基于深度学习的仿生机器孔雀图像识别方法与流程
本发明涉及计算机识别技术领域,具体涉及基于深度学习的仿生机器孔雀图像识别方法。
背景技术:
仿生机器人是仿生学与机器人领域应用需求的结合产物。从机器人的角度来看,仿生机器人则是机器人发展的高级阶段,生物特性为机器人的设计提供了许多有益的参考。目前的仿生机器人种类繁多,如仿生机器鱼,仿生机器狗。并广泛应用在军事和工业领域,但是作为娱乐机器人的应用目前较少。视觉系统是仿生机器人的一个重要组成部分,相当于仿生机器人的“眼睛”。该系统一般通过放置在机器人上的高清摄像头捕捉周围的环境信息,并通过现有的计算机视觉算法对捕获的图像进行分析处理已实现对机器人执行机构的运动控制,如机器鱼的水下打捞,机器狗的步态规划等。目前仿生机器人的视觉系统依赖于传统的图像处理算法,一般为,首先提取当前环境的图像特征然后对提取到的特征进行描述,最后通过特征描述对当前的环境进行识别,检测等相关任务。虽然特定的图像特征在仿生机器人领域取得了较好的效果,但是传统的图像特征更多依赖于人工经验,而且在复杂环境下,特征提取的复杂度高,鲁棒性低。
有鉴于此,急需提供一种鲁棒性好,实时性高的基于深度学习的仿生机器孔雀视觉识别方法应用于科技馆,大型商场,酒店等场所,寓教于乐。
技术实现要素:
为了解决上述技术问题,本发明所采用的技术方案是提供一种基于深度学习的仿生机器孔雀的图像识别方法,包括以下步骤:
s1、采集公开的人脸检测数据库作为训练和验证的图像数据集;
s2、设计基于卷积神经网络的深度学习架构,在深度学习架构内实现人脸检测功能;
s3、采集仿生机器孔雀摄像头所拍摄到的现场图像对训练好的卷积神经网网进行微调;
s4、根据步骤s3中微调后的深度学习架构进行测试,实现室内复杂环境下的人脸检测功能;
s5、根据步骤s4得到的人脸框定位和摄像头距离观众的位置关系,得到经验参数以确定观众的着装定位,并统计各种颜色所占的相应比重。
在上述方法中,所述步骤s1具体包括以下步骤:
s11、人脸检测数据库,选取公开wider_face数据集和celeba_face数据集作为人脸检测的训练样本;将图像数据集中原始图像归一化到一个统一的尺寸;
wider_face数据集和celeba_face数据集中提供了大量的人脸检测数据,并在图中提供了人脸框的位置信息;
s12、随机的对人脸图像选取边框,并计算选取边框与真实边框的重复度iou;
s13、将人脸检测数据分为三类,分别是人脸正样本、人脸负样本、人脸部分样本,其占比重为1:3:1;
s14、将训练样本生成文件路径,并做好与之对应的标签,标签内容包括正、负样本标签以及随机生成边框和真实边框的偏移值。
在上述方法中,所述步骤s12中,iou>0.65为人脸正样本,iou<0.4为人脸负样本;在0.4≤iou≤0.65之间为人脸部分样本。
在上述方法中,所述深度学习架构具体如下:
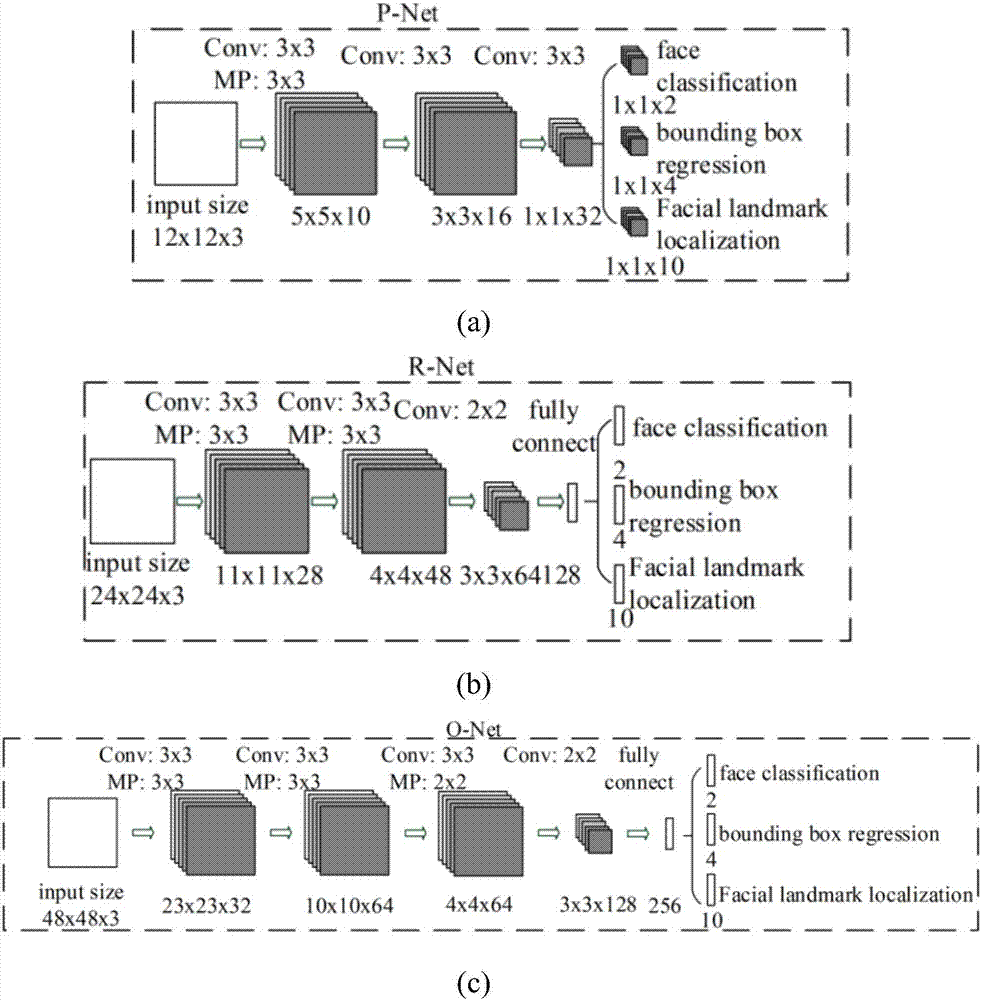
深度学习架构由三个卷积神经网络级联组成,三个卷积神经网络分别为第一卷积神经网络pnet,第二卷积神经网络rnet和第三卷积神经网络onet;
第一卷积神经网络pnet在训练阶段的输入尺寸为12*12*3的图像块,第一卷积神经网络pnet为三层全卷积网络,不包含全连接层;
第二卷积神经网络rnet输入尺寸为24*24*3的图像块,为四层卷积网路包含三个卷积层和一个全连接层;
第三卷积神经网络onet的输入尺寸48*48*3的图像块;为四层卷积网路包含三个卷积层和一个全连接层;
首先将训练样本送入第一卷积神经网络pnet,其输出分别为样本的类别,即人脸正、负样本和人脸定位的预测值;
第二卷积神经网络rnet用来细化pnet网络的输出结果;
第三卷积神经网络onet用来细化rnet网络的输出结果,输出分别为样本的类别,人脸定位的预测值和人脸关键点的预测值。
在上述方法中,所述步骤s3具体包括以下步骤:
s31、选取仿生机器孔雀现场所收集到的包括观众和不包括观众的多张图像分为训练样本和测试样本;选取训练样本中的图像取随机框获得人脸正样本、人脸负样本、和人脸部分样本;
s32、将确定好的训练样本和标签送入深度学习架构,对于深度学习架构中三个卷积神经网络的参数进行微调。
在上述方法中,所述步骤s4具体包括以下步骤:
s41、将测试样本送入第一卷积神经网络pnet,获取候选人脸框以及每个人脸对应的四个点坐标;
s42、将第一卷积神经网络pnet获取并输出的候选人脸框送入第二卷积神经网络rnet,对候选人脸框进行细化筛选并进行非极大值抑制,去除误检;
s43、将第二卷积神经网络rnet筛选并输出结果送入第三卷积神经网络onet,用于进一步对候选人脸框进行细化筛选,去除误检,最后得到人脸检测结果,包括人脸框定位和摄像头距离观众的位置关系。
在上述方法中,所述步骤s5具体包括以下步骤:
s51、根据摄像头多次测量和标定,选取着装候选框在图像中的定位为1.8个人脸框的偏移,着装候选框的大小为2个人脸框;
s52、设定的参与统计比重的颜色有红、黄、蓝、绿、紫、白、黑、灰,根据选取的着装候选框统计各种颜色所占的相应比重。
本发明提出一种基于深度学习的仿生机器孔雀的图像识别方法,旨在实现娱乐仿生机器人在复杂环境下准确高效的人脸检测和颜色识别,鲁棒性好;使用仿生机器孔雀采集到的现场图像对训练好的深度学习架构进行参数微调;最后实现对于摄像头捕捉到的现场图像进行实时人脸检测和着装识别;可以应用于科技馆、酒店、商场、供游客参观、娱乐。
附图说明
图1为本发明提供的流程图;
图2为本发明提供的深度学习架构的结构示意图;其中,
(a)为第一卷积神经网络pnet;(b)为第二卷积神经网络rnet;(c)为第三卷积神经网络onet;
图3为本发明提供的基于深度学习的仿生机器孔雀的图像识别流程框图;
图4为本发明提供的摄像头采集到的图像及统计颜色比重的示例图。
具体实施方式
下面结合具体实施方式和说明书附图对本发明做出详细的说明。
如图1-3所示,本发明提供了一种基于深度学习的仿生机器孔雀的图像识别方法,包括以下步骤:
s1、采集公开的人脸检测数据库作为训练和验证的图像数据集。其中,步骤s1具体如下步骤:
s11、人脸检测数据库,选取公开wider_face数据集和celeba_face数据集作为人脸检测的训练样本。wider_face数据集和celeba_face数据集中提供了大量的人脸检测数据,并在图中提供了人脸框的位置信息,总共可以得到20多万个人脸检测数据。
s12、随机的对人脸图像选取边框,并计算选取边框与真实边框的重复度iou(交并比)。其中,定义iou>0.65为人脸正样本,iou<0.4为人脸负样本;在0.4≤iou≤0.65之间为人脸部分样本。
s13、将人脸检测数据分为三类,分别是人脸正样本、人脸负样本、人脸部分样本,其占比重为1:3:1。
s14、将训练样本生成文件路径,并做好与之对应的标签,标签内容包括正、负样本标签以及随机生成边框和真实边框的偏移值。将图像数据集中原始图像归一化到一个统一的尺寸,如800*600*3。并对每幅有人脸的图像给以标签。如0001.png204301264390表示图像0001.png在矩形像素区域(204,301,264,390)上包含一个人脸,将所有标签都写在一个.txt文件中,图像路径和标签一一对应。
s2、设计基于卷积神经网络的深度学习架构,在深度学习架构内实现人脸检测功能。其中,深度学习架构具体如下:
如图2所示,深度学习架构由三个卷积神经网络级联组成,三个卷积神经网络分别命名为第一卷积神经网络pnet,第二卷积神经网络rnet和第三卷积神经网络onet;第一卷积神经网络pnet在训练阶段的输入尺寸为12*12*3的图像块,第二卷积神经网络rnet输入尺寸为24*24*3的图像块,第三卷积神经网络onet的输入尺寸48*48*3的图像块。
首先将训练样本送入第一卷积神经网络pnet,第一卷积神经网络pnet为三层全卷积网络,不包含全连接层,其输出分别为样本的类别(正、负样本)和人脸定位的预测值。
第二卷积神经网络rnet为四层卷积网路包含三个卷积层和一个全连接层。该网络可以用来细化pnet网络的输出结果。
第三卷积神经网络onet为四层卷积网路包含三个卷积层和一个全连接层。该网络可以用来细化rnet网络的输出结果,输出分别为样本的类别(正、负样本)、人脸定位的预测值和人脸关键点的预测值。
s3、采集仿生机器孔雀摄像头所拍摄到的现场图像对训练好的深度学习架构进行微调。采集到的现场图像包含有观众和没有观众的场景。其中,步骤s3具体如下步骤:
s31、选取仿生机器孔雀现场所收集到的包括观众和不包括观众的10万张图像分为训练样本和测试样本。选取该训练样本中的图像取随机框获得人脸正样本、人脸负样本、和人脸部分样本,具体如步骤s12~s14。
s32、将确定好的训练样本和标签送入深度学习架构,对于深度学习架构中三个卷积神经网络的参数进行微调。
s4、根据步骤s3中微调后的深度学习架构进行测试,实现室内复杂环境下的人脸检测功能。其中,步骤s4具体如下步骤:
s41、将测试样本首先送入第一卷积神经网络pnet,获取候选人脸框以及每个人脸对应的四个点坐标。
s42、将第一卷积神经网络pnet获取并输出的候选人脸框送入第二卷积神经网络rnet,对候选人脸框进行细化筛选并进行非极大值抑制,去除误检。
s43、将第二卷积神经网络rnet筛选并输出结果送入第三卷积神经网络onet,其操作与第二卷积神经网络rnet相同,用于进一步对候选人脸框进行细化筛选,去除误检,最后得到人脸检测结果,包括人脸框定位和摄像头距离观众的位置关系(人脸关键点位置)。
上述三个卷积网络级联的层数逐步加深,卷积核的大小逐步加大,而对人脸的检测也逐步细化。第一卷积神经网络pnet可以得到粗略的人脸候选框,第二卷积神经网络rnet和第三卷积神经网络onet则对于第一卷积神经网络pnet得到候选人脸框逐步筛选并进行非极大值抑制,得到最终的人脸检测结果。
深度学习架构采用多任务学习策略对网络进行优化,由三路监督学习信号组成:a、softmax分类器的交叉损失熵学习输入的图像块是否为人脸。b、矩形框的euclidean回归损失学习矩形框的定位。c、回归损失学习五个人脸关键点的定位。
深度学习架构的构建具体为:
使用caffe开源代码来训练整个网络,使用的计算机配置intelcorei7处理器,显卡配置为nividagtxtitan1080tigpu。操作系统为linuxubuntu16.04。
网络的学习参数为:迭代次数100000次,每次迭代送入的样本数100,初始学习率:0.01,冲量项:0.9,反向传播方式:随机梯度下降法。
s5、根据步骤s4得到的人脸框定位和摄像头距离观众的位置关系,得到经验参数以确定观众的着装定位,并统计各种颜色所占的相应比重。其中,步骤s5具体如下步骤:
s51、根据摄像头多次测量和标定,选取着装候选框在图像中的定位为1.8个人脸框的偏移,着装候选框的大小为2个人脸框大小,如图4所示,为本发明提供的摄像头采集到的图像及统计颜色比重的示例图。本实施例设定仿生机器孔雀的摄像头安装与现场观众的距离为2.5米。
s52、设定的参与统计比重的颜色有红、黄、蓝、绿、紫、白、黑、灰,根据选取的着装候选框统计各种颜色所占的相应比重。
本发明提供的仿生机器孔雀根据所捕获的视觉信息(现场观众人数和着装颜色比重)来做出是否开屏和开屏大小的决策,以实现其娱乐性。
本发明中整个仿生机器孔雀图像识别系统的构建为:
在仿生机器孔雀的头部安装logitechproc920摄像头,作为仿生机器孔雀的“眼睛”捕捉现场的环境画面,其中“眼睛”离观众的距离控制在2.5米左右。
使用visualstdio2013开发环境编写mfc界面程序。将caffe中的训练好的模型文件和网络脚本文件*.caffemodel和*.prototxt放入整个工程中,以实现仿生机器孔雀的人脸检测和着装识别功能。
将图像识别功能的代码封装成sdk库的形式,以方便仿生机器孔雀的其他功能模块的相互调用,如运动执行模块、语音对话模块、人脸识别模块、颜色筛选模块等等,并完成仿生机器孔雀整体功能的测试,以投入科技馆、酒店或商场中的使用,发挥其娱乐性。
本发明提出一种基于深度学习的仿生机器孔雀的图像识别方法,旨在实现娱乐仿生机器人在复杂环境下准确高效的人脸检测和颜色识别且鲁棒性好。首先使用人脸检测库制作卷积神经网络的预训练样本。然后设计卷积神经网络的结构,包括网络卷积层、池化层、全连接层的层数,每一层的参数,如卷积核的个数、大小,全连接层输出的神经元个数,在深度学习架构caffe上编写网络结构和训练的脚本程序。使用仿生机器孔雀采集到的现场图像(包含有观众和无观众)对训练好的深度学习架构进行参数微调。最后编写测试程序,实现对于摄像头捕捉到的现场图像进行实时人脸检测和着装识别。
本发明不局限于上述最佳实施方式,任何人应该得知在本发明的启示下作出的结构变化,凡是与本发明具有相同或相近的技术方案,均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!