一种合同文本风险检测方法、装置、设备及存储介质与流程
本发明涉及自然语言处理和语义计算等领域,特别涉及一种合同文本风险检测方法、装置、设备及存储介质。
背景技术:
近年来,随着合同文本的规范化以及自然语言处理的进步,一些公司利用自然语言技术对商业合同进行自动解析,其中商业合同的部分基础工作可以通过机器预先处理,从而减少人力,提高效率。
现有技术主要通过人工或半自动方式选择一些特定词语或短语作为特征,然后利用预设规则或机器学习算法对合同文本进行解析,从而完成文书解析裁判的工作。
对于该类方案,需要人工提取特征词语,以及用预设规则来完成法律文书的检测,或者通过计算两个法律文书的关键词的相似度来计算两个文书之间的相似度。
由于中文表达的多样性特点,上述方案无法对合同文本进行准确地解析和风险判决。
技术实现要素:
本发明实施例提供的一种合同文本风险检测方法、装置、设备及存储介质,解决合同文本解析和风险判决不准确的问题。
根据本发明实施例提供的一种合同文本风险检测方法,包括:
根据待检测的合同文本所属商业领域,获取所述商业领域对应的条款分类模型;
利用所述条款分类模型,对所述合同文本的条款进行分类,得到所述合同文本的条款文本及对应的条款类型;
对每个所述条款类型的条款文本进行风险评估,确定每个所述条款类型的条款文本的风险程度。
优选地,还包括:
在根据待检测的合同文本所属商业领域,获取所述商业领域对应的条款分类模型之前,构建用于对合同文本的条款进行分类的条款分类模型;
利用所述商业领域的训练合同文本,对所构建的条款分类模型进行训练,得到性能优化的条款分类模型。
优选地,所述利用所述商业领域的训练合同文本,对所构建的条款分类模型进行训练,得到性能优化的条款分类模型包括:
对所述训练合同文本的条款进行分类,得到所述训练合同文本的条款文本及对应的条款类型;
对所述训练合同文本的条款文本进行分词处理,得到组成所述训练合同文本的条款文本的词语;
利用所述词语的词向量及对应的条款类型,对所述条款分类模型的参数进行调整,得到性能优化的条款分类模型。
优选地,还包括:
在利用所述条款分类模型,对所述合同文本的条款进行分类之后,若每个预设条款类型均有对应的条款文本,则确定所述合同文本完备。
优选地,所述对每个所述条款类型的条款文本进行风险评估,确定每个所述条款类型的条款文本的风险程度包括:
利用语义匹配模型,将每个所述条款类型的条款文本与所述条款类型的条款样本进行相似比对,得到条款文本相似度;
根据所述条款文本相似度与预设风险阈值,对所述合同文本进行风险评估,得到每个所述条款类型的条款文本的风险程度。
优选地,所述利用语义匹配模型,将每个所述条款类型的条款文本与所述条款类型的条款样本进行相似比对,得到条款文本相似度包括:
从样本数据库中获取所述条款类型对应的多个条款样本;
利用所述语义匹配模型,将组成所述条款文本的词语的词向量分别与组成每个所述条款样本的词语的词向量进行相似比对,得到所述条款文本与每个所述条款样本的相似度,并将最大相似度确定为所述条款类型的条款文本相似度。
优选地,还包括:
在确定每个所述条款类型的条款文本的风险程度之后,将每个所述条款类型的条款文本作为新样本,保存至所述样本数据库;
利用所述样本数据库的所述新样本,更新所述条款分类模块和所述语义匹配模型。
根据本发明实施例提供的一种合同文本风险检测装置,包括:
模型获取模块,用于根据待检测的合同文本所属商业领域,获取所述商业领域对应的条款分类模型;
条款分类模块,用于利用所述条款分类模型,对所述合同文本的条款进行分类,得到所述合同文本的条款文本及对应的条款类型;
风险评估模块,用于对每个所述条款类型的条款文本进行风险评估,确定每个所述条款类型的条款文本的风险程度。
根据本发明实施例提供的一种合同文本风险检测设备,包括:处理器,以及与所述处理器耦接的存储器;所述存储器上存储有可在所述处理器上运行的合同文本风险检测程序,所述合同文本风险检测程序被所述处理器执行时实现上述的合同文本风险检测方法的步骤。
根据本发明实施例提供的存储介质,其上存储有合同文本风险检测程序,所述合同文本风险检测程序被处理器执行时实现上述的合同文本风险检测方法的步骤。
本发明实施例提供的技术方案具有如下有益效果:
本发明实施例通过基于大量合同文本训练得到的分类模块和深度语义匹配模型,实现对待检测合同文本的风险检测,对客户进行风险提醒,不需要提取特定词语或短语以及人工设定规则,提高了合同文本解析和风险判决准确率。
附图说明
图1是本发明实施例提供的合同文本风险检测流程图;
图2是本发明实施例提供的合同文本风险检测装置框图;
图3是本发明实施例提供的合同文本风险检测系统架构图;
图4是本发明实施例提供的完备性检测模块流程图;
图5是本发明实施例提供的风险检测模块流程图;
图6是本发明实施例提供的自学习模块流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行详细说明,应当理解,以下所说明的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
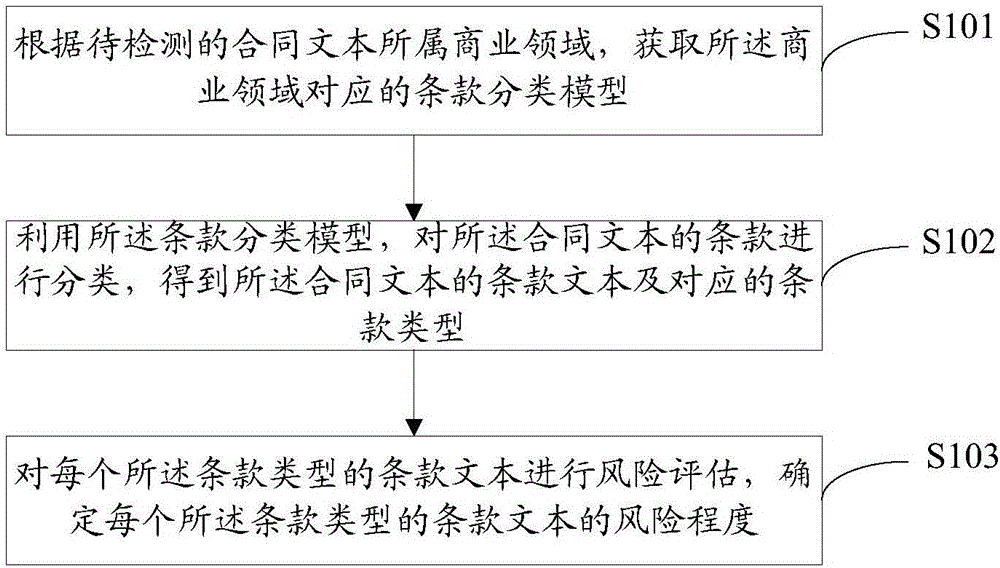
图1是本发明实施例提供的合同文本风险检测流程图,如图1所示,步骤包括:
步骤s101:根据待检测的合同文本所属商业领域,获取所述商业领域对应的条款分类模型。
在步骤s101之前,还包括:构建用于对合同文本的条款进行分类的条款分类模型,利用所述商业领域的训练合同文本,对所构建的条款分类模型进行训练,得到性能优化的条款分类模型。具体训练时,对所述训练合同文本的条款进行分类,得到所述训练合同文本的条款文本及对应的条款类型,对所述训练合同文本的条款文本进行分词处理,得到组成所述训练合同文本的条款文本的词语,利用所述词语的词向量及对应的条款类型,对所述条款分类模型的参数进行调整,得到性能优化的条款分类模型。
步骤s102:利用所述条款分类模型,对所述合同文本的条款进行分类,得到所述合同文本的条款文本及对应的条款类型。
利用步骤s102的分类结果,可以对所述合同文本进行完备性检测,具体地说,若每个预设条款类型均有对应的条款文本,则确定所述合同文本完备。
步骤s103:对每个所述条款类型的条款文本进行风险评估,确定每个所述条款类型的条款文本的风险程度。
步骤s103包括:利用语义匹配模型,将每个所述条款类型的条款文本与所述条款类型的条款样本进行相似比对,得到条款文本相似度,根据所述条款文本相似度与预设风险阈值,对所述合同文本进行风险评估,得到每个所述条款类型的条款文本的风险程度。更具体地,可以从样本数据库中获取所述条款类型对应的多个条款样本,然后利用所述语义匹配模型,将组成所述条款文本的词语的词向量分别与组成每个所述条款样本的词语的词向量进行相似比对,得到所述条款文本与每个所述条款样本的相似度,并将最大相似度确定为所述条款类型的条款文本相似度。
在步骤s103之后,还包括:将每个所述条款类型的条款文本作为新样本,保存至所述样本数据库,以便利用所述样本数据库的所述新样本,更新所述条款分类模块和所述语义匹配模型。
进一步地,在保存样本之前,还可以先根据步骤s103的处理结果,生成风险报告,并发送至客户端,以供客户端的法律人士进行确认鉴定,然后根据客户端的确认鉴定结果,保存样本。
其中,人工鉴定时,确认该合同文本的条款文本是否确实具有高风险度或低风险度。如果确认条款文本具有高风险度或存在风险,则可以将该条款文本作为该条款类型的反例样本,存入样本数据库。如果确认条款文本具有低风险度或不存在风险,则可以将该条款文本作为该条款类型的正例样本,存入样本数据库。一般情况下,在步骤s103中,选取的条款样本可以为正例样本,也可以为反例样本。当选取正例样本时,合同文本的条款文本与正例样本的相似度越高,说明风险越低,反之,当选取反例样本时,合同文本的条款文本与反例样本的相似度越高,说明风险越高。
本发明实施例基于大数据分析,对拟定的合同文本的内容进行风险检测,具体地说,可以对拟定的某一商业领域内的合同文本进行内容检测,实现对拟定的合同文本是否完备以及常规性漏洞的检测,同时通过展示及校验模块进行结果展示及提醒,从而提高合同的可执行性。
本领域普通技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机可读取存储介质中。进一步说,本发明还可以提供一种存储介质,其上存储有合同文本风险检测程序,所述合同文本风险检测程序被处理器执行时实现上述的合同文本风险检测方法的步骤。其中,所述的存储介质可以包括rom/ram、磁碟、光盘、u盘。
图2是本发明实施例提供的合同文本风险检测装置框图,如图2所示,包括:
模型获取模块21,用于根据待检测的合同文本所属商业领域,获取所述商业领域对应的条款分类模型。所述条款分类模型是预先生成的,具体为:首先构建用于对合同文本的条款进行分类的条款分类模型,然后利用所述商业领域的训练合同文本,对所构建的条款分类模型进行训练,得到性能优化的条款分类模型。
条款分类模块22,用于利用所述条款分类模型,对所述合同文本的条款进行分类,得到所述合同文本的条款文本及对应的条款类型。在分类结束后,对所述合同文本进行完备性检测,具体为:若每个预设条款类型均有对应的条款文本,则确定所述合同文本完备。
风险评估模块23,用于对每个所述条款类型的条款文本进行风险评估,确定每个所述条款类型的条款文本的风险程度。具体为:利用语义匹配模型,将每个所述条款类型的条款文本与所述条款类型的条款样本进行相似比对,得到条款文本相似度,根据所述条款文本相似度与预设风险阈值,对所述合同文本进行风险评估,得到每个所述条款类型的条款文本的风险程度。在得到每个所述条款类型的条款文本的风险程度后,还可以将每个所述条款类型的条款文本作为新样本,优化所述条款分类模型和所述语义匹配模型。
本发明实施例提供一种合同文本风险检测设备,包括:处理器,以及与所述处理器耦接的存储器;所述存储器上存储有可在所述处理器上运行的合同文本风险检测程序,所述合同文本风险检测程序被所述处理器执行时实现上述的合同文本风险检测方法的步骤。
图3是本发明实施例提供的合同文本风险检测系统架构图,本发明实施例提供了一种针对领域合同文本内容风险检测的方法及系统,判断合同文本是否完备以及常规性漏洞的检测,同时通过展示模块给予相应的风险提醒。所述系统包括:
文本采集模块31,用于对法律文书的文本采集。该系统支持纸质文书或通过外置存储设备进行文件导入。
文本预处理模块32,用于对采集到的文本进行格式标准化,简繁体转化,大小写转换,符号去除,合并拆分字等处理。
完备性检测模块33,用于检测法律文书在该领域的条款是否完备。
风险检测模块34,用于检测具体条款对当事人是否存在侵害风险,并计算其风险度。
展示及校验模块35,用来展示风险报告,同时用于人工对风险置信度进行评估。
样本数据库36主要用于存放原始训练数据和人工校验后的数据,并且用于完备性检测模型(或条款分类模型)和风险检测模型(或语义匹配模型)的自动更新学习。
所述装置还包括:
自学习模块(图中未标示),用于对原有模型进行更新训练,使其具有更好的泛化性。
所述系统实际是一种基于服务端的大数据分析,并辅以客户端识别的法律文书检测系统。其工作过程为流式流程,具体为:文本采集模块31用于法律文本的采集,对于纸质的法律文书,通过系统自带的ocr(opticalcharacterrecognition,光学字符识别)文字扫描设备采集;对于存储在存储设备中的文档,系统可以直接读取。文本预处理模块32用于对采集到的文本进行预处理,包含以下操作:格式标准化,简繁体转化,大小写转换,非语义符号去除,合并拆分字等。完备性检测模块33用于检测当前输入的领域合同文本是否完备,判断该合同是否缺少该领域的必要的条款。风险检测模块34用于计算在当前类别下条款文本与待比较文本之间的相似度,并根据预设的阈值,进行风险度的评估。展示及校验模块35,除了具有展示风险报告的功能,还提供人工查看校验的作用,并把校验结果自动上传到样本数据库36中。
所述方法包括两部分:
1、服务端
预处理模块32接收到客户端采集的文本,进行预处理,并把处理后的合同文本转发给完备性检测模块33,该模块33通过模型对合同中文本条款进行分类,其中类别是根据不同的商业领域预设的,如果该领域的所有基本类别都有相应的文本条款匹配,则认为当前的合同文本条款满足该领域合同的完备性,否则不满足。然后把所有条款及对应的归属类别标签缓存下来,转发到风险检测模块34,文本风险检测模块34通过语义相似度模型计算该类别下对应条款文本的相似度,并根据预设的风险阈值,来判断其是否存在风险,并生成风险评估报告,并推送到客户端的展示及校验模块35,通过人工的校验再次把文本转发到自学习模块,自学习模块根据新的样本进行自学习更新。
2、客户端
文本采集模块31采集文本,这里包含两种形式:对于纸质的法律文书,通过ocr文字扫描设备采集;对于存储在存储设备中文本文件可以直接读取。然后把采集到的法律文书文本转发到服务端的预处理模块32。
展示及校验模块35接收风险检测模块34生成的报告,并展示给当事人及相关人员,同时把用户反馈的信息转发给自学习模块,用于模型的更新。
本发明实施例基于大量的某一领域合同文本,利用深度学习对合同文本内容进行解析检测。可以对常见特定领域商业合同文本进行解析检测,例如房产买卖合同,其中房屋买卖合同一般包含如下条款内容:买卖双方的个人信息、房屋的属性、履行方式、违约责任、争议的解决方法等方面。基于上述的相关条款内容,利用深度学习训练分类模型,把各条款分类到对应条款的类别中,实现对房屋买卖合同领域的条款类别的完备性解析。然后,在此基础上,利用深度语义匹配模型,计算待检测的合同条款文本与该类别的相关条款文本的相似度,把其相似度与预设的风险阈值进行比较,从而判断条款是否具有风险。最后通过系统的自学习模块,自动更新模型,随着系统样本越来越多,系统会达到自适应,减少人工干预。因此本发明实施例是一种实用,具有自适性的合同文本内容解析检测系统,完全满足工程应用的需求。
图4是本发明实施例提供的完备性检测模块33流程图,如图4所示,该流程包括如下步骤:当完备性检测模块33接收到预处理后的文本,根据训练好的分类模型,对其每条条款文本进行分类,根据分类的结果判断是否所有的类别都有相应的条款文本匹配,如果是则认为当前领域合同文本条款是完备的,否则是不完备的,同时把条款文本及其对应的类别缓存下来,转发到风险检测模块34,进行下一步处理。
词向量训练:
由于词向量是该方案模型必备输入,故需要提前训练好词向量,同时领域的词向量可以复用。词向量可以通过开源的词向量训练工具自动生成,可以对词语的表示具有更深层次的语义性。
首先,对输入的合同文本进行预处理,主要包含:非法字符去除,数字的替换,非重大意义下的数字人名替换等,并把每句作为一行。
其次,对句子进行分词,用空格隔开,每句作为一行。分词可以通过开源的分词工具实现,如:ansj、结巴分词、哈工大的ltp等。
最后,选择适当的参数训练词向量模型。一般情况下词向量为100维就已经能够在分类任务中很好的表达词语的意义了,形式如下:
中国=[0.00570705,0.4275226,-0.62307459,0.01425633,0.02571641,0.85126471,-0.4231756,0.031421404,...0.21345081]
分类模型的算法选择textcnn算法,因为合同文本的条款一般不会太长,且文本分类一般不用考虑长序列语义,故选择该算法。该算法是基于深度学习的,输入为词向量,不需要人为抽取特征,泛化性较好。
本发明实施例通过词语的向量化表示,训练用于度量完备性和相似性的模型。
其中,完备性检测的具体步骤包括:
步骤s401:训练样本准备。
1、预先规定当前领域合同中必备条款类别,把该领域合同条款文本归到对应的类别,形成各个类别的文本串集合。
例如:在房屋买卖领域,合同必要类别一般包含如下内容:买卖双方的信息、房屋属性信息、房屋交易信息、付款方式、履行方式、违约责任、争议的解决方法等。如“乙方同意购买甲方拥有的座落在江苏省南京市雨花区雨花街道拥有的房产(别墅、写字楼、公寓、住宅、厂房、店面),建筑面积为90平方米。(详见土地房屋权证第21070021号)”,显然该条款是归属于房屋属性信息。
2、对第一步获取的文本进行自动化预处理,包含以下操作:格式标准化,简繁体转化,大小写转换,非语义符号去除、合并拆分字等。处理结果如下:
乙方同意购买甲方拥有的座落在江苏省南京市雨花区雨花街道拥有的房产别墅、写字楼、公寓、住宅、厂房、店面,建筑面积为90平方米。详见土地房屋权证第21070021号”
3、对预处理后的文本进行分词处理。
例如:分词结果
乙方/同意/购买/甲方/拥有/的/座落/在/江苏省/南京市/雨花区/雨花街道/拥有/的/房产.......
步骤s402:分类模型训练。
输入为条款文本中每个词语的词向量及类别标签,利用tensorflow构建分类模型textcnn进行训练及参数调整,使其具有最优的性能,并生成最终的分类模型。
步骤s403:通过模型对新的输入合同文本进行检测,如果当前领域的必备类别都有对应的文本匹配,则认为当前合同文本是完备的,否则是不完备的。
步骤s404:保存所述新的输入合同文本及对应的类别。
图5是本发明实施例提供的风险检测模块34流程图,如图5所示,该流程包括如下步骤:风险检测模块34接收到完备性检测模块33传来的文本及其对应类别标签,基于深度文本相似度算法,计算该文本与当前类别下若干标准文本相似度,若最高的相似度大于预设的阈值,则认为该条款是低风险,否则认为该条款是高风险的,给出预警,通过风险报告进行展示。
步骤s501:训练样本准备。
基于完备性检测模块传递过来的已经分好词的合同条款文本及对应类别标签,在每个类别内按比例无放回的随机挑选出若干条款文本作为该类的标准句。
步骤s502至步骤s504:深度语义匹配模型(或文本相似度模型)计算相似度。
这里的模型可以采用改进的dssm算法模型训练,是基于多层神经网络模型搭建的广义语义匹配模型,使用余弦相似度进行计算。输入为待比较的两个句子的词向量,进行模型训练,输出为相似度。对测试样本,分别计算与该类若干标准句的相似度,选取最高的相似度与预设的阈值进行比较,若最高的相似度大于预设的阈值,则认为该条款是低风险,否则认为该条款是高风险的,并生成风险报告。
例如:系统阈值预设为0.9,当最大相似度为0.932,则认为该条款文本是低风险的。
图6是本发明实施例提供的自学习模块流程图,如图6所示,该流程主要步骤为:
步骤s601至步骤s603:展示及校验模块35把生成的风险报告展示给有法律经验的当事人或有法律咨询机构对其确认。
步骤s605、步骤s606:系统会自动把已经确认属性的样本添加到样本数据库36中。例如:如果某领域法律专家对其生成报告进行确认鉴定后,那么系统会自动把报告对应的条款文本添加到样本数据库36中,具体地说,如果条款文本存在风险,则将该条款文本作为该类别的反例样本,如果条款文本不存在风险,则将该条款文本作为改类别的正例样本。随着样本越来越多,多样性越来越完整,系统的性能也会越来越高。
综上所述,本发明实施例根据合同的预设类型,基于大数据分析当前拟定的合同条款是否存在风险,以及对应的条款风险度,方便非法律人士在没有相应法律基础时,确定拟定的合同是否存在风险,从而避免因签订带有风险合同,给权利人带来相应的损失,同时通过客户端直观的展示给用户,提高了服务的友好性。
尽管上文对本发明进行了详细说明,但是本发明不限于此,本技术领域技术人员可以根据本发明的原理进行各种修改。因此,凡按照本发明原理所作的修改,都应当理解为落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!