一种基于脑功能网络特征对早晚期轻度认知障碍的分类方法及装置与流程
本发明属于医学影像图像处理
技术领域:
,具体涉及到利用静息态功能性磁共振成像(fmri)技术和脑功能网络特征对早期和晚期轻度认知障碍疾病分类。
背景技术:
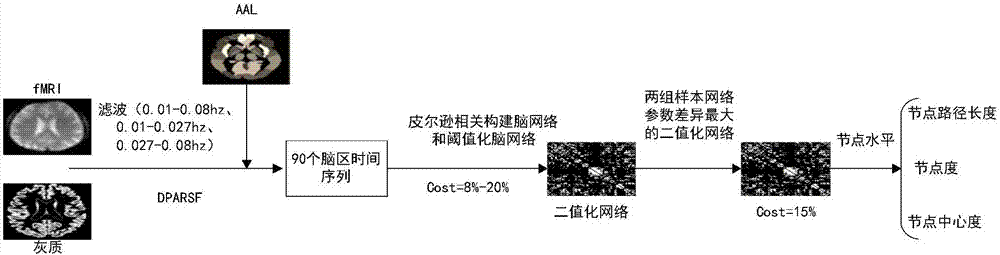
:轻度认知障碍(mci)是介于健康衰老和痴呆之间的一种中间阶段。有研究表明每年mci转移到老年痴呆症(ad)上的概率大概在10%~15%之间,而正常老龄人转变为ad则在1%~2%范围内。作为正常老龄化向痴呆过渡的中间阶段,mci受到了广泛的关注。根据mci疾病记忆损伤程度的不同,可以将mci病人分为早期mci患者(emci)和晚期mci患者(lmci)。但emci和lmci在多维信息上存在差异,寻找有效的分类生物标记并构建分类模式对两类患者进行分类,可以更好的了解病情的发展,能够加强对引起转变因素的了解,以促进对不同程度疾病进行针对治疗。研究表明mci疾病与大脑特殊脑区灰质减少、皮层厚度变薄、白质连接变化等有关。在mci疾病检测研究中,内嗅皮层,内侧颞叶,后扣带等脑区的萎缩有较高的敏感性和特异性,利用这些脑区进行分类也取得很好的分类效果。在emci和lmci两组的功能脑网络研究中,发现最短路径长度随着疾病程度增加而增加,而平均聚类系数随之降低;节点中心度在两组间也存在差异性,这些差异脑区为:左侧额下回三角部分,左侧眶额下回,左侧嗅皮质等。虽然小世界参数在emci和lmci统计不显著,但分别与正常老龄人与老年痴呆进行比较,发现部分参数在两两对比间存在显著性差异,但是差异的表现和区域不完全一致。在emci和lmci的研究中,人们更多的关注两组患者在大脑结构和功能上的差异,少有研究针对两组样本进行分类预测。利用认知评分,颞叶,顶叶和扣带脑区的体积参数对emci和lmci进行分类,goryawala等人报道了73.6%的分类精度,但两组样本在认知评分中存在显著性差异。在emci和正常人的分类中,根据先验知识,利用特定脑区的皮层厚度、皮层体积和对应脑区的新陈代谢变化进行分类,能获得较好分类结果(auc=0.668)。此外,mci疾病与不同频段的灰质活动有关,根据前人研究可以将低频bold(bloodoxygenationleveldependent)信号分为:full-band(0.01-0.08hz)、slow-4(0.027-0.073hz)、slow-5(0.01-0.027hz)、slow-3(0.073-0.0198hz)和slow-2(0.0198-0.25hz)几个频段,但是大脑灰质活动主要分布在slow-4和slow-5中。已有研究表明在mci患者中,slow-4和slow-5在后扣带、内侧前额叶和海马旁回等脑区存在显著性差异。可见分频段分类是个新的研究方向,但是少有研究利用不同频段功能网络对emci和lmci进行分类预测,因而有必要提出一种利用不同频段功能网络对emci和lmci进行分类预测的医学影像图像分类处理方法。技术实现要素:本发明的发明目的在于:针对上述存在的问题,提供一种利用脑功能网络特征对早期和晚期轻度认知障碍的分类方法及装置。本发明的基于脑功能网络特征对早晚期轻度认知障碍的分类方法,包括下列步骤:步骤1:获取训练样本:对采集的静息态功能磁共振数据(rs-fmri)进行预处理得到训练样本(对应不同的个体),所述预处理包括:格式转换、去时间点、时间层矫正、头动矫正、空间标准化、平滑、去线性漂移、滤波和去协变。步骤2:对训练样本进行脑网络特征提取:201:选择待提取的脑区,并分别提取每个脑区的时间序列(所有体素(像素)中的时间序列)的均值作为每个脑区的脑网络节点,得到m个脑网络节点构成的脑区网络节点集合v,其中m为脑区数;202:采用皮尔逊相关计算任意两个脑网络节点的相关系数,用i、j表示脑网络节点的区分符,ti、tj分别表示脑区i、j的时间序列(所有体素的时间序列)的元素,分别表示脑区i、j的时间序列的均值,则可得到脑网络节点i、j间的相关系数r(i,j)为:为了对区分不同的训练样本,定义训练样本n(训练样本标识符)的任意两个脑网络节点的相关系数为:即将两个脑区平均时间序列之间的相关系数定义为两脑网络节点的边,由皮尔逊相关系数得出。203:设置两个脑网络节点i和j间的连通性:若相关系数rn(i,j)大于或等于预设阈值γ(通过一定的稀疏度cost(值为百分比)来设置,前cost最大的相关系数的最小值作为阈值γ),则脑网络节点i和j间为连通;否则为不连通。例如定义“0”表示非连通,“1”表示连通,若rn(i,j)≥γ,则连通性bk(i,j)=1;否则bk(i,j)=0,从而得到脑网络w=(rij)m×m×n的二值化脑网络wcost=(bij)m×m×n,其中n为训练样本数。优选,可以通过下列步骤来设置cost的优选值costmax:在取值范围[8%,20%]内,基于预设步长(优选为1%)遍历ncost个稀疏度阈值cost,并基于每个稀疏度阈值cost脑网络节点i和j间的初始连通性:将相关系数rn(i,j)降序排序,并将前cost对应的脑网络节点间的连通性设置为连通;其它设置为非连通;基于对应每个稀疏度阈值cost的脑网络节点间的初始连通性,计算四种网络参数:(1)脑网络平均最短路径长度其中li表示脑网络节点i的最短路径长度,lij表示从脑网络节点i到脑网络节点j的最短路径数,|v|表示集合v的数目;(2)网络平均聚类系数其中脑区网络节点聚类系数ki表示脑网络节点i的节点连接数,即bij为二值邻接矩阵中对应i行j列位置的连通性值,ei为脑区网络节点i的邻居脑区网络节点组成的子网络中实际存在的边数;(3)全局效率(4)局部效率gi为与脑区网络节点i相连的脑区网络节点所构成的子图;从而得到每个训练样本的ncost组网络参数;将训练样本分为两组,一组的类别为晚期轻度认知障碍,另一组的类别为早期轻度认知障碍;采用双样本t(student'sttest)检验计算两组训练样本在关于血氧水平依赖bold信号的预设频段(例如full-band(0.01-0.08hz)、slow-4(0.027-0.073hz)、slow-5(0.01-0.027hz)等)下的各种网络参数的差异,获取最大差异所对应的cost值,记为costmax;在双样本t检验中,用分别表示两组训练样本的任意一种网络参数,则t分别为:其中分别表示对应的方差,n1、n2分别表示的训练样本数;最后,基于降序排序的相关系数rn(i,j)序列,将前costmax对应的脑网络节点间的连通性设置为连通,其它设置为非连通。204:基于脑网络节点间的连通性,提取每个训练样本的脑网络特征集合{k,b,l}:计算每个脑网络节点的节点连接数ki,由m个脑网络节点的节点连接数ki得到脑区网络节点度集合k;计算每个脑网络节点的中心度其中sjm表示脑网络节点m和j之间存在的最短路径个数,sjm(i)表示脑网络节点m和j中最短路径经过节点i的个,由m个脑网络节点的中心度得到脑区网络节点中心度集合b;计算从脑网络节点i到脑网络节点j的最短路径数lij,得到脑网络节点i的节点路径长度由m个节点路径长度li得到脑区网络节点路径长度集合l。步骤3:提取训练样本的特征向量:由步骤2可得到每个训练样本的每个脑区的脑网络特征ki、bi和li,对所有脑区的三类脑网络特征进行随机组合,得到种组合数据;并对每个训练样本的每种组合数据采用逐步分析方法进行特征筛选,并记录每一个组合所选择的特征标号(包括脑区标识符和脑网络特征类别标识符),得到组合选择特征集其中k为训练样本(个体)标识符,c为组合方式标识符;统计所有组合中各特征标号的出现概率,取出现概率最大的前tth(预设值,例如15)个特征标号所对应的脑网络特征作为每个训练样本的特征向量。其中第k个训练样本的任意特征标号的出现概率的计算公式可以表示为:存在函数j为脑区标识符,p为脑网络特征类别标识符,c为组合方式标识符。步骤4:基于所有训练样本的特征向量训练用于区分早期和晚期轻度认知障碍的二分分类器。例如采用基于径向基核函数进行支持向量机(svm)分类器训练,得到支持向量机训练所述二分分类器:首先对特征向量进行归一化预处理(分类处理时,同样需要进行相同的归一化预处理),例如采用映射公式对各特征向量进行归一化预处理,其中x表示特征向量的元素,即未归一化预处理的原数据,y是归一化之后的数据,xmin是原数据中最小的数据,xmax是原数据中最大的数据;然后对训练集采用10折交叉验证法进行参数优化,采用径向基核函数进行分类训练,得到二分分类器。步骤5:输入待分类的静息态功能磁共振数据,并采用提取训练样本的特征向量相同的方式,提取待分类的静息态功能磁共振数据的特征向量;并输入所述二分分类器得到分类结果。本发明还公开了一种基于脑功能网络特征对早晚期轻度认知障碍的装置,所述装置包括:用于采集静息态功能磁共振数据的采集装置;用于接收所述静息态功能磁共振数据的计算机,所述计算机被编程以执行上述分类方法的步骤。本发明的另一种基于脑功能网络特征对早晚期轻度认知障碍的装置,包括:数据预处理模块:对采集的不同个体的静息态功能磁共振数据进行预处理;脑网络特征提取模块:对预处理后的静息态功能磁共振数据提取脑网络特征,生成每个个体的脑网络特征集合{k,b,l}:特征向量提取模块:基于个体的脑网络特征集合{k,b,l}生成个体的归一化特征向量;二分分类器:用于基于个体的归一化特征向量区分早期和晚期轻度认知障碍的二分分类器,输入为个体的归一化特征向量,输出个体的轻度认知障碍的状态为早期或晚期;所述二分分类器基于基于多个训练样本的归一化特征向量进行训练得到。即数据预处理模块将预处理后的数据发送至脑网络特征提取模块,脑网络特征提取模块再将所提取到的个体的脑网络特征集合发送给特征向量提取模块,以生成个体的归一化特征向量,再将其作为二分分类器的输入,生成待检测个体的轻度认知障碍的状态结果:早期还是晚期轻度认知障碍。综上所述,由于采用了上述技术方案,本发明的有益效果是:本发明首先对样本数据进行预处理和提取多个脑区时间序列,采用皮尔逊相关计算脑区时间序列之间的相关系数构建脑功能网络,计算脑网络参数。其次采用逐步分析方法提取特征,并训练二分分类器,对待分类的静息态功能磁共振数据提取对应的特征向量并输入训练好的二分分类器,得到对医学影像图像分类结果。与现有方法相比,本发明的分类准确率、敏感性和特异性更好。附图说明图1是具体实施方式中,本发明的处理流程图;图2是具体实施方式中,提取网络特征的流程图;图3是本发明与最小冗余最大相关算法、费舍尔算法和基于平稳选择的线性回归特征选择算法在滤波频段为(0.01-0.027hz)的分类结果对比图;图4是本发明与最小冗余最大相关算法、费舍尔算法和基于平稳选择的线性回归特征选择算法在滤波频段为(0.027-0.08hz)的分类结果对比图;图5是本发明与最小冗余最大相关算法、费舍尔算法和基于平稳选择的线性回归特征选择算法在滤波频段为(0.01-0.08hz)的分类结果对比图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。参见图1,本发明的基于脑功能网络特征对早晚期轻度认知障碍的分类方法的具体步骤如下:步骤一:采集数据和数据预处理:本具体实施方式中,采用adni(alzheimer'sdiseaseneuroimaginginitiative)数据集中的mci数据。数据收集标准为:被试以adni的样本标记作为实验数据的划分标准。简易智能精神状态量表(mmse)评分在24-30之间,痴呆评定量表(cdr)得分为0.5,有记忆和认知功能上的损伤但并未符合痴呆标准。根据标准,本具体实施方式中共包括33名emci和29名lmci被试(年龄、性别和mmse得分均无显著性差异)。利用dparsf软件对数据集进行预处理,滤波阶段包括三个频段:full-band(0.01-0.08hz)、slow-5(0.01-0.027hz)、slow-4(0.027-0.08hz)。步骤二:构建脑功能网络和提取脑网络特征:201:对预处理得到的三个频段的数据利用aal(anatomicalautomaticlabeling)模板提取90个脑区的时间序列,计算任意两个脑区平均时间序列之间的皮尔逊相关系数,构建所有样本的脑网络w=(rij)90×90×62。采用稀疏度cost=15%的阈值法对w进行二值化,得二值化矩阵wcost=(bij)90×90×62。202:基于脑网络节点间的连通性,提取每个训练样本的脑网络特征集合{k,b,l};步骤三:特征提取:301:将三类网络特征进行随机组合,对每一种数据组合模式采用逐步判别法进行特征选择,并记录每一个组合所选择的特征标号。例如,逐步分析方法采用spss22.0中smallestfratio法,标准为使用f的概率。为了最大限度地保证特征的特异性和避免特征冗余,取值fa=0.1、fb=0.2。当变量使得两组计算f概率大于0.2时,变量加入模型,f概率小于0.1时,变量移除模型,记录模型中加入的变量作为本次组合所选的特征。302:分别对7种组合模式采用逐步分析方法,统计出7种组合中出现频率最大的前15个特征作为最后用于分类的特征集合。步骤四:分类预测:401;随机打乱样本,选取90%的样本作为训练集,剩余10%作为测试集,并分别对其进行归一化处理,映射公式如下:402:利用libsvm(用来实现支持向量机svm的基础功能)工具箱进行分类训练与测试,采用10折交叉验证选择惩罚参数c和核函数参数g。利用得到的最佳参数和svm进行训练与分类预测,并记录预测结果。重复打乱样本,执行参数寻优和训练预测300次,获取平均分类准确率、敏感性和特异性。为了验证本发明方法的性能,将本发明方法(本方法)与最小冗余最大相关算法(mrmr)、费舍尔算法(fs)和基于平稳选择的线性回归特征选择算法(ss-lr)得出的结果进行了对比。另外三种方法均是提取相同的功能网络参数,选取15个网络特征,用10折交叉验证法选择最佳惩罚参数c和核函数参数g,最后用svm进行分类预测,对比结果如图3、4和5所示,其中各柱状图中的准确率、敏感性和特异性的值分别如表1(滤波频段为(0.01-0.027hz))、2(滤波频段为(0.027-0.08hz))和3(滤波频段为(0.01-0.08hz))所示:表1方法准确率(标准差)敏感性(标准差)特异性(标准差)本方法83.72%(0.1475)83.71%(0.2409)85.01%(0.2110)mrmr71.17%(0.1714)64.13%(0.3079)77.98%(0.2625)ss-lr72.94%(0.1668)67.62%(0.3029)78.96%(0.2549)fs60.28%(0.1922)52.82%(0.3267)74.32%(0.2887)表2方法准确率(标准差)敏感性(标准差)特异性(标准差)本方法81.61%(0.1575)87.08%(0.2127)77.77%(0.2537)mrmr67.33%(0.1757)61.83%(0.3120)76.40%(0.2614)ss-lr68%(0.1920)60.57%(0.3311)75.47%(0.2704)fs57.94%(0.2075)53.74%(0.3421)66.93%(0.3086)表3方法准确率(标准差)敏感性(标准差)特异性(标准差)本方法77.83%(0.1634)73.93%(0.2638)83.31%(0.2292)mrmr65.72%(0.1881)58.79%(0.3100)76.71%(0.2692)ss-lr72.83%(0.1876)68.71%(0.2972)77.18%(0.2539)fs54.06%(0.2062)50.04%(0.3523)65.06%(0.3112)综上可知,在相同数目特征数下,本方法能取得更好的分类效果。以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1