基于隶属关系的数据系统及方法与流程
本发明涉及计算机技术领域,特别涉及一种基于隶属关系的数据系统及方法。
背景技术:
车联网业务拓展和个性化服务对数据库负载造成了巨大压力,以redis为代表的nosql数据库很好的解决了负载问题。但与此同时,redis数据结构并不支持隶属关系,各个数据之间无法判断相互关系,因此各个数据只能单独查询。如在单位车辆查询业务中,要显示某部门及其下属部门车辆状态数据,现有技术中,存储方案有如下两种方式:
第一,将该部门所属车辆状态数据以及下属部门所属车辆状态数据存储在该部门的哈希表或者集合中,查询时读取。此种存储方式在查询时拥有良好的响应能力,但实际上,造成了数据的重复存储,浪费大量存储空间。
第二,将各个部门所属车辆状态数据存储在各个部门的哈希表或集合中,查询时,首先确定该部门的下属部门,然后分别查询该部门所属车辆状态数据以及下属部门所属车辆状态数据,将结果汇总。此种存储方式不需要重复存储,但在进行查询操作时需要分别查询存在隶属关系的各个部门所属车辆状态数据,增加了查询时间和使用者的工作量。
技术实现要素:
针对现有技术中的缺陷,本发明提供一种基于隶属关系的数据系统及方法,用于有效处理隶属关系数据,既不会造成数据的重复存储,同时拥有良好的响应能力。
第一方面,本发明提供一种基于隶属关系的数据系统,包括关系数据单元、存储数据单元、代理单元,
所述关系数据单元,用于存储至少两个关键词以及所述至少两个关键词的隶属关系;
所述存储数据单元,用于存储所述关系数据单元中的每个关键词以及所述每个关键词对应的直属数据;
所述代理单元,用于根据接收的检索关键词,获取所述检索关键词的下属关键词,并通过所述存储数据单元获取所述检索关键词的直属数据及所述下属关键词的直属数据;
其中,所述检索关键词为所述关系数据单元中的一个关键词。
优选地,所述关系数据单元中的每个关键词和其下属关键词通过集合set结构存储。
优选地,所述每个关键词和所述每个关键词对应的直属数据通过键值对keyvalue结构存储。
优选地,所述键值对key-value结构存储为哈希表hash。
优选地,所述集合set或所述哈希表hash为redis数据结构。
第二方面,本发明提供一种处理隶属关系数据的方法,包括数据读取阶段,所述数据读取阶段包括以下步骤:
接收客户端发送的检索关键词,所述检索关键词为关系数据单元中的一个关键词;
根据所述检索关键词获取的关键词,获取该关键词的每个下属关键词;
根据所述关键词和所述每个下属关键词,获取该关键词的直属数据和所述每个下属关键词的直属数据。
优选地,所述数据读取阶段之前,还包括数据写入阶段,所述数据写入阶段包括以下步骤:
接收客户端发送的至少两个关键词,以及每个关键词对应的直属数据,所述至少两个关键词存在隶属关系;
将所述关键词和其对应的下属关键词存储至关系数据单元,将每个关键词和其对应的直属数据存储至存储数据单元;
读取代理单元的配置信息,根据所述配置信息建立关系数据单元、数据存储单元的连接。
优选地,所述数据写入阶段之前,还包括初始化阶段,所述初始化阶段包括初始化代理单元、关系数据单元、存储数据单元以及数据库集群连接。
优选地,所述数据读取阶段之后,还包括数据显示阶段,所述数据显示阶段包括以下步骤:
显示依据检索关键词获取的关键词的直属数据以及该关键词的每个下属关键词的直属数据。
由上述技术方案可知,本发明提供一种基于隶属关系的数据系统及方法,通过关系数据单元存储至少两个关键词以及所述至少两个关键词的隶属关系,通过存储数据单元存储每个关键词以及所述每个关键词对应的直属数据,并通过代理单元存储的配置信息建立关系数据单元、存储数据单元的连接,实现对隶属关系数据的有效处理。对于整个的数据处理过程来说,一方面,既不会造成数据的重复存储,节省存储空间,另一方面,又拥有良好的响应能力和易于扩展的特性。与此同时,操作简便,不需要分别查询,减少使用者的工作量。
附图说明
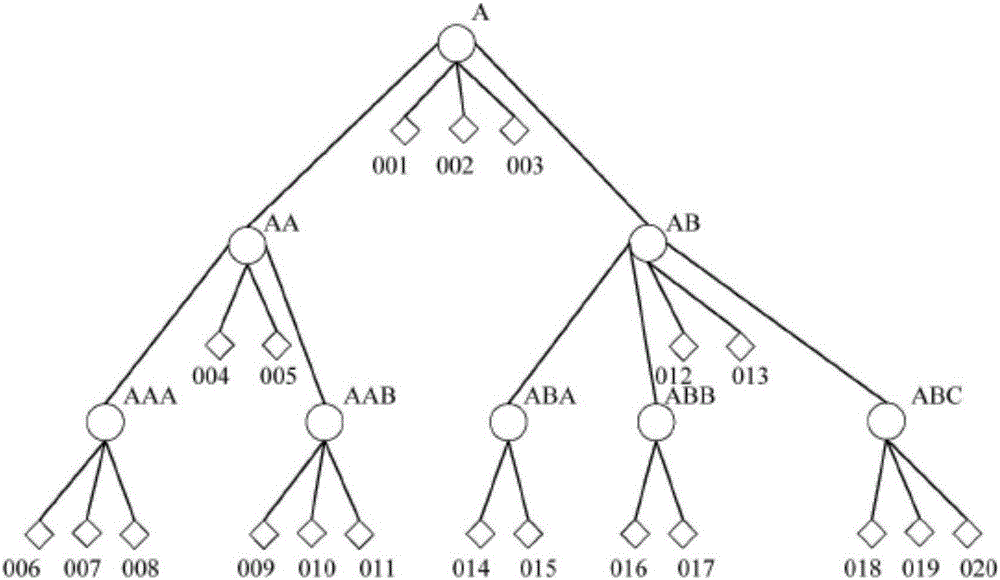
图1为本发明一实施例关键词的隶属关系示意图;
图2为本发明一实施例处理隶属关系数据系统的结构示意图;
图3为本发明另一实施例处理隶属关系数据系统的结构示意图;
图4为本发明一实施例处理隶属关系数据方法的流程示意图;
图5为本发明另一实施例处理隶属关系数据方法的流程示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
图2为本发明一实施例提供的处理隶属关系数据系统的结构示意图,如图2所示,本实施例中的处理隶属关系数据系统20包括关系数据单元21、存储数据单元22、代理单元23,
关系数据单元21,用于存储至少两个关键词以及所述至少两个关键词的隶属关系;
存储数据单元22,用于存储所述关系数据单元21中的每个关键词以及所述每个关键词对应的直属数据;
代理单元23,用于根据接收的检索关键词,获取所述检索关键词的下属关键词,并通过所述存储数据单元22获取所述检索关键词的直属数据及所述下属关键词的直属数据;
其中,所述检索关键词为关系数据单元中的一个关键词。
可理解的是,隶属关系是指在类目表中下位类带有上位类的属性,上位类包含它所属的各级下位类。在本实施例中,关键词存在隶属关系是指关键词之间存在直接或间接从属的关系。除了顶层关键词以外,每个关键词存在直接上属关键词,除了底层关键词外,每个关键词存在直接下属关键词。
举例来说,如图1所示,关键词a为顶层关键词,关键词aaa、aab、aba、abb和abc为底层关键词。关键词a的直接下属关键词是关键词aa、ab,关键词aa、ab的直接上属关键词是关键词a。
图3为本发明另一实施例提供的处理隶属关系数据系统的结构示意图,如图3所示,本实施例中的处理隶属关系数据系统30包括关系数据库redis31、存储数据库redis32、代理单元33,
关系数据库redis31,用于存储至少两个关键词以及所述至少两个关键词的隶属关系;
存储数据库redis32,用于存储所述关系数据库redis31中的每个关键词以及所述每个关键词对应的直属数据;
代理单元33,用于根据接收的检索关键词,获取所述检索关键词的下属关键词,并通过所述存储数据库redis32获取所述检索关键词的直属数据及所述下属关键词的直属数据;
其中,所述检索关键词为关系数据单元中的一个关键词。
在具体实现过程中,可以理解的是,关系数据库redis31,用于存储至少两个关键词以及所述至少两个关键词的隶属关系,由于每个关键词和其对应的下属关键词存在唯一对应关系,为了方便存储与读取,关系数据库redis31中的关键词和其对应的下属关键词通过集合set结构存储。
优选地,为了拥有良好的响应能力,所述集合set结构存储为redis数据结构。
可以理解的是,关键词对应的下属关键词包括该关键词的直接下属关键词和间接下属关键词。直接下属关键词是具有直接从属关系的下属关键词,间接下属关键词是具有间接从属关系的下属关键词。
举例来说,如图1所示,关键词a的直接下属关键词是关键词aa、ab,关键词a的间接下属关键词是关键词aaa、aab、aba、abb和abc。关键词a的下属关键词是aa、aaa、aab、ab、aba、abb和abc,通过集合set存储于redis缓存系统,通过关键词a可以获取对应的下属关键词aa、ab、aaa、aab、aba、abb、abc。
在具体实现过程中,可以理解的是,存储数据库redis32,用于存储每个关键词以及所述每个关键词对应的直属数据,由于每个关键词和其对应的直属数据存在唯一对应关系,为了方便存储与读取,关键词和其对应的直属数据通过键值对key-value结构存储。
优选地,为了拥有良好的响应能力,所述键值对key-value结构存储为redis数据结构,存储类型为哈希表hash。
在具体实现过程中,可以理解的是,代理单元33,用于根据接收的检索关键词,获取所述检索关键词的下属关键词,并通过所述存储数据单元获取所述检索关键词的直属数据及所述下属关键词的直属数据;
其中,所述检索关键词为关系数据单元中的一个关键词。
举例来说,如图1所示,如果检索关键词为a,通过关系数据库redis31,获取关键词a的下属关键词aa、aaa、aab、ab、aba、abb、abc;根据关键词a以及关键词a的下属关键词,通过存储数据库redis32,分别获取关键词a、aa、aaa、aab、ab、aba、abb、abc的直属数据。
对于整个的数据处理过程来说,一方面,既不会造成数据的重复存储,节省存储空间,另一方面,又拥有良好的响应能力和易于扩展的特性。与此同时,操作简便,不需要分别查询,减少使用者的工作量。
图4示出了本发明一实施例提供的处理隶属关系数据方法的流程示意图,如图4所示,本实施例的处理隶属关系数据方法如下所述。
s41、接收客户端发送的检索关键词。
可以理解的是,客户端是指使用所述处理隶属关系数据的方法,发送检索关键词进行检索的一方。检索关键词为关系数据单元的一个关键词。
举例来说,如图1所示,关系数据单元中包含关键词a,aa,aaa,aab,ab,aba,abb,abc,检索关键词可以是上述关键词中的任何一个。
s42、根据所述检索关键词获取的关键词,获取该关键词的每个下属关键词。
可以理解的是,检索关键词为关系数据单元的一个关键词,由于关键词和其对应的下属关键词通过集合set存储,由此,根据一个关键词可以得到该关键词对应的下属关键词。
举例来说,如图1所示,如果检索关键词为a,a是关系数据单元中的一个关键词,由于关键词和其对应的下属关键词通过集合set存储,获取关键词a对应的下属关键词,即关键词aa、aaa、aab、ab、aba、abb和abc。
s43、根据所述关键词和所述每个下属关键词,获取该关键词的直属数据和所述每个下属关键词的直属数据。
举例来说,如图1所示,如果检索关键词为a,获取关键词a的下属关键词aa、ab、aaa、aab、aba、abb和abc,进一步,由于关键词和其对应的直属数据通过键值对哈希表hash存储,分别获取关键词a以及下属关键词aa、ab、aaa、aab、aba、abb和abc的直属数据。
对于整个的数据处理过程来说,一方面,既不会造成数据的重复存储,节省存储空间,另一方面,又拥有良好的响应能力和易于扩展的特性。与此同时,操作简便,不需要分别查询,减少使用者的工作量。
图5示出了本发明另一实施例提供的处理隶属关系数据方法的流程示意图,如图5所示,本实施例的处理隶属关系数据方法如下所述。s50、初始化阶段:
可以理解的是,初始化阶段包括初始化代理单元、关系数据单元、存储数据单元以及数据库集群连接。
s51、数据写入阶段:
s511、接收客户端发送的至少两个关键词,以及每个关键词对应的直属数据。
可以理解的是,所述至少两个关键词存在隶属关系。
s512、将所述关键词和其对应的下属关键词存储至关系数据单元,将每个关键词和其对应的直属数据存储至存储数据单元。
优选地,将所述关键词和其下属关键词通过集合set存储至关系数据单元,将每个关键词和其对应的直属数据通过哈希表hash存储至存储数据单元。
s513、读取代理单元的配置信息,根据所述配置信息建立关系数据单元、数据存储单元的连接。
可以理解的是,代理单元,用于根据接收的检索关键词,获取所述检索关键词的下属关键词,并通过所述存储数据单元获取所述检索关键词的直属数据及所述下属关键词的直属数据;
其中,所述检索关键词为关系数据单元中的一个关键词。
进一步,所述配置信息为根据接收的检索关键词,获取所述检索关键词的下属关键词,并通过所述存储数据单元获取所述检索关键词的直属数据及所述下属关键词的直属数据的指令。
s52、数据读取阶段:
本实施例的处理隶属关系数据的方法,数据读取阶段如图4所示方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
s53、数据显示阶段:
显示依据检索关键词获取的关键词的直属数据以及该关键词的每个下属关键词的直属数据。
对于整个的数据处理过程来说,一方面,既不会造成数据的重复存储,节省存储空间,另一方面,又拥有良好的响应能力和易于扩展的特性。与此同时,操作简便,不需要分别查询,减少使用者的工作量。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!