一种基于数组私有化的并发大数据实时处理方法与流程
本发明属于大数据和互联网技术领域,具体涉及一种并发大数据的数组私有化方法。
背景技术:
目前,在大数据处理领域,因涉及的数据量级以及数据类型都具有相当高的复杂性和多样性,为了节省存储空间和内存资源,人们最常用的处理方法就是变量复用,这就造成了在迭代和循环过程中,变量反复的定义、重定义和反复引用的问题,同时阻碍了程序的并发处理,大大降低了数据处理的效率,而这对于实时性要求高的并发大数据处理场景来说是不可接受的。
技术实现要素:
为解决以上问题,尽量避免变量的频繁定义和复用,提高并发大数据处理的实时性和高效性,本发明提供了一种基于数组私有化的并发大数据实时处理方法。
本发明的技术方案为:
一种基于数组私有化的并发大数据实时处理方法,其特征在于:包括以下步骤:
a.临时数组变量的过滤,并利用临时变量的被写特征点在循环体中的相对位置,初步划分可私有化的数组;
b.利用暴露集特性理论,对步骤a粗选后的临时数组变量进行数组变量的可私有化过滤;
c.采用近似暴露集算法对循环嵌套中的临时变量数组进行可私有化判定;
d.对可私有化的临时数组变量进行私有化变换;
e.可私有化临时数组变量的原始数值的记忆与终止数值的转存。
进一步的,所述步骤a的具体实现方式为:
在分类出的临时变量中,根据变量的被写点位置,在本次循环体外或者本次循环体内的,可初步识别出可私有化处理的变量:
(1)若临时变量的被写点在前次循环中完成:
doi=1:n
operateva…
va=…
enddo
临时变量va不可进行私有化处理;
(2)若临时变量的被写点在迭代循环以外完成:
va=…
doi=1:n
operateva…
enddo
可以对临时变量va进行私有化处理;
(3)若临时变量的被写点在本次循环体内:
doi=1:n
va=…
operateva=…
enddo
可以对临时变量va进行私有化处理。
进一步的,所述步骤b的具体实现方式为:
根据数组元素暴露的特性——若数组元素在程序体中是暴露的,那么该数组元素在程序体中是先读后写的,即,假设一个n维临时数组变量array=[a1a2…an],若其中某元素ai是现在程序体program外赋值,后在program中被引用,那么数组元素ai就是program中暴露的,而array中相对于program中所有暴露元素的集合就是暴露集合,记为uep(array);
从步骤a中,临时数组变量依据被写点的相对位置关系可知,临时数组变量可私有化的充要条件是:当且仅当一个程序体中各循环迭代暴露集没有跨循环的写相关数据流,即,
其中,uelpi(array)表示在程序体第i次lp循环体中临时数组变量array的暴露集;
特别地,在循环迭代体中,若该临时数组变量的
其中,2≤i≤led,led为循环次数。
进一步的,所述步骤c的具体实现方式为:
如果对数组元素的读写操作间没有反相关性,那么在循环中就可以把读写操作交换顺序来执行,即,rd操作在循环体lp中引用的数组元素如果同时也在
其中,rd表示lp循环体中的读操作;wr表示lp循环体中的写操作;setlp表示lp循环体中的引用元素集合;rlp表示lp中的读操作集合;wrlp表示lp中的写操作集合。
进一步的,所述步骤d的具体实现方式为:
经过以上a步骤,b步骤以及c步骤后,可得到并发大数据处理程序中的所有可私有化的临时数组变量,记为mtr=[array1array2…arrayn],基于以上内容,即可对可私有化的临时数组变量集一一展开私有化变换,变量在循环体中的被写点的位置不同,共有两种私有化变换方式:
(1)被写点在迭代循环以外完成:
该类情况,是可以对va进行私有化处理的,处理方法如下:
va=…
doalli=1:n
localpra
pra=va
operatepra…
enddoall
即,临时变量被写点在循环以外时,将串行迭代中的临时变量指定为私有变量,然后对私有变量进行操作,即可消除临时变量并使迭代并行;
(2)被写点在本次循环体内:
对于这种情况,临时变量的私有化方法如下:
doalli=1:n
localpra
pra=…
operatepra…
if(i=n)then
va=pra
endif
enddoall
特别的,对于数组变量来说,有可能部分数组元素在循环体外被写,而另一部分在循环体内被写,因此就有了两种处理方式:
(1)精确的区分出哪些元素在循环体外,哪些在循环体内,按照各自的私有化方式分别私有化处理;
(2)无论元素是否在循环体外被写,都是可私有化的,因此对所有元素统一进行私有化处理;
进一步的,所述步骤e的具体实现方式为:
按可私有化数组元素的被写点相对于循环体的位置,可判断出哪些原始数值、哪些终止数值需要动态转存:
其中,remi(rd)表示在lp循环体中,每一次循环需要进行原始值记忆的数据集;lsti(wr)表示在lp循环体中,每一次循环需要动态转存终止数值的数据集。
本发明的有益效果为:该方法避免了并发大数据处理过程中变量的频繁定义和复用,提高了并发大数据处理的实时性和高效性。
附图说明
图1为一种基于数组私有化的并发大数据实时处理流程图。
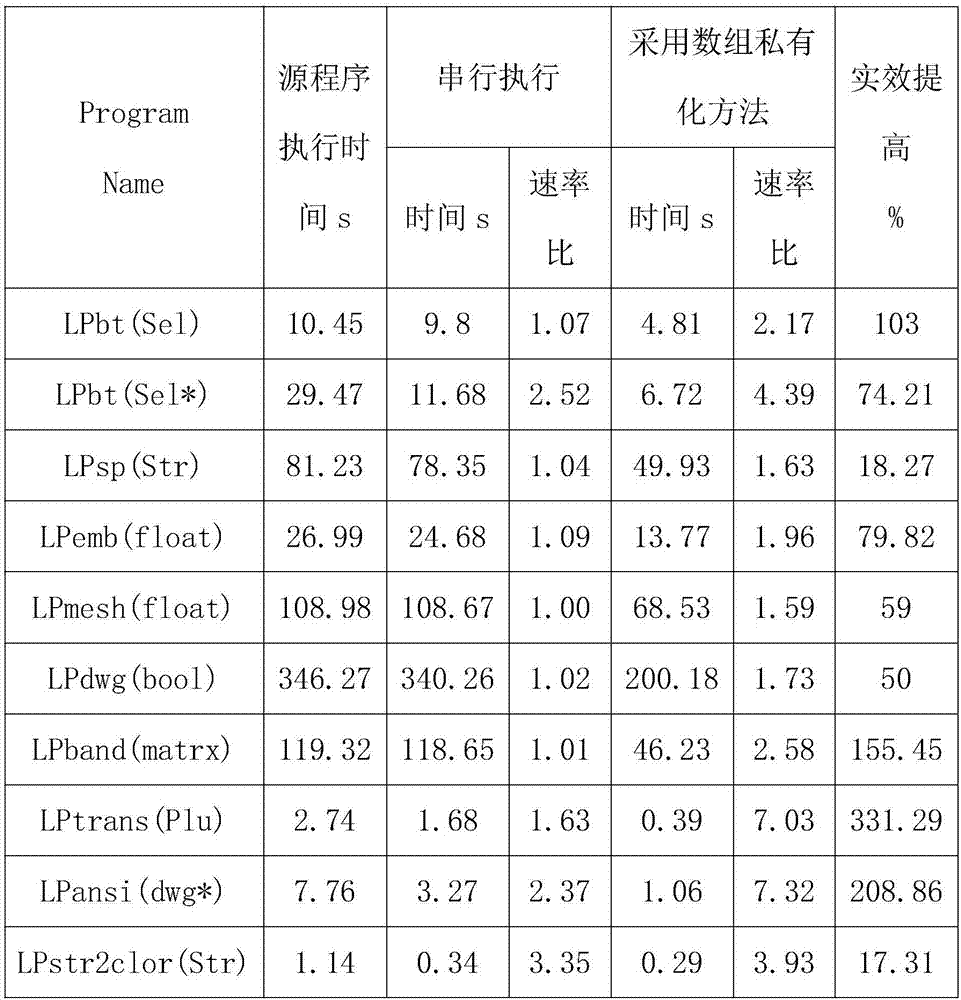
图2为基于数组私有化的并发大数据实时处理实验成效表。
具体实施方式
如图1所示,一种基于数组私有化的并发大数据实时处理方法包括以下步骤:
a.临时数组变量的过滤,并利用临时变量的被写操作点(以下简称“被写点”)在循环体中的相对位置,粗糙划分可私有化的数组:
数组的私有化可对任意变量使用,但只有对程序中大量的临时变量应用才具有显著的应用成效,因此首先要过滤出临时变量。我们利用临时数组变量的定义特性——在处理程序中会被反复的定义,即具有跨迭代输出特性相关的变量才是临时变量。
(1)若临时变量的被写点在前次循环中完成:
doi=1:n
operateva…
va=…
enddo
可知,被写点在前次循环中,临时变量va是不可进行私有化处理的。
(2)若临时变量的被写点在迭代循环以外完成:
va=…
doi=1:n
operateva…
enddo
很明显该类情况,是可以对va进行私有化处理的。
(3)若临时变量的被写点在本次循环体内:
doi=1:n
va=…
operateva=…
enddo
很明显这种情况也是可以对临时变量va进行私有化处理的。
在分类出的临时变量中,根据变量的被写点位置,在本次循环体外或者本次循环体内的,可初步识别出可私有化处理的变量。
这样对大量的临时变量进行粗糙私有化分类,可大大降低数据维数,同时降低后续算法的运算量。
b.利用暴露集特性理论,对步骤a粗选后的临时数组变量进行数组变量的可私有化过滤:
根据数组元素暴露的特性——若数组元素在程序体中是暴露的,那么该数组元素在程序体中是先读后写的,即,假设一个n维临时数组变量array=[a1a2…an],若其中某元素ai是现在程序体program外赋值,后在program中被引用,那么数组元素ai就是program中暴露的,而array中相对于program中所有暴露元素的集合就是暴露集合,记为uep(array)。
从步骤a中,临时数组变量依据被写点的相对位置关系可知,临时数组变量可私有化的充要条件是:当且仅当一个程序体中各循环迭代暴露集没有跨循环的写相关数据流,即,
其中,uelpi(array)表示在程序体第i次lp循环体中临时数组变量array的暴露集;
特别地,在循环迭代体中,若该临时数组变量的
c.采用近似暴露集算法对循环嵌套中的临时变量数组进行可私有化判定
在处理程序的构成中,数据处理相关的循环体往往会嵌套使用,即lpm循环体中会有lpn,甚至多个不同的循环,那么采用暴露集特性理论来判定临时数组变量的可私有性将会非常困难,因此对于循环嵌套中的临时数组变量,采用近似暴露集算法。
如果对数组元素的读写操作间没有反相关性,那么在循环中我们就可以把读写操作交换顺序来执行,即,rd操作在循环体lp中引用的数组元素如果同时也在
由此可知,
由(1)和(3)条件可得,
但是由(3)(4)(6)三式可知,rd和wr在lp循环体中有反相关性,与(6)式矛盾。由以上反证过程可得结论:
即本发明的重要创新点之一——近似暴露集算法。
其中,rd表示lp循环体中的读操作;wr表示lp循环体中的写操作;setlp表示lp循环体中的引用元素集合;rlp表示lp中的读操作集合;wrlp表示lp中的写操作集合。
d.对可私有化的临时数组变量进行私有化变换。
经过以上a步骤,b步骤以及c步骤后,可得到并发大数据处理程序中的所有可私有化的临时数组变量,记为mtr=[array1array2…arrayn],基于以上内容,即可对可私有化的临时数组变量集一一展开私有化变换。
变量在循环体中的被写点的位置不同,共有两种私有化变换方式:(1)被写点在迭代循环以外完成:
该类情况,是可以对va进行私有化处理的,处理方法如下:
va=…
doalli=1:n
localpra
pra=va
operatepra…
enddoall
即,临时变量被写点在循环以外时,将串行迭代中的临时变量指定为私有变量,然后对私有变量进行操作,即可消除临时变量并使迭代并行。
(2)被写点在本次循环体内:
对于这种情况,临时变量的私有化方法如下:
doalli=1:n
localpra
pra=…
operatepra…
if(i=n)then
va=pra
endif
enddoall
特别的,对于数组变量来说,有可能部分数组元素在循环体外被写,而另一部分在循环体内被写,因此就有了两种处理方式:
(1)精确的区分出哪些元素在循环体外,哪些在循环体内,按照各自的私有化方式分别私有化处理。
(2)无论元素是否在循环体外被写,都是可私有化的,因此对所有元素统一进行私有化处理。
对于数据量很小的情况下,第(1)种方式更为精确,第(2)种方式更为简单易实施。而在实际应用中,因为数据体量的巨大,采用第(2)种方式在精度上几乎等同于第(1)种方式,但却可以提高执行效率60%以上,因此在并发大数据的处理中,部分私有化的变量直接采用方法(2)进行统一私有化效果更好。
e.可私有化临时数组变量的原始数值的记忆与终止数值的转存:
在大数据领域,每一阶段每一项数据的价值在不同业务逻辑下是不同的,因此在临时数组变量的私有化处理前后,算法应当具有原始数值记忆与终止数值的转存考虑。
仍然按可私有化数组元素的被写点相对于循环体的位置,可判断出哪些原始数值、哪些终止数值需要动态转存,算式如下:
其中,remi(rd)表示在lp循环体中,每一次循环需要进行原始值记忆的数据集;lsti(wr)表示在lp循环体中,每一次循环需要动态转存终止数值的数据集。
综上,即完成了本发明所述一种基于数组私有化的并发大数据实时处理方法。
特别地,为证明该方法的有效性,在xoreaxincredibuild编译系统中实现了这种方法,并在同一计算环境中多次对比了原串行处理程序和采用本发明数组私有化方法后,两处理程序的运行速率比,得到了图2所述结果,可见,采用本发明所述方法后,对常用类型的并发大数据的实时处理时效都有较明显的提升。
该方法避免了并发大数据处理过程中变量的频繁定义和复用,提高了并发大数据处理的实时性和高效性。
- 还没有人留言评论。精彩留言会获得点赞!