一种基于弱监督多模态深度学习的微博情感预测方法与流程
本发明涉及多模态情感分析领域,尤其是涉及一种基于弱监督多模态深度学习的微博情感预测方法。
背景技术:
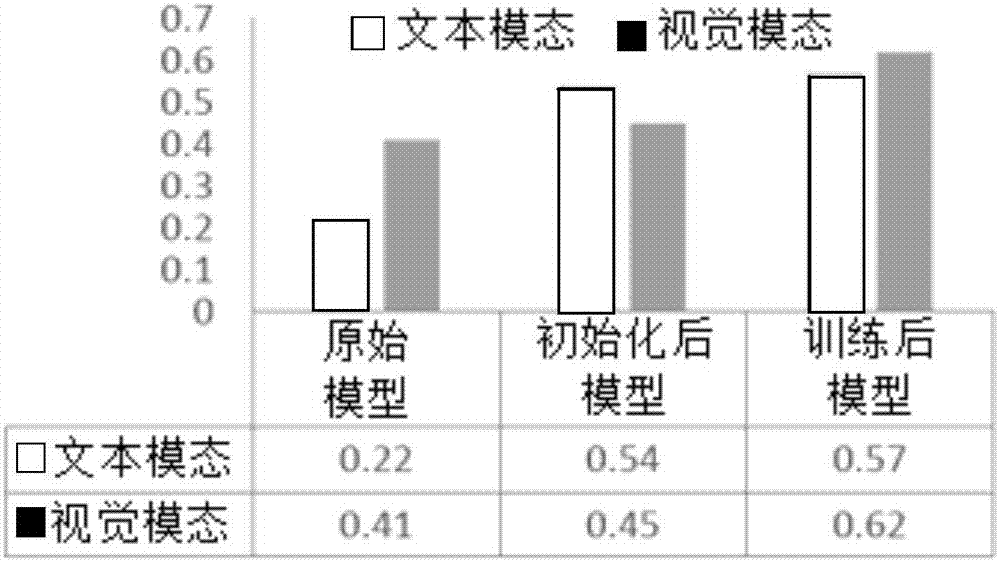
:近来,随着新浪微博等大型社交平台的迅速发展,每天社交网络的多媒体数据规模不断增长,以新浪微博为例,截止2016年3月,新浪微博月活跃用户达到2.6亿。作为最受欢迎的平台之一,新浪微博使得互联网用户能够在他们感兴趣的话题下表达他们的情感。因此,它吸引了大量的关于情感信息挖掘的研究,这些研究涉及一些新兴的应用包括事件检测、社交网络分析和商业推荐。微博发展的一个明显特征在于多模态信息的增长,比如图像、视频、短文本以及丰富的表情符号。认知方面的研究也揭示不同的模态有它们特有的特征(如在符号学方面,语义层面,和认知层面)。这启发我们从多模态层面分析微博的情感。然而,预测多模态微博情感的依然是一个未解决的问题。关键的挑战有两个方面,一方面在于跨多个模态的判别表示的学习,另一方面在于情感分析受限于足够样本标签数据的获取。当前,微博情感分析方法主要利用纯文本通道信息,比如《一种基于大规模语料特征学习的微博情感分析方法(中国专利CN201510310710.9)》、《基于规则和统计模型的中文微博情感分析方法(中国专利CN201510127310.4)》、《一种融合显性和隐性特征的中文微博情感分析方法(中国专利CN201410723617.6)》、《一种中文微博的情感倾向分析方法(中国专利CN201310072472.3)》、《基于卷积神经网络的中文微博文本情绪分类方法及其系统(中国专利CN201710046072.3)》。然而,由于微博文本具有结构随意,内容较少等特点,单从简单的纯文本通道进行微博情感类别分析难度大,情感预测的准确度低。《一种面向微博短文本的情感分析方法(中国专利CN201210088366.X)》提出一种短文本情感分析方法,但是其面向特定领域和特定主题,不具有普适性。《一种利用表情符号对微博进行情感倾向分类的方法(中国专利CN201310664725.6)》提出基于表情符号词典使用朴素贝叶斯方法构建中性情感分类器和极性情感分类器的方法进行微博情感分类,然而含有表情符号的微博仅占32%,利用表情符号单一通道进行微博情感预测难以适用于所有微博。《基于表情分析和深度学习的社交网络情感分析方法(中国专利CN201611035151.6)》提出一种利用表情符号作为标签数据进行监督学习的微博情感预测方法,然而由于表情符号在情感分类中存在精度偏差,最终训练到的模型在情感分类效果上并不理想。同时由于该方法无法挖掘到文本、表情和情感标签之间的内在关联,因此很难学到具有判别性的多模态的表示。《一种基于微博群环境的微博多模态情感分析方法(中国专利CN201410006867.8)》提出的多模态情感分析方法还是基于单一文本通道上的微博原文本和评论文本。《一种基于情感极性感知算法的跨媒体微博舆情分析方法(中国专利CN201611128106.5)》和《一种基于多模态超图学习的微博情感预测方法(中国专利CN201611128388.9)》提出了多模态的情感预测方法,然而这些方法都受限于足够的样本标签数据的获取,训练到的模型在情感分类效果上并不理想。由此可见,现有技术存在如下缺陷:第一,现有技术主要针对单一文本通道的微博情感分析,而微博的文本具有微博文本具有结构随意,内容较少等特点,单从简单的纯文本通道进行微博情感类别分析难度大;第二,现有技术难以挖掘多个模态与情感标签之间的内在关联,从而学习到具有判别性的特征表示;第三,现在技术受限于足够样本标签数据的获取,难以训练出有效的情感预测模型,特别是基于深度学习的模型。以上三点都使得现有技术在情感预测上的准确度偏低。技术实现要素:本发明的目的是针对在微博多通道内容(多模态)上的情感预测中存在的多模态判别表示和数据标签受限的问题,提供一种基于弱监督多模态深度学习的微博情感预测方法。本发明包括以下步骤:步骤1微博多模态数据预处理;步骤2多模态深度学习模型的弱监督训练;步骤3多模态深度学习模型的微博情感预测。在步骤1中,所述微博多模态数据预处理的具体方法可为:对爬取的微博数据进行去重操作,过滤掉微博内容中的标签符号和外部链接,使用中科院自动分词工具ICTCLAS对微博文本内容进行分词(Textsegment);将表情符号作为噪声标签,即表情符号类别(Bag-of-emoticon-word),收集文本语料里所有的表情符号,然后筛选出高频使用的49个表情符号,再为每条微博构建表情符号词袋模型作为表情符号类别,通过人工标注微博数据的情感极性来获取干净的标签,所述情感极性的类别包括正极性、负极性、中性。在步骤2中,所述多模态深度学习模型的弱监督训练的具体方法可为:(1)计算样本的文本模态和图像模态的情感类别概率输出,对于文本模态,首先使用词向量转换算法(word2vec)将词表中的每个词转换成一个特定的向量,然后将每个句子中的所有词向量整合成一个矩阵表示,将这个矩阵输入到动态卷积神经网络(DynamicConvolutionalNeuralNetwork,简称DCNN)中,输出文本模态下情感极性类别的概率分布;对于图像模态,直接将图像输入到预训练好的深度卷积神经网络(DeepConvolutionalNeuralNetwork,简称CNN)中,通过修改最后一层的网络输出结构,最终输出图像模态下情感极性类别的概率分布;(2)计算文本模态情感预测和图像模态情感预测的一致性,通过交叉熵(Kullback-Leible散度)计算文本模态下情感极性类别的概率输出与图像模态下情感极性类别的概率输出之间的一致性概率分布,利用非线性函数,将一致性概率分布转化为一致性概率值,该值反映了当前样本中文本和图像的情感属性是否一致,便于模型的更好训练;所述非线性函数可采用Sigmoid函数;(3)计算模型预测的情感概率分布和估计的真实情感概率分布之间的交叉熵损失并行性参数优化,首先将样本的表情符号类别作为观测变量,将情感概率分布作为隐变量,构建多模态噪声模型的概率图模型;然后通过使用最大期望算法(ExpectationMaximizationAlgorithm)求取模型预测的情感概率分布和估计的真实情感概率分布之间的交叉熵损失;最后利用反向传播算法(BackPropagationAlgorithm),将损失通过梯度的方式进行反向传播进而优化多模态噪声模型、DCNN模型和CNN模型的参数;(4)重复步骤(1)~(3),直到损失收敛到合理区间,进而获得最佳的多模态噪声模型、DCNN模型和CNN模型的参数,完成基于弱监督多模态深度学习的微博情感预测模型的训练过程。在步骤3中,所述多模态深度学习模型的微博情感预测的具体方法可为:将待预测微博的文本经过预处理并经过词向量的转化最终输入到训练好的DCNN模型中,输出文本模态的情感类别的概率分布,将微博的图像输入到训练好的CNN模型中,输出图像模态的情感类别的概率分布,将表示两个概率分布的两个向量和表情符号向量组成新的特征向量,经过Softmax分类器,实现最终多模态的情感类别预测。本发明解决了在微博多通道内容(多模态)上的情感预测中存在的多模态判别表示和数据标签受限等问题,提供一种基于弱监督多模态深度学习的微博情感预测方法,实现最终多模态的情感类别预测,实验评价标准为准确度(Accuracy),反映了预测的微博情感极性类别与事先标注的情感类别之间的一致程度。本发明所提出的方法与现有技术比较在性能上有较大的提升,与最佳的HGL模型比较也提升了2个百分点。与不同方法在不同模态上的情感极性类别预测效果比较可以看出,在不同的模态上的方法(WS-MDL)都取得了较好的效果。其中HGL方法在图像模态(VisualModality)上性能略优于WS-MDL,这是由于HGL采用了现有的视觉情感属性检测器来提取图像的特征,然而本发明的方法考虑到多模态之间的关联性,因此在整体的多模态性能上取得最优的效果。本发明在不同情感类别上都取得较为理想的分类效果。经过弱监督训练,使得文本和图像模态的初始模型在情感分类上效果有明显的提升。附图说明图1为基于弱监督多模态深度学习的微博情感预测方法的流程示意图。图2为不同方法在不同模态上的情感极性类别预测效果比较。图3为基于弱监督多模态深度学习的微博情感预测方法在不同情感类别上的精确率和召回率。图4为基于弱监督多模态深度学习的微博情感预测方法在不同模态的不同阶段的准确度比较。具体实施方式以下实施例将结合附图对本发明作进一步的说明。本发明实施例包括以下步骤:步骤1微博多模态数据预处理,具体方法如下:先对爬取的微博数据进行去重操作,然后过滤掉微博内容中的标签符号和外部链接,最后使用中科院自动分词工具ICTCLAS对微博文本内容进行分词(Textsegment);接着将表情符号作为噪声标签(表情符号类别),首先收集文本语料里所有的表情符号,然后筛选出高频使用的49个表情符号,最后为每条微博构建表情符号词袋模型作为表情符号类别(Bag-of-emoticon-word),通过人工标注微博数据的情感极性来获取干净的标签(情感极性类别:正极性,负极性,以及中性)。步骤2多模态深度学习模型的弱监督训练,如图1所示,具体方法描述如下:步骤2.1计算样本的文本模态和图像模态的情感类别概率输出。对于文本模态,首先使用词向量转换算法(word2vec)将词表中的每个词转换成一个特定的向量。然后将每个句子中的所有词向量整合成一个矩阵表示,最后将这个矩阵输入到动态卷积神经网络(DynamicConvolutionalNeuralNetwork,简称DCNN)中,输出文本模态下情感极性类别的概率分布。对于图像模态,直接将图像输入到预训练好的深度卷积神经网络(DeepConvolutionalNeuralNetwork,简称CNN)中,通过修改最后一层的网络输出结构,最终输出图像模态下情感极性类别的概率分布。步骤2.2计算文本模态情感预测和图像模态情感预测的一致性。通过交叉熵(Kullback-Leible散度)计算文本模态下情感极性类别的概率输出与图像模态下情感极性类别的概率输出之间的一致性概率分布。利用非线性函数(采用Sigmoid函数),将一致性概率分布转化为一致性概率值。该值反映了当前样本中文本和图像的情感属性是否一致,便于模型的更好训练。步骤2.3计算模型预测的情感概率分布和估计的真实情感概率分布之间的交叉熵损失并行性参数优化。首先将样本的表情符号类别作为观测变量,将情感概率分布作为隐变量,构建多模态噪声模型的概率图模型。然后通过使用最大期望算法(ExpectationMaximizationAlgorithm)求取模型预测的情感概率分布和估计的真实情感概率分布之间的交叉熵损失。最后利用反向传播算法(BackPropagationAlgorithm),将损失通过梯度的方式进行反向传播进而优化多模态噪声模型、DCNN模型和CNN模型的参数。步骤2.4重复进行步骤2.1、步骤2.2和步骤2.3,直到损失收敛到合理区间,进而获得最佳的多模态噪声模型、DCNN模型和CNN模型的参数,完成基于弱监督多模态深度学习的微博情感预测模型的训练过程。步骤3多模态深度学习模型的微博情感预测。将待预测微博的文本经过预处理并经过词向量的转化最终输入到训练好的DCNN模型中,输出文本模态的情感类别的概率分布,将微博的图像输入到训练好的CNN模型中,输出图像模态的情感类别的概率分布,将表示两个概率分布的两个向量和表情符号向量组成新的特征向量,经过Softmax分类器,实现最终多模态的情感类别预测。实验评价标准为准确度(Accuracy),反映了预测的微博情感极性类别与事先标注的情感类别之间的一致程度。多模态情感分类任务上各种方法的实验效果比较参见表1。表1方法学习方式精确度CBM-LR监督学习65.6%CBM-SVM监督学习66.6%HGL监督学习67.2%WS-MDL弱监督学习69.5%其中,CBM-LR为基于Logistics回归的跨模态词袋模型,CBM-SVM为基于支持向量机的跨模态词袋模型,HGL为多模态超图学习方法。以上皆为目前多模态情感分类任务上最佳的方法。WS-MDL为本发明所提出的基于弱监督多模态深度学习的预测模型。由表1可以看出本发明所提出的方法与其他的方法比较在性能上有较大的提升,与最佳的HGL模型比较也提升了2个百分点。不同方法在不同模态上的情感极性类别预测效果比较参见图2,从图2可以看出,在不同的模态上的方法(WS-MDL)都取得了较好的效果。其中HGL方法在图像模态(VisualModality)上性能略优于WS-MDL,这是由于HGL采用了现有的视觉情感属性检测器来提取图像的特征,然而本发明的方法考虑到多模态之间的关联性,因此在整体的多模态性能上取得最优的效果。基于弱监督多模态深度学习的微博情感预测方法在不同情感类别上的精确率和召回率参见图3,由图3可知,本发明在不同情感类别上都取得较为理想的分类效果。基于弱监督多模态深度学习的微博情感预测方法在不同模态的不同阶段的准确度参见图4,由图4可知,本发明经过弱监督训练,使得文本和图像模态的初始模型在情感分类上效果有明显的提升。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1