一种基于低维时空特征提取与主题建模的肢体冲突行为检测方法与流程
本发明属于视频监控技术领域,涉及一种肢体冲突行为检测方法,特别涉及一种基于低维时空特征提取与主题建模的肢体冲突行为检测方法。
背景技术:
:
近年来,随着各种安全突发事件的增多,大众安全意识的提升,同时伴随着人工智能理念的渗透和人工智能技术的不断成熟,智能监控越来越受到人们的关注。传统的监控系统主要通过人工监控的方式实现对公共场合的安全管理,缺乏实时性和主动性。在很多情况下,视频监控由于无人管理只是起到了视频备份的作用没有做到监管的职责。此外,随着监控摄像头的普及和广泛布设,传统的人工监控方式已经不能满足现代监控的需求。为解决这一问题,大众都致力于寻求解决方案来代替人工操作。目前,随着视频监控技术以及信息科学的不断发展,视频监控、人机交互、视频搜索等领域有了长足的发展,自动化监控逐渐成为一个具有广泛应用前景的研究课题。异常行为检测是自动监控的重要内容,相较于一般地人体行为识别集中在人的常规动作的识别上,异常行为通常具有高突发性,并且持续时间较短,很难获取行为特征的特点。
近年来,对于异常行为的检测,研究者们提出了不同的方法,早期异常行为检测的研究工作主要集中于利用简单集合模型描述人体行为,如基于二维轮廓模型、三维圆柱体模型等;除静态几何模型外,研究人员还尝试利用描述人体运动的某些特征进行建模,如形状、角度、所在位置、运动速度、运动方向、运动轨迹等特征进行行为描述和区分,并采用包括主成分分析法、独立成分分析法等在内的子空间方法对提取的特征进行降维和筛选,从而进行行为分析。现有针对异常行为检测的发明,存在未能真正理解异常行为的固有特点,因而现有异常行为检测模型并不能完全反应异常行为的本质,从而导致依据现有异常行为检测模型得到的检测精度并未达到理想效果,因此,设计一种基于低维时空特征提取与主题建模的肢体冲突行为检测方法,计算方法准确,检测结果精确。
技术实现要素:
:
本发明的目的在于克服现有技术存在的缺陷,寻求设计一种基于低维时空特征提取与主题建模的肢体冲突行为检测方法,计算方式简单,计算精度高,能够快速准确地对肢体冲突行为进行检测,并能够及时预警。
为了实现上述目的,本发明涉及的一种基于低维时空特征提取与主题建模的肢体冲突行为检测方法具体包括的工艺步骤如下:
S1、词本的定义
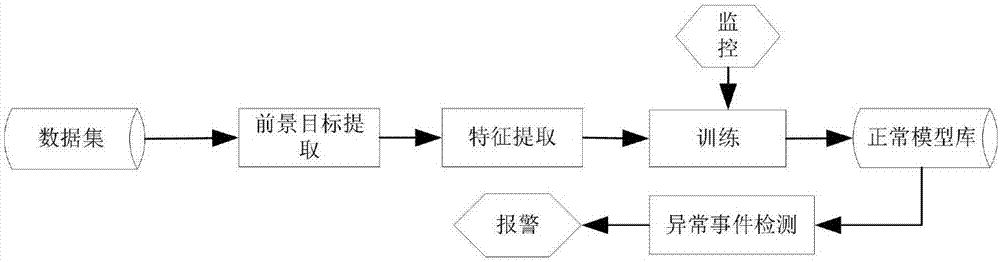
先从原始的监控视频数据中提取出符合人类认知的语义理解,通过本发明的算法设计自动分析理解视频数据,分析过程分为前景目标的提取、目标特征表示和行为分析归类,该方法基于LDMA模型用于视频监控中人体异常行为检测,对视频中每个对象的像素位置进行描述,对每个像素抽取特征向量,该特征向量包含每一像素的位置、运动的速度和方向、隶属于目标对象的大小,最终形成视觉信息词本和文档,并定义一个有效的词本,作为涵盖监控视频中的像素可查询的字典;
S2、量化对象的像素位置
在视频监控获得的视频中,行为基本是以行为发生者的位置为特征的,因此,本发明将位置信息考虑到词本的构建中,把视频中对象的像素位置量化成不重叠的10*10的细胞元中,对于M×N的视频对象,因此能够获得M/10×N/10个细胞元组;
S3、描述场景中的前景目标的大小
为了准确表示视频对象中前景目标,本发明把每一个前景像素和该像素属于何种前景目标联系起来,在视频监控获得的视频数据中,观察到的前景框基于它们的大小能够划分为两类,一类为小的前景框,主要是行人,一类是大的前景框,主要包括车辆或者一群行人;因此,本发明使用K-means聚类来分类前景框的大小,从而得到每个像素隶属的前景目标,取K-means中的聚类数k=2,最终使用聚类标号1和2来描述场景中的目标的大小,即1为小目标,2为大目标;
S4、确定前景像素的运动情况
对于视频监控中的场景,分析的内容针对于前景目标,需要进行背景减除得到前景像素,并对得到的每个前景像素根据Lucas-Kanade光流算法求解该像素的光流信息,通过设定光流向量大小的阈值来界定前景静态像素(静态标签)和动态的像素;再把动态的像素量化成具有运动方向、轨迹、位置、速度4种运动描述词描述的运动状态,因此,对于检测到的前景像素,有具有运动方向、轨迹、位置、速度和静止5种可能的运动描述词确定前景像素的运动情况;
S5、定义视频序列和像素点
将视频监控中的场景下的视频序列记为将分割成若干视频序列,其中,为分割的第m个视频片段,把视频序列看做当前的语料库则对应语料库中的文档(document),在视频片段中,定义像素点为词(word),每个词对应一个主题(topic),则随着时间t的变化,在中,各个词主题向其它主题产生转移或自转移状态,由MCMC(Markov Chain MonteCarlo)特性可知,这种特性在经过一段时间后会达到一种平稳分布;
S6、建立词本
根据上述步骤所述对于M×N的视频对象每个像素的位置有M/10×N/10种表示,运动形式有5种描述,大目标和小目标有两种表述,能够得到的词的表达为M/10×N/10×5×2种形式,即对于某个前景像素,存在种描述方式,但在某一时刻下,每个像素的运动信息和隶属的目标具有独立性,即对于视频片段,随着时间t的变化形成的不同的主题,其主题应该是独立分别获取的,因此,每个位置(location)能够采用联合特征(运动,大小)来表示将运动和大小的特征进行级联,然后作为每个细胞元的词的集合,用Vc表示,这就表示在构建一个视频段时,一个像素要对本位置同时提供两种特征词——运动和隶属的目标大小,则最终词本能够表示成M/10×N/10×(5+2)形式;因此,一个像素的特征词可以定义成wc,aC为细胞元位置,a为运动形式和大小的联合特征;
S7、语料库的建立
将监控视频分成短的若干个视频段,每个视频段作为一篇文档,视频段中随时间t变化的像素点表示成文档中出现的词以及这一系列词表示的主题内容,再以每个像素生成的词本为依据,若语料库中的总的词频为N,则在所有的N个词中,如果关注每个词vi的发生频率次数ni,那么
则语料库中每一语料的概率为:
其中,P(n)指语料库中每个词发生的频率次数的概率;
那么,对于每一个具体的主题并由该主题产生语料库中词汇的概率则最终语料库产生的概率就是对每一个主题上产生的词汇概率的累加求和:
语料库W中的服从多项式分布,主题服从一个概率分布这个分布成为参数的先验分布,先验分布选择多项式分布的共轭分布——Dirichlet分布;根据Dirichlet的分布规律,来计算出文本语料的产生概率为:
其中,代表Dirichlet先验分布的参数;所述文本语料是由文档组成语料库
将视频序列看作一篇文档(document),文档则是由多个主题(topic)混合而成,而每个Topic都是词汇上的概率分布,视频序列中每个像素代表的每个词是由一个固定的Topic生成的,这个过程就是文档建模的过程,即为一个bag-of-words模型:若有V个topic-word,记为每个主题对应一个词向量的概率分布对于包含M篇文档的语料C=(d1,d2,···,dM)中的每篇文档dm,都会有一个特定的doc-topic即每篇文档对应的主题向量概率分布为那么第m篇文档dm中每个词的生成概率为:
整篇文档的生成概率为:
由于文档之间相互独立,根据上述公式写出整个语料的生成概率,生成Topic-Model,然后使用EM算法进行求解局部最优解;
S8、肢体冲突行为的判断
基于低维时空特征提取和主题建模的肢体冲突行为检测方法,结合了低维的数据特征表示和基于模型的复杂场景分析,以此对视频序列进行分析,根据在视频中检测出人体位置,利用动作中人体位置信息的变化,学习出一个与身体部位无关的整体运动模型,通过分析整体运动模型,将检测到的结果与模型中的参数进行对比,进而判断出人体运动状态,本发明中每种行为会对应一种主题分布,在训练好的模型情况下,所测试的视频片段中如有出现肢体冲突的情况,那么这种行为会集中分布在一种主题中,进而根据主题确定这种行为是属于出现肢体冲突的状态。
本发明与现有技术相比,具有如下有益效果:主要采用图像的光谱特征精确提取运动区域的轮廓,能够清晰的看到运动目标的轮廓边缘,用于行为特征分析,不仅适用于打架等肢体冲突行为,同样适用于其他行为的检测,如快速移动等行为,该方法设计构思巧妙,检测原理科学,检测方式简单并且检测精确度高,应用环境友好,极具市场前景。
附图说明:
图1为本发明涉及的视频流中不同视频帧图像的前景检测效果图。
图2为本发明涉及的基于低维时空特征提取与主题建模的肢体冲突行为检测方法的工艺流程框图。
具体实施方式:
下面通过实施例并结合附图对本发明做进一步的说明。
实施例:
为了实现上述目的,本实施例所述的基于低维时空特征提取与主题建模的肢体冲突行为检测方法具体包括的工艺步骤如下:
S1、词本的定义
先从原始的监控视频数据中提取出符合人类认知的语义理解,通过本实施例的算法设计自动分析理解视频数据,分析过程分为前景目标的提取、目标特征表示和行为分析归类,该方法基于LDMA模型用于视频监控中人体异常行为检测,对视频中每个对象的像素位置进行描述,对每个像素抽取特征向量,该特征向量包含每一像素的位置、运动的速度和方向、隶属于目标对象的大小,最终形成视觉信息词本和文档,并定义一个有效的词本,作为涵盖监控视频中的像素可查询的字典;
S2、量化对象的像素位置
在视频监控获得的视频中,行为基本是以行为发生者的位置为特征的,因此,本实施例将位置信息考虑到词本的构建中,把视频中对象的像素位置量化成不重叠的10*10的细胞元中,对于M×N的视频对象,因此能够获得M/10×N/10个细胞元组;
S3、描述场景中的前景目标的大小
为了准确表示视频对象中前景目标,本实施例把每一个前景像素和该像素属于何种前景目标联系起来,在视频监控获得的视频数据中,观察到的前景框基于它们的大小能够划分为两类,一类为小的前景框,主要是行人,一类是大的前景框,主要包括车辆或者一群行人;因此,本实施例使用K-means聚类来分类前景框的大小,从而得到每个像素隶属的前景目标,取K-means中的聚类数k=2,最终使用聚类标号1和2来描述场景中的目标的大小,即1为小目标,2为大目标;
S4、确定前景像素的运动情况
对于视频监控中的场景,分析的内容针对于前景目标,需要进行背景减除得到前景像素,并对得到的每个前景像素根据Lucas-Kanade光流算法求解该像素的光流信息,通过设定光流向量大小的阈值来界定前景静态像素(静态标签)和动态的像素;再把动态的像素量化成具有运动方向、轨迹、位置、速度4种运动描述词描述的运动状态,因此,对于检测到的前景像素,有具有运动方向、轨迹、位置、速度和静止5种可能的运动描述词确定前景像素的运动情况;
S5、定义视频序列和像素点
将视频监控中的场景下的视频序列记为将分割成若干视频序列,其中,为分割的第m个视频片段,把视频序列看做当前的语料库则对应语料库中的文档(document),在视频片段中,定义像素点为词(word),每个词对应一个主题(topic),则随着时间t的变化,在中,各个词主题向其它主题产生转移或自转移状态,由MCMC(Markov Chain MonteCarlo)特性可知,这种特性在经过一段时间后会达到一种平稳分布;
S6、建立词本
根据上述步骤所述对于M×N的视频对象每个像素的位置有M/10×N/10种表示,运动形式有5种描述,大目标和小目标有两种表述,能够得到的词的表达为M/10×N/10×5×2种形式,即对于某个前景像素,存在种描述方式,但在某一时刻下,每个像素的运动信息和隶属的目标具有独立性,即对于视频片段,随着时间t的变化形成的不同的主题,其主题应该是独立分别获取的,因此,每个位置(location)能够采用联合特征(运动,大小)来表示将运动和大小的特征进行级联,然后作为每个细胞元的词的集合,用Vc表示,这就表示在构建一个视频段时,一个像素要对本位置同时提供两种特征词——运动和隶属的目标大小,则最终词本能够表示成M/10×N/10×(5+2)形式;因此,一个像素的特征词可以定义成wc,aC为细胞元位置,a为运动形式和大小的联合特征;
S7、语料库的建立
将监控视频分成短的若干个视频段,每个视频段作为一篇文档,视频段中随时间t变化的像素点表示成文档中出现的词以及这一系列词表示的主题内容,再以每个像素生成的词本为依据,若语料库中的总的词频为N,则在所有的N个词中,如果关注每个词vi的发生频率次数ni,那么
则语料库中每一语料的概率为:
其中,P(n)指语料库中每个词发生的频率次数的概率;
那么,对于每一个具体的主题并由该主题产生语料库中词汇的概率则最终语料库产生的概率就是对每一个主题上产生的词汇概率的累加求和:
语料库W中的服从多项式分布,主题服从一个概率分布这个分布成为参数的先验分布,先验分布选择多项式分布的共轭分布——Dirichlet分布;根据Dirichlet的分布规律,来计算出文本语料的产生概率为:
其中,代表Dirichlet先验分布的参数;所述文本语料是由文档组成语料库
将视频序列看作一篇文档(document),文档则是由多个主题(topic)混合而成,而每个Topic都是词汇上的概率分布,视频序列中每个像素代表的每个词是由一个固定的Topic生成的,这个过程就是文档建模的过程,即为一个bag-of-words模型:若有V个topic-word,记为每个主题对应一个词向量的概率分布对于包含M篇文档的语料C=(d1,d2,···,dM)中的每篇文档dm,都会有一个特定的doc-topic即每篇文档对应的主题向量概率分布为那么第m篇文档dm中每个词的生成概率为:
整篇文档的生成概率为:
由于文档之间相互独立,根据上述公式写出整个语料的生成概率,生成Topic-Model,然后使用EM算法进行求解局部最优解;
S8、肢体冲突行为的判断
基于低维时空特征提取和主题建模的肢体冲突行为检测方法,结合低维的数据特征表示和基于模型的复杂场景分析,以此对视频序列进行分析,根据在视频中检测出人体位置,利用动作中人体位置信息的变化,学习出一个与身体部位无关的整体运动模型,通过分析整体运动模型,将检测到的结果与模型中的参数进行对比,进而判断出人体运动状态,本实施例中每种行为会对应一种主题分布,在训练好的模型情况下,所测试的视频片段中如有出现肢体冲突的情况,那么这种行为会集中分布在一种主题中,进而根据主题确定这种行为是属于出现肢体冲突的状态。
- 还没有人留言评论。精彩留言会获得点赞!