一种基于词向量的句子相似度比较方法与流程
本发明涉及一种基于词向量的句子相似度比较方法,属于自然语言处理
技术领域:
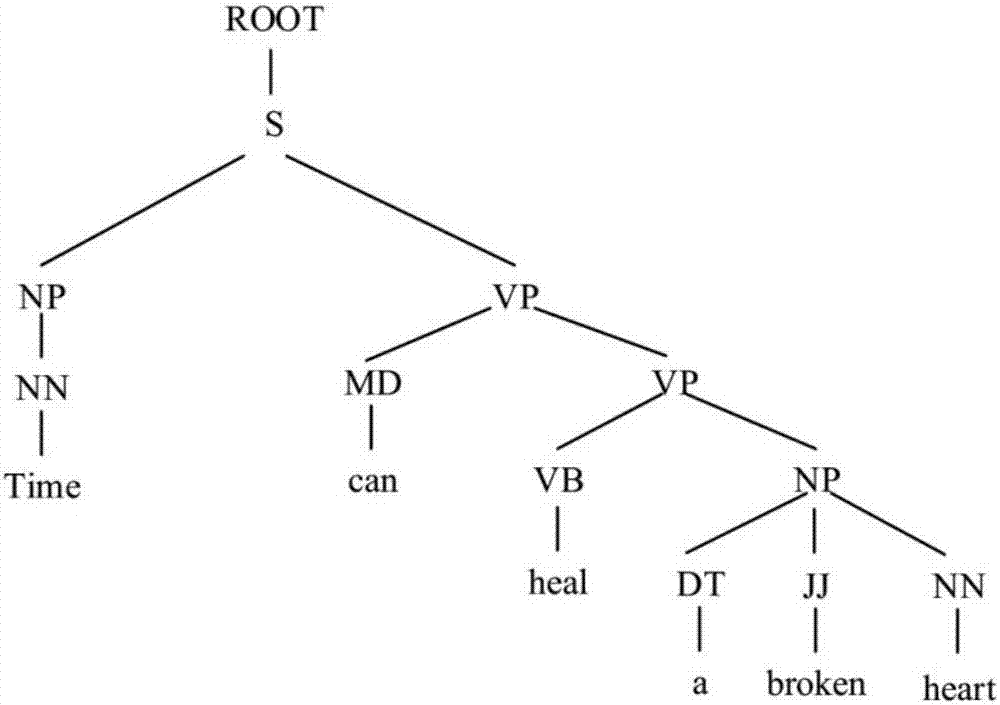
。背景内容句子相似度比较是自然语言处理的一个基本任务,它广泛应用于很多领域,比如信息检索、机器翻译、文本分类等。只要是需要判断二个句子相似性的场景,都离不开句子相似度判断方法。相似度判断方法越准确,有利于提高各种需要用到此相似度方法的系统的性能。句子相似度测量是自然语言处理中许多应用程序的核心,也是大多数文本相关任务的基础。句子相似度方法研究有很长的历史,有基于向量空间模型的方法,也有将句子通过神经网络嵌入成句子向量的方法,这一类方法最近取得了很大的成功,比如利用dnn(深度神经网络),rnn(循环神经网络),lstm(长短期记忆网络)等。但是这种将句子表示成向量的做法忽略了句子本身存在的句法信息,会丢失句子的句法信息。技术实现要素:本发明克服现有技术存在的不足,本发明公开了一种基于词向量的句子相似度比较方法。本发明基于大型语料库训练得到词向量模型,并且通过斯坦福句法分析器将句子表示成句法成分树结构,然后在词向量模型中搜索句子成分树叶子节点所对应的词向量,这此基础上,我们提出了一种基于词向量的句子相似度比较方法,这种方法首先构建句子成分向量树,然后通过我们提出的softpartialtreekernel函数计算最终的句子相似度得分。实验结果表示,这种方法相对于目前性能表现很强的众多神经网络方法,在超过一半数据集上都取得了最好的效果,并且在平均性能上取得了最先进的效果。这说明了这种方法是一种很有效的句子相似度度量方式。这说明了这种方法是一种很有效的句子相似度度量方式。为解决上述技术问题,本发明所采用的技术方案为:一种基于词向量的句子相似度比较方法,其特征在于,包括如下步骤:步骤一、训练得到词向量模型,所述词向量模型包含词和词的向量;步骤二、对于待测试的句子对,分别生成句子的句法成分树结构,每个句子对应的句法成分树结构的叶子节点都为句中的词;步骤三、基于句子的句子成分树结构,构建句子向量树结构;步骤四、将句子向量树结构输入计算,即得到二个句子向量树结构的相似度得分。进一步的改进,所述步骤一中,使用维基百科文本作为训练语料,使用word2vec工具训练词向量,得到词向量模型。进一步的改进,所述步骤二中,使用斯坦福句法分析器,生成句子的句法成分树结构;若所述句子为中文,则预先进行分词处理。进一步的改进,所述步骤三,包括如下步骤:3.1)基于句子成分树结构,构建叶子节点集;3.2)遍历叶子节点集中的每个词,到词向量模型中搜索词所对应的词向量,构建叶子节点词向量集;3.3)遍历句子成分树结构的每一个叶子节点,每个叶子节点都包含在叶子节点集中,按照叶子节点集到叶子节点词向量集的一一对应关系,将叶子节点替换成叶子节点集中所对应的词向量。进一步的改进,所述步骤四中,包括如下步骤:4.1)对于步骤三中构建的两个句子向量树结构t1,t2,首先生成句子向量树结构的子树集f1={n1,n2,…,ni},f2={m1,m2,…,mj},其中ni表示t1生成的最后一个子树的根节点,i表示t1生成子树的个数,mj代表t2生成的最后一个子树的根节点,j代表t2生成子树的个数;4.2)句子成分向量树相似度其中nl表示f1中任意一个元素,其中mk表示f2中任意一个元素;δ(nl,mk)表示nl和mk的相似度;这个式子表示将f1和f2中所有元素两两成对对比,计算值为δ(nl,mk),然后累加。进一步的改进,所述δ(nl,mk)的计算方法如下:4.3)如果nl和mk是不相同的并且不同时为叶子节点,则δ(nl,mk)=0;4.4)如果nl和mk同时为叶子节点,则δ(nl,mk)=cosine(vec1,vec2),vec1表示叶子节点nl对应的词向量,vec2表示叶子节点mk对应的词向量;cosine()表示对向量求余弦相似度;4.5)如果nl和mk都为非叶子节点且相同,则其中,μ表示树的高度的衰减因子,λ表示子序列的长度的衰减因子;表示以nl为根节点的孩子节点按照字典序排列而成的字符序列,表示以mk为根节点的孩子节点按照字典序排列而成的字符序列;和这二个字符序列长度的最小值其中表示字符序列的长度,表示字符序列的长度,表示取和这二个字符序列长度的最小值;函数δp表示求和在长度为p的公共子序列上的相似度,p表示字符序列生成子串长度的取值,若一个字符序列长度为h,则p的取值范围为1~h;4.6)δp函数计算过程如下:设和s1a表示以nl为根节点的子树的孩子节点按顺序组成的字符序列,a表示以nl为根节点的子树的最后一个孩子节点,s1表示以nl为根节点的子树的孩子节点按字典顺序排列后除去最后一个孩子节点a之后组成的字符序列;s2b表示以mk为根节点的子树的孩子节点按顺序组成的字符序列;b表示以mk为根节点的子树的最后一个孩子节点,s2表示以m1为根节点的子树的孩子节点按字典顺序排列后除去最后一个孩子节点b之后组成的字符序列;则具体计算如下:其中|s1|表示字符序列s1的长度,|s2|表示字符序列s2的长度,t表示字符序列s1生成子串序列取值长度,取值范围为1~|s1|,r表示字符序列s2生成子串序列取值长度,取值范围为1~|s2|,s1[1:t]表示从s1字符序列取下标从1到t位置的序列组成的字符子序列,s2[1:r]表示从s2字符序列取下标从1到r位置的序列组成的字符子序列;δ(a,b)表示单个节点的相似度,δ(a,b)的算法中分为以下几种情况:4.6.1.若节点a和节点b相同,则δ(a,b)=1;4.6.2.若节点a和节点b不相同且至少有一个为非叶子节点,则δ(a,b)=0;4.6.3.若节点a和节点b不相同且二者都是叶子节点,则δ(a,b)=cosine(veca,vecb),其中veca表示叶子节点a对应的词向量,vecb表示叶子节点b对应的词向量;4.6.4.最终的句子相似度计算公式为:其中,score表示最终的句子相似度,sptk(t1,t2)表示t1和t的句子成分向量树相似度;sptk(t1,t1)表示t1和t1的句子成分向量树相似度;sptk(t2,t2)表示t2和t2的句子成分向量树相似度。与现有技术相比,采用本发明具有如下优点:1.第一步,我们通过语料库经过训练得到词向量模型,语料库的选择可以根据具体的场景以及特地的领域进行选取,只要保证文字语法应该是基本正确的以及足够大即可。若没有语料,可以选择维基百科全部内容作为语料进行词向量训练。2.第三步,我们将词向量知识编码到句子成分树,从而构建了句子成分向量树,这种表示能很有效的将句子的句法以及词汇的语义考虑到一个统一的模型架构,从而能更有效的挖掘句子的语义信息。3.第五步,我们提出了一种能够用于计算句子成分向量树结构对的softpartialtreekernel函数,使得句子成分向量树能够很方便的计算相似度得分。4.本发明提出了一种基于词向量的句子相似度比较方法,这种方法相对于目前流行的神经网络方法,能取得一定可比较效果。附图说明图1为本发明的总流程示意图;图2为句子成分树的示意图;图3为句子成分向量树的示意图。其中,其中root表示根节点,s表示这个句子的开始节点,np表示名词短语,nn表示常用名词,vp表示动词短语,md表示情态助动词,vb表示动词,dt表示限定词,jj表示形容词或序数词。vectime,veccan,vecheal,veca,vecbroken,vecheart分别表示time,can,heal,a,broken,heart对应的词向量。具体实施方式如图1-3所示,本发明选用整个维基百科(本发明适用于选用其它大型语料)作为训练语料,使用word2vec工具训练词向量模型,词向量模型包含词和词的向量,通过词向量模型能够很方便的搜索到词汇所对应的词的向量。对于待测试的句子对(若句子是中文的,则需要分词,英文不需要),首先进行句子的预处理,预处理包括去除符号以及停用词。通过斯坦福句法分析器,将句子表示成句法成分树结构,此结构的叶子节点为句中的词,非叶子节点代表词的词性以及词之间关系。然后构建句子的句子成分向量树,基于句子的句子成分树,在词向量模型中搜索句子成分树的叶子节点所对应的向量,将叶子节点替换成词汇对应的向量。通过这种方式将待测的句子对表示成句子成分向量树,输入到树核函数(树核函数有很多种,本发明在ptk树核上进行了测试,设计了softpartialtreekernel函数),得到句子相似度得分。第一步、通过word2vec工具,训练得到词向量模型,训练的所用到的语料需要满足以下几点条件:1.训练语料必须足够大;2.训练语料所涉及的领域应该足够多(比如维基百科);3.训练语料所包含的文字语法应该是基本正确的,而不是通过随机文本生成的杂乱无章的文字;第二步、构建句子成分树,对于待测的句子对,通过句法分析,得到句子的句法成分树。例如,使用斯坦福句法分析器,将句子”timecanhealabrokenheart”表示成句子成分树(图2);第三步、基于句子的句子成分树结构,构建句子成分向量树。例如,将句子”timecanhealabrokenheart”表示成句子成分向量树(图3),具体过程如下:1.基于句子成分树,构建叶子节点集q={time,can,heal,a,broken,heart};2.遍历叶子节点集q中的每个词,去词向量模型中搜索词所对应的词向量,构建叶子节点词向量集p={vectime,veccan,vecheal,veca,vecbroken,vecheart};3.遍历句子成分树的每一个叶子节点,每个叶子节点都包含在叶子节点集q中,按照q到p的一一对应关系(比如time对应vectime),将叶子节点替换成叶子节点集q中所对应的词向量;4.构建完成;第四步、将待测的句子对按照第三步表示成句子成分向量树;第五步、基于句子成分向量树,我们提出一种softpartialtreekernel函数,使得这种树结构能够进行计算,具体计算过程如下:1.对于二棵树t1,t2,首先生成树的子树集f1={n1,n2,…,ni},f2={m1,m2,…,mj},ni表示t1生成的最后一个子树的根节点,i表示t1生成子树的个数,mj代表t2生成的最后一个子树的根节点,j代表t2生成子树的个数;2.使用softpartialtreekernel函数sptk(t1,t2)计算句子相似度如下:其中nl表示f1中任意一个元素,其中mk表示f2中任意一个元素,这个式子表示将f1和f2中所有元素两两成对按照δ函数(当元素为nl和mk时,计算值为δ(nl,mk)计算然后累加,δ函数具体计算过程依照3。3.以f1中第一个元素n1和f2中第一个元素m1为例。δ函数具体计算过程如下:3.1如果n1和m1是不相同的并且不同时为叶子节点,则δ(n1,m1)=0;3.2如果n1和m1同时为叶子节点,则δ(n1,m1)=cosine(vec1,vec2),vec1表示叶子节点n1对应的词向量,vec2表示叶子节点m2对应的词向量,cosine()表示对向量求余弦相似度;3.3如果n1和m1都为非叶子节点且相同,则其中μ和λ都为衰减因子,μ表示树的高度的衰减因子,λ表示子序列的长度的衰减因子。表示以n1为根节点的孩子节点按照字典序排列而成的字符序列,表示以m1为根节点的孩子节点按照字典序排列而成的字符序列。其中表示字符序列(每一个孩子节点为字符序列里面的一个元素)的长度,表示字符序列(每一个孩子节点为字符序列里面的一个元素)的长度,表示取这二个字符序列长度的最小值。δp函数表示求和在长度为p的公共子序列上的相似度,p表示字符序列生成子串长度的取值(若一个字符序列长度为h,则p的取值范围为1~h),δp的p取值从h减到1的时候就是δ函数的计算。δp函数具体计算过程依照3.4。3.4δp函数计算过程,以为例,s1a表示以n1为根节点的子树的孩子节点按顺序组成的字符序列(一个孩子节点看作字符序列里面的一个字符,a表示最后一个孩子节点),s2b表示以m1为根节点的子树的孩子节点按顺序组成的字符序列(一个孩子节点看作字符序列里面的一个字符,b表示最后一个孩子节点),s1表示以n1为根节点的子树的孩子节点按字典顺序排列后除去最后一个孩子节点a之后组成的字符序列,s2表示以m1为根节点的子树的孩子节点按字典顺序排列后除去最后一个孩子节点b之后组成的字符序列。则具体计算如下:其中|s1|表示字符序列s1的长度,|s2|表示字符序列s2的长度,t表示字符序列s1生成子串序列取值长度,取值范围为1~|s1|,r表示字符序列s2生成子串序列取值长度,取值范围为1~|s2|,s1[1:t]表示从s1字符序列取下标从1到t位置的序列组成的字符子序列,s2[1:r]表示从s2字符序列取下标从1到r位置的序列组成的字符子序列。δ(a,b)表示单个节点的相似度,在我们的算法中分为以下几种情况:(1).若节点a和节点b相同,则δ(a,b)=1;(2).若节点a和节点b不相同且至少有一个为非叶子节点,则δ(a,b)=0;(3).若节点a和节点b不相同且二者都是叶子节点,则δ(a,b)=cosine(veca,vecb),其中veca表示叶子节点a对应的词向量,vecb表示叶子节点b对应的词向量;第六步、最终的句子相似度计算公式为:第七步、结束我们基于2012年语义文本的相似性任务(semantictextualsimilaritytasks)开放的数据集进行了实验,实验对比了基于dan(深度平均网络),rnn(循环神经网络),irnn(循环神经网络的一种变体方法),lstmno(带有输出门的长短期记忆网络),lstmo.g.(不带输出门的长短期记忆网络)等先进的神经网络方法,如表1所示,我们的方法在超过一半数据集上都取得了最好的效果,并且在平均性能上取得了最先进的效果。tasksdanrnnirnnlstmnolstmo.g.scvtw2vmsrpar0.400.190.430.160.090.54msrvid0.700.670.730.710.710.73smteuroparl0.440.410.470.420.440.52onwm0.660.630.700.650.560.64smtnews0.600.510.580.610.510.55average0.560.480.580.510.460.66表1.实验结果图上述实施例仅仅是本发明的一个具体实施方式,对其的简单变换、替换等也均在发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1