1所围成的面积等于0.5,因此碳排放的基尼系数实际也等于洛伦兹曲线与45°的直线所围成面积的两倍,它在数值上位于区间[0,1)上;基尼系数越小,则说明结果越趋于公平;对于本发明,个体出行时空序列的基尼系数的数学表达为:式中,(y1,y2,...,yn,...yn)为各个传感器的通信节点数占总节点数的比例;优选地,在所述步骤4.7中,对于洛伦兹曲线、聚类分布和驻留地类型分布,取各样本与统计平均之间相关系数的上下界和关键节点的上下界作为误差范围;对于基尼系数,取各样本与统计平均之间的最大差值作为误差范围;洛仑兹曲线本身为离散函数,且x轴取值点各不相同,因此在做相关性分析的时候分别取两条洛仑兹曲线上的数值点f(x),x={0.1,0.2,0.3,……,0.8,0.9}进行相关性分析。优选地,所述步骤5包括:步骤5.1、遍历每条待识别的个体出行时间序列,进行节点的空间聚类,得到其日常空间活动范围的聚类结果;步骤5.2、计算出每条个体出行时间序列的洛伦兹曲线、基尼系数、聚类分布和驻留地分布;步骤5.3、对计算得到的洛伦兹曲线、基尼系数、聚类大小分布和驻留地分布,将其与步骤4得到判别依据对比(各种活动类型的平均值、平均曲线,分为相关系数计算和关键节点),寻找与其最为相似的活动类型,比较该出行时空序列与该活动类型的典型特征参数差值(比较该出行时空序列与该活动类型的各曲线和参数的相关系数和关键节点差值),若满足其上下界误差范围,则将其归类到与其最为相似的活动类型中;若个体出行时间序列与任何一种典型样本的典型特征参数差值都大于其上下界范围,则将其定义为异常样本,提取出来人工判别进行归类,并将其作为典型样本存入样本库;步骤5.5、遍历完所有个体出行时空序列后,统计提取所有的人工判别的异常记录,将其作为典型样本,重新对各个典型经济活动类型进行训练,校正曲线和判别参数。优选地,所述步骤6包括:步骤6.1、依据已有的统计资料,统计各种活动类型的人口,包括非经济活动人口,的手机持有率数据;步骤6.2、根据各活动类型的手持移动设备持有率,计算出各活动类型人口的总数;步骤6.3、针对特殊群体,则分别根据不同的经济活动非经济活动人口比和经济活动非经济活动人口手持移动设备持有率,统计出活动范围内的经济活动非经济活动人口数量,计算公式为:式中,pt为经济活动人口数量,ps为非经济活动人口数量,ht和hs分别为经济活动人口和非经济活动人口的持有手持移动设备的比率,r为经济活动对非经济活动人口的比例,r为指定时间段内指定活动范围内记录的个体的数量;步骤6.4、统计计算得到指定区域内的经济活动人口和非经济活动人口的人数和比例,更新人口监测数据库。本发明对于移动终端大数据进行处理和筛选,由个体所持移动终端和传感器之间的通信记录构建出个体出行的时空序列数据,通过数学插值补全时间间隔统一的用户出行时空序列数据,并将记录点的传感器编号以就近原则赋给插值点,并由插值点组成个体出行时空序列;通过对个体出行时空序列中的节点按照其时空分布进行空间聚类,得到时空序列中个体在不同时间范围内的空间驻留区域及其中心点;通过对大量典型的经济活动和非经济活动样本进行空间活动分布特征的特征分析(包括计算节点分布的洛仑兹曲线、基尼系数、节点聚类大小分布、个体驻留地分布),计算各种活动类型人口的平均活动特征及其相关系数和关键节点差值的上下界;在此基础上,采用同样方法分析待判别的个体出行时空序列的空间活动分布特征,并将其与典型经济/非经济活动的特征进行比对,对其经济活动类型进行判断和识别,从而统计指定时间段内相关的经济活动个体的数量及其在所有个体中的比例,并采用固定系数扩样的方法,最终获得全局的经济活动人口数量和比例。本发明的优点是:充分依托现有的用户持有的移动终端与传感器之间的通信大数据资源,利用通信网络中已有海量匿名移动终端持续的加密位置信息,即能低成本、自动化、便捷地获取指定时间范围内大量人口的出行时空序列,采用空间聚类算法快速地找出出行时空序列中个体的驻留地点、时间和时长,从中挑选典型样本出行时空序列的空间活动特征的挖掘和判别参数的训练,依据训练得到的参数和规则进行个体经济活动类型的识别和判断,从而便捷、高效地对指定时间和区域内经济活动人口的数量进行统计。附图说明图1为本发明的总体流程图;图2为职住分离白天全职型样本出行时空序列节点分布洛仑兹曲线(全局),节点分布的基尼系数为0.9792;图3为职住分离白天全职型洛仑兹平均曲线及其关键节点上下界;图4为个体出行时空序列洛仑兹曲线。具体实施方式为使本发明更明显易懂,兹以优选实施例,并配合附图作详细说明如下。本发明的目的是利用移动终端个体在指定时间范围内的空间活动数据集,挖掘大量个体的出行轨迹数据,对其进行拟合插值,获得等时间间隔的个体出行时空序列;采用空间聚类方法在个体出行时空序列中搜索可能的聚类区域,获得个体的驻留点;对个体的经济活动类型进行划分,利用已识别经济活动类型的样本训练出每种经济活动类型的特征;利用这些特征对待识别出行时空序列进行判别,为其划分经济活动类型。为了达到上述目的,本发明提供了一种大数据环境下个体经济活动类型识别的系统。本发明利用通信网络中已有海量匿名移动终端持续的加密位置信息,即能低成本、自动化、便捷地获取指定时间范围内大量人口的出行轨迹,利用样本出行时空序列数据训练个体经济活动类别的判别规则和阈值,并以此对海量个体的经济活动类型进行判断和识别;从而实现快速高效地统计地区的经济活动状况。为了达到上述目的,本发明提供了一种基于大数据的经济活动人口识别方法,如图1所示,包括以下步骤:步骤1、系统读取从传感器运营商获取匿名加密移动终端传感器数据,匿名加密移动终端传感器数据理论上在时间与空间上连续,不同移动终端对应不同的epid,提取每个epid在指定时间段内所触发的通信信令记录,构成该epid的出行数据集;匿名加密移动终端传感器数据是运营商从移动通信网络、固定宽带网络、无线wifi以及位置服务相关app等实时获取并脱敏加密后的匿名手机用户时间序列的加密位置信息,内容包括:epid、type、time、regioncode、sensorid,参见申请号为201610273693.0的中国专利。具体介绍如下:epid(匿名单向加密全球唯一移动终端标识码,encryptioninternationalmobilesubscriberidentity),是对每个移动终端用户进行单向不可逆加密,从而唯一标识每个移动终端用户,且不暴露用户号码隐私信息,要求每个移动终端用户加密后的epid保持唯一性,即任意时刻各手机用户的epid保持不变且不与其它手机用户重复。type,是当前记录所涉及的通信动作类型,如,上网、通话、主被叫、收发短信、gps定位、传感器小区切换、传感器切换、开关机等。time,是当前记录所涉及的通信动作发生时刻,单位为毫秒。regioncode、sensorid是当前记录所涉及的通信动作发生的传感器加密位置信息。regioncode、sensorid传感器的编号,其中regioncode代表传感器所处大区,sensorid是具体的传感器的编号。步骤1.1、系统读取从传感器运营商获取匿名加密移动终端传感器数据,理论上匿名加密移动终端传感器数据在时间与空间上都应该是连续的,包括:用户唯一编号epid、通信动作类型type、通信动作发生时刻time、传感器所处大区regioncode、传感器具体编号sensorid;其中,传感器所处大区regioncode及传感器具体编号sensorid构成了传感器编号;步骤1.2、一条匿名加密移动终端传感器数据为一个信令记录,对每条信令记录进行解密;步骤1.3、根据用户编号epid,查询其在指定时间段内所有的通讯记录,构建用户出行数据;在本例中,提取得到的用户与传感器的实时信令记录数据为:表1:解密后新接收的实时信令记录数据步骤2、依次提取每个epid在指定时间段内与传感器的通信记录,按时间顺序排序,建立个体出行轨迹数据集;从时间起点t0出发,以t时间为间隔对出行数据的空间位置进行插值,构建由真实点和插值点构成的个体出行时空序列;步骤2.1、提取步骤1.3得到的用户出行轨迹数据中,所有的固定位置传感器编号regioncode-sensorid及其对应的经纬度坐标lon-lat,将经纬度坐标转换为地理坐标x-y;在本例中,固定位置传感器的编号和地理坐标样例见表2:表2经纬度转换后的固定位置传感器x-y坐标步骤2.2、遍历用户出行轨迹数据,将其按触发通信时间timestamp顺序排列;步骤2.3、从时间起点开始遍历出行数据,相邻的每3个通信记录点拟合一条二次曲线,二次曲线的x轴为用户出行轨迹的时间,y轴为通信记录点的x-y坐标,这样若用户的出行轨迹包含n个通信记录点,则总共需要拟合出2n-4条二次曲线;步骤2.4、从整数时间起点t0出发,按时间间隔t计算用户在每个时间点的x-y坐标,相同时间x(t0+nt)和y((t0+nt)构成一个插值点,除首尾两段外,其余通信点之间都存在2条拟合曲线,在此之间的插值点的x-y坐标由两条曲线的计算结果求平均得到;在本例中,令时间起点t0为00:00,时间间隔t为10分钟,插值后得到的个体出行时空序列,见表3。表3插值数据与记录数据(部分)步骤2.5、将所有插值点和记录点按时间顺序排序,构成初步的个体的出行时空序列数据;步骤2.6、对个体出行时空序列进行分割,以记录点为端点,平均分割所有两两记录点之间的插值点,将插值点归属到离其最近的记录点,将记录点中的固定位置传感器编号赋给插值点,表明插值点也是潜在的会于该传感器通信的点。在本例中,附上固定位置传感器编号的插值点和记录点见表4。表4附上固定传感编号的插值数据与记录数据(部分)步骤2.7、从个体出行时空序列中删除所有的记录点,使个体出行时空序列完全由赋有传感器编号的插值点组成;在本例中,去掉通信节点后,仅由插值点构成的个体出行时空序列为见表5。表5个体出行时空序列(部分)recordidtimestampregioncodesensoridxy....................................ins482017-06-2008:00:00987834153821.9415598.461ins492017-06-2008:10:00987834153821.9415598.461ins502017-06-2008:20:00987834153821.9415598.461ins512017-06-2008:30:00987834153821.9415598.461ins522017-06-2008:40:00987834154298.1925730.753ins532017-06-2008:50:00987846324858.8855882.748ins542017-06-2009:00:00987863435534.4186040.373ins552017-06-2009:10:00988012426055.0296238.754ins562017-06-2009:20:00988012536615.1916467.808ins572017-06-2009:30:00988012537100.8216594.081ins582017-06-2009:40:00988014547414.4026574.482ins592017-06-2009:50:00988014547727.9836554.883ins602017-06-2010:00:00988014548065.8666434.546ins612017-06-2010:10:00988076458409.8256289.025ins622017-06-2010:20:00988076458478.6176259.921ins632017-06-2010:30:00988076458478.6176259.921ins642017-06-2010:40:00988076458478.6176259.921....................................步骤3、基于dbscan算法,设计一种基于距离的空间聚类算法,对样本出行时空序列数据上的插值点进行空间聚类,提取出节点的聚类簇(cluster),从中提取出聚类簇中的核心点(corept)作为个体的驻留点,以个体在聚类内驻留的时间作为聚类的大小;步骤3.1、从数据库中读取已由步骤2得到的个体出行时空序列数据,从时间起点开始遍历,以每个节点为中心,查找其前后邻域中的n1个临近节点(前后各个);在本例中,令n1为2;步骤3.2、假设当前遍历到节点n,则其前后临近点的边界为节点和统计从节点到节点的分段距离加和其中节点间的距离以欧式距离计算;在本例中,个体出行时空序列中ins53邻域内各节点之间的距离见表6。表6个体出行时空序列(部分)recordidrecordiddistance..................ins48ins490ins49ins500ins50ins510ins51ins52494.2835ins52ins53580.9295ins53ins54693.6789ins54ins55557.1273ins55ins56605.1836ins56ins57501.7782ins57ins58314.1929ins58ins59314.1929ins59ins60358.6724ins60ins61373.4758ins61ins6274.69526ins62ins630ins63ins640ins64ins650..................步骤3.3、根据得到的节点n邻域内的距离和,计算以节点n为中心的邻域的节点密度:在本例中,个体出行时空序列中各节点的邻域节点密度见表7。表7个体出行时空序列节点邻域密度(部分)recordiddensity............ins482ins492ins500.004038ins510.001858ins520.00113ins530.001091ins540.001077ins550.001201ins560.001406ins570.001768ins580.002024ins590.00191ins600.002476ins610.004453ins620.026422ins632ins642............步骤3.4、判断以点n为中心的邻域的节点密度是否大于临界阈值thr-ρ;步骤3.4.1、若大于thr-ρ,则该节点邻域内为密度可达,将该邻域标注为一个节点聚类簇,令其密度相连,将其内部所有的节点都标注为聚类节点,记录下其外部前后的一个节点的空间坐标;步骤3.4.2、若小于thr-ρ,则舍弃该节点邻域,继续遍历下一个节点;步骤3.5、当遍历完整个个体出行时空序列后,从头开始遍历每个判定的节点聚类簇,判断相邻的节点聚类所包含的节点之间是否有交集,若存在交集,则称该两个节点聚类簇之间密度可达,将这两个节点聚类簇合并为一个,令其密度相连,重新计算该合并后的节点聚类簇的节点密度,并统计聚类内的节点数量;在本例中,令thr-ρ等于2,最终得到的三个聚类,见表8。表8聚类结果nofromto12017-06-2000:00:002017-06-2008:30:0022017-06-2010:20:002017-06-2017:20:0032017-06-2019:20:002017-06-2024:00:00步骤3.6、若聚类内的插值点数量小于阈值thr-n,则表明个体在该聚类内的停留时间太短,达不到驻留标准,舍弃该聚类;在本例中,令thr-n等于30分钟,本例中的三个聚类时间都在30分钟以上,因此保留聚类结果;步骤3.7、遍历每个留存下来的节点聚类簇,计算每个节点聚类簇的加权中心点c,其中权重w为聚类内节点距离其排序中心点的序号差,若聚类内节点数为m个,则第1个和第m个节点的权重w最小,第个节点的权重最大,聚类中心点c的x-y坐标为,在本例中,三个聚类的中心点见表9:表9聚类中心点noxy13821.9415598.46128478.6176259.92133821.9415598.461步骤4、对经济活动和非经济活动类型进行划分,选取其中的典型样本的出行时空序列数据,统计其在指定时间段内的聚类数量、聚类大小、聚类中心点所在位置等数值,挖掘不同活动类型的个体的空间出行活动特征,获得不同活动类型的典型特征参数及其上下界误差范围,作为个体活动类型的判别依据;步骤4.1、将经济活动与非经济活动人口分类;其中,经济活动人口划分为职住分离白天全职型、职住分离夜间全职型、职住分离轮岗全职型、职住分离白天兼职型、职住分离夜间兼职型、职住分离混合型、厂区居住型、公司居住型、教师、在校高中大学学生、自由职业者、失业者;非经济活动人口分为:在校初中小学生、退休人员、居家无劳动能力者;步骤4.2、选取若干已明确活动特征的个体(包含经济活动人口和非经济活动人口)出行时空序列作为样本;在本例中,职住分离白天全职型的样本出行时空序列样本见表10:表10职住分离白天全职型样本出行时空序列(一天)recordidtimestampregioncodesensorid........................ins482017-03-2000:00:0098783442ins492017-03-2000:10:0098783442........................ins502017-03-2007:10:0098783442ins512017-03-2007:20:0098785462ins522017-03-2007:30:0098788562ins532017-03-2007:40:0098787845ins542017-03-2007:50:0098782354ins552017-03-2008:00:0098789845........................ins562017-03-2012:10:0098789845ins572017-03-2012:20:0098785624ins582017-03-2012:30:0098789845........................ins592017-03-2019:10:0098789845ins602017-03-2019:20:0098784165ins612017-03-2019:30∶0098788995ins622017-03-2019:40∶0098784323ins632017-03-2019:50:0098782133ins642017-03-2020:00:0098787459ins642017-03-2020:10:0098783442........................ins642017-03-2023:50:0098783442........................步骤4.3、计算样本个体出行时空序列的洛伦兹曲线和基尼系数;步骤4.3.1、遍历样本个体出行时空序列,读取其中的节点及其通信传感器编号;步骤4.3.2、统计每条出行时空序列中与每个通信传感器发生通信行为节点(包括记录点和插值点)的数量,对传感器以节点数量从小到大排序,画出个体出行时空序列的洛伦兹曲线;洛伦兹曲线的定义为:设全球各个国家/地区的(x1,x2,...,xn),(y1,y2,...,yn)分别为根据“人均所有量”从低到高排序得到的相应的国家/地区的人口和碳排放所有量占全球总数的比例。(xi,yi)表示国家j的人口比例和所有量比例。则以点绘制散点图得到洛伦兹曲线;洛伦兹曲线的两端分别为(0,0)点和(1,1)点;在本发明中,由于传感器本身是均质的,所以不需要考虑平均的概念,因此在本发明中,设各个传感器的(x1,x2,...,xn),(y1,y2,...,yn)分别为根据“通信节点数量”从低到高排序得到的相应的传感器和通信节点数量占全球总数的比例。因此(x1,x2,...,xn)的数值都为1/n,(y1,y2,...,yn)为各个传感器的通信节点数占总节点数的比例,仍然以绘制洛伦兹曲线;步骤4.3.3、根据洛仑兹曲线得到的各个传感器根据“通信节点数量”从低到高排序得到的相应的传感器和通信节点数量占全球总数的比例,计算个体出行时空序列中传感器分布的基尼系数;基尼系数的表达方式有很多种,本专利采用最典型的计算方法:基尼系数的值等于洛伦兹曲线与45°的直线所围成面积占45度直线与x轴,x=1所围成的面积的比。由于45°直线与x轴,x=1所围成的面积等于0.5,因此碳排放的基尼系数实际也等于洛伦兹曲线与45°的直线所围成面积的两倍,它在数值上位于区间[0,1)上;基尼系数越小,则说明结果越趋于公平;对于本发明,个体出行时空序列的基尼系数的数学表达可写为:在本例中,职住分离白天全职型的样本出行时空序列的以节点数排序的固定位置传感器列表及其节点数见表11:表11职住分离白天全职型样本出行时空序列分传感器节点数(一天)获得的全局的洛仑兹曲线如图2所示。步骤4.4、采用步骤3.1-3.3的方法,计算出指定时间段内各个样本的空间聚类特征,包括聚类数量、聚类大小、聚类中心点所在位置;步骤4.5、以聚类覆盖的时间为大小,统计每天各种大小的聚类的平均数量(具体分为12+小时聚类、10-12小时聚类、8-10小时聚类、6-8小时聚类、4-6小时聚类、2-4小时聚类、0-2小时聚类),以聚类大小为x坐标,聚类数量为y坐标,计算聚类大小分布;在本例中,职住分离白天全职型样本出行时空序列的聚类大小分布见表12:表12职住分离白天全职型样本出行时空序列聚类大小平均分布(个/天)聚类大小平均出现频率(个/天)12+0.3810-121.038-100.926-80.054-60.062-40.150-20.46步骤4.6、提取聚类点中心所在地,将其划分为住宅区、厂区、办公楼、购物中心、商业设施、医院、学校、广场公园、道路等,个体平均有每天在上述地点的累积聚类时间,将其按照固定顺序排列,以累积时间的长短作为累积量,计算个体日常生活中驻留地类型的分布特征;在本例中,职住分离白天全职型样本出行时空序列的驻留地分布见表13表13职住分离白天全职型样本出行时空序列的驻留地分布驻留地类型平均驻留时间(小时/天)住宅11.2厂区0办公楼9.8购物中心0.3商业设施0.05医院0学校0广场公园0.1道路0步骤4.7、根据得到的各个典型出行时间序列样本的出行活动特征(包括洛伦兹曲线、基尼系数、聚类大小分布和驻留地类型分布),计算各种经济活动类型的人群日常空间活动的平均出行特征及其上下界误差范围,作为对后续步骤中对大量样本的识别判断的统计基础;对于洛伦兹曲线、聚类分布和驻留地类型分布,本专利取取各样本与统计平均之间相关系数的最低值和关键节点的上下界作为误差范围;对于基尼系数,本专利直接取各样本与统计平均之间的最大差值作为误差范围;洛仑兹曲线本身为离散函数,且x轴取值点各不相同,因此在做相关性分析的时候分别取两条洛仑兹曲线上的数值点f(x),x={0.1,0.2,0.3,......,0.8,0.9}进行相关性分析;在本例中,通过多样本计算训练,得到职住分离白天全职型样本出行时空序列的四种特征:洛仑兹曲线、基尼系数、聚类大小分布和驻留地分布的平均值关键节点上下界见图3、表14、表15:表14、职住分离白天全职型基尼系数平均值和上下界平均值上界下界0.7410.52表14、职住分离白天全职型聚类大小平均分布及其关键节点上下界(个/天)表15、职住分离白天全职型驻留地分布及其关键节点上下界(个/天)驻留地类型平均驻留时间(小时/天)上界下界住宅10.514.58.2厂区11.312.57.4办公楼10.212.46.2购物中心0.20.80商业设施0.31.20医院0.20.40学校0.20.50广场公园0.11.20道路000其中三种特征:洛仑兹曲线、聚类大小分布和驻留地分布的相关系数见表16:表16、职住分离白天全职型三种特征相关系数最低值特征类型取值洛仑兹曲线0.75聚类大小分布0.62驻留地分布0.68步骤5、遍历个体出行时空序列,依据步骤4获得的经济活动判别特征和参数,对每个个体的经济活动类型进行判断和识别;步骤5.1、遍历每条待识别的个体出行时间序列,采用步骤3.1-3.3的方法进行节点的空间聚类,得到其日常空间活动范围的聚类结果;步骤5.2、采用步骤4.2-4.6的方法,计算出每条个体出行时间序列的洛伦兹曲线、基尼系数、聚类分布和驻留地分布;本例中,表5显示的个体出行时空序列,其完整序列的基尼系数为0.8746,洛仑兹曲线,聚类分布和驻留地分布见图4、表17和表18:表17个体出行时空序列聚类分布表18个体出行时空序列驻留地分布驻留地类型平均驻留时间(小时/天)住宅11.5厂区0办公楼9.3购物中心0.5商业设施0医院0学校0广场公园0.5道路0步骤5.3、对计算得到的洛伦兹曲线、基尼系数、聚类大小分布和驻留地分布,将其与步骤4.7得到的各种活动类型的平均值、平均曲线进行比较(分为相关系数计算和关键节点对比),寻找与其最为相似的活动类型,比较该出行时空序列与该活动类型的各曲线和参数的相关系数和关键节点差值,若满足其上下界范围,则将其归类到与其最为相似的活动类型中;在本例中,对比发现个体出行时空序列的特征与职住分离白天全职型的特征相关度最高,且其四种特征关键节点的值都在职住分离白天全职型的特征关键节点取值上下界之间,因此判定该个体出行时空序列为职住分离白天全职型。步骤5.4、若个体出行时间序列与任何一种典型样本的相关系数和关键节点的差值都大于其上下界范围,则将其定义为异常样本,提取出来人工判别进行归类,并将其作为典型样本存入样本库;步骤5.5、遍历完所有个体出行时空序列后,统计提取所有的人工判别的异常记录,将其作为典型样本,重新对各个典型经济活动类型进行训练,校正曲线和判别参数。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1