一种考虑标签信息的贝叶斯个性化排序推荐方法与流程
本发明属于个性化推荐领域,具体说是一种考虑标签信息的贝叶斯个性化排序(tbpr)推荐方法。
背景技术:
推荐系统作为解决“信息过载”的有效工具,已经成为电子商务网站的基本配置。根据使用数据类型不同,可将推荐系统的推荐方法的分为基于显式评分数据的评分预测算法和基于隐式反馈数据的个性化排序算法。显式评分数据主要是通过用户对产品打分的方式产生,而隐式反馈数据则是来源于用户的购买、点击、收藏等,因此隐式反馈数据凭借广泛性、成本低、贴近现实等优点获得了越来越多的关注。
经典的贝叶斯个性化排序算法认为与用户交互过的产品属于正向反馈,用户未交互过的产品属于负项反馈,并且假设用户对交互过的产品的偏好大于未交互过的产品。但在用户的交互记录非常稀少或者没有交互记录时,经典的贝叶斯个性化排序算法不能很好的捕捉用户的产品偏好,导致个性化推荐率不高。然而推荐系统中在实际应用中,用户与产品的交互记录大多比较稀疏,在数据稀疏情形下,如何利用辅助信息提高个性化推荐精度成为个性化推荐研究的热点。
技术实现要素:
本发明为克服现有技术存在不足之处,提出一种考虑标签信息的贝叶斯个性化排序推荐方法,以期能在数据稀疏和冷启用用户的情况下利用标签作为辅助信息,从而提高个性化推荐的准确性。
为达到上述目的,本发明采用的技术方案为:
本发明一种考虑标签信息的贝叶斯个性化排序推荐方法的特点是按照如下步骤进行:
步骤一、定义交互关系集合d表示用户和产品的所有交互关系:
步骤二、基于用户与产品的标签匹配度,利用式(1)获得用户u与未交互产品j的标签匹配度match(u,j),从而获得用户u与所有未交互产品的标签匹配度集合:
式(1)中,
步骤三、定义一个基于标签的用户偏好反馈集合的划分标准;
步骤3.1、基于用户与产品的交互关系集合d,定义用户u的所有交互产品构成用户u的正反馈集合
步骤3.2、设置参数ε,0≤ε≤1;
基于用户u与所述产品集合i中所有未交互产品的标签匹配度{match(u,j)}j=1,2,…,|j|,获得用户u对应的强偏好反馈集合
若满足match(u,j)≥ε,则表示未交互产品j属于用户u的强偏好反馈集合
若满足0<match(u,j)<ε,则表示未交互产品j属于用户u的弱偏好反馈集合
若满足match(u,j)=0,则表示未交互产品j属于用户u的负反馈集合
步骤四、利用式(2)构建用户集合u对产品集合i的矩阵分解模型:
式(2)中,
步骤五、利用贝叶斯个性化排序方法对所述矩阵分解模型进行优化求解,得到所述矩阵分解模型中的各个参数值;
步骤5.1、利用式(3)得到所述矩阵分解模型的目标函数χ:
式(3)中,
步骤5.2、定义外循环变量为α,并初始化α=1;
步骤5.3、利用正态分布随机初始化第α次循环的参数集合θα={wα,hα,bα};利用(0,1)随机初始化第α次循环的正则化参数
步骤5.4、定义内循环变量为β,并初始化β=1;
步骤5.5、在第α次外循环下遍历用户和产品的的交互关系集合d:
步骤5.6、在访问第β个交互关系dβ的过程中第β次随机选取一个用户u,同时从所述用户u对应的正反馈集合
步骤5.7、将用户产品组合
步骤5.8、利用随机梯度下降方法更新目标函数
步骤5.9、令β+1赋值给β,并判断β>|d|是否成立,若成立,则执行步骤5.10;否则,返回步骤5.6;
步骤5.10、判断参数
步骤六、随机选取所述产品集合u中一个用户v,根据式(3)得到所述用户v在所述产品集合i中所有未交互产品的偏好,并对所有未交互产品的偏好进行降序排序,选择前top个产品形成推荐列表推送给所述用户v。
相对于现有的技术相比,本发明的有益效果体现在:
本发明考虑了标签信息对用户偏好的影响,保留了用户与产品的交互信息,与传统协同过滤推荐算法相比在数据非常稀疏和冷启动用户情况下,能取得较好的推荐精度,具体的说:
1、推荐系统中含有大量隐式反馈数据且数据较为稀疏,通过直接预测用户对产品的偏好得分不能准确反映用户个体偏好,从而不能产生较好的推荐效果,而本发明利用排序方法求解矩阵分解模型,排序方法对隐式反馈数据具有良好的适应性,能够有效提高个性化推荐的精度。
2、本发明融合标签信息,利用用户-标签,产品-标签细化用户对未交互的产品的偏好,拓展了传统贝叶斯个性化排序算法的偏好假设,更贴近真实推荐场景,明显提升了预测结果的准确性,提高了推荐效果。
3、本发明可用于图书和家电等实体产品、音乐和视频等数字产品、旅游路线和度假安排等服务产品的个性化推荐系统,可以在电脑和手机的网页和app等平台使用,应用范围广泛。
附图说明
图1为本发明方法的流程图;
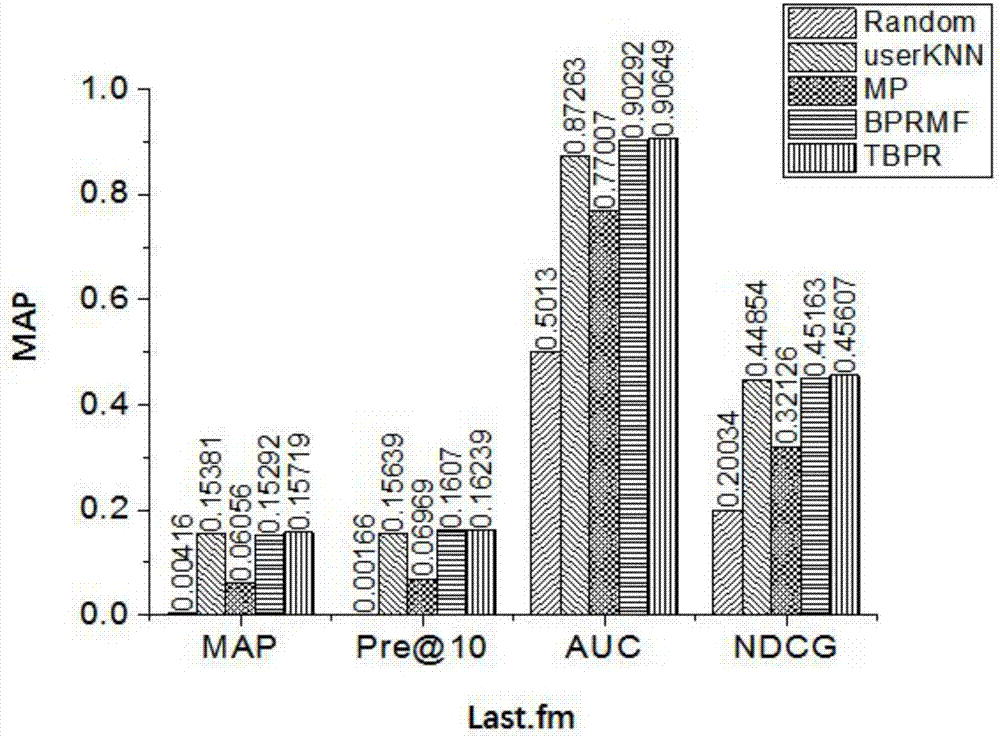
图2为本发明在last.fm数据集上与基准算法的各项推荐指标map、auc、ndcg、pre@10对比图;
图3为本发明在last.fm数据集上与贝叶斯个性化排序算法在对冷启动用户推荐上的效果对比图;
图4为本发明在last.fm数据集上不同稀疏度训练集对个性化推荐的推荐效果的影响图。
具体实施方式
本发明在用户与产品交互的基础上,考虑用户-标签、产品-标签,构造用户与用户对未交互的产品的标签匹配度,从而将用户偏好缺失值部分进行了更细粒度的划分。根据用户的偏好差异,本发明将全部产品划分为正反馈集合、强偏好反馈集合、弱偏好反馈集合、负反馈集合。
如图1所示,本实施例中,一种考虑标签信息的个性化排序算法,按如下步骤进行:
步骤一、定义交互关系集合d表示用户和产品的所有交互关系:
步骤二、用户通过对产品打标签产生标签信息,标签不仅能体现用户兴趣,同时反映产品的特征;基于用户与产品的标签匹配度,利用式(1)获得用户u与未交互产品j的标签匹配度match(u,j),从而获得用户u与所有未交互产品的标签匹配度集合:
式(1)中,
步骤三、定义一个基于标签的用户偏好反馈集合的划分标准;
步骤3.1、基于用户与产品的交互关系集合d,定义用户u的所有交互产品构成用户u的正反馈集合
步骤3.2、设置参数ε,0≤ε≤1;
基于用户u与所述产品集合i中所有未交互产品的标签匹配度{match(u,j)}j=1,2,…,|j|,获得用户u对应的强偏好反馈集合
若满足match(u,j)≥ε,则表示未交互产品j属于用户u的强偏好反馈集合
若满足0<match(u,j)<ε,则表示未交互产品j属于用户u的弱偏好反馈集合
若满足match(u,j)=0,则表示未交互产品j属于用户u的负反馈集合
本发明基于所述用户偏好反馈集合的划分标准做出三组偏序关系假设:用户u对正反馈集合
步骤四、利用式(2)构建用户集合u对产品集合i的矩阵分解模型:
式(2)中,
步骤五、利用贝叶斯个性化排序方法对所述矩阵分解模型进行优化求解,得到所述矩阵分解模型中的各个参数值;
步骤5.1、利用式(6)得到所述矩阵分解模型的目标函数χ:根据贝叶斯个性化排序方法得出矩阵分解模型的学习目标就是最大化式(3)中的后验概率
θ表示所述矩阵分解模型中的参数集合,并有θ={w,h,b},
式(4)中,
综合式(4)、式(5),得到所有用户u∈u的全部参数对数形式后验分布,即矩阵分解模型的最终目标函数χ:
式(6)中,σ(·)表示logistic函数,λθ为正则化参数;match(u,k)值越大,表示用户对产品i与产品k的偏好越接近;match(u,s)值越大,表示用户对产品s与产品j的偏好差异越大;本发明的训练准则是最大化公式(6)中的目标函数;
步骤5.2、定义外循环变量为α,并初始化α=1;
步骤5.3、利用正态分布随机初始化第α次循环的参数集合θα={wα,hα,bα};利用(0,1)随机初始化第α次循环的正则化参数
步骤5.4、定义内循环变量为β,并初始化β=1;
步骤5.5、在第α次外循环下遍历用户和产品的的交互关系集合d:
步骤5.6、在访问第β个交互关系dβ的过程中第β次随机选取一个用户u,同时从所述用户u对应的正反馈集合
步骤5.7、将用户产品组合
步骤5.8、利用随机梯度下降方法更新目标函数
步骤5.9、令β+1赋值给β,并判断β>|d|是否成立,若成立,则执行步骤5.10;否则,返回步骤5.6;
步骤5.10、判断参数
步骤六、随机选取所述产品集合u中一个用户v,根据式(3)得到所述用户v在所述产品集合i中所有未交互产品的偏好,并对所有未交互产品的偏好进行降序排序,选择前top个产品形成推荐列表推送给所述用户v。
针对本发明方法进行实验论证,具体包括:
1)准备标准数据集
本发明使用在推荐领域应用广泛的数据集last.fm数据集作为标准数据集验证本发明提出的个性化推荐方法的性能。last.fm数据集的数据来自last.fm网站,last.fm是一个面向音乐爱好者的在线音乐网站,音乐爱好者可以在last.fm平台上为喜爱的歌手和相关歌曲添加标签。我们过滤掉原始数据集中用户对歌手没有标注历史的数据后,产生了92834个“用户-产品”二元组,28176个“用户-标签”二元组和84396个“产品-标签”二元组,来自1892个用户对17632为歌手标注的2109个标签。为了检验tbpr的推荐性能,我们从“用户-产品”二元组中随机选取20%的“用户-产品”交互数据作为测试集,剩余的数据作为训练集训练tbpr模型参数。最后得到了含有74362个“用户-产品”二元组的训练集,和18472个“用户-产品”二元组的测试集。
2)评价指标
采用平均准确率均值(map)和标准化折扣增益(ndcg),长度为n的准确率pre@n,感受性曲线下方的面积(auc)作为本实验的评价指标。平均准确率均值和准确率衡量推荐推荐效果的指标,标准化折扣增益和感受性曲线下方的面积衡量排序效果的指标。长度为n的准确率pre@n的计算公式为:
式(7)中,s(k;u)表示出现在列表前k个产品中并被成功被用户u选择的产品集合。平均准确率均值的计算公式为:
式(8)中,s(u)表示测试集中用户u交互过的所有产品集合,c(u)表示测试集中用户u的待推荐产品集合。
感受性曲线下方的面积的计算公式为:
式(10)中
标准化折扣增益ndcg的计算公式如下:
其中,
式(12)和式(13)中,r(u)是测试集中用户u的待推荐产品集合c(u)的降序排序,
3)在标准数据集上进行实验
为验证发明的有效性,我们将本发明提出的tbpr方法和4种基准方法进行比较,4种基准方法为:随机推荐算法(random)、最热推荐算法(mostpopular)、基于用户的最近邻(userknn)算法,基于矩阵分解的贝叶斯个性化排序(bprmf)方法。在last.fm数据集上用5种方法进行建模和推荐,并将推荐结果进行比较。实验结果如图2。与4种基准方法相比,本发明提出的群推荐方法在last.fm获得了更优的推荐精度。
为了验证本发明提出的tbpr方法对冷启动用户的推荐效果,我们本发明和基于矩阵分解的贝叶斯个性化排序(bprmf)方法分别对训练集中选择产品个数少于5的用户进行推荐,图3反映的是tbpr与bprmf对冷启动用户的推荐结果分析。实验结果表明本发明通过标签信息在用户与产品之间建立匹配联系,对于冷启用用户的推荐具有良好的效果。图4反映的是不同稀疏度训练集数据对本发明实验结果的影响,实验结果表明,在训练集稀疏度较低的情况下,本发明的推荐效果要好于其他对比算法。本发明对于稀疏度较高的数据和冷启动用户的推荐都具有良好的效果。
- 还没有人留言评论。精彩留言会获得点赞!