基于低维图像编码与集成学习的白胚布平整度分级方法与流程
本发明涉及模式识别和机器学习领域,具体涉及一种基于低维图像编码与集成学习的白胚布平整度分级方法。
背景技术:
织物平整度是衡量织物质量、美观的重要指标,因此对于织物平整度的正确评定是非常重要的。目前,纺织业对于织物评定只能通过人工比对标准模板进行评定,但是因为相关标准只提供6个级别的3d模板,同时人工评定的主观性误差以及不同人之间评定的差异性,评定出的结果有一定的误差,可靠性不高。织物图像平整度评级是一个渐变连续的过程,平整度级别从3.2到1.0,图像上皱褶越来越大,越来越多,在渐变过程中,相邻的皱褶图像的特征相差不大。根据标准,每一张图像的皱褶级别是由三个资深工程师评级取平均值得出。
平整度评级方法主要有:基于高通滤波的织物平整度判定,其基本步骤为:1)图像预处理(减少光照和噪声的影响);2)利用高斯拉普拉斯算子(log)提取折痕(每个皱褶中明暗交错的中心线);3)平整度特征生成,对折痕位置上的每一个点周围得像素分布情况对褶皱进行量化;4)根据平整度特征建立评级参考系,使用的是svm(支持向量机)。但该方法的计算量很大,需要对折痕周围的所有褶皱区域的每一个像素进行滤波器组卷积操作,几乎接近逐像素处理;其次最后图像特征有5000维也比较多;该方法的最后验证结果也待进一步提升。
技术实现要素:
本发明的目的是克服现有方法的不足,提出了一种基于低维图像编码与集成学习的白胚布平整度分级方法。该方法主要通过特征提取来生成图像编码,然后通过机器学习来生成学习器,最后通过集成学习的思想来综合多个基学习器的结果得到最后结果。本方法使用计算机自动化的方法来对图像平整度进行客观、准确的评级,利用特征中心直方图作为图像编码,极大降低了编码维数,减少学习器计算量;使用集成学习的策略为最后结果提供可靠的保证,从而在节省人工成本的同时降低主观误差,并且在分级结果上能达到资深工程师的评级能力。
为了解决上述问题,本发明提出了一种基于低维图像编码与集成学习的白胚布平整度分级方法,所述方法包括:
图像和标签预处理;
基于预处理结果提取图像的皱褶特征中心;
基于特征中心对数据集中图像进行编码;
评级参考系的建立与验证。
优选地,所述图像和标签预处理,具体为:
将彩色图像变成灰度图像;对灰度图像进行自适应中值滤波,去除日常拍摄时引入的校验噪声;选取并裁剪图像皱褶的有效区域;对裁剪的有效区域进行直方图均衡化处理,降低成像误差;对数据集中图像的皱褶等级数值进行向量化处理,便于基学习器的训练。
优选地,所述提取图像的皱褶特征中心,具体为:
生成mr8(themaximumresponesets)滤波器组;提取任一个皱褶级别的局部特征向量集;对局部特征向量集使用聚类方法(k_means)进行聚类,获得m个聚类中心,并由m个聚类中心与n个皱褶级别得到m×n个特征中心。
优选地,所述对数据集中图像进行编码,具体为:
求出m×n个特征中心出现的频率直方图,把各特征中心出现频数排成m×n维向量以作为该图像的编码,并对编码进行归一化处理;对数据集所有的图像都进行前述处理,得到所有图像的m×n维向量编码。
优选地,所述评级参考系的建立与验证,具体为:
选取训练集和测试集;将训练集图像的编码与第一个工程师评级的结果组成训练集,使用支持向量机(svm,supportvectormachine)来训练第一个基学习器;将训练集图像的编码与第二个工程师评级的结果组成训练集,使用k近邻算法来训练第二个基学习器,计算该编码与所有训练集的欧氏距离;将训练集图像的编码与第三个工程师评级的结果组成训练集,使用k近邻算法来训练第三个个基学习器,计算该编码与所有训练集的曼哈顿距离;取三个基学习器输出结果的平均值作为最后结果输出;利用测试集来验证分类器的泛化能力,验证的方法采用的是皱褶分层验证和交叉验证法。
在本发明实施例中,提出了一种基于低维图像编码与集成学习的白胚布平整度分级方法,该方法主要通过特征提取来生成图像编码,然后通过机器学习来生成学习器,最后通过集成学习的思想来综合多个基学习器的结果得到最后结果。本方法使用计算机自动化的方法来对图像平整度进行客观、准确的评级,利用特征中心直方图作为图像编码,极大降低了编码维数,减少学习器计算量;使用集成学习的策略为最后结果提供可靠的保证,从而在节省人工成本的同时降低主观误差,并且在分级结果上能达到资深工程师的评级能力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
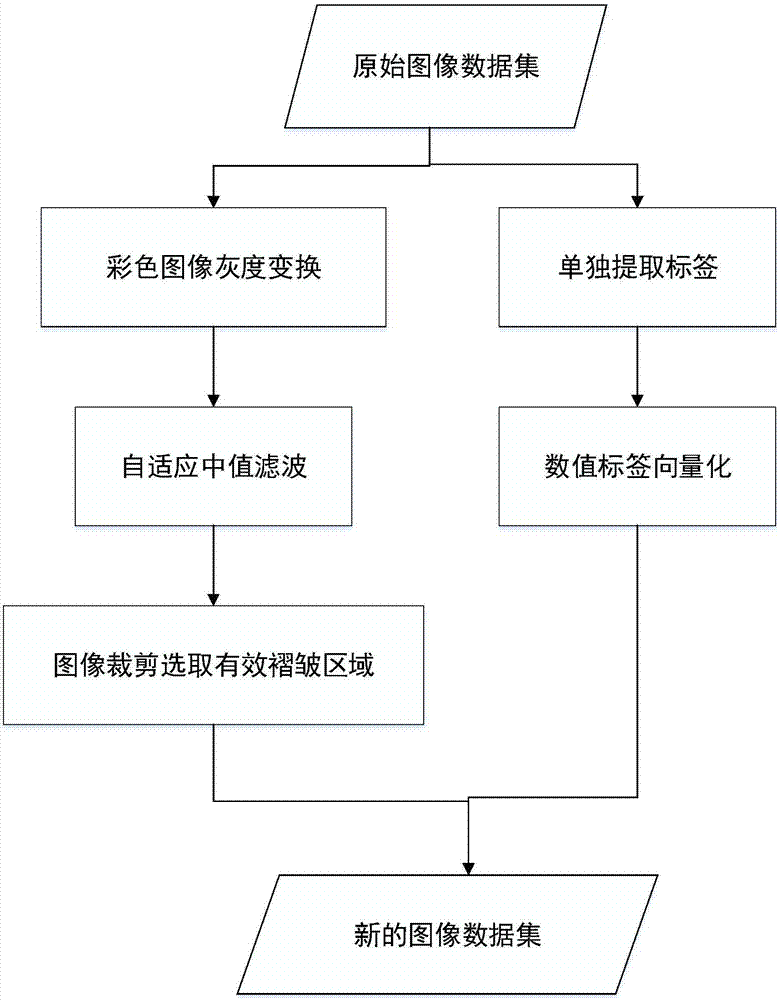
图1是本发明实施例的整体流程图;
图2是本发明实施例的预处理流程图;
图3是本发明实施例的生成特征中心的流程图;
图4是本发明实施例的mr8滤波器组二维图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1是本发明实施例的整体流程图,如图1所示,该方法包括:
s1,图像和标签预处理;
s2,基于预处理结果提取图像的皱褶特征中心;
s3,基于特征中心对数据集中图像进行编码;
s4,评级参考系的建立与验证。
步骤s1,具体如下:
s11,日常拍摄都是彩色图像,而本方法处理的是灰度图像。因此首先把彩色图像变成灰度图像,公式:
i=0.3×ir+0.59×ig+0.11×ib
其中i表示像素灰度,ir、ig、ib分别表示原像素的红绿蓝颜色值。
s12,对灰度图像进行自适应中值滤波,去除日常拍摄时引入的校验噪声。
s13,选取与裁剪图像皱褶的有效区域。主要原因是图像发生皱褶后,拍摄时会拍到背景图像,并且背景与织物图像会形成强烈的边缘效应,对分级产生较大的影响。本发明实施例根据数据集影响,裁剪的有效区域是426×426大小。
s14,对裁剪的有效区域进行直方图均衡化处理,降低日常拍摄时因光照不均所导致的成像误差对后续特征提取的干扰。
s15,对数据集中图像的皱褶等级数值进行向量化处理,便于基学习器的训练。数据集中一共有460张图像,共23个等级,范围是1.0-3.2,每个等级有20张图像。标签预处理就是把平整度级别的数字表示转换成向量表示,处理结果是每张图像的标签都是23维的向量。例如平整度为1.0的图像对应的标签向量只有第一维是1,其余维都是0。
步骤s2,具体如下:
s21,生成mr8(themaximumresponesets)滤波器组。mr8滤波器组由38个滤波器组成,其中有36个各向异性滤波器和2个同向滤波器如图4所示。36个滤波器中主要有两类滤波器,分别是一阶微分高斯滤波器和分割微分高斯滤波器。每种滤波器主要有3个尺度,在每个尺度内有6个方向。2个同向滤波器分别是高斯滤波器和拉普拉斯高斯滤波器。本发明实施例用mr8滤波器组提取特征时,首先截取图像49×49的局部区域,然后与每个滤波器作卷积操作,生成38个卷积响应值。然后在选取最大的8个响应值作为截取局部区域的特征。
s22,提取任一个皱褶级别的局部特征向量集。在一个皱褶级别图片中随机选取70%的图片,共14张作为生成该皱褶级别特征中心的数据集。对于单张图片,选取图像有效区域后图像大小是426×426。首先从图像的第25行、第25列的像素开始,以该像素为中心截取49×49区域利用mr8滤波器组与该区域进行卷积运算,一共有38个卷积响应值,把所有的响应值进行排序,选取最大的8个响应值作为该局部区域的特征,本发明实施例在卷积操作时选取的步长是25。经过多步操作最终在单张图片上能提取到256个8维的特征向量。一个皱褶级别选取了14张图像,因此最后对于一个褶皱级别共提取了14×256个8维局部特征向量。
卷积计算公式:
其中ii,j代表被截取的49×49的局部区域第i行j列的像素的灰度,fi,j代表滤波器对应位置的值,卷积的实质就是对应位置相乘后,所有位置求和就是卷积的响应值。
s23:对于s22的结果使用聚类方法(k_means)进行聚类,最终获得若干个聚类中心,本发明实施例选择9个聚类中心。本发明实施例处理的数据集中共有23个皱褶级别,把所有皱褶级别所得到的聚类中心组成一个集合,共有23×9=207个特征中心。然后对207个特征中心进行编号即1~207。
步骤s3,具体如下:
s31,读取数据集的任一张图像,生成初始默认编码是一个207维的零向量。对于输入的一张皱褶图像,根据需要选定起始点后参照步骤a22利用mr8滤波器组提取局部特征向量,然后分别计算该局部特征向量与207个特征中心的欧氏距离,找个与局部特征向量欧氏距离最近的特征中心对应的编号x。然后使图像编码的第x维上的数值加1。选定步长后,对图像循环上述运算,最后得到各个特征中心出现的频率直方图,把各个中心出现频数排成207维的向量,作为该图像的编码。之后对编码进行归一化处理。
s32,对数据集所有的图像都进行s31的操作,最后每一张图像都有一个对应的207维向量编码。
步骤s4,具体如下:
s41,选取训练集和测试集。为了保证每个皱褶级别样本使用数目的均衡性,本发明实施例在每一个皱褶级别随机选取70%的图像,最后把所有皱褶级别的并集作为训练集,剩下30%作为测试集。
s42,将训练集图像的编码与第一个工程师评级的结果组成训练集,使用支持向量机(svm,supportvectormachine)来训练第一个基学习器,相似性度量使用的是欧氏距离(euclideandistance),核函数使用的是径向基核函数。支持向量机主要的学习目的就是学习到不同褶皱级别之间的超平面。
s43,将训练集图像的编码与第二个工程师评级的结果组成训练集,使用k近邻算法来训练第二个基学习器。具体做法是对于输入的测试图像,首先得到对应编码特征,然后计算这个编码与所有训练集的欧氏距离,找个距离值最小的若干个编码得到其对应的皱褶级别,取这些级别数值的平均值作为第二个基学习器的输出结果,本发明实施例中选取15个最小的编码。
s44,在实验过程中,发现使用欧氏距离时,在皱褶级别较低时输出结果总是稍微偏大,但是在皱褶较大的时候结果就很好;使用曼哈顿距离时,情况于此恰好相反。因此参照第二个基学习器,将训练集图像的编码与第三个工程师评级的结果组成训练集,使用k近邻算法来训练第三个个基学习器,但是这里计算的是曼哈顿距离。
s45,关于集成学习的综合策略本方法是直接取三个基学习器输出结果的平均值作为最后结果输出。
s46,整个集成分类器训练完成后,利用测试集来验证分类器的泛化能力。验证的方法采用的是皱褶分层验证和交叉验证法。其中皱褶分层验证会在每一个皱褶级别都进行单独验证,分析分类对于不同皱褶级别的评级情况。交叉验证主要是测试集中包含一部分训练集的数据,验证分类器的是否过拟合。
在本发明实施例中,提出了一种基于低维图像编码与集成学习的白胚布平整度分级方法,该方法主要通过特征提取来生成图像编码,然后通过机器学习来生成学习器,最后通过集成学习的思想来综合多个基学习器的结果得到最后结果。本方法使用计算机自动化的方法来对图像平整度进行客观、准确的评级,利用特征中心直方图作为图像编码,极大降低了编码维数,减少学习器计算量;使用集成学习的策略为最后结果提供可靠的保证,从而在节省人工成本的同时降低主观误差,并且在分级结果上能达到资深工程师的评级能力。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
另外,以上对本发明实施例所提供的一种基于低维图像编码与集成学习的白胚布平整度分级方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!