用于图形处理单元的着色器中的统一断言的制作方法
本公开涉及多线程处理,且更确切地说,涉及单指令多数据(SIMD)处理系统中的技术执行。
背景技术:
单指令多数据(SIMD)处理系统为包含对多个数据段执行相同指令的多个处理元件的一种类型的并行计算系统。SIMD系统可为独立计算机或计算系统的子系统。举例来说,一或多个SIMD执行单元可用于图形处理单元(GPU)中以实施支持可编程着色的可编程着色单元。SIMD处理系统允许程序的多个执行线程来以并行方式在多个处理元件上同时执行,由此增加程序的吞吐量,其中需要对多个数据段执行相同操作集合,在特定SIMD处理元件上执行的特定指令被称作线程或纤程。线程组可被称作波或线程束。
例如GPU的处理单元包含处理元件和存储数据以供指令执行的通用寄存器(GPR)。在一些实例中,处理元件执行用于处理一个数据项的指令,且相应的处理元件在GPR中存储这项数据或来自处理的所述项的所得数据。数据项可以是发生处理的基本单位。举例来说,在图形处理中,图元的顶点是项的一个实例,且像素是项的另一实例。存在与每个顶点和像素相关联的图形数据(例如,坐标、色彩值等)。
处理元件的处理器核心内可存在多个处理元件,从而允许指令的并行执行(例如,多个处理元件同时执行相同指令)。在一些状况下,所述处理元件中的每一个在GPR中存储项的数据,且从GPR读取项的数据,即使对于多个项所述数据是相同的也是如此。
技术实现要素:
一般来说,公开描述用于确定GPU的着色器核心和/或SIMD处理核心的断言位的技术。断言位指示在达到指令集中的分支条件时SIMD处理核心的一个线程将或将不执行指令集的哪个(些)部分。确切地说,本公开描述一种技术,借此当所有线程以相同方式分支时可由SIMD处理核心中的线程束的所有线程存储和使用单组断言位。与使用每线程断言位相比,此技术允许简化和功率节省。
在一个实例中,本公开描述处理图形处理单元中的数据的方法,所述方法包括接收图形处理单元(GPU)中线程束的所有线程将执行第一指令集中的相同分支的指示,将一或多个断言位作为单组断言位存储在存储器中,其中单组断言位适用于线程束中的所有线程,以及根据单组断言位执行第一指令集的部分。
在另一实例中,本公开描述用于处理数据的设备,所述设备包括经配置以存储第一指令集的存储器、经配置以接收第一处理器中的线程束的所有线程将执行第一指令集中的相同分支的指示,将一或多个断言位作为单组断言位存储在寄存器中,其中单组断言位适用于线程束中的所有线程,以及根据单组断言位执行第一指令集的部分。
在另一实例中,本公开描述用于处理数据的设备,所述设备包括用于接收图形处理单元(GPU)中线程束的所有线程将执行第一指令集中相同分支的指示的装置、用于将一或多个断言位作为单组断言位存储在存储器中的装置,其中单组断言位适用于线程束中的所有线程,以及用于根据单组断言位执行第一指令集的部分的装置。
在另一实例中,本公开描述计算机可读存储媒体,其具有存储在其上的指令,所述指令在执行时使一或多个处理器接收图形处理单元(GPU)中的线程束的所有线程将执行第一指令集中的相同分支的指示,将一或多个断言位作为单组断言位存储在存储器中,其中单组断言位适用于线程束中的所有线程,以及根据单组断言位执行第一指令集的部分。
随附图式和以下描述中阐述了一或多个实例的细节。其它特征、目标和优点将从所述描述、图式和权利要求书中显而易见。
附图说明
图1是说明根据本公开中所描述的一或多个实例技术的用于处理数据的实例装置的框图。
图2是更详细地说明图1中所说明的装置的组件的框图。
图3是说明指令集的实例的概念图。
图4是说明GPU的着色器核心的通用寄存器(GPR)中的数据存储的实例的概念图。
图5是图1的GPU的实例着色器核心的更详细框图。
图6是图1的GPU的另一实例着色器核心的更详细框图。
图7是说明处理GPU中的数据的实例技术的流程图。
具体实施方式
并行处理单元,例如经配置以并行(例如,同时)执行许多操作的图形处理单元(GPU),包含执行一或多个程序的指令的一或多个处理器核心(例如,GPU的着色器核心)。为易于描述,相对于GPU或通用GPU(GPGPU)描述本公开中所描述的技术。然而,本公开中描述的技术可以扩展到未必是GPU或GPGPU的并行处理单元,以及非并行处理单元(例如,未具体配置成用于并行处理的非并行处理单元)。
GPU可经设计有单指令多数据(SIMD)结构。在SIMD结构中,着色器核心(或更一般来说,SIMD处理核心)包含多个SIMD处理元件,其中每个SIMD处理元件执行相同程序但在不同数据上的指令。在特定SIMD处理元件上执行的特定指令被称作线程或纤程。线程组可被称作波或线程束。执行线程束的所有处理元件一起可被称为向量处理单元,其中向量的每一通道(例如,处理元件)执行一个线程。每一SIMD处理元件可以被认为是执行不同线程,因为用于给定线程的数据可能是不同的;然而,在处理元件上执行的线程是与在其它处理元件上执行的指令相同的程序的相同指令。以此方式,SIMD结构允许GPU并行(例如,同时)执行许多任务。
SIMD处理核心可包含多个处理元件,而每一处理元件执行一线程。每一处理元件并行执行相同指令集。在一些情况下,指令集可包含条件分支指令(例如,如果-则-否则指令)。由于每一处理元件对不同数据进行操作,因此可以不同方式使相同线程束中的不同线程分支。也就是说,给定每一线程的不同输入数据,取条件指令的“则”分支还是条件指令的“否则”分支的条件可对于每一线程而不同。
在一些实例中,使用指示SIMD向量的每一线程(通道)(例如,每一处理元件)应如何分支(即,在单个指令集包含分支指令的状况下)的断言位在“每线程”的基础上执行用于SIMD处理核心的控制流。由于线程具有独立数据,这些断言通常彼此不具有任何相关性。然而,并非始终如此,且对于其中相同断言适用于线程束中的所有线程的状况,独立断言的使用是浪费的。
本公开描述使用统一断言集的方法、技术和装置,在所述统一断言组中单组断言位适用于整个线程束。此类统一断言可当确定线程束的所有线程以相同方式分支时使用。以此方式,可实现功率节省,因为在使用统一断言时仅进行单个测试,而非在每线程基础上分配断言位。
此外,本公开还描述并靠GPU的SIMD核心将标量处理单元添加在GPU中。标量处理单元可用于执行已确定为以相同方式对线程束的所有线程进行分支的指令集。以此方式,标量处理单元可使用统一断言组来执行具有统一分支的指令集,而SIMD核心的向量处理单元可用于与标量处理单元并行处理另一指令集。
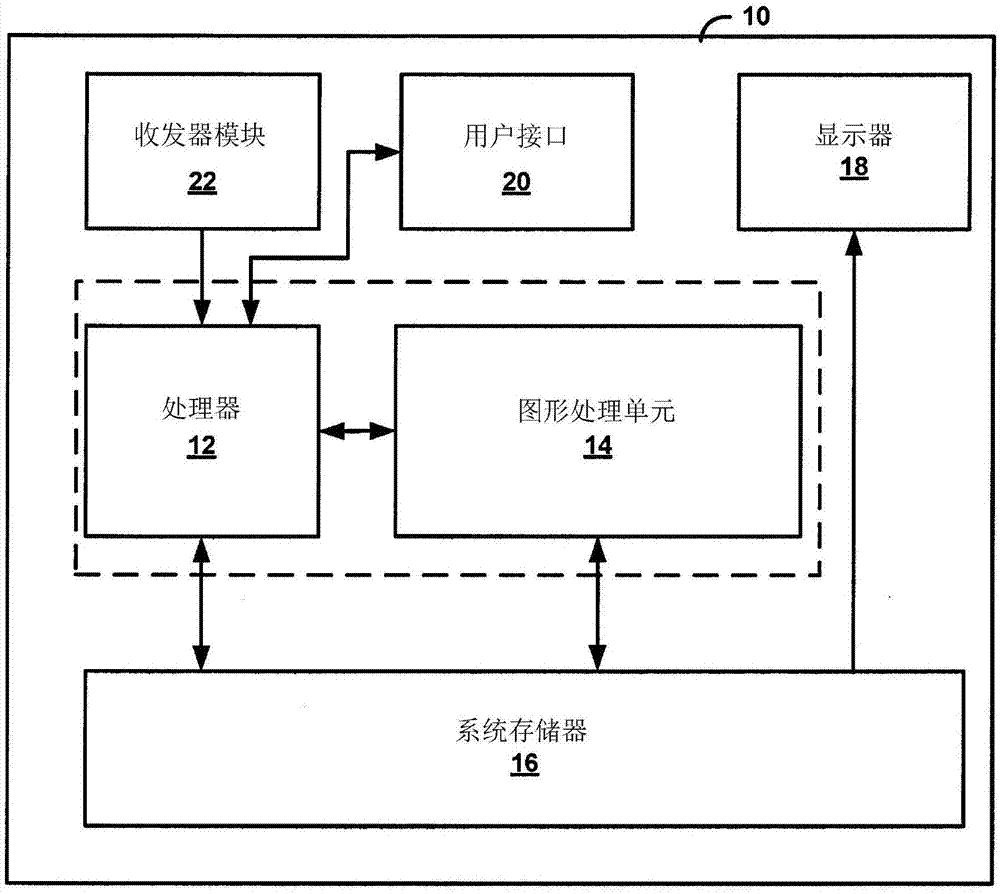
图1是说明根据本公开中所描述的用于使用统一断言执行着色器核心中的线程的一或多个实例技术的用于处理数据的实例装置的框图。图1说明装置10,其实例包含但不限于例如媒体播放器等视频装置、机顶盒、例如移动电话等无线通信装置、个人数字助理(PDA)、台式计算机、笔记本电脑、计算机、游戏控制台、视频会议单元、平板计算装置等等。
在图1的实例中,装置10包含处理器12、图形处理单元(GPU)14和系统存储器16。在一些实例中,例如装置10是移动装置的实例,处理器12和GPU 14可以形成为集成电路(IC)。举例来说,IC可以被认为是例如芯片上系统(SoC)的芯片封装内的处理芯片。在一些实例中,例如其中装置10是台式计算机或笔记本电脑的实例,处理器12和GPU 14可装纳在不同集成电路(例如,不同芯片封装)中。然而,在装置10是移动装置的实例中,处理器12和GPU 14有可能装纳在不同集成电路中。
处理器12和GPU 14的实例包含但不限于一或多个数字信号处理器(DSP)、通用微处理器、专用集成电路(ASIC)、现场可编程逻辑阵列(FPGA)或其它等效的集成或离散逻辑电路。处理器12可为装置10的中央处理单元(CPU)。在一些实例中,GPU 14可以是专用硬件,其包含集成和/或离散逻辑电路,所述集成和/或离散逻辑电路向GPU 14提供适合于图形处理的大规模并行处理能力。在一些情况下,GPU 14还可包含通用处理能力,且在实施通用处理任务(即,非图形相关任务)时可被称为通用GPU(GPGPU)。
出于说明的目的,结合GPU 14描述本公开中所描述的技术。然而,本公开中所描述的技术不受此限制。本公开中所描述的技术可扩展到其它类型的并行处理单元(例如,提供大规模并行处理能力的处理单元,即使未用于图形处理)。此外,本公开中所描述的技术可扩展到未经具体配置以用于并行处理的处理单元。
处理器12可执行各种类型的应用程序。应用程序的实例包含操作系统、网络浏览器、电子邮件应用程序、电子数据表、视频游戏或生成用于显示的可视对象的其它应用程序。系统存储器16可存储用于执行一或多个应用程序的指令。在处理器12上执行应用程序使得处理器12产生用于有待显示的图像内容的图形数据。处理器12可向GPU 14发射图像内容的图形数据以供进一步处理。
作为一个实例,在处理器12上执行应用程序使得处理器12能够产生图元的顶点,其中相应顶点处的图元的互连形成图形对象。在此实例中,处理器12产生的图形数据是用于所述顶点的属性的属性数据。举例来说,在处理器12上执行的应用程序可以生成顶点的色彩值、不透明度值、坐标等,这些全都是顶点的属性的实例。还可存在额外属性,且在一些实例中,应用程序无需产生全部实例属性。一般来说,所述技术可以扩展到属性数据之外的数据类型(例如,计数器),且所述技术不应当被视为受限于属性数据或受限于例如色彩值、不透明度值、坐标等属性数据的实例。
在一些非图形相关实例中,处理器12可以生成更适合于通过GPU 14处理的数据。此些数据无需用于图形或显示目的。举例来说,处理器12可以输出需要通过GPU 14对其执行矩阵运算的数据,且GPU 14又可以执行矩阵运算。
一般来说,处理器12可以将处理任务分担给GPU 14,所述处理任务例如需要大规模并行运算的任务。作为一个实例,图形处理需要大规模并行运算,且处理器12可将此类图形处理任务分担到GPU 14。然而,例如矩阵运算等其它运算也可得益于GPU 14的并行处理能力。在这些实例中,处理器12可利用GPU 14的并行处理能力,以使得GPU 14执行非图形相关运算。
处理器12可根据特定应用处理接口(API)与GPU 14通信。此类API的实例包含的API、克罗诺斯(Khronos)组织的或OpenGL以及OpenCLTM;然而,本公开的各方面不限于DirectX、OpenGL或OpenCL API,且可扩展到其它类型的API。此外,本公开中所描述的技术不需要根据API起作用,且处理器12和GPU 14可利用任何通信技术。
装置10还可包含显示器18、用户接口20和收发器模块22。装置10可包含出于清楚起见而未在图1中展示的额外模块或单元。举例来说,装置10可包含扬声器和麦克风(两者均未在图1中展示),以在装置10为移动无线电话的实例中实现电话通信。此外,装置10中所示的各种模块和单元可并不在装置10的每一实例中都是必要的。举例来说,在装置10为台式计算机的实例中,用户接口20和显示器18可在装置10外部。作为另一实例,在显示器18为移动装置的触敏或压敏显示器的实例中,用户接口20可为显示器18的一部分。
显示器18可以包括液晶显示器(LCD)、阴极射线管(CRT)显示器、等离子显示器、触敏显示器、压敏显示器或另一类型的显示装置。用户接口20的实例包含但不限于轨迹球、鼠标、键盘和其它类型的输入装置。用户接口20也可为触摸屏且可并入作为显示器18的一部分。收发器模块22可包含允许装置10与另一装置或网络之间的无线或有线通信的电路。收发器模块22可包含调制器、解调器、放大器以及其它用于有线或无线通信的此类电路。
系统存储器16可以是装置10的存储器。系统存储器16可包括一或多个计算机可读存储媒体。系统存储器16的实例包含但不限于随机存取存储器(RAM)、电可擦除可编程只读存储器(EEPROM)、快闪存储器或可用于运载或存储呈指令和/或数据结构的形式的所要程序代码且可由计算机或处理器存取的其它媒体。
在一些方面中,系统存储器16可包含使处理器12和/或GPU 14执行在本公开中归属于处理器12和GPU 14的功能的指令。因此,系统存储器16可以是其上存储有指令的计算机可读存储媒体,所述指令在被执行时使一或多个处理器(例如,处理器12和GPU 14)执行各种功能。
在一些实例中,系统存储器16可为非暂时性存储媒体。术语“非暂时性”可指示存储媒体未体现于载波或传播信号中。然而,术语“非暂时性”不应解释为意味着系统存储器16是非可移动的或其内容为静态的。作为一个实例,可从装置10移除系统存储器16,且将所述系统存储器16移动到另一装置。作为另一实例,大体类似于系统存储器16的存储器可插入到装置10中。在某些实例中,非暂时性存储媒体可存储可随时间推移而改变(例如,在RAM中)的数据。
举例来说,如在本公开中的其它地方更详细地描述,系统存储器16可以存储用于在处理器12上实行的执行本公开中所描述的一或多个实例的技术的编译程序的代码。系统存储器16还可存储在GPU 14的着色器核心上执行的着色器程序(例如,顶点着色器、像素或片段着色器、计算着色器等)的代码。
术语图形项在本公开中用于是指GPU 14执行并行处理的基本单位。GPU 14可以并行(例如,同时)处理多个图形项。举例来说,顶点着色器可以处理顶点,且GPU 14可以并行执行顶点着色器的多个例子以同时处理多个顶点。类似地,像素或片段着色器可以处理显示器的像素,且GPU 14可以并行执行像素着色器的多个例子以同时处理显示器的多个像素。顶点和像素是图形项的实例。
对于非图形相关应用,术语图形项还指GPU 14执行处理的最小单位。然而,此类处理可能不是图形相关的。因此,术语“图形项”的意思是指图形处理单元(例如,GPU 14)或通用图形处理单元(例如,其中GPU 14充当GPGPU的实例)将要并行处理的项。图形项可以用于图形或非图形目的。
如将在下文更详细地阐释,根据本公开的各种实例,GPU 14可经配置以接收GPU中线程束的所有线程将执行第一指令集中的相同分支的指示,将一或多个断言位作为单组断言位存储在存储器中,其中单组断言位适用于线程束中的所有线程,以及根据单组断言位执行第一指令集的部分。
图2是更详细地说明图1中所说明的装置的组件的框图。如图2中所说明,GPU 14包含着色器核心24,其包含通用寄存器(GPR)26、统一断言寄存器(UPR)92,以及固定功能管线30。着色器核心24和固定功能管线30可以一起形成处理管线,其用于执行图形或非图形相关功能。处理管线执行由在GPU 14上执行的软件或固件定义的功能,且由经硬接线以执行特定功能的固定功能单元执行功能。
在GPU 14上执行的软件和/或固件可被称为着色器程序(或简单地称为着色器),且着色器程序可以在GPU 14的着色器核心24上执行。虽然仅仅说明一个着色器核心24,但是在一些实例中,GPU 14可以包含类似于着色器核心24的一或多个着色器核心。固定功能管线30包含固定功能单元。着色器核心24和固定功能管线30可以从彼此发射和接收数据。举例来说,处理管线可以包含在着色器核心24上执行的着色器程序,其从固定功能管线30的一个固定功能单元接收数据,且向固定功能管线30的另一固定功能单元输出经处理数据。
着色器程序为用户和/或开发人员提供功能灵活性,因为用户可设计着色器程序以按任何可设想方式执行所要的任务。然而,针对固定功能单元执行任务的方式而硬接线固定功能单元。因此,固定功能单元可不提供许多功能灵活性。
着色器程序的实例包含顶点着色器程序32、片段着色器程序34和计算着色器程序36。顶点着色器程序32和片段着色器程序34可以是用于图形相关任务的着色器程序,且计算着色器程序36可以是用于非图形相关任务的着色器程序。在一些实例中,可仅使用如顶点着色器程序32和片段着色器程序34的图形相关着色器程序。在一些实例中,可仅使用如计算着色器程序36的非图形相关着色器程序。存在例如几何形状着色器的着色器程序的额外实例,出于简洁目的未予描述。
在处理器12上执行的图形驱动程序40可经配置以实施应用程序编程接口(API)。在此类实例中,可根据与图形驱动程序40相同的API配置着色器程序(例如,顶点着色器程序32、片段着色器程序34和计算着色器程序36)。尽管未说明,但系统存储器16可存储用于图形驱动程序40的代码,处理器12从系统存储器16检索所述代码以用于执行。在虚线框中说明图形驱动程序40以指示在此实例中,图形驱动程序40是在硬件(例如,处理器12)上执行的软件。然而,图形驱动程序40的功能性中的一些或全部可以实施为处理器12上的硬件。
图形驱动程序40可经配置以允许处理器12和GPU 14与彼此通信。举例来说,当处理器12将图形或非图形处理任务分担到GPU 14时,处理器12经由图形驱动程序40将此些处理任务分担到GPU 14。
作为实例,处理器12可以执行产生图形数据的游戏应用程序,且处理器12可以将此图形数据的处理分担到GPU 14。在此实例中,处理器12可以在系统存储器16中存储图形数据,且图形驱动程序40可以指令GPU 14何时检索图形数据,在系统存储器16中从哪里检索图形数据,以及何时处理图形数据。此外,游戏应用程序可要求GPU 14执行一或多个着色器程序。举例来说,游戏应用程序可能需要着色器核心24来执行顶点着色器程序32和片段着色器程序34,以生成将显示(例如,显示在图1的显示器18上)的图像。图形驱动程序40可以指令GPU 14何时执行着色器程序,且指令GPU 14从哪里检索着色器程序所需的图形数据。以此方式,图形驱动程序40可以在处理器12与GPU 14之间形成链接。
图形驱动程序40可以根据API配置;但是图形驱动程序40不需要限于根据特定API配置。在装置10是移动装置的实例中,可以根据OpenGL ES API配置图形驱动程序40。OpenGL ES API具体被设计成用于移动装置。在装置10为非移动装置的实例中,可以根据OpenGL API配置图形驱动程序40。其它实例API包含微软公司的API的DirectX系列。
在一些实例中,系统存储器16可存储用于顶点着色器程序32、片段着色器程序34和计算着色器程序36中的一或多个的源代码。在这些实例中,在处理器12上执行的编译程序38可编译这些着色器程序的源代码,以创建GPU 14的着色器核心24在运行时(例如,在这些着色器程序需要在着色器核心24上执行的时间)期间可执行的对象或中间代码。在一些实例中,编译程序38可以预编译着色器程序,且在系统存储器16中存储着色器程序的对象或中间代码。
着色器核心24可经配置以并行执行相同着色器程序的相同指令的许多例子。举例来说,图形驱动程序40可以指令GPU 14检索多个顶点的顶点值,且指令GPU 14执行顶点着色器程序32以处理所述顶点的顶点值。在此实例中,着色器核心24可执行顶点着色器程序32的多个例子,且通过针对顶点中的每一个在着色器核心24的一个处理元件上执行顶点着色器程序32的一个例子而执行此操作。
着色器核心24的每一处理元件可以在相同例子执行顶点着色器程序32的相同指令;然而,特定顶点值可能是不同的,因为每一处理元件在处理不同的顶点。如上文所描述,每一处理元件可被视为执行顶点着色器程序32的线程,其中线程是指正在处理特定顶点的顶点着色器程序32的一个指令。以此方式,着色器核心24可执行顶点着色器程序32的许多例子以并行(例如,同时)处理多个顶点的顶点值。
着色器核心24可类似地执行片段着色器程序34的许多例子以并行处理多个像素的像素值,或执行计算着色器程序36的许多例子以并行处理许多非图形相关数据。以此方式,着色器核心24可以用单指令多数据(SIMD)结构配置。为易于描述,关于通用着色器程序描述以下内容,所述通用着色器程序的实例包含顶点着色器程序32、片段着色器程序34、计算着色器程序36和例如几何形状着色器的其它类型的着色器。
系统存储器16可以存储用于编译程序38的代码,处理器12从系统存储器16检索所述代码以用于执行。在图2的实例中,在虚线框中说明编译程序38,以指示在此实例中编译程序38是在硬件(例如,处理器12)上执行的软件。然而,在一些实例中,编译程序38的一些功能性可以实施为处理器12上的硬件。
根据本公开的技术,处理器12可经配置以确定来自着色器程序(例如,顶点着色器程序32、片段着色器程序34、计算着色器程序36或任何其它着色器程序)的特定指令集是否包含分支指令。在此实例中,指令集可以是将使用着色器核心24(例如,SIMD处理核心)执行为线程束(例如,并行使用多个线程)的特定指令集。在处理器12上执行的编译程序38可经配置以确定用于线程束的指令集包含分支指令。
图3是展示包含分支指令39的指令集37的概念图。在此实例中,分支指令39是如果-则-否则分支指令。在一般意义上,术语‘如果(条件)’确定特定条件是否为真(例如,通过比较一个值与另一值)。不管如何确定条件,如果条件为真,那么着色器核心24中的处理元件执行指令集37的第一部分41(例如,与‘则’分支相关联的指令的部分)。如果条件不为真,那么处理元件执行指令集37的第二部分43(例如,与‘否则’分支相关联的指令的部分)。
返回参考图2,GPU 14和/或编译程序38可经配置以确定线程束的每一线程将如何采用分支指令。基于此确定,GPU 14和/或编译程序38可对线程束的每一线程分配断言位,以指示线程将如何采用分支指令。实际上,断言位指示特定线程将执行指令集的哪些部分。举例来说,断言位可指示图3的第一部分41或图3的第二部分43是否经执行。
在一些实例中,断言位可指定执行指令集的哪些部分。在其它实例中,断言位指示不执行指令集的哪些部分。无论如何,线程束的每一线程并行执行指令集。如果特定线程不执行如由断言位所指示的指令集的特定部分,那么特定线程不执行动作(例如,不执行操作指令),同时线程束中的其它线程执行指令集的特定部分。
根据本公开的技术,处理器12(例如,通过编译程序38的执行)可经进一步配置以确定线程束的所有线程是否将采用分支指令的相同分支。如果作出此确定,那么编译程序38可指示GPU 14设置可用于线程束中的每一线程的单组统一断言位。也就是说,当所有线程采用条件分支指令的相同分支时,仅存储单组断言位,而非具有针对线程束的每一线程的单独的断言位。
举例来说,编译程序38可经配置以将单组统一断言位存储或使GPU 14存储在UPR 92中。UPR 92可以是寄存器或可由执行线程束的特定线程的着色器核心24中的每一处理元件存取的任何其它类型的存储器。编译程序38可确定线程束的所有线程以任何方式采用条件分支指令的相同分支。举例来说,编译程序38可在线程束的输入值是基于常量且从统一通用寄存器(uGPR)获取的状况下作出此确定。
作为一个实例,在编译着色器程序(例如,顶点着色器程序32、片段着色器程序34或计算着色器程序36)时,编译程序38可确定将执行为线程束的着色器程序的指令集是否需要存取统一数据。在此上下文中,着色器程序需要存取统一数据意指在着色器核心24的相应处理元件上执行的着色器程序的每一线程各自请求相同数据。在此实例中,着色器核心24可从uGPR中检索此相同数据。
作为另一实例,着色器程序可包含分支指令(例如,如果-则-否则指令)。对于一些特定分支,着色器程序可包含将一或多个变量设置成等于恒定值的指令(例如,将所有x、y、z和w坐标设置成等于0的指令)。在此实例中,编译程序38可确定恒定值是用于图形项的变量的数据,其跨线程束中的所有线程是统一的。
如果编译程序38确定着色器程序需要存取跨图形波统一的数据,那么编译程序38可以包含显式指令,其向着色器核心24指示数据跨图形波是统一的。作为响应,GPU 14可在UPR 92中设置统一断言位。在一些实例中,统一数据可存储于经分配用于存储统一数据的GPR 26的区段中(即,可由线程束的所有线程统一存取的数据)。经分配用于统一数据的GPR 26的此区段可被称为uGPR。
考虑包含分支指令的代码的一般实例。举例来说,在高级语言中,分支指令的实例可以是:
<程序的其余部分>
如果编译程序38无法确定R0和R1的值是‘统一的’,那么将使用每线程断言位。然而,如果编译程序38确定值R0和R1是统一的(例如,如果,那么所使用的值来自常量寄存器),那么可代替地使用‘统一’断言(UP0):
<程序的其余部分>
图4是说明GPU的着色器核心的GPR中的数据存储装置的实例的概念图。如所说明,GPU 14包含着色器核心24,且着色器核心24包含GPR 26。尽管未在图4种说明,但着色器核心24还包含各自执行着色器程序的例子的多个处理元件。
作为一实例,着色器核心24可以包含三十二个处理元件,且每个处理元件可以执行着色器程序的一个例子以处理一个图形项。GPR 26可以存储所述图形项的数据。举例来说,GPR 26可以存储用于三十二个图形项的九个属性的属性数据。然而,GPR 26可以存储用于三十二个图形项的多于或少于九个属性的数据。此外,GPR 26可以存储与图形项的属性无关联但是为处理图形项所需的变量的数据的数据。
在图4中说明的实例中,图形项识别为P0-P31,其可以是顶点。通过图形项识别符之后的变量识别属性。举例来说,P0.X是指P0图形项的x坐标,P0.Y是指P0图形项的y坐标等等。P0.R、P0.G、P0.B和P0A分别是指P0图形项的红色分量、绿色分量、蓝色分量和不透明度。类似地识别其它图形项(例如,P1-P31)。
换句话说,在图4中,顶点P0-P31各自与多个变量相关联。作为一个实例,顶点P0-P31中的每一个与识别x坐标(P0.X到P31.X)的变量相关联。顶点P0-P31中的每一个与识别y坐标(P0.Y到P31Y)等等的变量相关联。处理所述多个图形项中的每一个需要这些变量中的每一个。举例来说,处理顶点P0-P31中的每一个需要识别x坐标的变量。
也如图4中所说明,图形项中的每一个还包含PRJ属性。PRJ属性是在着色器核心24的处理元件上执行的顶点着色器可以利用的投影矩阵。在此实例中,PRJ属性是处理顶点P0-P31中的每一个所需的另一变量。举例来说,顶点着色器可将投影矩阵与相应坐标相乘(例如,将P0.PRJ与P0.X、P0.Y、P0.Z和P0.W相乘)。
应理解,可存在GPU 14可以在其中存储数据(例如,值)的各种单元。GPU 14可以在系统存储器16中存储数据,或可以在本地存储器(例如,高速缓冲存储器)中存储数据。着色器核心24的GPR 26不同于系统存储器16和GPU 14的本地存储器两者。举例来说,系统存储器16可由装置10的各种组件存取,且这些组件使用系统存储器16存储数据。GPU 14的本地存储器可由GPU 14的各种组件存取,且这些组件使用GPU 14的本地存储器来存储数据。然而,GPR 26可能只可由着色器核心24的组件存取,或可以仅仅存储用于着色器核心24的处理元件的数据。
在一些实例中,图形波中的图形项的一或多个变量跨图形波是统一的。在此类实例中,GPU 14可将统一数据单次存储在uGPR 27中,而非将用于每一线程的单独条目中的一或多个变量的统一数据存储在GPR 26中。如图4中所展示,uGPR 27是GPR 26的部分。在其它实例中,uGPR 27可以是单独的寄存器。
在一个实例中,uGPR 27可包含多个存储位置,其中每一存储位置与图形项的多个属性的一个属性相关联。举例来说,如图4中所说明,每一图形项P0-P31包含九个属性(PRJ、x、y、z、w、R、G、B和A)。在此实例中,uGPR 27可以包含九个存储位置,其中uGPR 27的第一位置与PRJ属性相关联,uGPR 27的第二位置与x坐标相关联,等等。同样,uGPR 27中的数据可供线程束的每一线程使用。
图5是说明可用于实施本公开的统一断言的技术的GPU 14的实例配置的框图。GPU 14经配置以按并行方式执行用于程序的指令。GPU 14包含着色器核心24,所述着色器核心24包含控制单元72、处理元件74A-74D(统称为“处理元件74”)、指令存储装置76、数据存储装置78、通信路径80、82、84、86A-86D、断言寄存器(PR)75A-75D(统称为“断言寄存器75或PR 75”),以及统一断言寄存器(UPR)92。通信路径86A-86D可统称为“通信路径86”。在一些实例中,GPU 14可经配置为单指令多数据(SIMD)处理系统,其经配置以使用处理元件74执行程序(例如,着色器)的线程束的多个执行线程。在此SIMD系统中,相对于不同数据项处理元件74可一起一次处理单个指令。在完成执行与程序相关联的所有线程之后,可退出程序。
控制单元72经由通信路径80以通信方式耦合到指令存储装置76,经由通信路径82耦合到处理元件74,并经由通信路径84耦合到数据存储装置78。控制单元72可使用通信路径80以将读取指令发送到指令存储装置76。读取指令可指定指令存储装置76中指令应检索的指令地址。响应于发送读取指令,控制单元72可从指令存储装置76接收一或多个程序指令。控制单元72可使用通信路径82以将指令提供到处理元件74,且在一些实例中,从处理元件74接收数据,例如,用于评估分支条件的比较指令的结果。在一些实例中,控制单元72可使用通信路径84以从数据存储装置78检索数据项值,例如以确定分支条件。尽管图4将GPU 14说明为包含通信路径84,但在其它实例中,GPU 14可不包含通信路径84。
处理元件74中的每一个可经配置以处理存储于指令存储装置76中的程序的指令。在一些实例中,处理元件74中的每一个可经配置以执行相同操作集合。举例来说,处理元件74中的每一个可实施相同指令集架构(ISA)。在额外实例中,处理元件74中的每一个可为算术逻辑单元(ALU)。在另外的实例中,GPU 14可经配置为向量处理器,且处理元件74中的每一个可为向量处理器内的处理元件。在额外实例中,GPU 14可为SIMD执行单元,且处理元件74中的每一个可为SIMD执行单元内的SIMD处理元件。
由处理元件74所执行的运算可包含算术运算、逻辑运算、比较运算等。算术运算可包含例如加法运算、减法运算、乘法运算等运算。算术运算还可包含例如整数算术运算和/或浮点算术运算。逻辑运算可包含例如逐位“与”运算、逐位“或”运算、逐位“异或”运算等的运算。比较运算可包含例如大于运算、小于运算、等于零运算、不等于零运算等运算。大于运算和小于运算可确定第一数据项是否大于或小于第二数据项。等于零运算和不等于零运算可确定数据项是否等于零或不等于零。用于运算的运算数可存储于数据存储装置78中所含有的寄存器中。
处理元件74中的每一个可经配置以响应于经由通信路径82从控制单元72接收指令而执行操作。在一些实例中,处理元件74中的每一个可经配置以经激活和/或经去激活,与其它处理元件74无关。在此类实例中,处理元件74中的每一个可经配置以响应于在激活相应处理元件74A-74D时从控制单元72接收指令而执行操作;且响应于在去激活(即,未激活)相应处理元件74A-74D时从控制单元72接收指令而并不执行操作。
处理元件74A-74D中的每一个可经由相应通信路径86A-86D以通信方式耦合到数据存储装置78。处理元件74可经配置以从数据存储装置78检索数据并经由通信路径86将数据存储到数据存储装置78。在一些实例中,从数据存储装置78所检索的数据可为用于由处理元件74所执行的运算的运算数。在一些实例中,存储到数据存储装置78的数据可为由处理元件74所执行的运算的结果。
指令存储装置76经配置以存储程序,以供GPU 14执行。程序可存储为指令序列。在一些实例中,每一指令可由唯一指令地址值寻址。在此些实例中,指令序列中的稍后指令的指令地址值大于指令序列中的较前指令的指令地址值。在一些实例中,程序指令可为机器级指令。即,在此等实例中,指令可为对应于GPU 14的ISA的格式。指令存储装置76经配置以经由通信路径80从控制单元72接收读取指令。读取指令可指定应从中检索指令的指令地址。响应于接收读取指令,指令存储装置76可经由通信路径80将对应于读取指令中所指定的指令地址的指令提供到控制单元72。
指令存储装置76可为任何类型的存储器、高速缓冲存储器或其组合。当指令存储装置76为高速缓冲存储器时,指令存储装置76可高速缓存存储于GPU 14外部的程序存储器中的程序。尽管指令存储装置76经说明为在GPU 14内,但在其它实例中,指令存储装置76可在GPU 14外部。
数据存储装置78经配置以存储由处理元件74所使用的数据项。在一些实例中,数据存储78可包括多个寄存器,每一寄存器经配置以存储在GPU 14上操作的多个数据项内的相应数据项。数据存储装置78可耦合到经配置以在数据存储装置78的寄存器与存储器或高速缓冲存储器(未展示)之间传送数据的一或多个通信路径(未展示)。
尽管图4说明用于存储由处理元件74所使用的数据的单个数据存储装置78,但在其它实例中,GPU 14可包含用于处理元件74中的每一个的单独、专用数据存储装置。出于示范性目的,GPU 14说明四个处理元件74。在其它实例中,GPU 14可具有呈相同或不同配置的更多处理元件。
控制单元72经配置以控制GPU 14执行存储于指令存储装置76中的程序的指令。对于程序的每一指令或指令集,控制单元72可经由通信路径80从指令存储装置76检索指令,并处理指令。在一些实例中,控制单元72可通过使对处理元件74中的一或多个执行与指令相关联的操作而处理指令。举例来说,由控制单元72检索的指令可为指示GPU 14相对于由指令所指定的数据项执行算术运算的算术指令,且控制单元72可使处理元件74中的一或多个以对指定数据项执行算术运算。在另外的实例中,控制单元72可在无需使得对处理元件74执行操作的情况下处理指令。
控制单元72可通过经由通信路径82将指令提供到处理元件74而致使对处理元件74中的一或多个执行操作。指令可指定待由处理元件74执行的操作。提供到处理元件74中的一或多个的指令可与从指令存储装置76检索的指令相同或不同。在一些实例中,控制单元72可通过激活应在其上执行操作的处理元件74的特定子集和去激活不应在其上执行操作的处理元件74的另一子集中的一或两个来使对处理元件74(包含由单个处理元件)的特定子集执行操作。控制单元72可通过经由通信路径82将相应激活和/或去激活信号提供到处理元件74中的每一个而激活和/或去激活处理元件74。在一些实例中,控制单元72可通过将激活和/或去激活信号提供到处理元件74以及将指令提供到处理元件74而激活和/或去激活处理元件74。在另外的实例中,控制单元72可在将指令提供到处理元件74之前激活和/或去激活处理元件74。
控制单元72可使用处理元件74执行程序的多个执行线程。并行执行的多个线程有时被称为线程束。处理元件74中的每一个可经配置以针对多个线程中的相应线程而处理程序指令。举例来说,控制单元72可将每一执行线程分配到处理元件74中的个别一个以供处理。相对于数据项集合中的不同数据项,程序的执行线程可执行相同指令集。举例来说,处理元件74A可关于多个数据项中的第一数据项子集执行存储于指令存储装置76中的程序的第一执行线程,且处理元件74B可关于多个数据项中的第二数据项子集执行存储于指令存储装置76中的程序的第二执行线程。第一执行线程可与第二执行线程包含相同指令,但第一数据项子集可不同于第二数据项子集。
在一些实例中,控制单元72可激活并去激活多个执行线程中的个别线程。当控制单元72去激活线程时,控制单元72也可去激活和/或停用经分配以执行所述线程的处理元件74A-74D。此些经去激活的线程可被称为非活动线程。类似地,当控制单元72激活线程时,控制单元72也可激活经分配以执行所述线程的处理元件74A-74D。此些经激活的线程可被称为活动线程。如将在下文更详细地阐释,控制单元72可经配置以选择激活线程来执行发散操作(例如,串行操作),而不需要考虑其它活动或非活动线程。
如本文中所使用,活动线程可指经激活的线程,且非活动线程可指经去激活的线程。对于在给定处理循环期间GPU 14上执行的多个线程,活动线程中的每一个可经配置以在处理循环期间处理通过用于多个线程的全局程序计数器寄存器所识别的程序的指令。举例来说,控制单元72可激活处理元件74,其经分配到活动线程以便配置此些处理元件74以在处理循环期间处理程序的指令。另一方面,对于在给定处理循环期间GPU 14上执行的多个线程,非活动线程中的每一个可经配置以不在处理循环期间处理程序的指令。举例来说,控制单元72可去激活处理元件74,其经分配到非活动线程以配置此些处理元件74从而不在处理循环期间处理程序的指令。
在一些实例中,处理循环可指程序计数器的连续载入之间的时间间隔。举例来说,处理循环可指当程序计数器载入第一值时与当程序计数器载入第二值时之间的时间。第一和第二值可为相同或不同值。在程序计数器归因于恢复检查技术而以异步方式载入的实例中,此些异步载入在一些实例中可不用以区分处理循环。换句话说,在这些实例中,处理循环可指程序计数器的连续同步载入之间的时间间隔。在一些实例中,程序计数器的同步载入可指由时钟信号触发的载入。
有时,在检索下一指令之前,控制单元72确定待由GPU 14处理的下一指令。控制单元72确定待处理的下一指令的方式取决于先前通过GPU 14所检索到的指令是否为控制流指令而不同。如果先前通过GPU 14所检索到的指令不是控制流指令,那么控制单元72可确定待由GPU 14处理的下一指令对应于存储于指令存储装置76中的下一顺序指令。举例来说,指令存储装置76可以经排序序列存储程序指令,且下一顺序指令可为紧接在先前所检索到的指令之后出现的指令。
如果先前通过GPU 14所检索到的指令为控制流指令,那么控制单元72可基于控制流指令中所指定的信息而确定待由GPU 14处理的下一指令。举例来说,控制流指令可为非条件控制流指令(例如,非条件分支指令或跳转指令),在此状况下控制单元72可确定待由GPU 14处理的下一指令为通过控制流指令识别的目标指令。作为另一实例,控制流指令可为条件控制流指令(例如,条件分支指令),在此状况下控制单元72可从指令存储装置76选择通过控制流指令所识别的目标指令或存储于指令存储装置76中的下一顺序指令中的一个作为待处理的下一指令。
如本文中所使用,控制流指令可指包含识别指令存储装置76中的目标指令的信息的指令。举例来说,控制流指令可包含指示控制流指令的目标程序计数器值的目标值。目标程序计数器值可指示目标指令的目标地址。在一些实例中,目标指令可不同于存储于指令存储装置76中的下一顺序指令。高级程序代码可包含控制流语句,例如if、switch、do、for、while、continue、break和goto语句。编译程序38可将高级控制流语句转译成低级(例如,机器级)控制流指令。并非控制流指令的指令可在本文中被称作顺序指令。举例来说,顺序指令可不包含识别目标指令的信息。
对于控制流指令,识别目标指令的信息可为指示存储于指令存储装置76中的目标指令的值。在一些实例中,指示指令存储装置76中的目标指令的值可为指示指令存储装置76中的目标指令的指令地址的值。在一些状况下,指示目标指令的指令地址的值可为指令存储装置76中的目标指令的地址。在额外状况下,指示目标指令的指令地址的值可为用于计算目标指令的地址的值。在另外的实例中,指示目标指令的指令地址的值可为指示对应于目标指令的目标程序计数器值的值。在一些状况下,指示目标程序计数器值的值可为对应于目标指令的目标程序计数器值。在额外状况下,指示目标程序计数器值的值可为用于计算目标程序计数器值的值。在一些实例中,对应于目标指令的目标程序计数器值可等于目标指令的地址。
控制流指令可为前向控制流指令或后向控制流指令。前向控制流指令可为目标指令出现在存储于指令存储装置76中的指令的经排序序列中的控制流指令之后的控制流指令。后向控制流指令可为目标指令出现在存储于指令存储装置76中的指令的经排序序列中的下一顺序指令之前的控制流指令。下一顺序指令可紧接在指令的经排序序列中的控制流指令之后出现。
控制流指令可为条件控制流指令或非条件控制流指令。条件控制流指令包含指定用于跳转到与控制流指令相关联的目标指令的条件的信息。当处理条件控制流指令时,如果控制单元72确定满足条件,那么控制单元72可确定待处理的下一指令为目标指令。另一方面,如果控制单元72确定并不满足条件,那么控制单元72可确定待处理的下一指令为存储于指令存储装置76中的下一顺序指令。非条件控制流指令并不包含指定用于跳转到与控制流指令相关联的目标指令的条件的信息。当处理非条件控制流指令时,控制单元72可以非条件方式确定待处理的下一指令为通过控制流指令所识别的目标指令。换句话说,此状况下的确定并不取决于非条件控制流指令中所指定的任何条件。如本文中所使用,条件控制流指令可在本文中被称作分支指令,除非分支指令以其它方式被指定为非条件分支指令。此外,非条件控制流指令可在本文中被称作跳转指令。
条件分支指令可包含关于一或多个数据项值所指定的条件。举例来说,一种类型的条件可以是将用于在GPU 14中执行的每一活动线程的第一数据项值与第二数据项值进行比较的比较条件。比较数据项值可包含例如确定第一数据项值是否大于、小于、不大于、不小于、等于或不等于第二数据项值。另一类型的条件可为确定执行于GPU 14的每一活动线程的数据项值是否等于或不等于零的零检查条件。由于处理元件74中的每一个对不同数据项进行操作,因此对于GPU 14上执行的每一活动线程来说,评估条件的结果可以是不同的。
如果GPU 14上执行的所有活动线程均满足分支条件或GPU 14上执行的所有活动线程不满足分支条件,那么统一分支条件出现且据称线程的分支发散为统一的。另一方面,如果GPU 14上执行的活动线程中的至少一个满足分支条件和GPU 14上执行的活动线程中的至少一个不满足分支条件,那么发散分支条件出现且据称线程的分支发散为发散的。
发散指令的一个实例是如果-则-否则指令。如上文所论述,在处理如果-则-否则指令时,‘如果(条件)’术语确定特定条件是否为真(例如,通过比较一个值与另一值)。不管如何确定条件,如果条件为真,那么着色器核心24中的处理元件74执行指令集的第一部分(例如,部分41)。如果条件不为真,那么处理元件74执行指令集的第二部分(例如,部分43)。在一些实例中,根据分支条件执行的指令的部分可以是无操作指令(例如,分支指令可包含不执行任何操作的指令)。
为了指示处理元件74中的每一个如何处理分支指令,控制单元72可将断言位存储在相应断言寄存器75中的每一个中。每一处理元件74可存取与特定处理元件相关联的专用PR 75。这是因为处理元件74中的每一个通常对不同数据进行操作。因而,分支指令的条件可对于处理元件74中的每一个而不同(即,对于分支的每一线程而不同)。
如上文所论述,断言位指示指令集的哪些部分将由特定线程且因此特定处理元件74执行。在一些实例中,断言位可指定执行指令集的哪些部分。在其它实例中,断言位指示不执行指令集的哪些部分。无论如何,线程束的每一处理元件74并行执行指令集。如果特定处理元件74的确未执行如由断言位所指示的指令集的特定部分,那么特定处理元件74不执行动作(例如,执行无操作指令),而线程束中的其它处理元件74执行指令集的所述特定部分。
根据本公开的技术,处理器12(例如,通过编译程序38的执行)可经进一步配置以确定线程束的所有线程是否将采用分支指令的相同分支。如果作出此确定,那么编译程序38可指示GPU 14设置可用于线程束中的每一线程的单组统一断言位。也就是说,当所有线程采用条件分支指令的相同分支时,仅存储单组断言位,而非具有针对线程束的每一线程的单独的断言位。
举例来说,控制单元72可经配置以响应于针对第一指令90线程束的所有线程将执行分支指令的相同指令的确定而将单组统一断言位93存储在UPR 92中。第一指令90可以是包含分支指令的着色器程序的任何指令集。存储于UPR 92中的断言位93可由执行线程束的处理元件74中的每一个存取。通过包含用于所有处理元件74的单组断言位93,可节省电力,这是因为仅对断言集执行单个测试(与对于每一线程的断言的测试相反)。
图6是图1的GPU的另一实例着色器核心的更详细框图。在图6的实例中,着色器核心24与图5中所展示的着色器核心相同,例外为标量处理单元94的添加。在此实例中,在UPR 92中的断言位指示线程束的所有线程在相同方向上分支且将处理的数据是统一的状况下,标量处理单元94可用于执行第一指令90。以此方式,可使用单个标量处理单元94来处理对统一数据执行的统一分支的第一指令90,而非使用包含处理元件74的向量处理器。在一些实例中,处理元件74可接着用以与标量处理单元94并行处理第二指令91(其可不经统一分支)。
使用标量处理单元94执行统一分支的指令,如由UPR 92中的断言位93所指示,提供一些实施益处。这是因为标量处理单元94无需访问PR 75来确定指令集如何分支。因而,由处理元件74执行的第二指令91与由标量处理单元94执行的第一指令90之间不存在‘冲突’或模糊状态。这允许并行处理第一指令90和第二指令91。
标量处理单元94可以是经配置以一次对一个数据项进行操作的任何类型的处理器。与处理元件74相似,标量处理单元94可包含ALU。由标量处理单元94所执行的运算可包含算术运算、逻辑运算、比较运算等。算术运算可包含例如加法运算、减法运算、乘法运算、除法运算等的运算。算术运算还可包含例如整数算术运算和/或浮点算术运算。逻辑运算可包含例如逐位“与”运算、逐位“或”运算、逐位“异或”运算等的运算。比较运算可包含例如大于运算、小于运算、等于零运算、不等于零运算等运算。大于运算和小于运算可确定第一数据项是否大于或小于第二数据项。等于零运算和不等于零运算可确定数据项是否等于零或不等于零。用于运算的运算数可存储于数据存储装置78中所含有的寄存器中。
在一些情况下,第一指令90的每一线程以相同方式分支,这是因为将由线程束操作的每一数据项或图形项是相同值。在此实例中,标量处理单元94仅需要执行一个运算且运算的结果可经存储用于待处理的所有数据元件。
图7是说明根据本公开的技术的实例方法的流程图。图7的技术可由GPU 14和/或处理器12中的一或多个实施(参见图1)。
在本公开的一个实例中,GPU 14可经配置以接收GPU 14中线程束的所有线程将执行第一指令集中的相同分支的指示(100)。GPU 14可经进一步配置以将一或多个断言位作为单组断言位存储在存储器中,其中单组断言位适用于线程束中的所有线程(102)。GPU 14可经进一步配置以根据单组断言位执行第一指令集的部分(104)。
在本公开的一个实例中,单组断言位指示将由线程束的每一线程执行的第一指令集的部分,指令集的部分与第一指令集中的相同分支相关。在本公开的另一实例中,单组断言位指示将不由线程束的每一线程执行的第一指令集的部分,指令集的部分与第一指令集中的相同分支相关。
在本公开的另一实例中,GPU 14可经配置以使用SIMD处理核心(例如,图5的处理元件74)根据单组断言位执行第一指令集。在本公开的另一实例中,GPU 14可经配置以使用标量处理单元(例如,图6的标量处理单元94)根据单组断言位执行第一指令集。在一个实例中,GPU 14可经配置以在使用标量处理单元根据单组断言位执行第一指令集的同时使用SIMD处理核心执行第二指令集。
在本公开的另一实例中,处理器12可经配置以确定GPU中线程束的所有线程将执行第一指令集的相同分支,且响应于确定而指示。在另一实例中,处理器12可经配置以通过确定用于第一指令集的整个线程束使用相同常量集或通过确定用于第一指令集的整个线程束使用来自适用于线程束的所有线程的统一通用寄存器(uGPR)的数据来确定GPU 14中的线程束的所有线程将执行第一指令集的相同分支。
在一或多个实例中,所描述功能可用硬件、软件、固件或其任何组合来实施。如果用软件实施,那么所述功能可作为一或多个指令或代码在计算机可读媒体上存储或发射,且由基于硬件的处理单元执行。计算机可读媒体可包含计算机可读存储媒体,其对应于例如数据存储媒体的有形媒体。以此方式,计算机可读媒体通常可以对应于非暂时性的有形计算机可读存储媒体。数据存储媒体可为可由一或多个计算机或一或多个处理器存取以检索用于实施本公开中描述的技术的指令、代码和/或数据结构的任何可用媒体。计算机程序产品可包含计算机可读媒体。
借助于实例而非限制,此类计算机可读存储媒体可包括RAM、ROM、EEPROM、CD-ROM或其它光盘存储装置、磁盘存储装置或其它磁性存储装置、快闪存储器,或可用以存储呈指令或数据结构形式的所要程序代码且可由计算机存取的任何其它媒体。应理解,计算机可读存储媒体和数据存储媒体并不包含载波、信号或其它暂时性媒体,而是替代地涉及非暂时性有形存储媒体。如本文中所使用,磁盘和光盘包含压缩光盘(CD)、激光光盘、光学光盘、数字多功能光盘(DVD)、软性磁盘和蓝光光盘,其中磁盘通常以磁性方式再现数据,而光盘用激光以光学方式再现数据。以上各项的组合也应包含于计算机可读媒体的范围内。
指令可以由一或多个处理器执行,所述一或多个处理器例如是一或多个数字信号处理器(DSP)、通用微处理器、专用集成电路(ASIC)、现场可编程逻辑阵列(FPGA)或其它等效的集成或离散逻辑电路。因此,如本文中所使用的术语“处理器”可指上述结构或适用于实施本文中所描述的技术的任何其它结构中的任一个。另外,在一些方面中,本文中所描述的功能性可在经配置以用于编码和解码的专用硬件和/或软件模块内提供,或并入在组合的编解码器中。此外,所述技术可完全实施于一或多个电路或逻辑元件中。
本公开的技术可实施于各种装置或设备中,各种装置或设备包含无线手持机、集成电路(IC)或IC组(例如,芯片组)。本公开中描述各种组件、模块或单元是为了强调经配置以执行所公开的技术的装置的功能方面,但未必需要由不同硬件单元实现。实际上,如上文所描述,各种单元可结合合适的软件和/或固件组合在编解码器硬件单元中,或通过互操作硬件单元的集合来提供,所述硬件单元包含如上文所描述的一或多个处理器。
已经描述各种实例。这些和其它实例在所附权利要求书的范围内。
- 还没有人留言评论。精彩留言会获得点赞!