一种基于深度学习的单帧图像三维重建装置及方法与流程
本发明涉及单帧图像三维重建的装置,关键是一种基于深度学习的单帧图像三维重建方法,属于单帧图像三维重建领域
背景技术:
三维重建是指将真实场景中的三维物体在计算机中建立数学模型的过程,是计算机视觉领域的一个热门研究方向。相比于二维图像,三维模型能够提供物体的深度数据,从而能够更加全面的展示物体特性,因而在计算机动画、人机交互、现代医学等多个领域都有着广泛的应用。
但是多数的三维重建算法都为多帧图像三维重建,在实际的应用中,多帧图像的局限性很大,无法实时三维重建,无法对动态非刚性物体三维重建。然而对于传统的单帧重建方法,精确度不高,表面细节无法重建,很难应用于高精度需求的场景。先前的基于深度学习的三维重建算法,无法实现单帧,精度差,对颜色鲁棒性差,无法三维重建出表面有多种颜色的物体。
技术实现要素:
为了实现单帧图像三维重建,本发明提供实现单帧图像三维重建的集成装置及方法。依靠本发明提供的装置及方法,可以对单帧图像三维重建,可实现高精度,表面重建细节丰富,对颜色具有鲁棒性的三维表面模型。
基于深度学习的单帧图像三维重建装置,包括上位机,其特征在于还包括一个支撑框架,支撑框架顶部设有一个高清相机,围绕高清相机设有三个平行光led面光源,高清相机与各个平行光led面光源位于同一水平面,三个平行光led面光源至高清相机的距离相等,每个平行光led面光源与高清相机及其邻近的平行光led面光源呈120度夹角,三个平行光led面光源分别为白红、白绿、白蓝光源;所述高清相机与所述上位机相连。
所述的基于深度学习的单帧图像三维重建装置,其特征在于所述支撑框架为一个圆柱体形框架,其顶部中心固定一个高清相机,在圆柱框架顶部每隔120度装有一个平行光led面光源
所有设备均与设备控制器相连,可以单独控制开关。
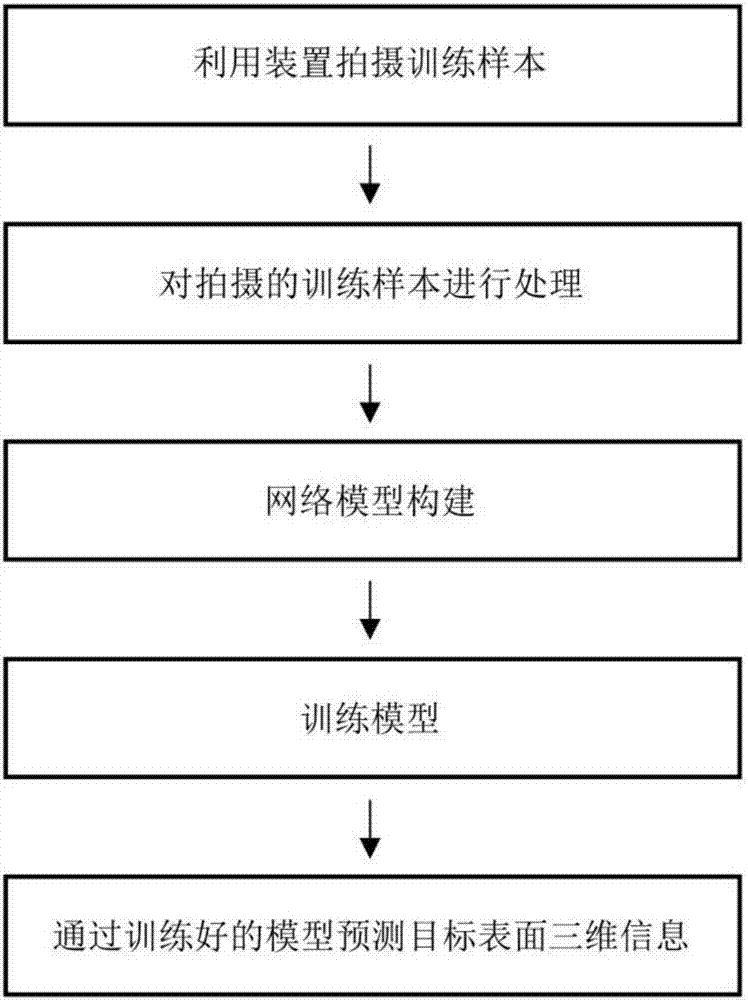
基于深度学习的单帧图像三维重建方法,其特征在于包括以下步骤:
1)将待拍摄物体放置在高清相机正下方,在与高清相机同一水平面上,围绕高清相机设置三个平行光led面光源,每个平行光led面光源至高清相机的距离相等,每个平行光led面光源与高清相机及其邻近的平行光led面光源呈120度夹角,三个平行光led面光源分别为白红、白绿、白蓝光源;
2)利用高清相机和平行光led面光源拍摄n组训练样本,对于每一组训练样本,都包含一张红绿蓝灯同时照射下的物体图像和三个白灯依次开启的状态下拍摄的三张物体图像;拍摄时,保持物体静止,每拍摄一组训练样本,将物体旋转1-10度再进行下一组训练样本的拍摄,待第一种待拍摄物体旋转完一圈后,更换一下一种物体;n为不低于100的自然数;
3)对所拍摄图像进行预处理:对于上步获得得每组训练样本,取其中心m×m像素大小的图像块;将截取后的白光依次照射下的三张图像取灰度值,转变为单通道图像;所述m取值100-600;
对以上处理后的图像进行归一化操作,将红绿蓝光同时照射下得图像的每一通道像素值范围由0到255归一化至0到1,成为m×m×3大小的矩阵;将白光依次照射下的三张单通道灰度图像的像素值由0到255归一化至0到1,将归一化后三张白光依次照射下的图像数据在第三维上拼接,成为m×m×3大小的矩阵;将以上两个矩阵数据重塑成两个m2×3大小的矩阵y和w;
对所有训练样本做同样处理操作,并将所有样本处理后所得的y和w在第一维上拼接,如果有n个训练样本组,那么拼接后得到的矩阵yz和wz的大小为(nm2)×3,yz作为训练模型所需的输入数据wz作为训练模型所需的真值;
4)利用深度学习的方法,根据输入的数据,构建一个适用于单帧图像三维重建的逐像素的全连接网络模型:
全连接网络的结构模型由11个层组成,包括输入层,输出层,和9个隐藏层,每一层都囊括需要训练的权值参数;输入层为矩阵yz一行的3个值,输出层为矩阵wz中对应行的3个值,输入层中的输出节点数量为2048;隐藏层1的输入节点数量为2048,输出节点数量为2045;隐藏层2至隐藏层8的输入节点数量均为2045,输出节点数量为2048;隐藏层9的输入节点数量为2048,输出节点数量为3;输出层的输入节点数量为3;在隐藏层2至隐藏层8中,重复加入了与输入层相同的数据,以减少输出层数据的过度融合并防止训练时的退化和梯度消失;
5)训练模型,初始化网络参数,利用反向传播算法不断调整优化网络参数:
通过计算相对偏差rel作为损失函数,利用损失量最小化来控制训练过程,并使其在恰当的时刻停止训练,以达到最优效果,选择当相对偏差rel小于2%时,即认为训练已经达到最有效果;
上述损失函数的计算公式为:
其中,n表示每次训练批量(batchsize)的大小,
6)预测目标表面三维信息:将训练好的模型参数保存,并输入预测样本组数据,预测样本同样由步骤1、2的方式进行拍摄,使用同样的图像预处理步骤,将一张红绿蓝灯同时照射下的物体图像处理为m2×3的矩阵数据;经过训练好的网络的预测,输出同样m2×3大小的矩阵数据;
通过matlab软件,将预测的m2×3的矩阵数据reshape为m×m×3大小的矩阵数据,并在第三维上拆分为预测好的三张白色灯光照射下的归一化灰度图像;
7)将三张归一化的灰度图像通过光度立体方法,求得目标表面法向,再依据积分算法得出目标表面三维信息,从而完成基于深度学习的单帧图像三维重建。
采用上述字数方案后,本发明与背景技术相比,具有如下优点:
1、本发明将深度学习算法应用于单帧图像三维重建,通过改进网络的结构,构建适用于单帧图像三维重建的网络模型,解决了单帧图像高精度三维重建问题,相比于多帧图像三维重建,应用场景将大大增加。
2、本发明基于深度学习的单帧图像三维重建方法,提高了先前单帧图像三维重建的精度及准确度,丰富了待重建物体表面的细节特征,并且本发明的方法对颜色具有鲁棒性,可应用于多种颜色的物体表面。
附图说明
图1是装置图
图2是方法流程图
图3是网络模型结构图
其中,1、支撑框架,2、高清相机,3、平行光led面光源。
具体实施方式
基于深度学习的单帧图像三维重建装置,包括上位机,其特征在于还包括一个支撑框架1,支撑框架顶部设有一个高清相机2,围绕高清相机2设有三个平行光led面光源3,高清相机2与各个平行光led面光源3位于同一水平面,三个平行光led面光源3至高清相机2的距离相等,每个平行光led面光源3与高清相机2及其邻近的平行光led面光源3呈120度夹角,三个平行光led面光源3分别为白红、白绿、白蓝光源;所述高清相机2与所述上位机相连。
如图1,所述的基于深度学习的单帧图像三维重建装置,其特征在于所述支撑框架1为一个圆柱体形框架,其顶部中心固定一个高清相机2,在圆柱框架顶部每隔120度装有一个平行光led面光源3。支撑框架1为高度1.5m,直径1.5m的圆柱体,将高清相机2固定在顶部中心处的相机固定装置上,相机连接在上位机上,由上位机控制。调节灯照射方向,将照射方向朝向圆环中心相机位置正下方,且将灯光照射方向的slant角调为26.5度。
三个平行光led面光源灯的直径约为12cm,功率为7w,表面为磨砂玻璃,所有灯连可单独控制,设备控制器中安装有变压器,可将电压转为12v直流电压,供设备使用。相机与灯组位于同一平面。
利用本发明装置实现基于深度学习的单帧图像三维重建方法实例中,操作步骤如下:
1、利用本发明装置拍摄300组训练样本,对于每一组训练样本,都包含一张红绿蓝灯同时照射下的物体图像和三个白灯依次开启的状态下拍摄的三张物体图像,在拍摄时,需要保证物体保持静止,表面没有发生变化。将待拍摄的物体放置在相机下方框架底面,使三个灯能均匀照射。每拍摄一组训练样本,将物体旋转5度再进行下一组训练样本的拍摄,待一种物体旋转完一圈后,更换一下一种物体。这样用圆旋转的方法可以拍摄尽可能多的得到每一种物体的表面法向在红绿蓝灯和白灯下的图像。
2、对所拍设的图像进行预处理。对于上步获得得每组训练样本,取其中心400×400像素大小的图像块。进一步地,将截取后得白光依次照射下的三张图像取灰度值,转变为单通道图像。
对以上处理后的图像进行归一化操作,将红绿蓝光同时照射下得图像的每一通道像素值范围由0到255归一化至0到1,成为400×400×3大小的矩阵。将白光依次照射下的三张单通道灰度图像的像素值由0到255归一化至0到1,将归一化后三张白光依次照射下的图像数据在第三维上拼接,成为400×400×3大小的矩阵。在matlab种通过reshape命令将以上两个矩阵数据重塑成两个160000×3大小的矩阵y和w。
对所有训练样本做同样处理操作。并将所有样本处理后所得的y和w在第一维上拼接,如果有a个训练样本组。那么,拼接后得到的矩阵yz和wz的大小为160000a×3,即160000×300×3个,yz作为训练模型所需的输入数据wz作为训练模型所需的真值。
3、网络模型的构建。利用深度学习的方法,根据输入的数据,构建一个适用于单帧图像三维重建的逐像素的全连接网络模型。模型结构参阅图3。全连接网络的结构模型由11个层组成,包括输入层,输出层,和9个隐藏层,每一层都囊括需要训练的权值参数。输入层为矩阵yz一行的3个值,输出层为矩阵wz中对应行的3个值。输入层中的输出节点数量为2048;隐藏层1的输入节点数量为2048,输出节点数量为2045;隐藏层2至隐藏层8的输入节点数量均为2045,输出节点数量为2048;隐藏层9的输入节点数量为2048,输出节点数量为3;输出层的输入节点数量为3。在隐藏层2至隐藏层8中,重复加入了与输入层数据,这样做有以下几个原因:第一,重复加入输入层数据可以减少输出层数据的过度融合;第二,重复加入输入层数据可以在一定程度上防止训练时的梯度消失问题。在每一层中,都将权值输入sigmoid激活函数进行处理。
4、训练模型,初始化网络参数,利用反向传播算法不断调整优化网络参数。在训练时,网络不断重复反向调整,需要一个尊则来衡量当前训练情况下的误差,在本发明方法中,通过计算相对偏差rel作为损失函数,利用损失量最小化来控制训练过程,并使其在恰当的时刻停止训练,以达到最优效果。在本实施例中,当相对偏差rel小于2%时,即认为训练已经达到最有效果。
上述损失函数的计算公式为:
其中,n表示每次训练的批量大小,
5、预测目标表面三维信息,将训练好的模型参数保存,并输入预测样本组数据。预测样本同样由本发明装置进行拍摄,使用同样的图像预处理步骤,将一张红绿蓝灯同时照射下的物体图像处理为160000×3的矩阵数据。经过训练好的网络的预测,输出同样160000×3大小的矩阵数据。通过matlab软件,将预测的160000×3的矩阵数据reshape为400×400×3大小的矩阵数据。并在第三维上拆分为预测好的三张白色灯光照射下的归一化灰度图像。
最后,将三张归一化的灰度图像通过光度立体方法,求得目标表面法向,再依据积分算法得出目标表面三维信息,从而完成基于深度学习的单帧图像三维重建的方法。
- 还没有人留言评论。精彩留言会获得点赞!