一种基于透明计算的增量机器学习方法及系统与流程
本发明涉及机器学习领域,特别是一种基于透明计算的增量机器学习方法及系统。
背景技术:
随着移动网络和各种轻量级客户端的普及,物联网不断地改变着我们的日常生活。智能手机、可穿戴设备和移动传感器等各种物联网应用已经广泛应用于医疗、智能家居、环境监测、智能交通等领域。传统上,轻量级客户端只具有数据收集和数据显示的能力。然而,在许多情况下,为了能够确保实时性能,我们更倾向于使得客户端具有一些职能功能,比如面部识别、目标检测等,这些功能不需要将数据传送到服务器进行处理。另外,在一些诸如隧道、偏远地方等网络连接较差的地区,我们更希望客户端具备智能能力。因此,智能化已经逐渐成为了物联网环境下的各类客户的基本要求。
机器学习可以分为无监督学习和监督学习,它是实现机器智能的一种有代表性的技术。与无监督学习相比,监督学习的应用更为广泛。监督学习通常包括数据训练和数据测试,前者输入大量的训练数据,然后使用相应的算法生成相应的测试模型,而后者使用测试模型来对新的样本进行分析判断。一般来说,数据训练需要消耗大量的计算资源,但是一旦测试模型生成,测试就可以以很少的计算资源快速地完成。
在客户端不断轻量化和小型化的趋势下,物联网环境下的机器学习面临着新的问题,即计算能力和服务需求的不匹配。具体而言,包括以下几个方面:
(1)客户端的异构性。客户端采集到的数据往往来自不同的设备,例如传感器、程序生成、用户生成等等。不同的设备需要兼容性各不相同的训练算法,使得训练成本大幅提高。
(2)计算能力有限。客户端的计算能力往往很难存储大量的数据,也很难对其进行较为复杂的运算处理。
(3)通信消耗。当大量数据需要传输到云端服务器进行处理的情况下,服务可能会因为大量的通信消耗而产生延迟,并且训练过程只能在线完成,并不能离线进行。
技术实现要素:
本发明所要解决的技术问题是,针对现有技术不足,提供一种基于透明计算的增量机器学习方法及系统,避免多客户端差异造成的兼容问题,缓解因计算能力不足而导致的系统延迟,缓解由于单个节点存储能力有限而造成的io阻塞的问题,降低由于通信消耗而造成的系统延迟,提高用户体验度。
为解决上述技术问题,本发明所采用的技术方案是:一种基于透明计算的增量机器学习方法,包括以下步骤:
1)透明客户端、透明服务器以及边缘节点同时进行数据采集;其中,透明客户端采集到的数据发送到透明服务器以及边缘节点的存储空间中;
2)透明服务器和边缘节点根据采集到的数据以及各自的计算能力分别对各自节点上的数据进行训练;
3)透明服务器和边缘节点将训练生成的测试模型分别发送到相应的透明客户端中;
4)将测试数据分别根据不同节点以及服务器获得的测试模型进行测试,透明客户端对静态的测试结果进行整理,根据测试结果的分类概率进行均值计算,进而更新最终的测试结果;
5)用户根据得到的最终的测试结果进行独立判断,并将判断结果反馈到透明服务器或边缘节点中;透明服务器和边缘节点收集到来自用户反馈的数据信息,暂时存储起来,等待收集到的反馈信息积累到一定的量,即各个类别的反馈数据信息都达到了可以进行训练的数量,重复步骤2)到步骤4)。。
相应的,本发明还提供了一种基于透明计算的增量机器学习系统,其包括:
透明客户端:用于与透明服务器以及边缘节点同时进行数据采集,并将采集到的数据发送到透明服务器以及边缘节点的存储空间中;
透明服务器:用于与透明客户端以及边缘节点同时进行数据采集,并根据采集到的数据以及自身的计算能力对自身节点上的数据进行训练,然后将训练生成的测试模型分别发送到相应的透明客户端中;将测试数据分别根据不同的测试模型进行测试,对静态的测试进行动态的更新,最终综合所有的测试结果来更新测试结果;
边缘节点:用于与透明客户端以及透明服务器同时进行数据采集,并根据采集到的数据以及自身的计算能力对自身节点上的数据进行训练,然后将训练生成的测试模型分别发送到相应的透明客户端中;
用户端:用于根据得到的测试结果进行独立判断,并将判断结果反馈到透明服务器或边缘节点中,这些被反馈的数据信息和采集到的数据一起进行下一轮训练。
与现有技术相比,本发明所具有的有益效果为:
(1)解决客户端的异构性,使得不同类型的客户端采集到的数据统一传输到透明服务器或边缘节点来进行训练操作,避免了由于客户端差异而造成的兼容问题。
(2)将数据训练过程分散到透明服务器和各个边缘节点中,减少单个节点的计算量,缓解了因计算能力不足而导致的系统延迟。
(3)采集到的数据通过一种多级缓存管理策略(以往的情况下,客户端承担了存储采集到的数据的任务,但是在这种方法框架下,客户端在第一步直接将采集到的数据转移存储到服务器和边缘节点中)分散存储到透明服务器和边缘节点中,缓解了由于单个节点存储能力有限而造成的io阻塞的问题。
(4)由于数据被分散到服务端和各个边缘节点进行处理,以及客户端可以通过接收到的测试模型来进行离线测试,所以大幅降低了由于通信消耗而造成的系统延迟。
(5)实时性。由于透明客户端中存储了大量已经训练好的测试模型,进而保证了测试结果能够在离线状态下实时得到,提高用户体验度。
附图说明
图1为本发明系统框架图;
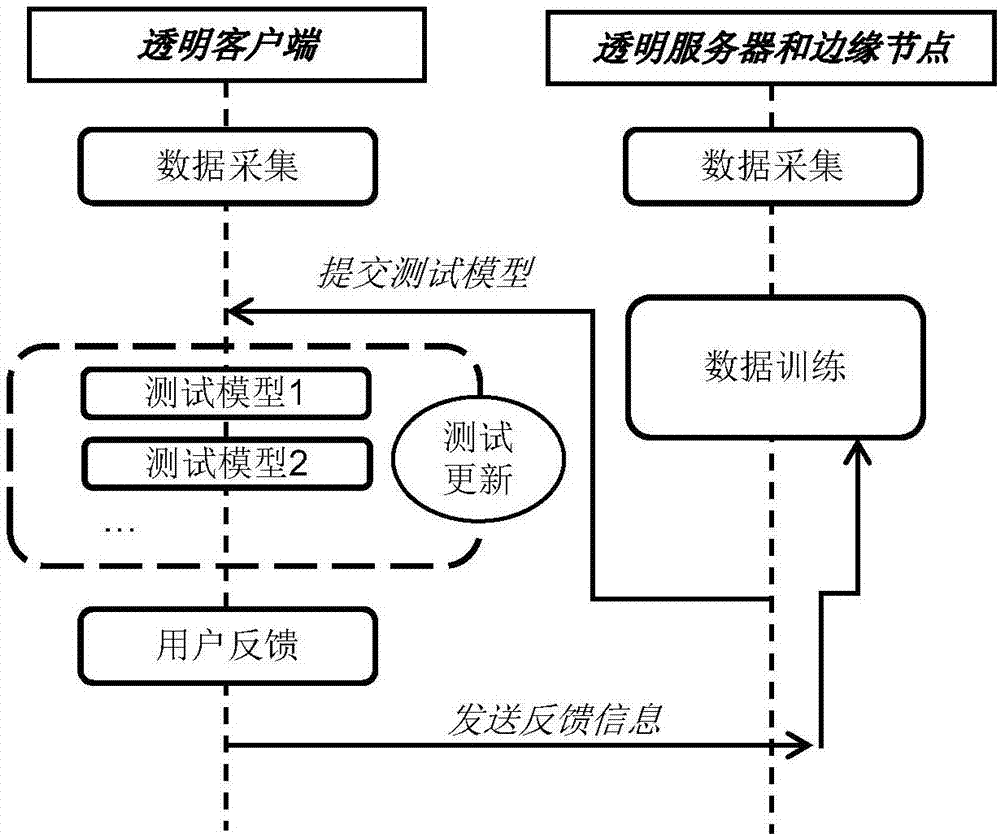
图2为本发明增量学习流程图。
具体实施方式
如图1所示,本发明系统的框架如图1所示。它主要包含三个部分:透明服务器、透明客户端、边缘节点。训练的数据可以从三个部分获得,但数据训练只能在有着较强计算能力的透明服务器和边缘节点上进行。
透明服务器和透明客户端中的网络配置中存储了从客户端到透明服务器之间的所有边缘节点的通讯信息。基于透明客户端上的测试模型,透明客户端可以进行用户测试,并且用户可以对测试的结果进行用户反馈,修订其正确性。透明客户端、边缘节点和透明服务器都可以进行数据采集,一旦数据采集发生在透明客户端,它可以将采集到的数据通过网络发送到边缘节点或者透明服务器。采集到的数据将存储在透明服务器的存储器或者各类节点的缓存中。另外,在边缘节点和透明服务器中还配置了相应的机器学习算法,例如深度学习、支持向量机等等。这些算法都是预配置在系统中的,并且将会在数据进行训练之前通过相应的安装包进行自动安装。机器学习算法还提供了数据训练所需要的训练模型,数据通过这些训练模型生成测试模型,并将这些测试模型发送到相应的透明客户端上,用来进行相应的用户测试。
在系统进行初始化和网络配置之后,系统将以一种增量学习的方式来运行。增量学习的流程如图2所示。
第一步,透明客户端、透明服务器以及边缘节点同时进行数据采集。其中,透明客户端采集到的数据将发送到另外两类节点的存储空间中。
第二步,透明服务器和边缘节点根据采集到的数据以及各自的计算能力分别对各自节点上的数据进行数据训练。
第三步,透明服务器和边缘节点将训练生成的测试模型分别发送到相应的透明客户端中。
第四步,将测试数据分别根据不同的测试模型进行测试,透明客户端将对静态的测试进行动态的更新,最终综合所有的测试结果来更新测试结果,提高测试的准确率。
第五步,用户可以根据得到的结果进行独立判断,判断结果将通过用户反馈将反馈信息重新发送到透明服务器或边缘节点中,这些被反馈的数据信息将和采集到的数据一起进行下一轮训练。
本发明由于采用了基于透明计算的增量机器学习框架,使得其可以在低网络依赖的前提下,高效的进行机器学习。并且本发明将训练数据进行拆分处理,在保证了测试精确度的情况下大幅降低了机器学习的时间消耗,提高了机器学习的效率。另外,本发明还通过增量式的反馈学习,不断地提高机器学习的准确性。
- 还没有人留言评论。精彩留言会获得点赞!