一种基于无监督聚类和度量学习的迁移学习方法与流程
本发明涉及迁移学习的
技术领域:
,尤其涉及到一种基于无监督聚类和度量学习的迁移学习方法。
背景技术:
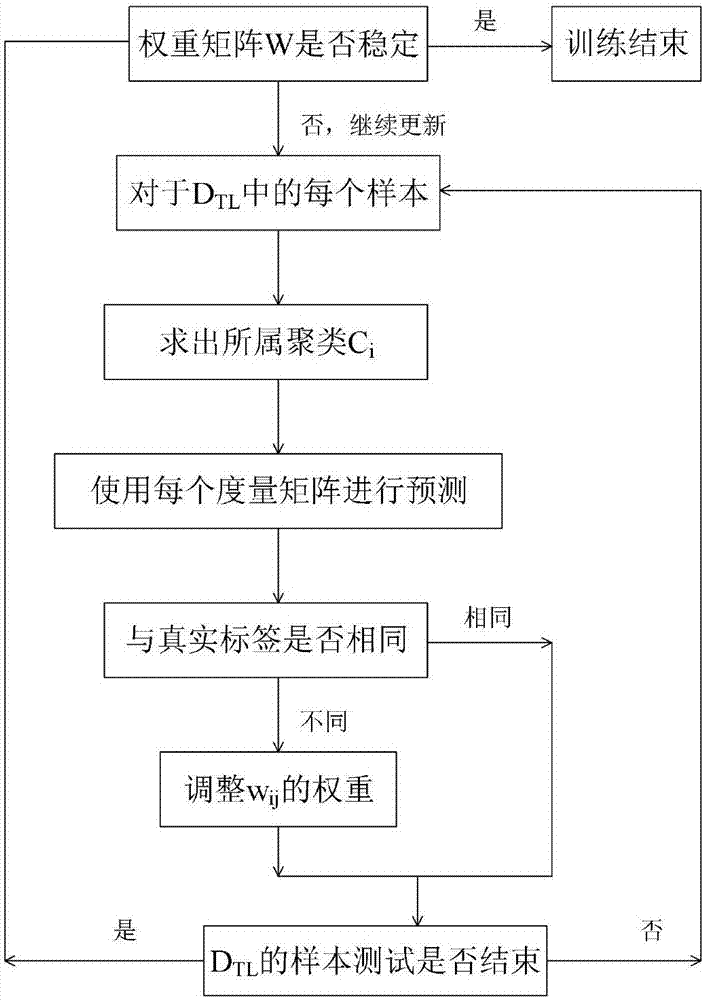
:迁移学习用于解决训练样本(源域)和测试样本(目标域)的分布不一致问题。知识迁移在现实生活中广泛存在,例如,学会打羽毛球之后要学习打网球,学会削苹果之后要学习削梨子,学会辨识猫之后要学习如何辨识狗,这些知识相似、但不相同。如何最大化地利用已有的知识,从而以最快、最有效的方式来学习新知识,是迁移学习的主要难点。人类需要有知识迁移的能力,机器人也是如此。RoboBrain是由来自于斯坦福大学、康奈儿大学等高校的教授主导的项目,其核心目标就是为机器人赋予知识迁移的能力。人类之所以能够不断掌握新知识,其主要原因就是能够举一反三、迁移知识,这种能力也是“机器换人、智能制造”要解决的难题之一。深度学习的优势是从复杂环境里提取特征,但是却不具备迁移能力。AlphaGo的核心是深度学习和强化学习,但是,如果比赛前突然改变围棋的盘面大小,AlphaGo就无法适应,而人类却可以自如地应对。近年来,迁移学习已经成为人工智能、机器人等领域的核心研究问题。已有的迁移学习技术主要是基于特征、基于实例、或者基于度量。基于特征的方法尝试通过学习特征或子空间来匹配源域和目标域。基于实例的方法主要是调整源域实例的权重从而减少源域和目标域的数据分布之间的差异。这些技术以欧氏距离为基础,不能够获得样本维度之间的相关性。但是,样本的不同维度之间却存在关联,例如,人的身高和体重、人的性别和爱好之间可能存在某种关联,这种关联会影响到整体的特征。度量学习考虑了样本的维度之间的相关性。基于度量学习的迁移学习方法相对较少,已有的方法仅仅考虑样本的标签,忽视了样本特征所蕴含的本质属性。例如,动物的体重可以划分为多个档次,如small、medium、big等等。30~50公斤的猪(样本)可以算作small,但是,同样体重的狗(样本)却可以算作medium。所以,在这种情况下样本的特征更能够反应其本质属性。因此,将聚类与度量学习相结合,更有利于在迁移情况下预测样本的标签。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种基于无监督聚类和度量学习的迁移学习方法,其既考虑样本维度之间的相关性、又考虑样本特征所隐含的本质属性,使源域知识能更好地迁移到目标域。为实现上述目的,本发明所提供的技术方案为:包括以下步骤:S1、准备源域样本DS和目标域样本DT;源域样本指过去的样本,目标域样本指当前要预测的样本。由于这两类样本的分布存在一定的区别,所以不可以仅仅使用源域样本来训练预测模型。另外,如果对全部的目标域样本DT都人工贴标签,其工作量太大。所以,本方案是先给一小部分的目标域样本贴标签,然后结合DS来为DT训练新的预测模型。所述目标域样本DT分成两部分:DT={DTL∪DTU},就样本数量来说,DTL<<DTU。DTL的标签已知,该标签由人工赋予,DTU的标签未知。训练集为T,T={DS∪DTL}。S2、使用主成份分析方法降低全部样本的维度;在图像识别等领域,样本往往高达数万维甚至更多,计算度量矩阵也就变得十分复杂。如何既有效地降低样本的维度、又保留原始数据的本质特征,这是该步骤需要解决的问题。S3、对源域样本DS进行无监督聚类,将源域样本聚为多个类别,本质相似的样本聚在一起;S4、为每个聚类学习一个度量矩阵G;对于每个聚类,在学习度量矩阵之前都需要将样本的顺序打乱,其目的是让选中的样本更具有随机性。S5、通过每个聚类和所有的度量矩阵的关联性得出权重矩阵w0;S6、根据已知标签的目标域样本DTL训练权重矩阵w0,得到最优的权重矩阵W;S7、根据权重矩阵W预测未知标签的目标域样本DTU的标签。进一步地,步骤S4中,度量矩阵G为对称矩阵,其初始值G0设置为单位矩阵,对角线元素为1,其余全部为0。G0在经过许多次迭代更新后就趋于稳定。学习度量矩阵G之前需设置收敛条件:||G-G0||<Lamda,其中,G0为度量矩阵G的初始值,Lamda为设定的阈值,||G-G0||表示G和G0之间距离;求解度量矩阵G的目标函数的公式如下:subjecttodG(xi,xj)≤α(i,j)∈S,dG(xi,xj)≥β(i,j)∈D该公式反应了:不同类的样本之间距离大、同类样本之间的距离小。其中,xi、xj指其中的某个样本,S表示xi与xj同类,D表示xi与xj不同类;p(x;G)表示度量矩阵G下的样本x的概率分布;α和β为设定的阈值。阈值α和β的设置方式为:从训练集里任意选取100个样本对,并且将它们之间的距离按从小到大的顺序排列,排第5的距离值为α,排第95的距离值为β。进一步地,步骤S6的具体过程如下:S61、求出每个已知标签的目标域样本DTL的所属聚类Ci;S62、使用每个度量矩阵进行预测,若结果与真实标签相同,则不需要调整,若结果与真实标签不相同,则调整聚类Ci和该度量矩阵所对应元素的权重;直至所有已知标签的目标域样本DTL均已测试;S63、若经所有已知标签的目标域样本DTL测试后的权重矩阵w0满足收敛条件,则训练结束,该权重矩阵即为最优的权重矩阵W;否则继续使用DTL更新权重矩阵,直至满足收敛条件为止。权重矩阵w0满足收敛条件后,对于w0的每个元素wij(1≤i,j≤n)均执行归一化操作,公式如下:进一步地,步骤S7的具体过程如下:S71、求出每个未知标签的目标域样本DTU各自所属的聚类Ct;S72、使用全部的度量矩阵预测样本i的类型;S73、使用KNN分类器进行分类得出分类值;S74、若分类值大于阈值threshold,则预测样本i的标签值为Label1,否则预测样本i的标签值为Label2;其中,threshold=(Label1-Label2)/NumOfCategory,NumOfCategory为标签种类。与现有技术相比,本方案原理如下:先准备源域样本DS和目标域样本DT,再使用主成份分析方法降低全部样本的维度,然后对源域样本DS进行无监督聚类,将源域样本聚为多个类别,本质相似的样本聚在一起,再为每个聚类学习一个度量矩阵G,通过每个聚类和所有的度量矩阵的关联性得出权重矩阵w0,并根据已知标签的目标域样本DTL训练权重矩阵w0,得到最优的权重矩阵W,最后根据权重矩阵W预测未知标签的目标域样本DTU的标签。与现有技术相比,本方案优点如下:1、使用主成份分析方法来降低样本的维度,从而降低后续计算的复杂度。2、使用无监督聚类方法将样本聚为多个类别,从而更能够反应样本的本质特性。3、使用带标签的目标域样本来学习权重矩阵,从而更符合目标域样本的实际情况。附图说明图1为本发明实施例的流程图;图2为本发明实施例中权重矩阵的训练流程图;图3为本发明实施例中预测目标域样本标签的流程图。具体实施方式下面结合具体实施例对本发明作进一步说明:参见附图1所示,本实施例所述的一种基于无监督聚类和度量学习的迁移学习方法,包括以下步骤:S1、准备源域样本DS和目标域样本DT;目标域样本DT分成两部分:DT={DTL∪DTU},DTL<<DTU,DTL的标签已知,该标签由人工赋予,DTU的标签未知。训练集为T,T={DS∪DTL};S2、使用主成份分析方法降低全部样本的维度;S3、对源域样本DS进行无监督聚类,将源域样本聚为多个类别,本质相似的样本聚在一起;S4、每个聚类学习一个度量矩阵G;对于每个聚类,在学习度量矩阵之前都需要将样本的顺序打乱,如使用randperm函数(以Matlab为例),其目的是让选中的样本更具有随机性;另外,设置收敛条件:||G-G0||<Lamda,其中,G0为度量矩阵G的初始值,Lamda为设定的阈值,||G-G0||表示G和G0之间距离;求解度量矩阵G的目标函数的公式如下:subjecttodG(xi,xj)≤α(i,j)∈S,dG(xi,xj)≥β(i,j)∈D其中,xi、xj指其中的某个样本,S表示xi与xj同类,D表示xi与xj不同类;p(x;G)表示度量矩阵G下的样本x的概率分布;α和β为设定的阈值。阈值α和β的设置方式为:从训练集里任意选取100个样本对,并且将它们之间的距离按从小到大的顺序排列,排第5的距离值为α,排第95的距离值为β。S5、通过每个聚类和所有的度量矩阵的关联性得出权重矩阵w0;每个聚类都和所有的度量矩阵相关联,如表1所示:表1权重矩阵w0={wij,i=1,2,…,n,j=1,2,…,n},如表2所示:w11w12…w1nw21w22…w2n…………wn1wn2…wnn表2n为聚类数目;权重矩阵w0的初始值为对角矩阵,如表3所示:10…001…0…………0001表3S6、根据已知标签的目标域样本DTL训练权重矩阵w0,得到最优的权重矩阵W;如图2所示,具体步骤如下:S61、求出每个已知标签的目标域样本DTL的所属聚类Ci;S62、使用每个度量矩阵进行预测,若结果与真实标签相同,则不需要调整,若结果与真实标签不相同,则调整聚类Ci和该度量矩阵所对应元素的权重;直至所有已知标签的目标域样本DTL均已测试;S63、若经所有已知标签的目标域样本DTL测试后的权重矩阵w0满足收敛条件,则训练结束,该权重矩阵即为最优的权重矩阵W;否则继续使用DTL更新权重矩阵,直至满足收敛条件为止。其中,w0的收敛条件为||ws+1-ws||<Sigma,Sigma为一个很小的正数,ws表示第s次迭代后的权重矩阵;权重矩阵w0满足收敛条件后,对于w0的每个元素wij(1≤i,j≤n),均执行归一化操作,公式如下:S7、根据权重矩阵W预测未知标签的目标域样本DTU的标签;如图3所示(假设样本的标签值为0、1),具体步骤如下:S71、求出每个未知标签的目标域样本DTU各自所属的聚类Ct;S72、使用全部的度量矩阵分别预测样本i的类型为mj(1jn);S73、使用KNN分类器进行分类得出分类值:wi=wt1m1+wt2m2+…+wtnmn;S74、若分类值大于阈值threshold,则预测样本i的标签值为Label1,否则预测样本i的标签值为Label2(Label1大于Label2);其中,threshold=(Label1-Label2)/NumOfCategory,NumOfCategory为标签种类。如Label1和Label2分别为1和0,NumOfCategory为2,可得threshold=(1-0)/2=0.5;若分类值大于阈值0.5,则预测样本i的标签值为1,否则预测样本i的标签值为0。本实施例可以用于常见的迁移学习数据集,例如:i)20Newsgroup(文本分类,http://people.csail.mit.edu/jrennie/20Newsgroups/)ii)Office-Caltech(物体识别,http://www.eecs.berkeley.edu/~jhoffman/domainadapt/)iii)USPS(手写字体识别,http://www-i6.informatik.rwth-aachen.de/~keysers/usps.html)和MNIST(手写字体识别,http://yann.lecun.com/exdb/mnist)其中,USPS、MNIST的数据分布不同但相关,两者均可以作为源域或目标域数据。而且本实施例具有以下优点:1、使用主成份分析方法来降低样本的维度,从而降低后续计算的复杂度。2、使用无监督聚类方法将样本聚为多个类别,从而更能够反应样本的本质特性。3、使用带标签的目标域样本来学习权重矩阵,从而更符合目标域样本的实际情况。以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1