用户兴趣信息推荐方法、存储介质与流程
本发明涉及大数据技术分析领域,具体说的是用户兴趣信息推荐方法、存储介质。
背景技术:
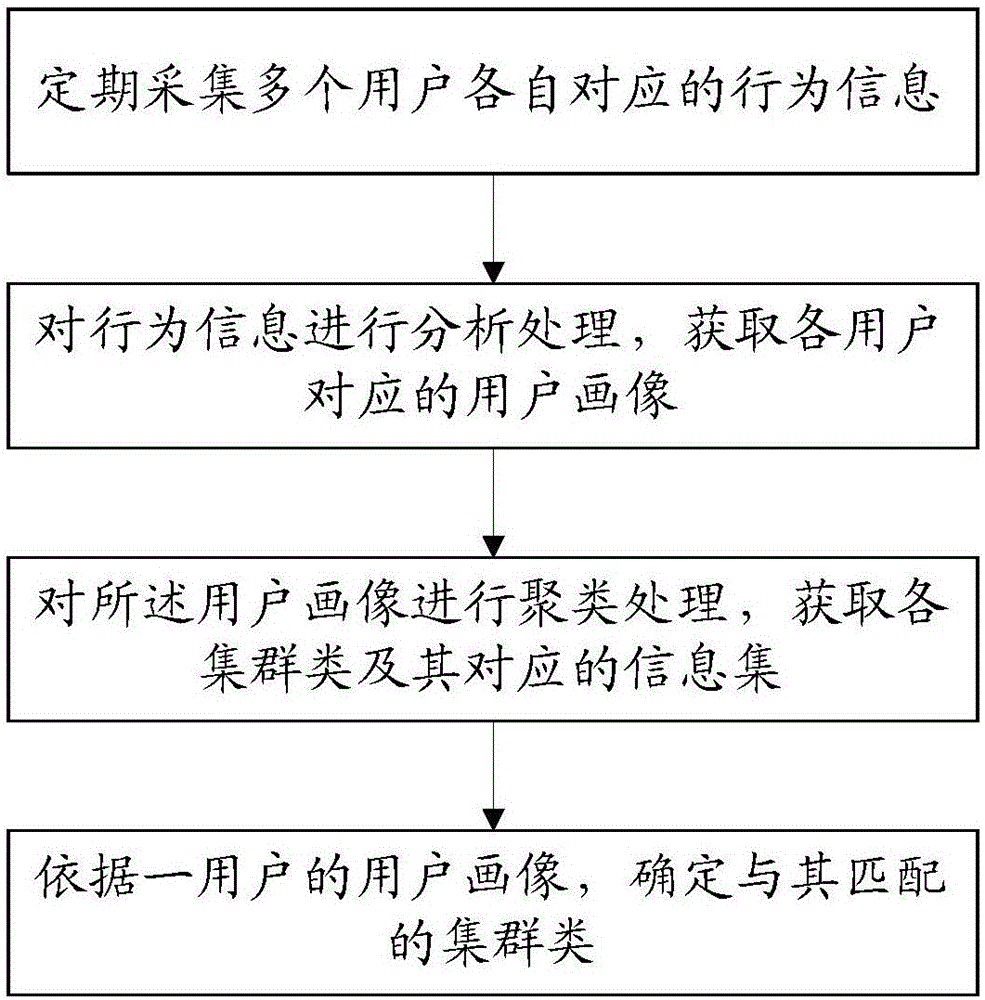
:随着大数据时代的来临,极其丰富又多样的网络信息让人应接不暇。面对大数据网络系统,用户寻找实际需求信息的难度大大增加,往往难以准确地获取感兴趣的信息。因此,现有趋势是主动给用户推荐其感兴趣的信息,以尽可能的提高用户对当前环境的驻留时间或推荐信息的点击率。特别是对于第三方应用,非常有必要能够对应特定的用户针对性的推荐其感兴趣的信息,以提高信息关注度和利用率。例如大数据技术在网络教学中的实用。现有的教学系统学员主要通过以下几种多种进行课程的选择:1、课程排行点播。学员通过课程点播排行榜来选择所要学习的课程。一般来说,在现有的教学系统中,会对点击量最多的n个课程进行排名展示,学员可以直观的看到较为热门的课程。2、课程索引点播。对于学员来说,对于自己所要学习的知识点可以通过一张知识体系图来了解。因此现有的教学系统中有针对各学科的知识体系索引图,学员可以去逐一学习相应的课程。3、自由点播。学员通过自有浏览的方式去选择课程。上述推荐方式具有以下不足:1、在课程排行点播中,只能展示出较为热门的课程,但是热门的课程不一定是学员需要的,因此增加了学员寻找需求资源的难度。2、对于学员来说,想要学习到的知识体系不一定能够了解的全面,因此即使有知识体系图作为引导也并不能够让其充分的学习到知识。3、自有点播的方式目的性太差,学习效率低下,时间成本过高。可见,在网络教学领域中,现有推荐方式多为基于关联的方式进行推荐,在该方式下对用户进行推荐结果较为笼统,不能做到对个人的精确推荐。因此,有必要提供一种用户兴趣信息推荐方法、存储介质,解决难以针对个人精准的推荐其感兴趣信息的问题。技术实现要素:本发明所要解决的技术问题是:一种用户兴趣信息推荐方法、存储介质,能够针对个人精准的推荐其感兴趣的信息。为了解决上述技术问题,本发明采用的技术方案为:一种用户兴趣信息推荐方法,包括:定期采集多个用户各自对应的行为信息;对行为信息进行分析处理,获取各用户对应的用户画像;对所述用户画像进行聚类处理,获取各集群类及其对应的信息集;依据一用户的用户画像,确定与其匹配的集群类。本发明提供的另一个技术方案为:一种计算机存储介质,其上存储有计算机程序,所述程序在被计算机读取时,能执行上述用户兴趣信息推荐方法中的步骤。本发明的有益效果在于:本发明通过定时线上对多个用户的行为信息进行采集,线下分析生成数据库;能够基于数据库实时地对应单个用户准确地推荐其感兴趣的信息。具体的,本发明通过聚类算法将单个用户稀疏的数据,归集到与其相同类特征的群体中去,再基于具有类特征的集群对单个用户进行协同过滤推荐,获取推荐数据,使所推荐的数据更为精准有效。附图说明图1为本发明的一种用户兴趣信息推荐方法的流程示意图;图2为本发明实施例一的用户兴趣信息推荐方法的流程示意图;图3为本发明实施例四的系统结构组成连接示意图。标号说明:1、数据采集模块;2、数据存储模块;3、数据分析模块;4、课程推荐模块。具体实施方式为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。本发明最关键的构思在于:本发明通过聚类算法将单个用户稀疏的数据,归集到与其相同类特征的群体中去,再基于具有类特征的集群对单个用户进行协同过滤推荐,获取推荐数据,使所推荐的数据更为精准有效。请参照图1,本发明提供一种用户兴趣信息推荐方法,包括:定期采集多个用户各自对应的行为信息;对行为信息进行分析处理,获取各用户对应的用户画像;对所述用户画像进行聚类处理,获取各集群类及其对应的信息集;依据一用户的用户画像,确定与其匹配的集群类。从上述描述可知,本发明的有益效果在于:采用了聚类算法,能够解决单个用户的数据稀疏性的问题,使单个用户形成的稀疏矩阵成为具有类特征的密集矩阵,通过具有类特征的集群对单个用户进行协同过滤推荐,通过协同过滤算法的推荐的方式来为用户提供具有针对性的信息,使推荐更为精准有效。进一步的,所述依据一用户的用户画像,确定与其匹配的集群类,具体为:采集一用户的行为信息;若数据库中已存储有所述一用户的在先行为信息,则通过合并获取所述一用户对应的所有行为信息;对所述所有行为信息进行分析处理,得到所述一用户的用户画像;获取与所述一用户的用户画像匹配的集群类;推荐所述匹配的集群类对应的信息集中相应的信息给所述一用户。由上述描述可知,对应目标用户的分析将基于在先采集得到的行为信息,随着时间的积累,所采集得到的基础用户以及目标用户的行为信息数据量的提升,所获取的数据库也将更加的具有标志性,基于此对应目标用户的推荐信息分析将更深入更准确,从而逐步的为用户定制出个性化的兴趣信息库,更好的锁定用户。进一步的,通过在终端埋点的方式收集得到所述行为信息;所述行为信息包括对应一信息的至少一个的具体行为。由上述描述可知,能保证依据用户操作全面而准确地获取用户的行为信息;行为信息中包含对应用户查阅的信息的具体行为,具体行表征着对对应信息的兴趣度,为后续基于行为信息的准确分析提供有力支持。进一步的,所述分析处理包括采用分值叠加法进行量化处理。由上述描述可知,通过量化处理使所分析的数据能够更加直观的体现其特征性。进一步的,所述分析处理还包括在量化处理后进行归一化处理。由上述描述可知,通过归一化处理能缩小特征值之间的数据差值,帮助更进一步直观的体现数据的特征性。进一步的,所述分析处理包括:对行为信息中的每个具体行为进行权重划分,确定每个具体行为的权重;根据各个用户的行为信息中每个具体行为的次数进行权重分值叠加,获取各个用户各自对应的一维矩阵;获取由所述多个用户各自的一维矩阵构成的多维矩阵。由上述描述可知,通过对用户的行为信息采用分值叠加法进行量化,对用户的每个行为信息进行权重赋值,并根据行为次数进行分值叠加,则可以根据单个用户的行为信息生成一维矩阵,实现对应单个用户的数据归整,同时又能直观的体现该用户数据的特征性。进一步的,对所述多维矩阵中的每个特征值进行归一化处理。由上述可知,由于对应多个用户信息的多维矩阵中特征值之间的数据差距较大,因此通过归一化处理,能缩小该差距,同时又不影响特征值之间区别的体现。进一步的,所述对所述用户画像进行聚类处理,获取各集群类及其对应的信息集,具体为:对归一化处理后的所述多维矩阵依据聚类算法进行分类,获取包含多个集群类的密集数据矩阵;依据所述每个具体行为的权重,计算获取每个用户相应每个具体行为对应信息的兴趣值;依据所述兴趣值计算获取各个集群类中用户对相应信息的兴趣评分。由上述可知,通过聚类分析,将一个个较为稀疏的用户数据聚类成为多个的数据相对密集的具有相同类特征的集群,获取数据相对密集的矩阵;不仅更具有代表性,而且能有效避免稀疏的数据影响推荐的精准度,从而显著提高推荐精度。进一步的,所述确定与其匹配的集群类,具体为:计算所述一用户的用户画像与所述各个集群类的距离;匹配与所述一用户的用户画像距离最近的集群类;推荐所述集群类对应的信息集中兴趣评分前n名次的信息给所述一用户。由上述可知,能够准确定位目标用户的兴趣特征,并基于该兴趣特征从数据库中确定兴趣特征与其最相近的集群类,然后推荐该集群类中top-n的信息给目标用户,从而准确地推荐目标用户感兴趣的信息,保证推荐信息的精准有效。本发明提供的另一个技术方案为:一种计算机存储介质,其上存储有计算机程序,所述程序在被计算机读取时,能执行上述的用户兴趣信息推荐方法中各个步骤。从上述描述可知,本技术方案的有益效果在于:能够通过处理器调用并执行存储介质中的计算机程序,实现定时线上对多个用户的行为信息进行采集,线下分析生成数据库;能够基于数据库实时地对应单个用户准确地推荐其感兴趣的信息,且保证所推荐的信息的精准有效。实施例一请参照图2,本实施例提供一种基于聚类的协同过滤以推荐用户兴趣信息的方法。本实施例的方法能够在如今大数据技术的背景下,实现对用户个人具有针对性和精确性地推荐其该真实感兴趣的信息,帮助更好的满足用户实际需求,更好的锁定用户,同时又能优化用户体验。本实施例的方法可以定时分析过程以及实时推荐过程。实时推荐的实现依赖于定时分析的结果,定时分析不断更新的数据库能够为实时推荐提供更加精准到位的推荐效果。定时分析过程包括以下步骤:s1:依据预设的时间间隔,采集得到多个(两个以上)用户的行为信息。所述行为信息通过采集用户输入获取,用户输入包括从多个移动端和多个pc端的输入数据;具体通过在移动端以及pc端埋点的方式搜集得到。所述行为信息包括对应一信息的至少一个的具体行为。一信息对应一具体行为,信息包括搜索记录、观看某一文章或某一视频的题材内容等具体数据内容;而具体行为指对应信息包括点击次数、观看时长、是否点赞、是否收藏、是否转发等体现对其兴趣的行为。在一具体实施方式中,以所推荐的信息为课程内容,用户为学员为例进行说明。目的为在学员使用客户端的过程中,能逐步为学员定制出个性化且有针对性的课程,提高学员的学习效率,进而锁定生源。但实际运用时并不仅限于此。在上述课程推荐这一具体实施方式中,单个用户的行为信息指学员在已有的教学系统中进行学习的时候,对课程的点击次数、课程的观看时长、收藏的课程、点赞的课程等一系列能够在一定程度上反映出用户对课程兴趣度的指征。在上述课程推荐这一具体实施方式中,还包括对采集得到的用户输入信息进行离散化处理后进行存储。s2:对行为信息进行分析处理,获取各用户对应的用户画像。可选的,对应单个用户的输入信息进行采集后,将依据分析处理的结果形成一维矩阵,即用户画像。可选的,分析处理为依次采用分值叠加法进行量化处理,以及在量化处理后进行归一化处理。具体的,所述s2可以包括以下步骤:s21:对行为信息中的每个具体行为进行权重划分,确定每个具体行为的权重;如赋值点赞这一具体行为的权重为1,收藏的权重为3,一次点击的权重为1等。s22:根据各个用户的行为信息中每个具体行为的次数进行权重分值叠加,获取各个用户各自对应的一维矩阵;假设对应一用户的行为信息包括具体行为a1、a2、a3三种;对每个具体行为进行权值划分后,每个具体行为对应的权重为w1,w2,w3;该用户对应上述具体行为的行为次数为c1,c2,c3。则可以根据该用户的行为信息生成一维矩阵:j1=[a1*w1*c1,a2*w2*c2,a3*w3*c3](1)s23:获取由所述多个用户各自的一维矩阵构成的多维矩阵。则由多个用户各自对应的用户信息则可得到一个m*n的多维矩阵:jn*m=[j1,j2,j3,j4,j5...jn](2)其中,n为用户的个数,同时对应各个用户信息。s24:对所述多维矩阵中的每个特征值进行归一化处理。由于特征值(构成矩阵的值)之间的数值差距较大,因此可以进行归一化处理。具体的,归一化的方法为:每一个特征值的最大值减去最小值得到归一化分母range,在用每一个特征值去减去该特征的最小值,得到值x,归一化的值就为x/range。s3:对所述用户画像进行聚类处理,获取各集群类及其对应的信息集;由于用户之间的用户画像(上述一维矩阵)较为稀疏,并不具备代表性,若直接据此进行推荐,最终会影响到推荐的精准度。因此,还将对各用户对应的用户画像(上述归一化处理后的多维矩阵)进行聚类分析。其中,所述信息集指的是一集群类内所有行为信息所对应的所有信息的集合。信息的大类包括时事新闻、或娱乐信息、或育儿知识、或购物、或科技、或体育等等;大类下分各个小类,如时事新闻下的政治时事、社会时事等,还可以依据推荐精准度的灵活调控决定是否再进一步往下做细分,甚至是记录数据本身,如对应某一人物的新闻)。具体的,所述s3包括以下步骤:s31:对归一化处理后的所述多维矩阵(假设为jn*m’)依据聚类算法进行分类,获取包含多个集群类的密集数据矩阵kn*m:kn*m=[{j1,j3},{j2,j5},{jn,...,jn-1}](3)s32:依据所述每个具体行为的权重,计算获取每个用户相应各信息的兴趣值;假设用户w的行为信息中包含了指向信息h的多个具体行为,指向信息x的多个具体行为;因此,依据对应具体行为的权重,采用一定算法进行计算,将得到用户w对应信息h的兴趣值,以及对应信息x的兴趣值。兴趣值由具体行为的权重来体现,对应对该具体行为的兴趣程度。s33:依据所述兴趣值计算获取各个集群类中用户对相应信息的兴趣评分。通过对kn*m中每一个子类(集群类)中用户的兴趣值进行计算,获取每一个集群类内所有用户对相应信息(该集群类对应的信息集中包含的各个具体信息)的兴趣评分。可选的,可以对每一个类中用户进行兴趣值叠加计算,叠加结果去除以类中的用户个数,从而得出每一类用户中对相应课程的兴趣评分。可选的,还包括依据评分结果,得出该类的top-m兴趣信息并存储。所述m为预设的整数,若m为5,则top-5兴趣信息为兴趣值排名前5的兴趣信息。在上述课程推荐这一具体实施方式中,即可得出每个集群类中的top-m课程。优选的,上述步骤s1至s3是可以循环往复的过程,循环的过程即不断更新数据库的过程,用户在系统中的使用次数越多,就能够获得更为精准的兴趣信息推荐。之后,还包括:s4:依据一用户的用户画像,确定与其匹配的集群类的步骤。即实时推荐的过程。具体的,实时推荐过程包括以下子步骤:s41:采集一用户的行为信息;具体的,将采集形成步骤s22中对应(1)的一维矩阵;s42:若数据库中已存储有所述一用户的在先行为信息,则通过合并获取所述一用户对应的所有行为信息;具体的,将采集得到的行为信息与已有数据(数据库)中对应该用户的用户数据进行合并,实现数据整合。优选的,每次用户退出系统,将依据登陆过程的操作采集结果生成最新的用户行为信息。s43:对所述所有行为信息进行分析处理,得到所述一用户的用户画像;所述分析处理的具体过程参见上述步骤s2。经过分析处理,将得到新的对应该用户的用户画像,即获取对应该用户的新的一维矩阵。s44:获取与所述一用户的用户画像匹配的集群类;可选的,可以将该用户的新的一维矩阵与上述步骤s31所获取的密集数据矩阵kn*m中的数据进行比较,确定与该新的一维矩阵匹配的集群类。优选的,上述比较的方式为欧式距离。通过欧式距离确定与该用户最相近(与该用户的用户画像距离最近)的集群类。s45:推荐所述匹配的集群类对应的信息集中相应的信息给所述一用户。可选的,推荐所匹配的集群类对应的信息集中兴趣评分前n名次的信息给该用户。即可以直接依据上述步骤s33所存储的每一个集群类的top-m兴趣信息进行推荐。在上述课程推荐这一具体实施方式中,即可直接依据该学员的一维矩阵确定与其兴趣最相近的集群类,再以该集群中兴趣课程的top-n课程对该学员进行推荐。可选的,在步骤s1之前,还可以包括初步推荐步骤:先对用户的兴趣信息进行收集。通过向导的方式对用户进行引导,收集用户学习信息的特征信息。如用户需求的知识点、用户倾向的学习方式以及用户倾向的学习时长等。然后根据用户的兴趣信息对用户进行的初步的课程推荐。实施例二本实施例对应实施例一中课程推荐这一具体实施方式的具体运用场景。一、用户数据量化:以用户ua学习的课程ca举例:ua对课程ca点赞、收藏、观看时长、点击的统计如下表1:课程点赞收藏点击收看时长ca3是8200min表1根据用户行为的权重,进行分值叠加。如点击一次得分为1,点赞为3分,收藏5分。那么结果为下表2:课程点赞分数收藏分数点击分数收看时长ca3*3=951*8200表2同理,用户ua对课程cb、cc的行为评分也可获得。用户a对三个课程的行为量化结果如下表3:课程点赞分数收藏分数点击分数收看时长ca958200cb0011cc35310表3同理,对于多个用户也可采取这样的方式,因此可以得出如上文中描述的多维矩阵。二、对每个变量进行归一化处理归一化结果如下表4课程点赞分数收藏分数点击分数收看时长ca1111cb0000cc0.3310.280.045表4根据特征值权重计算对每个课程兴趣度结果,结果如下表5。cacbccua401.16ub031.1uc30.541.01表5三、用户ua、ub、uc之间距离计算通过欧拉公式可知ua与ub距离:5.025;ua与uc距离:1.3141;ub与uc距离:3.879。因此可以找出离ua距离最近的为uc。同理对于多个用户,可以得出距其最近的k个用户的距离,使其成为多个类cla、clb。clc。并且多个类中对各个课程c的评分也可算出,评分结果如下表6所示。cacbcccla80.22.11clb061.1clc52.661.01表6当某用户使用时,通过对其行为进行实时采集,按照以上步骤进行分析后再计算出与各个类之间的距离,找出离其距离最近的类。根据距离最近类中,课程兴趣度从高到低的顺序产生课程推荐。实施例三请参照图3,本实施例为对应实施例一,提供一种用户兴趣信息推荐系统,包括:数据采集模块1:该模块用于采集用户输入,包括了从多个移动端和多个pc端的输入数据,通过在移动端以及pc端埋点的方式搜集用户信息;并对用户的输入信息进行离散化处理,将数据放入存储模块。数据存储模块2:该模块用于存储进行量化处理后的用户的行为信息,以及经过分析后的数据库。数据分析模块3:该模块对数据存储模块中的行为信息进行定期分析,通过聚类算法以及协同过滤算法生成数据库。其中,聚类是为了使稀疏的个人数据变成密集的数据集,协同过滤是为了根据个人数据去产生推荐数据。课程推荐模块4:该模块可以实时的对个人用户产生兴趣信息推荐,通过数据收集模块中实时收集到的个人用户行为信息,与分析模块中的分析结果进行匹配,通过协同过滤算法产生所要推荐给用户的兴趣信息,并输出。本实施例在教学推荐领域中的具体运用,可实现一种基于协同过滤的推荐的教学系统。具体通过采用了聚类算法,能够解决单个用户的数据稀疏性的问题,使单个用户形成的稀疏矩阵成为具有类特征的密集矩阵,通过具有类特征的集群对单个用户进行协同过滤推荐,使推荐更为精准有效。本具体运用提供的教学系统,是对传统教学系统的补充,能够对学员进行个性化的推荐,使学员能够更易了解到需要学习的课程,完善自身的知识体系。实施例四本实施例对应实施例一提供一种计算机存储介质,其上存储有计算机程序,所述程序在被计算机读取时,能执行上述实施例一的用户兴趣信息推荐方法中的所有步骤。具体步骤不再复述,详情请参阅实施例一。综上所述,本发明提供的一种用户兴趣信息推荐方法、存储介质,不仅能针对用户个人准确地推荐其真实感兴趣的信息;而且还将通过定时分析不断更新的数据库,实现推荐精度的不断提升,进而实现对用户个人的精确推荐;进一步的,本发明还将在课程推荐领域具有良好的运用前景,能够提升学员对课程选择的精准度,同时能够让学员随时能够了解自己知识体系相关的课程内容,从而提高学习效率。以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的
技术领域:
,均同理包括在本发明的专利保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1