基于用电数据对企业进行偿付能力风险识别和预测的方法与流程
本发明涉及企业偿付能力风险识别或者信用评级领域,特别是涉及一种仅基于单视角的用电特征数据对乏信息中小企业的偿付能力进行风险识别和预测的方法。
背景技术:
2015年3月发布的“电改9号文”启动了万亿级的售电市场。自此,各类售电实体如雨后春笋一般蓬勃发展。截止2017年9月11日,已有2185家售电公司或代理平台在电力交易中心公示。伴随着电力交易市场的盘活,售电实体服务的对象除了少数重点关注的大客户之外,更多的是庞大的中小企业群体。正如风险控制之于金融系统的重要性,售电实体首先需要考虑的是如何对参差不齐的中小企业客户进行偿付能力不足的风险识别和预测,从而最大限度降低影响公司经营的被动风险。然而,有别于全景信息披露规范、行为模式有据可循的少数大客户,鱼龙混杂的中小企业由于信息缺失或者行为模式易变很难利用多维视角下的传统评价体系对其进行信用评估或者风险诊断。
我国在电力客户信用评价方面已经开展了较多研究。从方法上看,绝大多少研究是基于传统手段的综合评价方法,比如层次分析法、模糊综合评价法、熵权法、数据包络分析法、topsis、物元分析理论;少数用到了人工智能方法,比如聚类方法、神经网络方法、决策树和支持向量机;从评价指标体系上看,已经构建了丰富的可以靠主客观结合打分量化的指标体系,鲜有引入用大数据完全客观量化的指标。目前,电力客户的信用管理实践广泛采用5c全景维度的指标体系(品德character、能力capacity、资本capital、抵押collateral和外部情况condition)来考察企业的信用状况或偿付能力。因此,对于售电实体来说难以获取企业客观的多维视角数据是应用传统信用评估方法的最大障碍。
技术实现要素:
本发明主要解决的技术问题是提供一种仅基于用电特征单一视角数据采用机器学习模型对乏信息中小企业的偿付能力进行风险识别和预测的方法,为售电市场放开下的千万售电实体提供了一个评估客户风险的有效手段。本发明从企业用电缴费数据中提炼出一个能够反映其偿付电费能力的指标作为分类器模型的响应变量,从而将企业划分为偿付能力差的和无须关心的两大群体,进而采用集成学习的随机森林和梯度提升决策树二分类器模型实现了风险客户群体的识别和预测。
为解决上述技术问题,本发明基于用电数据对企业进行偿付能力风险识别和预测的方法,包括:
s1对用电业务数据的清洗和治理,所述用电业务数据包括:9张原始业务数据表:用户档案表、日冻结表底示数、日测量功率曲线、测量点日冻结电压统计数据、测量点日不平衡度统计数据、日测量点电压曲线、日测量点电流曲线、线路档案、线路线损数据;
s2构建和标准化14项自变量指标数据,所述的自变量指标数据包括:合同容量、年用电量、设备利用小时率、年平均日负荷率、年最大峰谷差率、季不均衡率、电压越上限率、电压越下限率、电压不平衡率、电流不平衡率、电压断相率、需量超容、线路线损率、电量陡变指数;
s3基于探索性因子分析技术的数据降维和特征提取;
s4利用缴费数据构造出反映企业偿付能力的响应变量;
s5利用集成机器学习模型进行二分类问题的模式识别和预测;
s6模型的参数调优策略。
进一步地,电量陡变指数为日用电量移动平均后差分的斜率突变的数量,首先计算第i天用电量趋势斜率,即
其中,fl是第l天的用电量,
再定义第i天的陡变指数,即
最后形成统计周期n内的电量陡变指数t,即
电量陡变指数一定程度上反映了企业窃电的可能性,是诚信的表征。
进一步地,s4包括:利用一段连续时间内企业缴纳电费的次数n和金额rcv_amt以及相应的发行电费次数m和金额rcvbl_amt,构造出反映企业偿付能力的响应变量ai指数。
进一步地,为了定量刻画企业缴纳电费的偿付能力,构造了一个ai指数,其计算公式为:
其中,rcv_amti为企业的第i次缴纳电费金额;rcvbl_amtj为企业的第j次发行电费;n为统计期内企业的缴费次数;m为统计期内电费的发行次数。
进一步地,s5采用了随机森林、梯度提升决策树两种形式的基于决策树的集成学习模型。
进一步地,梯度提升决策树模型采用了xgboost形式的算法实现,表述如下:
假定模型输入的训练样本集为s={(x1,y1),(x2,y2),...,(xm,ym)},其中xi为特征数据集,yi为对应类别结果非1即-1,m为样本个数;ft-1(x)是第t-1轮迭代后获知的强学习器模型,l(y,ft-1(x))是其对应的损失函数。gbdt迭代算法如下:
step1:初始化弱学习器
step2:对迭代轮数t=1,2,...,t,执行
2.1对于每一个样本i=1,2,…,m,计算上一轮强学习器损失函数相应的负梯度
2.2构造第t轮迭代的训练样本集(xi,δt,i),i=1,2,...,m,利用cart算法生成第t棵二叉回归树(对应第t个弱学习器ht(x))。该回归树对应的叶子节点区域标记为rt,n,n=1,2,...,n。
2.3对于每一个叶子节点区域n=1,2,…,n,计算最佳拟合值
进而可得第t棵回归树对应的弱学习器模型为
2.4更新第t轮迭代后的强学习器模型
ft(x)=ft-1(x)+ηht(x)
其中η为迭代步长,是为提高模型泛化能力而引入的正则化项。
step3:得到t轮迭代过后最终的强学习器模型为
对于二分类问题,由于样本集的类别输出值yi不是连续的定距变量,往往采用如下对数似然形式的损失函数,
进一步地,s6梯度提升决策树模型可以调优的三个重要参数是弱分类小决策树的建树深度max_depth、决策树最大迭代残差修正次数nrounds以及迭代步长eta。
借由上述方案,本发明基于用电数据对企业进行偿付能力风险识别和预测的方法至少具有以下优点:
本发明:基于用电特征单一视角数据对中小企业偿付能力进行风险识别和预测,独创的方式方法在中小企业信息披露匮乏的困境下找到了一条出路,既绕开了传统信用评级方法难以逾越的障碍又以一种完全客观量化而且更加简化有效的方式实现了殊途同归。最为关键的是,对于售电实体来说获取客户各类用电数据是水到渠成的,免去了利用传统信用评级方法必须主、客观结合构造多视角数据的繁琐和麻烦。
附图说明
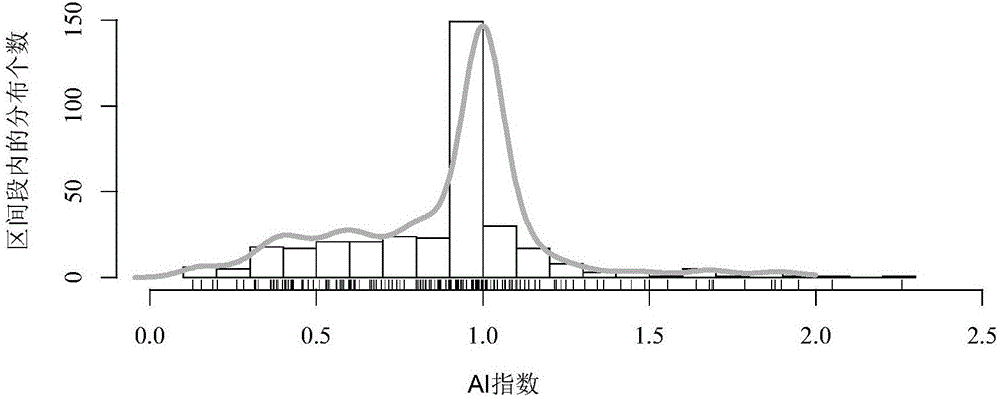
图1是本发明提供的ai指数分布的柱状图和轴须图;
图2是本发明提供的探索性因子分析的碎石图。
具体实施方式
下面结合附图对本发明的具体实施方式做进一步的详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
请参阅图1至图2,本发明以某地区用电合同容量介于200kw~2000kw之间的363家中小企业群体为数据分析对象,本发明基于用电数据对企业进行偿付能力风险识别和预测的方法,方法的具体实施方式为:
1.1数据清洗和融合
数据的清洗和融合对应着数据由窄表得宽表的过程,是数据分析的第一步也是工作量最大的一步。数据清洗是指完成对数据缺失值和异常值的处理。来自不同业务系统的窄表数据对应不同的清洗规则。数据融合是指清洗后的窄表数据经过一定的集成和变换构造出能够反映不同用电角度的指标数据,比如负荷波动指标、电量陡变指标等,进而形成宽表。
数据清洗的原则是先删除缺失率满足一定条件的记录和异常值,后采用均值思想填补。比如,对于日用电量窄表数据,用前、后有数据的表底示数的差除以缺失天数填补缺失值,剔除日用电量大于行业水平百分之十的异常用户;对于缴费数据,将交易额的负极大值和交易间隔小于一分钟的相同数额交易作为异常值删除。
在数据融合方面,定义了宽表数据的15个指标项,其中合同容量、年用电量、设备利用小时率、年平均日负荷率、年最大峰谷差率、季不均衡率、电压越上下限率、电压电流不平衡率、电压断相率、线路线损率可以顾名思义外,还着重定义了如下三个指标:
(1)需量超容
对应一个分类变量。将月最大十五分钟瞬时功率乘以功率因数后除以合同容量,比值记为k。参考国网用采数据异常诊断标准,以0.8、1.1、1.3为三个阈值点,将连续变量k分割为值是{0,1,2,3}的四类别变量。
(2)电量陡变指数
为日用电量移动平均后差分的斜率突变的数量。首先计算第i天用电量趋势斜率,即
其中fl是第l天的用电量,
再定义第i天的陡变指数,即
最后形成统计周期n内的电量陡变指数t,即
电量陡变指数一定程度上反映了企业窃电的可能性,是诚信的表征。
(3)偿付能力指数
为了定量刻画企业缴纳电费的偿付能力,构造了一个ai指数,其计算公式为:
其中,rcv_amti为企业的第i次缴纳电费金额;rcvbl_amtj为企业的第j次发行电费(账单金额);n为统计期内企业的缴费次数;m为统计期内电费的发行次数。
类比用户偿付信用卡账单的场景,一般情况下多数用户都是等欠费额缴纳,对应ai指数等于1;偿付能力不足的用户会选择分期付款,即不足额缴纳,对应ai指数小于1;偿付能力充裕的用户为减少麻烦会考虑超额缴纳,对应ai指数大于1。图1是此发明中ai指数分布的柱状图和轴须图。可见,ai指数的众数为1,完全符合预期。相比于超额缴纳,有比较多的企业对应的ai指数小于1,表明有偿付风险的企业群体不容忽视。本发明中,我们将ai指数作为响应变量,并且考虑数据倾斜和保守估计两方面因素将ai指数小于等于0.53的企业定义为偿付能力风险高到预警级别的警戒群体,而将ai指数高于0.53的企业归为非警戒群体,因此本发明要解决的技术问题转化成二分类的识别和预测问题。
1.2特征选择和提取
pearson相关性分析表明宽表的15项指标自变量数据之间存在多重共线性关系,所以为了提高模型的精度和效率有必要进行数据特征选择和提取。主成分分析、线性判别分析和探索性因子分析(efa)都是常用的经典技术。经过对比和测试,efa是最为合适的方法。
由如图2所示的碎石检验图,根据只要真实数据相关系数矩阵的特征值大于100次随机模拟数据相关系数矩阵的特征值就可入选的准则,判定合适的因子个数为5。利用最大似然法提取5个公共因子后,为增强因子的可解释性对其进行方差极大正交旋转,最后得到的因子载荷矩阵及相关说明。可见,5个因子从企业的不同用电信息角度窥视了企业概貌,比如f1因子直接反映了企业的用电规模、f2因子通过电压不稳定因素反映了企业设备资产优良水平、f3因子反映了企业生产对电网的冲击情况、f4因子反映了企业自身用电负荷的波动情况、f5因子反映了企业生产特征。另外,还发现:年最大峰谷差率x5、电压断相率x9、电量陡变指数x12以及线路线损率x13对应的efa适用性评判定性为极差,这表明其信息并未被上述5个因子所涵盖,因此在数据建模阶段这些指标数据不参与因子分析而是直接作为模型输入。
1.3建模和性能评估
建模的实质是根据发明问题的划分选择合适的数学模型进行数据背后规律的模式匹配。本发明属于二分类问题的监督式学习范畴,二分类器性能评估首先涉及到样本数据集的划分方式,常见的有训练集-测试集(-验证集)静态划分、k-折交叉验证两种方式。其次,分类器的性能评价指标有正确率、错误率、查准率、查全率(召回率)、f1分数、roc/auc、kappa一致性系数,其中auc和kappa系数能够屏蔽由于样本不平衡导致的由高正确率推断出模型良好的错误结论,是更健全的评价指标。
采用默认参数的c5.0模型。单从正确率指标(90.28%)上看似乎模型尚可,但是由于企业偿付能力风险识别更聚焦在正类的查准率(61.54%)和查全率(80%)上,表明两者都有待提高。模型的kappa一致性系数为0.64,这也表明此模型的综合评价并不高。为了提升正类查准率,引入犯错惩罚参数矩阵,即让c5.0决策树模型在训练时如果把正类预测为假阳性则接受更高的惩罚。数据分析结果表明,尽管正类的查准率从61.54%提高到了100%,但是正类的查全率从80%降低到了40%,依然无法找到正类查准率和查全率之间的最佳平衡点。
1.4模型优化和调参
模型优化的方向既可以考虑更换其它分类器模型比如适合小样本学习的支持向量机(supportvectormachine,svm),也可以采用集成学习组合分类器的思路。结果表明:尽管采用高斯核函数形式svm模型的正类查准率提高至100%,但是正类查全率低至30%、kappa系数降至0.42。这说明svm模型相比c5.0模型是更不胜任的。追其原因,svm是数据倾斜敏感的模型,由于样本数据正负类的严重不平衡导致了模型结果要比预想的差。基于决策树的组合分类器模型的分支包括装袋(bagging)技术、提升(boosting)技术和随机森林(randomforest,rf)技术。其中,梯度提升决策树(gradientboostingdecisiontree,gbdt)和自适应增强算法(adaptiveboosting,adaboost)是boosting思想的两种不同实现。模型参数调优是选定模型后紧接着进行的一步环节。比如,gbdt模型可以调优的三个重要参数是弱分类小决策树的建树深度max_depth、决策树最大迭代残差修正次数nrounds以及迭代步长eta。adaboost、gbdt和随机森林rf(利用了bagging思想)这三种集成学习算法的性能对比结果表。从中可见,相比于决策树c5.0模型集成学习能够显著提升模型的性能,而且经过参数调优的gbdt和rf两种算法殊途同归地找到了正类查准率和查全率之间的最佳平衡点。gbdt和rf两种算法性能相当,即企业偿付能力风险异常高警戒群体的查准率为100%、查全率为90%、模型整体的正确率为98.61%、f1分数为0.95、更重要的是综合评价指标kappa系数高达0.94。这都表明gbdt和rf均是胜任本发明的优异二分类器模型。
表1是本发明提供的5个公共因子的载荷矩阵及解释;
表2是本发明提供的三种集成学习adaboost、随机森林和梯度提升决策树模型的性能对比;
1.5预测结果的实证分析
数据分析结果已经表明基于单一视角的用电特征对中小企业ai指数进行二分类识别和预测是十分有效的。为了进一步理解本发明的有效性从最能表征企业偿付能力的财务数据来印证ai指数的指向性是有意义的。由于黑色金属加工及冶炼行业的中小企业对外披露信息十分有限,我们利用网络爬虫技术只搜集到了6家有财务数据的中小企业。表3是这6家企业的比对数据。从中可见:(1)6家企业都一致地呈现出低利润率的行业特征,(2)定义能够直接体现企业单位资产盈利能力的指数pi=利润总额u3/资产总额u1×100%。如果将pi指数作为衡量企业偿付能力的标尺,则其与ai指数的指向性除了企业q5外是完全一致的。即从样本数据可知:大体上ai指数越低对应的pi指数也越低,表征了企业的偿付能力越不足、偿付风险越大。因此,本发明用自定义的ai指数来表征企业的偿付能力是合理可信的。
表3是本发明提供的实证分析的六家企业财务数据与ai指数印证;
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!