一种基于深度学习技术的血红蛋白动态光谱分析预测方法与流程
本发明属于数据分析处理技术领域,涉及一种基于深度学习技术的血红蛋白动态光谱分析预测方法。
背景技术:
人体血红蛋白浓度是诊断贫血症(hb偏低)以及真性血红蛋白增多症(hb偏高)的可靠依据之一。当人体血红蛋白浓度低于正常范围时则为贫血。据世界卫生组织统计,目前全球大约有20亿人患有不同程度的贫血。造成贫血的因素主要包括骨髓造血功能障碍、造血物质缺乏或利用障碍、溶血性贫血、创伤造成的失血过多以及一些生理性原因等。另一方面,当血红蛋白水平高于正常范围时,也反映着一些疾病的存在,如心肺疾病、肾脏疾病、肿瘤疾病、慢性高原病等。血红蛋白减少与增多都反映了被测者在健康状况上的相应变化,检测血红蛋白浓度可以用来分析被测者的健康情况。
现有的血红蛋白检测技术需要对待测患者进行穿刺采样,增加了患者感染的风险,同时降低了患者的医疗体验;样本采集与分析之间存在时延难以对重症患者进行实时监测。可见利用动态光谱的方法具有无创、检测速度快、成本低、操作简单等优点。利用动态光谱分析技术能快速准确地测定血红蛋白的浓度,是传统方法所不能达到的,在测量的过程中也不需额外添加试剂,操作简单不会造成环境的污染,也不会增加测定的成本,是一种无创、无污染、检测速度快、实时性高的检测分析技术,将动态光谱分析技术应用于血红蛋白检测领域具有十分重要的现实意义。利用深度学习的技术,让机器自动拟合数据特征减少了人为进行回归分析所带来的误差,增加了测量的准确度。因此利用动态光谱分析技术实现对血红蛋白浓度的综合数据分析已经成为亟需解决的技术问题。
技术实现要素:
本发明的目的是为了解决现有技术中无法对血红蛋白浓度进行自动综合分析的缺陷,提供一种基于深度学习技术的血红蛋白动态光谱分析预测方法来解决上述问题。
本发明是这样实现的:
一种基于深度学习技术的血红蛋白动态光谱分析预测方法,步骤如下:
深度学习训练数据的获得与预处理:使用光谱仪获取患者的动态光谱数据,对获取的动态光谱数据进行预处理,得到若干个训练样本,同时根据医院的诊断情况对样本进行标记;
构建深度学习模型;
深度学习测试数据的获得:数据获取与获取训练数据方法相同;
将预处理过后的训练数据、测试数据和相应标签输入进深度学习模型,完成对深度学习模型的训练与评价;
将待测数据输入训练好的深度学习模型,即可得到相应的预测结果。
所述的训练样本的获取和预处理包括以下步骤:
患者将手指放进动态光谱仪中,获取不同患者的光电容积脉搏波;
对获得的光电容积脉搏波进行低通滤波,去除高频噪声;
对光电容积脉搏波去除基线漂移,同时保留未去基线漂移的数据;
对提取的光电容积脉搏波进行归一化处理;同时保留未归一化的数据。
利用光电容积脉搏波提取动态光谱信息;
上述对光电容积脉搏波去除基线漂移方法:利用小波分析或者emd(经验模态分解)去除光电容积脉搏波中的低频的呼吸波成份以及手指的偶然抖动的低频部分。
上述利用光电容积脉搏波提取动态光谱的方法:
式中δc为吸光度,即动态光谱幅值;imax为光电容积脉搏波最大值;imin为光电容积脉搏波最小值。
上述归一化方法:
其中,
上述深度学习模型是基于改进的神经网络模型,对输入进行自动特征提取,神经网络的最后一层为预测层采用全连接的方式,利用one-hot的形式判断疾病类型同时输出具体的血红蛋白浓度的预测数值。
附图说明
图1是本发明的方法流程图;
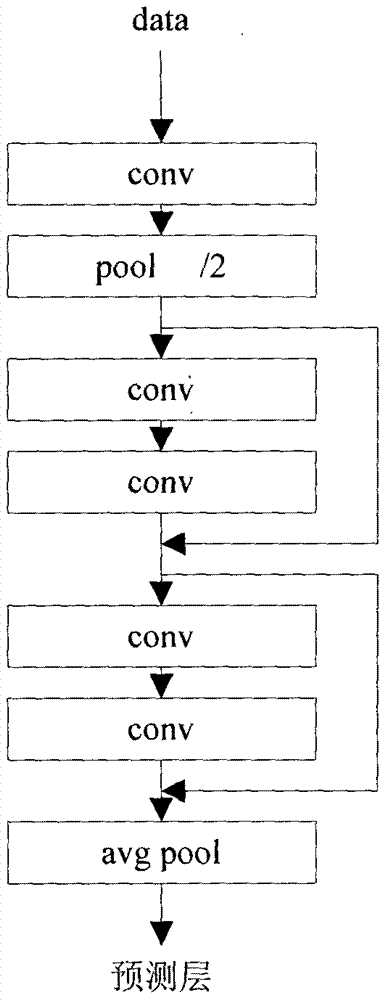
图2是本发明中resnet网络结构示意图;
图3是本发明中one-hot形式的示意图;
图4是本发明中卷积网络(conv)结构示意图;
图5是本发明中池化结构(pool)示意图;
图6是本发明中resnet短接方法示意图。
具体实施方式
下面结合附图对本发明做进一步说明。
如图1所示,一种基于深度学习技术的血红蛋白动态光谱分析预测方法包括如下步骤:
1.深度学习训练数据的获得与预处理,用光谱仪获取患者的动态光谱数据,对获取的动态光谱数据进行预处理,得到若干个训练样本,同时根据医院的诊断情况对样本进行标记。具体包括如下步骤:
(1)患者将手指放入光谱仪中,测量患者的光电容积脉搏波。
(2)对获得的光电容积脉搏波进行低通滤波,去除高频噪声。
(3)运用小波分析或者emd去除基线漂移,同时保留未去基线漂移的数据。即利用小波分析或者emd去除信号中所包含的低频的呼吸波成份以及手指抖动所造成的低频成份。
(4)利用如下公式提取动态光谱:
式中δc为吸光度,即动态光谱幅值;imax为光电容积脉搏波最大值;imin为光电容积脉搏波最小值。
(5)利用如下公式对动态光谱进行归一化,本发明采用矢量归一化:
其中,
(6)将每一条数据的医院诊断结果利用相应标签进行标记,标签形式为one-hot形式,如图3所示。
如图3所示,本发明的标签形式采用one-hot形式。输出层的每一个神经元对应着一种病症,例如,当第一个神经元被激活其他神经元均未被激活时对应贫血1度,当最后一个神经元被激活其他神经元未被激活时对应慢性高原病3度,以此类推。输出层每一个神经元代表不同的病症,这种方法能够有效提升预测的准确性。因此本发明的输出层采用softmax函数作为判决函数以支撑one-hot标签形式。
(7)由经过去基线漂移的信号所对应的动态光谱数据,未去基线漂移的信号所对应的动态光谱数据,归一化后的动态光谱数据,未归一化的动态光谱数据共同组成训练集。这种方式可以有效提高深度学习模型的抗干扰能力,增加模型的泛化能力,提升预测的准确度。
(8)测试数据获取按上述(1)~(7)步骤进行,采用与训练集不同的患者数据。
2.构建深度学习模型。其过程包括:
(1)将未加标签的动态光谱数据作为输入,对深度学习模型进行预训练。
(2)将上述训练集数据和相应标签作为输入,对深度学习模型进行正式训练。
(3)深度学习模型进行前向传播,如图2所示,步骤如下:
a.数据经过卷积层(conv)进行自动的特征提取,卷积层原理如图4所示,图中每一个方框代表一种特征。卷积层能够有效地自动提取信号的特征。并且,利用卷积层的局部感受野的特性,机器能够有效地学习有扰动的信号的本质特征,可以有效提升预测的准确性。为了保持维度的相同,本发明利用补0(padding)的方法保持数据维数的恒定。同时,卷积利用了共享权重的方法,简化了模型参数,使其便于优化。
b.提取后的特征经过池化层(pool),池化原理如图5所示。如图2所示,本层池化层采用最大值池化。经过池化,数据数量变为原来的1/2。池化层可以达到提炼特征,减少模型规模便于优化的目的。
c.经过若干卷积层,进行充分的特征提取。如图2所示,本发明所采用的深度学习模型为有“短接”的resnet模型,“短接”原理由图6所示。“短接”的使用,能够有效降低由于层数过多引起的梯度爆炸问题,能够有效地提升模型的深度,增加预测的准确度。
d.经过平均池化层。
(4)深度学习模型进行反向传播。根据输出层代价函数的梯度反向计算每一层的梯度,利用梯度进行全局参数的优化,最终使代价函数达到最小,即使输出向量与目标向量偏差最小。
3.评价深度学习模型。
深度学习模型的质量应进行具体的量化,因此本发明采用交叉熵对深度学习模型进行评价,交叉熵表达式如下:
式中n为输出向量数目;y为目标输出向量;a为实际输出向量。loss为代价函数,交叉熵描述了两个向量的相似程度,两个向量越相似交叉熵代价函数越小,即实际输出与预期输出越相近。因此利用交叉熵代价函数能够很好地评价深度学习模型的质量。评价也可以利用各种正则化后的代价函数。
4.利用动态光谱数据进行预测。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理和最优解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理和最优实施例之一,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!