一种基于FPGA在视觉应用中的卷积神经网络加速器的制作方法
本实用新型涉及图像处理与模式识别技术领域,具体涉及一种基于FPGA在视觉应用中的卷积神经网络加速器。
背景技术:
随着集成电路设计和制造工艺的进步,具有大量高速可编程逻辑资源的现场可编程门阵列(Field Programmable Gate Array,FPGA)得到了快速发展,单个芯片的集成度越来越高。为了进一步提高FPGA性能,主流的芯片厂商在芯片内部集成了具有高速数字信号处理能力的数字信号处理(Digital Signal Processing,DSP)定制计算单元与大量的硬件乘累加(Multiply-add Accumulation,MAC)单元,能够高效、低功耗的实现定点运算,完成大量的卷积运算任务。使得FPGA在视频与图像处理、网络通信与信息安全、模式识别等应用领域被广泛采用。
卷积神经网络(Convolutional Neural Networks ,CNN)是一种源自人工神经网络的多层感知器,它对图像的处理与特征提取具有高度的适应性使之成为当前模式识别和图像识别领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络结构,降低了网络模型的复杂度,减少了权值的数量。图像可以直接作为网络的底层输入,信息再依次传输到不同的层,每层通过一个数字滤波器去获得观测数据的最显著的特征,避免了传统识别算法中复杂的特征提取和数据重建过程。
现有的大部分CNN实现主要是基于通用处理器CPU,图形处理器GPU或是专用集成电路(Application Specific Integrated Circuits,ASIC)实现的。CPU 为了满足通用性,芯片面积有很大一部分都用于复杂的控制流和Cache缓存,留给运算单元的面积并不多,所以无法充分地挖掘CNN内部的并行性;GPU 运行效率比 CPU 快很多,但是由于高昂的价格以及超大的功耗对于使其在实际应用中成本相对更高;ASIC虽是一个有效的方式实现卷积神经网络,但其设计周期长和制造成本高,而且体系结构是固定的,灵活性与拓展性较差。
技术实现要素:
本实用新型的目的在于:克服现有技术的缺陷,针对视觉应用中图像处理功耗高,实时性与可拓展性较差的不足,提供一种基于FPGA在视觉应用中的卷积神经网络加速器,实现对图像数据的快速处理和对实时图像的高度识别。
本实用新型解决其技术问题所采用的技术方案是:本实用新型选择Xilinx Zynq-7000扩展式处理平台,具体采用ZYNQ-XC7Z020 SOC,它组合了一个双核ARM Cortex-A9处理器和一个传统FPGA逻辑部件,两者采用AXI工业标准的接口,从而在芯片的两个部分之间实现互联的异构架构。
ZYNQ中ARM Cortex-A9是一个应用级的处理器,位于处理系统端(Processing system,PS),而可编程逻辑端(Programmable Logic,PL)部分是基于Xilinx7系列的FPGA架构,此外还具有用于密集存储需要的块 RAM 和用于高速算术的 DSP48E1 片。
利用FPGA的并行计算能力在PL端的FPGA上设计乘法累加模块(Multiply and Accumulate operations,MAC )进行大量的卷积运算。MAC模块拥有一块较小的内存,存储与输入数据对应的卷积核数据,称之为“协存储器”。
ARM是整个系统的主控制器,是用于处理不同类型的卷积操作。ARM提供每个卷积操作中不同的参数,同时在PL端控制器需要配置不同的卷积核参数与运行时特征图的尺寸和数量。输入图像与其权值都被存储在片外DDR SDRAM存储器中。这个存储器连接到位于PS端的DDR内存控制器上。
ARM与逻辑运算部分及存储单元使用AXI CDMA(AXI Central Direct Memory Access)接口进行通信 ,ARM通过对总线控制器进行设置来控制各模块之间数据传输与通信。
卷积运算网络(CNN)采用Alex-net网络。它包括1个输入层,5个卷积层,3个池化层,3个全连接层。第一层拥有96个11*11卷积核,第二层拥有256个11*11卷积核,第三,四层拥有384个3*3卷积核,第五层拥有256个3*3卷积核,其池化层采用最大值法,滑动窗口大小为3*3,步长为2。
本实用新型所产生的有益效果有:
利用ARM+FPGA硬件平台进行卷积运算网络的加速,可以提高CNN网络的实时性,实现了较高的计算性能并且降低功耗,提高了该系统的拓展性。
附图说明
图1是本实用新型的系统运行时框图。
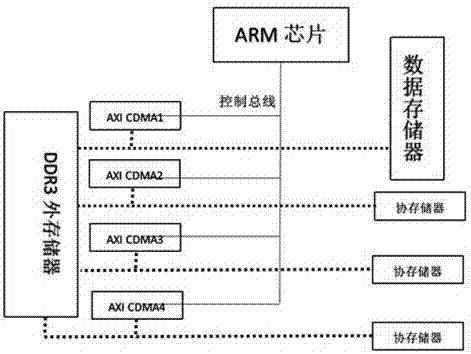
图2是本实用新型的系统片外存储器互联图。
图3是Alex-net卷积神经网络各层输入输出参数。
具体实施方式
现结合附图对本实用新型做进一步描述。
如附图1所示,本实用新型的系统结构包括PS端ARM主控芯片,PL端包含总线控制器,数据存储器,MAC运算模块与其对应的协存储器。如附图2所示,PS与PL端及PL端内部通过AXI接口互联,片上存储器到片外存储器的数据传输是通过使用AXI CDMA实现的。
系统结构通过Vivado综合设计环境与verilog语言设计,使用Vivado HLS软件编写控制程序。数据存储器和协存储器中内存为空,总线控制器控制多个多路复用器进行数据传输与模块选择。数据存储器与协存储器的内存长度都为32字节,卷积核长度为16字节。
本加速器包含32个MAC模块,每个都对应一个18KB的存储卷积核数据的协存储器,2MB的数据存储器空间来存储输入输出图像信息。其中协存储器由FPGA中的块RAM实现,而数据存储器由FPGA基于查找表(Look Up Table,LUT)生成分布式RAM构成。每个MAC模块包含12个DSP48模块用于进行卷积运算。每个协存储器存储两个16位卷积核的值,在片上存储器使用双端口RAM,两个端口都可读写。这样两行协存储器可以在同一时间访问,MAC模块可以生成四个对应不同的特征图的输出数据。
首先,ARM处理器AXI GPIO设置多路复用器连接片上数据存储器和协存储器,然后配置CDMA加载输入特征图的数据映射到数据存储器,同时使卷积核数据映射到每个相应的协存储器上。
之后,ARM一方面通过总线控制器设置合适的寄存器参数,PL端的控制器使用这些参数来计算所需的地址信息,选择所需的MAC模块,从而操作PL侧控制寄存器来运行卷积操作;另一方面通过设置多路复用器将数据内存连接到控制单元,同时也使协存储器连接到对应的MAC模块。
接下来图像数据通过控制单元开始传输到MAC模块,在每次运行后存储经过计算输出的像素信息在数据存储器中,持续着个操作直到运行完成一个周期后。当运行完成一个周期时,即代表全部输出的特征数据已经完成了运算与存储。
当所有的输出数据都已经完成计算,ARM需要再次控制并设置多路复用器,通过AXI总线连接到片上存储器来传递数据存储器中存储的卷积操作的运算结果给片外存储器中进行后期处理,加速过程完成。
其中AXI工作在分散/聚集(Scatter-gather DMA)模式。这种工作方式DMA自动加载数据源,这个数据源来自于片外存储器中存储的多组数据,传递完成后中断CPU。而当运行完成一个周期时,新卷积核将在协存储器中取代旧卷积核,而数据存储器中的数据将保持不变,直到它用于下一个周期的循环。这能够改善了加载数据与卷积核的时间,同时对中断的数量进行限制,从而降低了每个卷积操作中CPU的负载。
通过控制程序可对系统参数进行修改,支持运行时修改图像大小的参数范围,卷积核大小,及MAC模块调用。利用可重用性的内核数据,限制不必要的访问片外存储器,因此减少带宽消耗,因此提高卷积神经网络的实时性与灵活性,从而完成提高卷积神经网络计算效率的任务。
- 还没有人留言评论。精彩留言会获得点赞!