一种基于长短期记忆网络的售电量预测方法与流程
本发明涉及售电量预测
技术领域:
,尤其涉及一种基于长短期记忆网络的售电量预测方法。
背景技术:
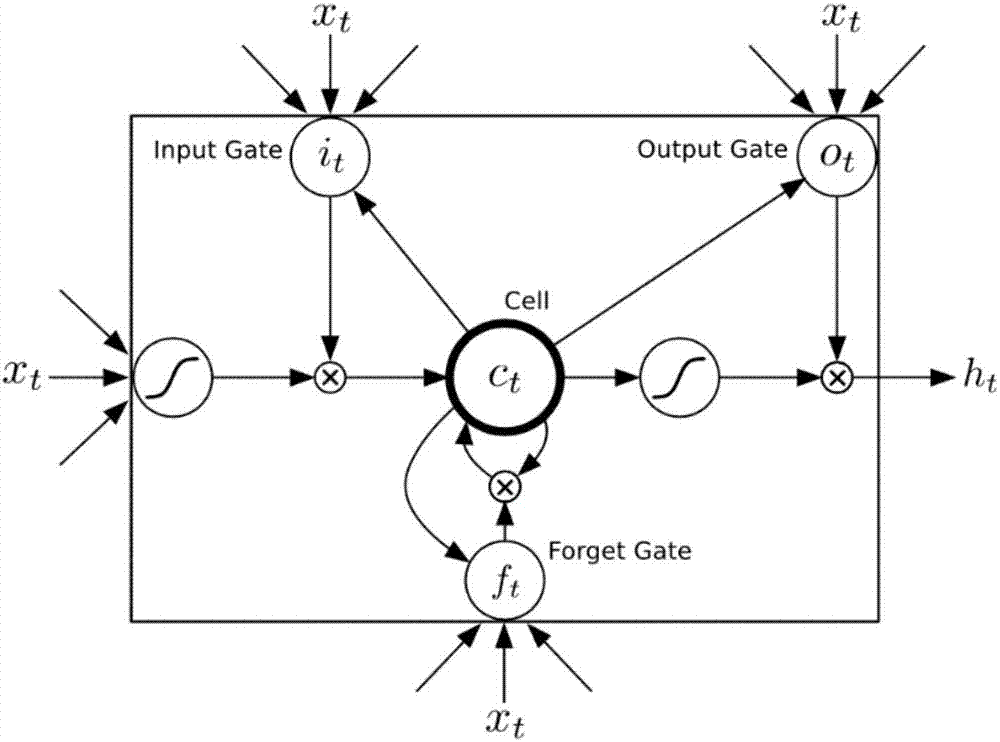
:随着国家经济的高速发展,电力事业也处在大力发展的阶段,准确的售电量预测对供电企业调整未来供电量、优化供电结构、提高电力系统运行安全性等多方面都具有重要意义。售电量预测问题的本质可以归结为时间序列预测问题。时间序列是指将某种统计指标在不同时刻所表示的数值按照其发生的先后顺序排列而成的序列,时间序列数据则是时间序列所反应的实际数据。由于售电量的变化情况不仅仅根据时间轴上售电量本身有关,还与其他额外条件有关,包括周末情况、节假日情况、季节、气温、气候等多个因素有关,因此售电量预测本质上属于多条件时间序列预测问题。时间序列预测通用模型包括经典的自回归模型(ar)、滑动平均模型(ma)以及结合这二者的自回归滑动平均模型arma模型(iietransactions,2015),同时由于时间序列数据通常呈现出非平稳的特点,研究者提出自回归积分滑动模型(arima),其对时间序列数据进行单步或多步差分,使得数据变得平稳(journaloftheamericanstatisticalassociation,1970)。时间序列除了非平稳的特点外,通常还是非线性的,这就导致经典的自回归模型无法很好的进行拟合;针对非平稳非线性的时间序列采用非线性的模型通常会获得更好的效果,研究者提出了基于svm和ls-svm的回归模型(neuralnetworksandbrain,2005);其次,由于神经网络具有以任意精度拟合任意borel可测函数的能力,有学者提出基于神经网络的预测模型(neuralnetworks,1989),此外利用神经网络和arima分别在非线性和线性建模的优势,有学者提出联合神经网络和arima的混合模型(neurocomputing,2003),在时间序列上取得了较好的预测结果。然而,以上预测方法通常难以有效地提取到好的特征,这使得时间序列预测结果的准确度往往不高。深度学习是近几年提出的一种非常有效的提取特征的方法(nature,2015),其中循环神经网络(rnn)模型主要应用于处理序列类问题,它基于循环的网络结构能够充分利用序列数据本身的序列信息,发现序列的内在规律和特征。chen等(ieeeinternationalconferenceonbigdata,2015)利用循环神经网络进行股票预测;sutskever等(internationalconferenceonmachinelearning,2011)利用循环神经网络进行文本生成;gregor等(internationalconferenceonmachinelearning,2015)利用循环神经网络将图片在序列上建模自动进行图片生成。但是,rnn存在梯度消失的问题导致无法很好的利用长期历史信息。技术实现要素:本发明为了解决上述问题,提供了一种基于长短期记忆网络的售电量预测方法,其能够自动学习售电量数据以及相关影响因素的数据特征,基于长短期记忆网络对多条件售电量数据进行建模,实现对售电量的准确预测。为了解决上述问题,本发明采用以下技术方案予以实现:本发明的一种基于长短期记忆网络的售电量预测方法,包括以下步骤:s1:确定影响售电量数据的影响因素;s2:计算每个待分析行业的售电量数据与每个影响因素数据的pearson相关系数r,构建相关系数矩阵;s3:使用k-means聚类算法,对以上各个行业的pearson相关系数r进行聚类,聚类之后得到若干个簇,每个簇包含了若干个行业,每个簇作为一个子集,然后将每一个簇中所有行业的售电量数据按日期进行累加,得到每个簇的日总用电量数据;s4:对每个簇的日总用电量数据进行归一化处理,对影响因素数据进行归一化处理;s5:建立基于长短期记忆网络lstm的售电量预测模型,将归一化处理后的每个簇的日用电量数据以及影响因素数据作为售电量预测模型的输入进行训练,以m天作为训练数据时间步长,构建3维输入张量,形状为(batchsize,timestep,features),其中batchsize为样本输入batch大小,timestep为时间步长,features为总特征个数,得到每个簇的售电量预测结果,将所有簇的售电量预测结果求和,得到总的售电量预测结果。在本技术方案中,由于售电量涉及多个产业,每个产业又包括多个行业,每个行业在售电量方面都有各自的影响因素,需要对各个行业进行分类处理,因此,先计算每个待分析行业的售电量数据与每个影响因素数据的相关性,相关性采用pearson相关系数r作为评价依据,如:售电量数据与气温数据的相关性、售电量数据与gdp数据的相关性、售电量数据与投资数据的相关性、售电量数据与日期数据的相关性。然后对售电量数据及其影响因素数据归一化处理,最后基于长短期记忆网络lstm的售电量预测模型得到总的售电量预测结果。作为优选,所述pearson相关系数r的计算公式如下:其中,r表示pearson相关系数,取值范围为[-1,1],r=0表示不相关,r值越接近1则正相关性越大,r值越接近-1则是负相关性越大;x和y为两个数据特征变量;cov(x,y)表示协方差,σx,σy表示标准差。作为优选,所述步骤s3中的k-means聚类算法过程如下:输入:售电量数据与每个影响因素数据的pearson相关系数r集合d={x1,x2,...,xm},xi表示第i个行业的相关系数向量,其中的每一维表示与售电量数据相关的影响因素,m表示行业个数,聚类簇数是k;输出:k个聚类簇。作为优选,所述步骤s4中归一化处理的计算公式如下:其中,x为每一类数据的原始数值,xmin为每一类数据的最小值,xmax为每一类数据的最大值,x*为该类数据计算得到的归一化数值。作为优选,所述步骤s5中建立基于长短期记忆网络lstm的售电量预测模型的方法包括以下步骤:设售电量时间序列数据为x=(xt,x2,...,xt-1,xt),xt是t时刻的售电量,则售电量预测问题即是根据已知时间序列数据x求得xt+1时刻的最大似然估计p(x):在多条件时间序列情况下,公式(3)变成如下形式:其中xt表示t时刻的售电量,表示t时刻的第i个影响因素的值;公式(3)与公式(4)是售电量预测的目标,lstm-rnn网络中通过以输入门、遗忘门、输出门控制历史信息的遗忘和记忆来提取序列数据的特征规律,最终输出预测结果,t时刻计算过程如下:it=sigmoid(wxixt+whiht-1+wcict+bi)ft=sigmoid(wxfxt+whfht-1+wcfct+bf)ct=ftct-1+ittanh(wxcxt+whcht-1+bc)ot=sigmoid(wxoxt+whoht-1+wcoct+bo)ht=ottanh(ct)其中,i,f,o分别表示输入门、遗忘门、输出门;c表示记忆单元cell;h表示隐层输出;w表示连接权重,其下标表示权重关联项;b为偏置项。根据i,f,o在[0,1]范围的取值,来控制历史信息通过门结构的比例,lstm记忆单元的门结构使得循环神经网络能够学习长间隔历史信息。本发明的有益效果是:通过所设计的数据特征选择、数据归一化处理过程以及长短期记忆网络,能够自动学习售电量数据以及相关影响因素的数据特征,实现对售电量的准确预测,提高售电量预测的准确性。附图说明图1是本发明的基于长短期记忆网络的售电量预测流程图;图2是长短期记忆单元结构图。具体实施方式下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。实施例:本实施例的一种基于长短期记忆网络的售电量预测方法,如图1所示,包括以下步骤:s1:确定影响售电量数据的影响因素;s2:计算每个待分析行业的售电量数据与每个影响因素数据的pearson相关系数r,构建相关系数矩阵;pearson相关系数r的计算公式如下:其中,r表示pearson相关系数,取值范围为[-1,1],r=0表示不相关,r值越接近1则正相关性越大,r值越接近-1则是负相关性越大;x和y为两个数据特征变量;cov(x,y)表示协方差,σx,σy表示标准差;通过以上计算结果可以知道两个数据特征变量之间是否相关,如:售电量数据与气温数据的相关性、售电量数据与gdp数据的相关性、售电量数据与投资数据的相关性、售电量数据与日期数据的相关性;s3:使用k-means聚类算法,对以上各个行业的pearson相关系数r进行聚类,聚类之后得到若干个簇,每个簇包含了若干个行业,相同簇中的行业的售电量数据对某些影响因素数据具有一定的相似性,每个簇作为一个子集,然后将每一个簇中所有行业的售电量数据按日期进行累加,得到每个簇的日总用电量数据;k-means聚类算法过程如下:输入:售电量数据与每个影响因素数据的pearson相关系数r集合d={x1,x2,...,xm},xi表示第i个行业的相关系数向量,其中的每一维表示与售电量数据相关的影响因素,m表示行业个数,聚类簇数是k:输出:k个聚类簇;步骤:(1)从相关系数集合d中随机选取k个行业的相关系数向量作为初始均值向量μ={μ1,μ2,...μk},其中μi是第i个行业的相关系数向量;(2)do;(3)令(4)forj=1,2,...,mdo;(5)计算xj与μi的距离,根据距离最近的均值向量确定xj的簇划分;(6)endfor;(7)fori=1,2,3,...,kdo;(8)计算新均值向量μi;(9)如果μ′i!=μi则更新μi否则保持不变;(10)while(μ不再更新);s4:对每个簇的日总用电量数据进行归一化处理,对影响因素数据进行归一化处理;由于售电量数值与影响因素的数值相差较大,故必须对这些数据进行归一化处理,其方法是将各类数值缩放到同一尺度,归一化处理的计算公式如下:其中,x为每一类数据的原始数值,xmin为每一类数据的最小值,xmax为每一类数据的最大值,x*为该类数据计算得到的归一化数值;s5:建立基于长短期记忆网络lstm的售电量预测模型,将归一化处理后的每个簇的日用电量数据以及影响因素数据作为售电量预测模型的输入进行训练,以m天作为训练数据时间步长,根据以上数据模型构建3维输入张量,形状为(batchsize,timestep,features),其中batchsize为样本输入batch大小,timestep为时间步长,features为总特征个数,得到每个簇的售电量预测结果,将所有簇的售电量预测结果求和,得到总的售电量预测结果。由于售电量涉及多个产业,每个产业又包括多个行业,每个行业在售电量方面都有各自的影响因素,需要对各个行业进行分类处理,因此,先计算每个待分析行业的售电量数据与每个影响因素数据的相关性,相关性采用pearson相关系数r作为评价依据,如:售电量数据与气温数据的相关性、售电量数据与gdp数据的相关性、售电量数据与投资数据的相关性、售电量数据与日期数据的相关性。然后对售电量数据及其影响因素数据归一化处理,最后基于长短期记忆网络lstm的售电量预测模型得到总的售电量预测结果。步骤s5中建立基于长短期记忆网络lstm的售电量预测模型的方法包括以下步骤:设售电量时间序列数据为x=(xt,x2,...,xt-1,xt),xt是t时刻的售电量,则售电量预测问题即是根据已知时间序列数据x求得xt+1时刻的最大似然估计p(x):在多条件时间序列情况下,公式(3)变成如下形式:其中xt表示t时刻的售电量,表示t时刻的第i个影响因素的值;公式(3)与公式(4)是售电量预测的目标,lstm-rnn网络中通过以输入门、遗忘门、输出门控制历史信息的遗忘和记忆来提取序列数据的特征规律,最终输出预测结果,lstm记忆单元结构如图2所示,使用lstm网络使得在模型层次深度加深后避免梯度消失的问题,t时刻计算过程如下:it=sigmoid(wxixt+whiht-1+wcict+bi)ft=sigmoid(wxfxt+whfht-1+wcfct+bf)ct=ftct-1+ittanh(wxcxt+whcht-1+bc)ot=sigmoid(wxoxt+whoht-1+wcoct+bo)ht=ottanh(ct)其中,i,f,o分别表示输入门、遗忘门、输出门;c表示记忆单元cell;h表示隐层输出;w表示连接权重,其下标表示权重关联项,例如wxi表示从输入层到输入门的连接权重;b为偏置项。根据i,f,o在[0,1]范围的取值,来控制历史信息通过门结构的比例,lstm记忆单元的门结构使得循环神经网络能够学习长间隔历史信息。以某市第二产业与第三产业中总共10个行业的售电量为例,示例数据信息详见下表1所示,表1产业售电量历史数据行业名称行业代码时间跨度数据总量贵金属矿采092020150101--20170525870条石棉及其他非金属采矿109020150101--20170525870条电信601020150101--20170525870条房地产开发经营721020150101--20170525870条公路旅客运输521020150101--20170525870条有色金属压延加工355020150101--20170525870条结构性金属制品制造341020150101--20170525870条切削工具制造342120150101--20170525870条其他金属工具制造342920150101--20170525870条金属丝绳及其制品制造344020150101--20170525870条以表1中的电信行业为例,其售电量数据如表2所示,表2电信行业售电量数据结合各个行业售电量数据,考虑节假日情况、季度情况、日平均气温三个影响因素,进一步说明本发明的具体实施方式,步骤如下:s1:确定影响售电量数据的影响因素为节假日、季度、日平均气温;s2:计算每个上述10个行业的售电量数据与每个影响因素数据的pearson相关系数r,构建相关系数矩阵;如:计算电信行业售电量数据与节假日的相关系数r、电信行业售电量数据与季度的相关系数r、电信行业售电量数据与日平均气温的相关系数r,得到以下相关系数矩阵,其中,第一列表示电信行业售电量数据与节假日的相关系数,第二列表示电信行业售电量数据与季度的相关系数,第三列表示电信行业售电量数据与日平均气温的相关系数;s3:使用k-means聚类算法,对以上10个行业的pearson相关系数r进行聚类,设簇个数为2,聚类结果如下:簇1包含的行业编号:0920,1090,7210,5210,3350,3421,3429,3440;簇2包含的行业编号:1090,3410;将每一个簇作为一个行业子集,然后将每一个簇中所有行业的售电量按日期进行累加,得到该簇的日总用电量数据,最后得到共计2个行业特征集合;s4:由于售电量数值与节假日、季度或日平均气温的数值相差较大,故必须对这些数据进行预处理,其方法是将各类数值缩放到同一尺度,采用的缩放方式为min-max归一化,此操作会将所有维度的数据在数值上缩放到[0,1]之间;以日平均气温为例进行说明:从2015年01月01日至2017年05月25日总计870天的日平均气温,最大气温值为33.5度,最小气温值为-2.5度,对每一个气温数据按公式(2)进行缩放得到的结果如表3所示,表3日平均气温归一化处理结果s5:建立基于长短期记忆网络lstm的售电量预测模型,将归一化处理后的每个簇的日用电量数据以及影响因素数据作为售电量预测模型的输入进行训练,以90天作为训练数据时间步长,根据以上数据模型构建3维输入张量,形状为(batchsize,timestep,features),其中batchsize为样本输入batch大小,timestep为时间步长,features为总特征个数,本示例中batchsize为1,timestep为90,features为4,模型详细参数如下表4所示,表4售电量预测模型训练参数超参数名称具体设置lstm层数2lstm隐藏单元数100学习算法rmsprop学习率0.001损失函数msedropout率0.5批次大小(batchsize)128时间步长90迭代次数500售电量预测模型的输入为上述3维张量,模型的输出为未来的售电量数据,由于当前聚类簇的数量为2,由此训练得到2个预测模型;在预测阶段使用与训练阶段相同的数据预处理过程,构建3维输入张量,其形状为(1,90,4),将数据输入至售电量预测模型中,最终结果是将以上2个预测模型的预测结果进行求和累计,得到总的售电量预测结果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1