一种问答社区中的感知信息质量度量方法与流程
本发明属于信息系统中的信息质量研究领域,q&a问答社区作为当前社会网络媒体的重要载体,其具有较强的协作性和交互性,感知信息质量作为信息度量的一个侧面,反映了人们对内容的主观评价。选择合适的评价指标,有助于帮助用户和网站管理者对社区内容的主观信息质量获得客观的认识。
背景技术:
当今用户在社会网络媒体上产生的内容不断增多,如何在这种环境下度量数据质量的问题渐渐显得重要起来。感知信息质量在传统web环境和现在高度交互的web环境下在关键的几个方面已经具有了很大的不同。但是,感知信息质量在这两种环境下的度量范畴是相同的,分为三个方面:
1.主观范畴:包括基于个人观点,经验和社会背景的主观度量维度,例如在q&a社区中的信誉,对某些内容的反馈或关联。
2.客观范畴:可以通过对信息本身进行分析,来确定其度量维度,例如完整性,时序性,客观性或者可观测到的数据个数。
3.流程范畴:在社交网络媒体中,有许多数据是在用户使用过程中产生的,例如查询操作,访问操作以及平台响应时间等。
虽然传统网络媒体和社会网络媒体在范畴上相同,但在范畴内部已经发生了一些变化,具体体现在以下几个方面:
1.客观范畴的区别:社会网络媒体仍然具有完整性,时序性和一致性等度量维度,但是数据的数量成为了最被重视的客观度量维度,因为他反映了网络信息的快速增长,体现了社会网络媒体信息过载的特点。
2.流程范畴的区别:用户与平台交互过程中的准确性,安全性,可访问性依旧重要,但两者在具体度量标准下的数据表现的差异明显增大。
3.主观范畴的区别:在社会网络媒体中,用户反馈和个人信誉是最为主要的两个度量维度。值得注意的是,最不被人所关注的个人信誉一跃而上,成为了最常被人提起的维度之一。内容的适当性,可理解性和可信度依然是主观范畴下的重要度量维度。
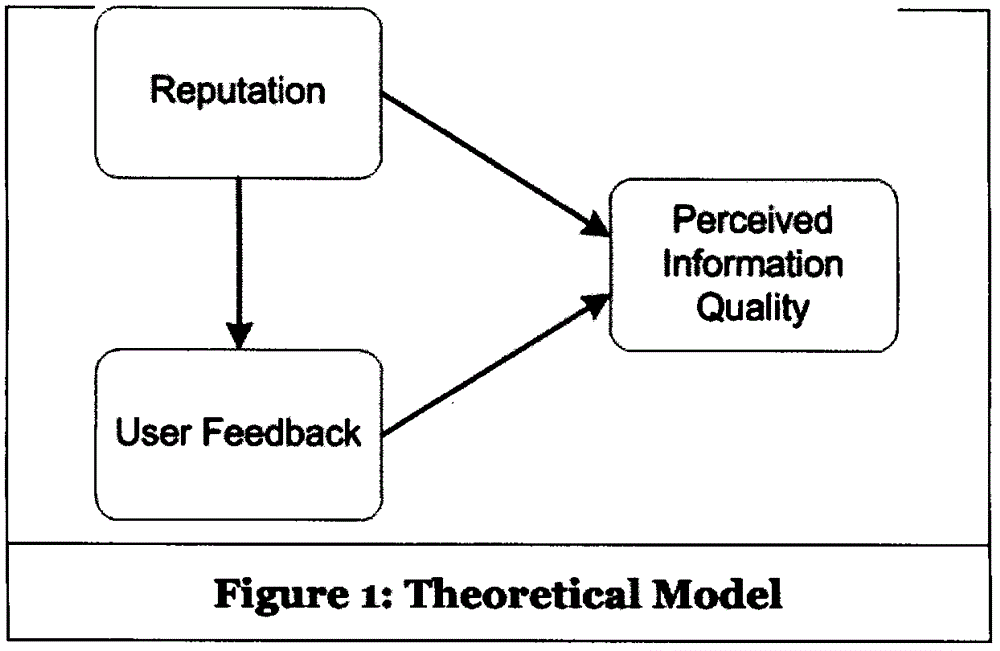
这些区别说明了用户已经逐渐适应快速变化的网络环境,差异因素正在影响他们对于信息质量的观念。社交网络媒体展现出了更高的交互性和内容增长速度,因此一些度量维度正在被其他更适合的维度所替换。其中变化最大的集中在主观范畴,而主观范畴中个人信誉和用户反馈究竟与哪些可度量的因素相关,以及如何影响感知信息质量的度量,是该领域研究的重点。
为此,我们使用假设检验的方法,找出了在q&a问答社区中主观范畴的感知信息质量的测度的相关因素。
技术实现要素:
为了度量感知信息质量,要探究个人信誉和用户反馈是如何影响感知信息质量的,为此,我们明确了三个概念,提出了三个命题,并使用它们构建了一个理论关系模型。
概念1:个人信誉。在社交网络媒体环境中,用户能够识别他人,包括他们自己的立场的程度。
概念2:用户反馈。一种特定类型的用户生成的内容,是使用对其他信息内容的响应而创建的。
概念3:感知信息质量。关于信息对解决问题的有用性的主观判断
命题1:内容提供者信誉的增加与感知的信息质量正相关。
命题2:用户反馈的增加与感知信息质量呈正相关。
命题3:内容提供者信誉的增加和用户反馈呈正相关
在此基础上,我们选择了q&a问答社区作为实验环境,因为其中包含许多可量化的指标,可以帮助我们将理论模型实例化。
附图说明
图1为理论关系模型。
图2为假设模型。
具体实施方式
此项研究的数据来源于theworkplace问答社区,它是stackexchange的子站之一,其中与工作的话题,如“标准的职场礼仪与惯例是什么”。其他用户可以提供答案、对答案进行评分、评论某个问题或答案,以及根据一个回答的质量支持或否定某个答案。选择这个q&a问答网站有两个原因,1)关于交换的讨论通常是专业化的,由少数人主导,因此可以提供高质量的数据集,并且该网站具有良好的包容性和交互性,这使得其受众为更广泛的用户,而不是少数人;2)该网站官方报告为,在324个讨论过的题目中,100%的问题(n=6505)至少得到了一个答案(n>21000)。这表明在许多不同的主题上都有充分的建议,这将提高可靠性和普遍性。
在此前面理论模型和该数据集的基础上,我们通过五个可量化的指标和八个假设,构建了可实际操作的假设模型。
h1.a-b和h2.a-d测试了信誉和用户规范对感知信息质量的影响程度。h3.a和h3.b测试了信誉对用户反馈的影响程度
表1为这5个指标的定义:
用户信誉是对用户先前行为的评分。表2列出了样本行为,不同的行为可以增加或减少用户的信誉评分。
用户反馈通过两个指标来衡量:1)回答的评论数;2)其他用户对于该答案的评分总和。感知信息质量也用两个指标来衡量:1)答案的得分;2)是否是最佳答案。该指标是由问题的作者提出的,因此代表了个人对回答质量的看法。
在进行假设检验之前,对数据的本质进行了基本的分析。上述的每个指标都给出了5个统计数字,具体数值见表3,这表明每个有序变量都有负的倾斜。同样,二进制变量(ba)的频率分析表明,大约19%(n=203)被选为最佳答案。因变量的分布最好符合负偏正峭度分布,因此对这些作为因变量的值进了对数变换(as_l)。为了确保在使用对数变换时不发生错误,需要在该函数中添加一个常数4。
通过表4我们发现,ac和sc的相关性接近60%,因此为了预防h1.a到h2.d发生多重共线,我们对假设进行了逐步的分层回归分析。
表5给出了使用对数变换的分层回归评分结果,其中as_l作为因变量。结果表明,as_l与sc有很强的正相关关系(β=552×**);as_l和信誉没有显着的相关性(β=08纳秒);ac没有达到95%可信区间,但在当前样本量的敏感性阈值之外可能存在负相关(β=14ns,p=067)。
在表6中,ac和sc显示出出负偏态和很高比例的零值。因此,我们对这些变量之间的关系作了两组测试。首先,使用二元logistic回归分析来检验是否ra能够预测这些答案能否收到其他用户的评论,以及获得对它质量的评价。这些数据表明,ra和回答是否收到评论之间没有显著的相关性,beta<=001,p=0.481;ra和是否该评论的质量获得评价也没有显著的相关性,beta<=0.001,p=0.485。然后,ra和ac,beta=0.050,p=636,以及ra和sc之间都没有显著的相关性,beta=0.149,p=0.256。
综合以上分析,分析结果最终支持了三个假设。h1.b表明回答者的信誉对某条回答的感知信息质量有预测作用,其呈正相关;h2.c和h2.d表明用户反馈的质量和两个感知信息质量的测度间,存在正相关性。
- 还没有人留言评论。精彩留言会获得点赞!