基于RGBD相机的人脸实时三维重建方法与流程
本发明涉及计算机视觉技术领域,尤其涉及一种基于RGBD相机的人脸实时三维方法重建。
背景技术:
随着RGBD相机和计算机视觉的发展,三维重建技术展现了广阔的应用前景。其中,基于RGBD相机的人脸几何与反射率快速重建在智能移动设备上的应用将会在消费娱乐、动画制作、远程协作等领域产生广泛影响。
基于RGBD相机实现人脸三维重建的方式主要有两种:一、基于人脸多线性模型和混合形状模型的方法;二、基于Volume的一般三维重建方法。前者是对若干人脸几何模板进行线性组合得到最终三维模型,几何模板的数量决定了模型的表达能力,因此该方法的模型小、处理速度快,但表达能力有限,得到的三维重建结果缺乏纹理细节。后者是将一般的基于Volume的三维重建方法应用到人脸三维重建当中,模型结构庞大,难以做到实时三维重建;且该方法重建出来的三维模型缺少语义信息,对于人脸这种具有丰富语义信息的对象,重建效果有所欠缺。
目前没有一种实时的、表达效果好的人脸三维重建方法,给人脸三维重建带来诸多不便。
技术实现要素:
本发明为了解决现有技术中没有一种实时的、表达效果好的人脸三维重建方法的问题,提供一种基于RGBD相机的人脸实时三维重建方法。
为了解决上述问题,本发明采用的技术方案如下所述:
本发明提供一种基于RGBD相机的人脸三维重建方法,包括以下步骤:S1:采集彩色图像和深度图像:利用RGBD相机采集一帧正面人脸的彩色图像和深度图像;S2:获取第一点集:在所述彩色图像中提取人脸特征点的图像坐标,将所述人脸特征点的图像坐标投影到所述深度图像中,获得人脸特征点的三维坐标,人脸特征点的三维坐标的点集记为第一点集;S3:求解人的头部姿态、身份系数、表情系数并构建纹理图像的数据偏移量:利用所述第一点集和所述深度图像迭代求解人的头部姿态,并迭代求解人脸多线性模型中的身份系数和表情系数;构建纹理图像的数据偏移量,所述数据偏移量包括深度数据偏移量和颜色数据偏移量;S4:计算得到当前人脸模板以及人脸三维几何模型:利用人脸多线性模型和人脸混合形状模型计算得到当前人脸模板;更新所述数据偏移量,由当前人脸模板和更新的数据偏移量计算得到人脸三维几何模型;S5:得到更新的人脸三维几何模型:继续采集下一帧彩色图像和深度图像,依次利用步骤S2、S3、S4的方法进行处理,得到更新的人脸三维几何模型。
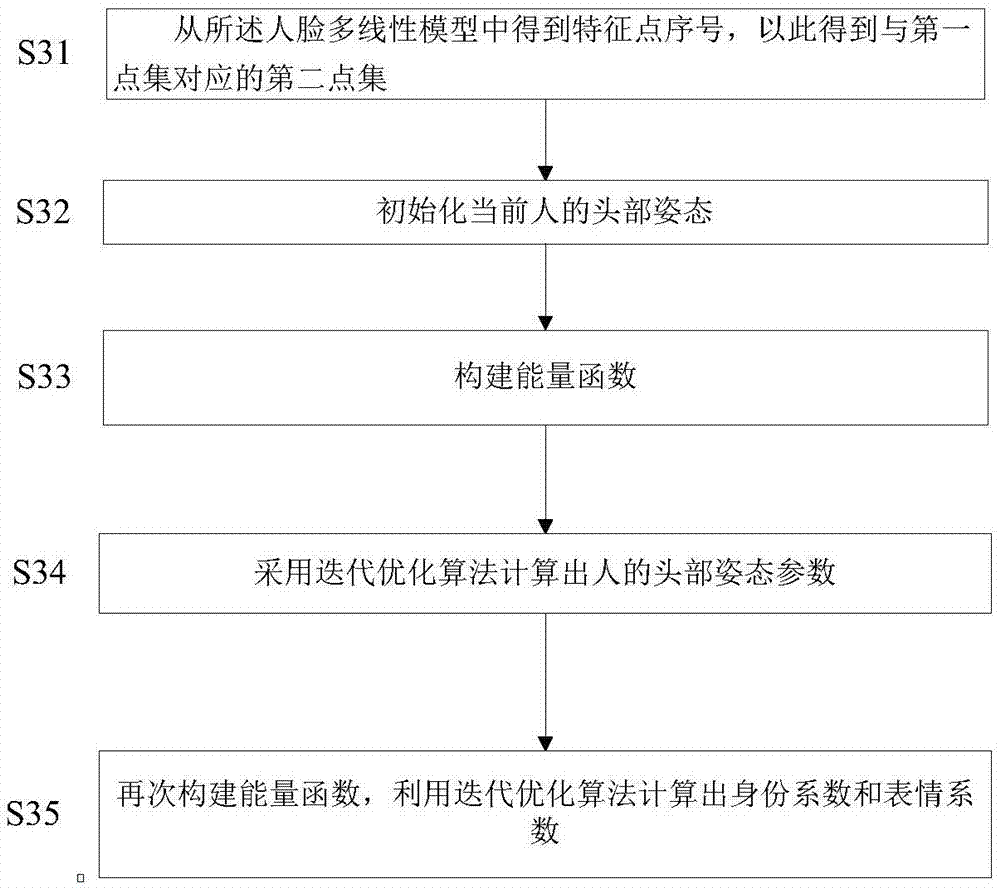
步骤S3中求解人的头部姿态、身份系数、表情系数的方法包括:S31:从所述人脸多线性模型中得到特征点序号,以此得到与第一点集对应的第二点集;S32:初始化当前人的头部姿态;S33:构建能量函数:Epos=ω1E1+ω2E2,其中L0是所述第一点集;lk是第一点集中的特征点坐标,l′k是第二点集中特征点的坐标;F0是所述深度图像中与人脸多线性模型中有对应关系的点的集合,为第三点集,fk是第三点集中点的三维坐标;f′k是人脸多线性模板中与第三点集对应的点的三维坐标;R、t是人的头部姿态参数,ω1和ω2是两部分能量函数的系数;S34:采用迭代优化的方法最小化能量函数Epos,计算出人的头部姿态参数;S35:再次构建能量函数,利用迭代优化算法计算出身份系数和表情系数。
步骤S4中计算得到当前人脸模板以及人脸三维几何模型的方法包括:将人脸多线性模型通过身份系数加权平均得到当前人脸的混合形状模型,所述人脸的混合形状模型为具有相同身份、不同表情的模板的混合;然后结合表情系数计算得到当前人脸模板。当前人脸模板的计算公式为:其中B为当前人脸模板,Bi为人脸的混合形状模型,wexp(i)为表情系数向量wexp的第i个分量。深度数据偏移量的计算公式为:其中Bump(u,v)为深度数据的偏移量,Color(u,v)为颜色数据的偏移量,初始值均为0,Weight(u,v)为所述人脸特征点的深度数据和/或颜色数据的可信度,V(u,v)为所述第三点集中的点的三维坐标,N(u,v)为V(u,v)的法向量,V′(u,v)为N(u,v)投影在深度图像上的点的三维坐标,令p=V′(u,v)-V(u,v),C′为V′(u,v)在所述彩色图像上的颜色数据。人脸三维几何模型中点的坐标计算公式为:M(u,v)=V(u,v)+Bump(u,v)N(u,v)。
本发明的有益效果为:基于RGBD相机的人脸三维重建方法是利用采集得到的彩色图像和深度图像在人脸多线性模型和人脸混合形状模型的基础上,进一步构建纹理图像的数据偏移量得到人脸三维几何模型,该方法计算量小,易实现实时计算;采用较少的存储量实现较为精细的几何细节和纹理建模,是一种实时的、表达效果好的人脸三维重建方法。
附图说明
图1是本发明实施例中基于RGBD相机的人脸三维重建方法示意图。
图2是本发明实施例中求解人的头部姿态、身份系数和表情系数的方法示意图。
具体实施方式
下面结合附图通过具体实施例对本发明进行详细的介绍,以使更好的理解本发明,但下述实施例并不限制本发明范围。另外,需要说明的是,下述实施例中所提供的图示仅以示意方式说明本发明的基本构思,附图中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的形状、数量及比例可为一种随意的改变,且其组件布局形态也可能更为复杂。
实施例1
人脸三维重建的发展
实时的人脸的三维重建是一个非常重要的研究问题,这个研究领域有着广泛的应用场景,比如智能监控、机器人、人机交互等。随着计算机视觉、图像处理、及其学习等技术的发展,越来越多的人脸重建方法被提出来。普通的视频相机可以提供丰富的颜色和纹理信息,这对于人脸三维重建非常有用,但是其捕获到的数据极易受到光照变化的影响,同时在某些复杂场景中,背景和前景的纹理可能高度类似。与传统的二维灰度或彩色图像相比,深度图像可以提供拍摄对象到相机的距离信息。利用每个像素位置的深度值以及相机内部参数信息,可以方便地对拍摄对象进行形状与尺寸度量,同时,因为深度数据收表面纹理的影响较少,所以目标分割、背景剪切等问题变得更加容易。
目前深度相机主要有三种形式:基于双目视觉的深度相机、基于结构光的深度相机以及基于TOF(时间飞行法)的深度相机。以下进行简要说明,无论哪种形式都可以被用在实施例中。
基于双目视觉的深度相机是利用双目视觉技术,利用处在不同视角的两个相机对同一空间进行拍照,两个相机拍摄出的图像中相同物体所在像素的差异与该物体所在的深度直接相关,因而通过图像处理技术通过计算像素偏差来获取深度信息。
基于结构光的深度相机通过向目标空间投射编码结构光图案,再通过相机采集目标空间含有结构光图案的图像,然后将该图像进行处理比如与参考结构光图像进行匹配计算等可以直接得到深度信息。
基于TOF的深度相机通过向目标空间发射激光脉冲,激光脉冲经目标反射后被接收单元接收后并记录下激光脉冲的来回时间,通过该时间计算出目标的深度信息。这三种方法中第一种一般采集彩色相机,因而受光照影响大,同时获取深度信息的计算量较大。后两种一般利用红外光,不受光照影响,同时计算量相对较小。目前双摄相机、利用VCSEL芯片做为光源的结构光、TOF相机都可以被嵌入到手机、电脑等设备中。
微软公司发布了Kinect成像设备,该设备由深度传感器(基于结构光原理)和RGB视频相机两部分组成。该设备的采集速度可以达到30帧/秒,分辨率为640*480,深度数据的有效范围约为0.5-10米,其中0.8-3.5米之间的深度数据准确率较高。其他的RGBD相机,比如的Kinect Xbox 360、Kinect One、Xtion和Orbbec也随之出现。
对于人脸三维重建,基于RGBD相机的重建技术有如下的优势:RGBD相机能够快速获取深度信息;RGBD相机是一种主动传感器,不易受环境可见光谱的干扰;RGBD相机的操作与普通摄像机类似,易于使用。目前,将RGBD相机应用于物体建模,面临的挑战主要有:1)如何用RGBD相机快速地重建出人脸完整的三维模型;2)重建系统需要对RGBD相机从各个视角获取的三维点云进行配准,在三维点云配准失败或配准结果误差较大时,如何保证重建系统能够正确运行,并得到完整的物体模型;3)对于有遮挡的人脸如何重建出较完整的物体模型;4)如何系统地评估RGBD相机人脸重建的精度等。基于RGBD相机实现人脸三维重建的方式主要有两种:一、基于人脸多线性模型和混合形状模型的方法;二、基于Volume的一般三维重建方法。前者是对若干人脸几何模板进行线性组合得到最终三维模型,几何模板的数量决定了模型的表达能力,因此该方法的模型小、处理速度快,但表达能力有限,得到的三维重建结果缺乏纹理细节。后者是将一般的基于Volume的三维重建方法应用到人脸三维重建当中,模型结构庞大,难以做到实时三维重建;且该方法重建出来的三维模型缺少语义信息,对于人脸这种具有丰富语义信息的对象,重建效果有所欠缺。
人脸三维重建的方法
本发明为了解决现有技术中没有一种实时的、表达效果好的人脸三维重建方法的问题,提供一种基于RGBD相机的人脸实时三维重建方法。
如图1所示,
一种基于RGBD相机的人脸三维重建方法,包括以下步骤:
(1)采集彩色图像和深度图像:利用Kinect采集一帧中性正面人脸的彩色图像C0和深度图像D0;
(2)获取第一点集:在彩色图像C0中提取人脸特征点(landmark),并将特征点的图像坐标投影到深度图像D0中,获得特征点的三维坐标,并将人脸特征点对应的三维点集记为第一点集L0;
(3)求解人的头部姿态、身份系数、表情系数并构建纹理图像的数据偏移量:利用第一点集L0和深度图像D0迭代求解人的头部姿态[R,t],并迭代求解人脸多线性模型中的身份系数wid和表情系数wexp;构建纹理图像的数据偏移量,数据偏移量包括深度数据偏移量Bump(u,v)和颜色数据偏移量Color(u,v);
(4)计算得到当前人脸模板以及人脸三维几何模型:利用人脸多线性模型和人脸混合形状模型计算得到当前人脸模板B;更新数据偏移量,更新所述数据偏移量包括更新深度数据偏移量和/或更新颜色数据偏移量;由当前人脸模板B和更新的数据偏移量计算得到人脸三维几何模型M;
(5)得到更新的人脸三维几何模型:对于每个新采集到的彩色图像Ct和Dt(其中t≥1),类似步骤(2)中的方法提取人脸三维特征点集Lt;类似步骤(3),利用迭代优化的方法计算当前人脸姿态[R,t],并估计混合表情系数wexp;类似步骤(4),更新Bump(u,v)和color(u,v);利用Bump(u,v)和color(u,v)更新最终人脸三维几何模型M。
如图2所示,求解人的头部姿态、身份系数和表情系数的方法包括如下步骤:
(1)从人脸多线性模型中得到特征点序号,以此得到与第一点集L0对应的第二点集LT;
(2)初始化当前人的头部姿态[R,t]=[I,0],其中I为单位矩阵,0为零向量;
(3)构建能量函数:Epos=ω1E1+ω2E2,其中L0是第一点集;lk是第一点集L0中的特征点坐标,l′k是第二点集LT中特征点的坐标;F0是深度图像中与人脸多线性模型中有对应关系的点的集合,为第三点集,fk是第三点集F0中点的三维坐标;f′k是人脸多线性模板中与第三点集对应的点的三维坐标;R、t是人的头部姿态参数,ω1和ω2是两部分能量函数的系数;
(4)采用迭代优化的方法最小化能量函数Epos,计算出人的头部姿态参数[R,t];
(5)再次构建能量函数,利用迭代优化算法计算出身份系数wid和表情系数wexp。
步骤S4中计算得到当前人脸模板以及人脸三维几何模型的方法包括:将人脸多线性模型通过身份系数wid加权平均得到当前人脸的混合形状模型{Bi}{1≤i≤N},人脸的混合形状模型{Bi}{1≤i≤N}为具有相同身份、不同表情的模板的混合;然后结合表情系数wexp计算得到当前人脸模板B。当前人脸模板B的计算公式为:其中B为当前人脸模板,Bi为人脸的混合形状模型,wexp(i)为表情系数向量Wexp的第i个分量。深度数据偏移量的计算公式为:其中Bump(u,v)为深度数据的偏移量,Color(u,v)为颜色数据的偏移量,初始值均为0,Weight(u,v)为人脸特征点的深度数据和/或颜色数据的可信度,V(u,v)为第三点集中的点的三维坐标,N(u,v)为V(u,v)的法向量,V′(u,v)为N(u,v)投影在深度图像上的点的三维坐标,令p=V′(u,v)-V(u,v),C′为V′(u,v)在彩色图像上的颜色数据。V(u,v)是所述人脸多线性模型中网格顶点的坐标或由网格顶点坐标插值得到。
人脸三维几何模型中点的坐标计算公式为:M(u,v)==V(u,v)+Bump(u,v)N(u,v)。
在本发明的变通实施例中,人脸特征点提取和跟踪方法包括但不限于级联特征提取器、端到端神经网络等人脸特征点提取和跟踪方法,所提取的特征点数量包括但不限于68点、74点等常用人脸特征点数量。
在本发明的变通实施例中,RGBD相机包括但不限于Kinect Xbox 360、Kinect One、Xtion、Orbbec等可同时采集彩色图像和深度图像的传感器。
本发明的方法是利用采集得到的彩色图像和深度图像在人脸多线性模型和人脸混合形状模型的基础上,进一步构建纹理图像的数据偏移量得到人脸三维几何模型,该方法计算量小,易实现实时计算;采用较少的存储量实现较为精细的几何细节和纹理建模,是一种实时的、表达效果好的人脸三维重建方法。并不拘泥与本发明所说的设备,其他可以同时采集彩色图像和深度图像的能够实现本发明方法的设备也可以;本发明得到的实时的、表达效果好人脸三维几何模型可以有多种应用,基于本发明的方法得到的人脸三维几何模型的进一步应用也应该属于本发明所要保护的范围。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!