互联网存在的评分的制作方法
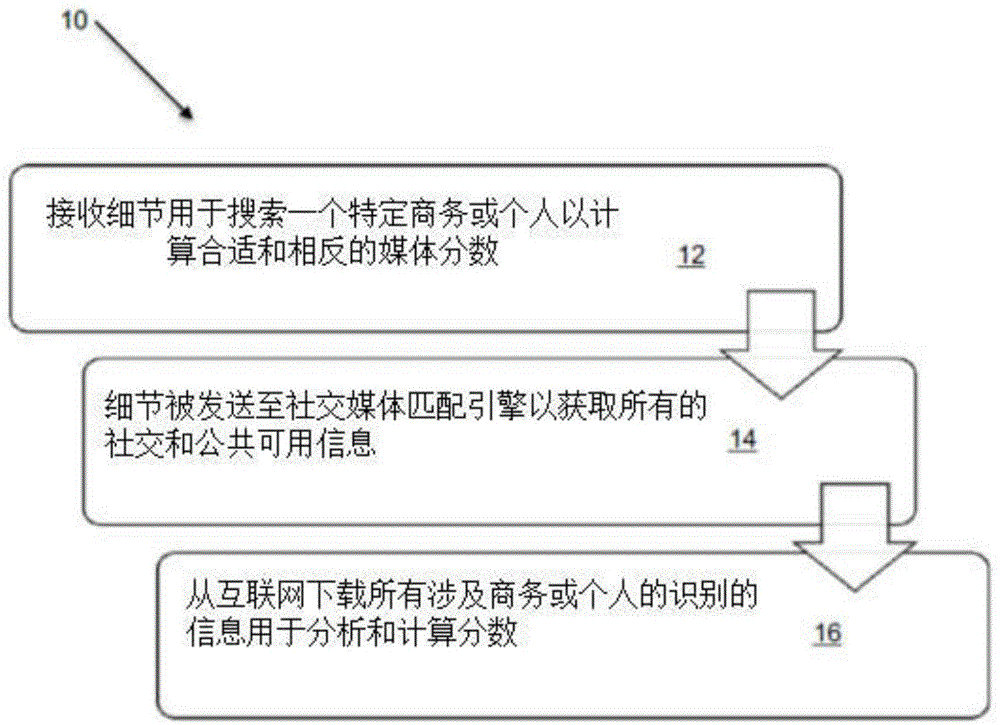
本发明涉及互联网存在的评分。特别地,本发明涉及一种将分数分配给一个受试者的互联网存在的方法和一种社交媒体存在分析系统。
背景技术:
:发明人知道可以用于对用户的社交媒体使用进行分类的社交媒体应用。然而,社交媒体应用都没有提供将风险概况与用户的社交媒体活动相关联的方法。这种风险概况对于评估用户进入某些类型的交易的风险是有用的,无论是商业交易还是就业协议等。技术实现要素:根据本发明的第一方面,提供了一种为一个受试者的互联网存在分配分数的方法,该方法包括:接收要对其社交媒体存在进行评分的受试者的搜索项;使用搜索参数进行互联网搜索以编辑出现搜索参数的网站(包括社交媒体网站)的初步搜索结果;评估初步搜索结果以确认初步搜索结果超出预定义的最小匹配阈值与搜索项;从超过预定义的最小匹配阈值的初步搜索结果中编辑最终搜索结果;在结构化数据库中编辑最终搜索结果;在结构化数据库中评估与一组预定义评估标准相关的最终搜索结果的文本;根据预定义的评分方案为该组预定义评估标准集合中的每个元素分配分数;通过整理预定义评估标准集合中的每个元素的分数来编辑受试者的社交媒体存在的最终分数。搜索的网站可以包括社交媒体网站,并且网站上的受试者的存的最终分数可以包括在社交媒体网站上的受试者的存在。因此,受试者的互联网存在包括受试者的社交媒体存在。接收被评估的受试者的社交媒体存在的搜索项,可以包括接收受试者的社交媒体帐户的用户名。可选的,接收被评估的受试者的社交媒体存在的搜索项,可以包括基于受试者的个人详细信息来编辑社交媒体搜索项的列表。个人详细信息可以包括受试者的姓名,姓氏,昵称,雇主,兴趣,爱好,国家,民族和组织关系,当前职业和过去职业,位置等。使用搜索项进行互联网搜索以编辑网站的初步搜索结果,可以包括系统地使用网络爬虫,rss订阅源和应用程序接口(api)以返回在互联网上找到的文本,其包括被搜索的搜索项。该方法可以包括将最终搜索结果从非英语语言翻译成英语。该步骤可以包括检测外语,然后应用翻译应用程序将文本从非英语语言翻译成英语。评估初步搜索结果以确认初步搜索结果超过预定义的最小匹配阈值可以包括将找到的文本与待搜索的搜索项集合进行比较,并编辑搜索项和搜索结果之间的相关性分数。预定义评估标准的集合可以包括受试者的意识形态,受试者使用的语调,受试者的情绪表达,受试者使用的语言,受试者的组织,受试者的兴趣。在结构化数据库中编辑最终搜索结果可以包括将搜索结果的文本排列到数据库中的字段中。例如,结构化数据库可以包含以下字段:唯一系统标识符,找到信息的源,受试者标识符,从源提取的信息,分配给受试者的意识形态,受试者的情感分数,语言使用分数,与受试者相关的实体或个体,受试者使用的语调,受试者的兴趣等。在结构化数据库中评估与一组预定义的评估标准相关的最终搜索结果的文本,可以包括将文本中使用的语言分类为数据库中的至少一些字段的多个预定义备选。例如,找到信息的来源可以包括:新闻源,博客,论坛,网站,广播,社交媒体站点等。受试者标识符可以包括:姓名,社交媒体帐户,身份证号码,物理地址,手机号码,雇主详细信息等。分析文本后分配给受试者的意识形态。受试者的情绪得分可以包括:快乐,悲伤,紧张,担心,痛苦等。语言使用得分可以包括:犯规,冒犯,亵渎,坏话,咒骂词,政治,性,种族等。受试者使用的语调可以包括:欣赏,热情,傲慢,苦涩,顺从,批判,困惑,居高临下等。该受试者的兴趣可能包括:飞机定位,喷枪,气枪,表演,航模,业余天文,业余无线电,动物/宠物/狗,射箭,足球,柔道,定点跳伞,篮球海滩/日晒,赶海等。根据预定义的评分方案将分数分配给该组预定评估标准中的每个元素可以包括为该组预定评估标准中的每个元素的结果分配一个数值。将分数分配给该组预定义评估标准中的每个元素可以包括将权重与预定义评估标准的每个元素相关联。通过整理该组预定义评估标准中的每个元素的分数来编译受试者的社交媒体存在的最终分数可以包括将该组预定义评估标准的每个元素的分数与预定义评估标准的该元素的权重相乘。该步骤可以包括将最终分数标准化为百分比。该方法可以包括将标准化百分比分配到预定风险带中的步骤。例如,风险带可以定义为0到50%之间的分数,导致受试者处于低风险,在51到80%之间的分数导致受试者处于中等风险中并且在81和100%之间的分数导致受试者处于高风险。本发明扩展到社交媒体存在分析系统,其包括:社交聆听者,可用于接收社交媒体输入流;语言分析层,可用于检测接收文本的非英语语言并将文本语言翻译成英语;结构化数据库,用于将英文文本存储在一组预定义的数据字段中;自然语言处理器,可用于以从结构化数据库访问数据并分析与一组预定义评估标准相关的文本语言;社交媒体评分引擎,可用于从自然语言处理器接收输入并基于受试者的社交媒体存在来计算受试者的分数。由社交媒体得分计算器计算的分数可以指示受试者的社交媒体风险分数。现在将参考以下附图仅通过非限制性示例描述本发明。附图说明在图中:图1示出了根据本发明的一个方面的将分数分配给受试者的互联网存在的方法的概述;图2示出了根据本发明一个方面的社交媒体存在分析系统的概述架构;图3示出了作为图1的方法的一部分的社交监听器的操作;图4示出了作为图1的方法的一部分的数据结构和语言转换层的操作图5示出了形成图1的方法的一部分的评分引擎的数据文件准备的操作;图6示出了本发明的评分引擎的功能框图;图7示意性地示出了作为图1的方法的一部分的第三方数据的输入;图8示意性地示出了一个数据库,其中存储了作为图1的方法的一部分而生成的数据;图9示意性地示出了如何分析由评分系统生成的数据的示例;图10显示了图8的数据库的数据字段;和图11显示了图9中所示的数据分析的评估。具体实施方式在图1中,示出了将分数分配给受试者的互联网存在的方法的广泛概述(10)。在该示例中,受试者的社交媒体存在将用于解释本发明。在(12)处接收要评分的特定受试者的细节。受试者可以是个人或实体。搜索是在受试者姓名和受试者上可用的其他详细信息上进行的。在(14)处,将受试者的细节转发到匹配引擎以在互联网上公开可用的所有数据中进行检索,其以一种方式或另一种方式链接到受试者的任何细节。通常,公开可用的数据可以是社交媒体信息或其他公共数据,例如白页信息,法院程序信息,在(16),将与在14处提供的受试者的细节匹配的互联网的数据在服务器上进行检索,并且分析数据并基于预定义的评分算法生成分数。在图2中,示出了根据本发明的一个方面的社交媒体存在分析系统(30)的概述架构。社交监听器(32)被示出并且用于从历史调度器(34)和记录调度器(36)接收信息。来自社交监听器(32)的输入馈送到管理源服务(38),其中文本馈送被转发到交互生成阶段(42)。从交互生成阶段(42)文本被馈送到结构化层(44)。在图3中示出了社交监听器(32)的操作(50),作为将得分分配给受试者的社交媒体存在(10)的方法的一部分,如图1所示。在(52),评估是否已经接收到受试者的社交媒体细节以及数据是否完整和充分。如果在(52)处已经接收到社交媒体细节,则在(54)处捕获细节。候选人的社交媒体细节通常可以是社交媒体帐户的用户或帐户名称,例如twitter帐户,facebook帐户,youtube帐户等。如果在(52)未接收到社交媒体细节,则搜索项是根据(56)处的受试者可获得的信息编译的。选择最能描述候选者的搜索项并手动输入系统。然后,系统通过利用特定算法和搜索功能生成自动搜索脚本,生成的配置文件脚本将用于搜索正在审查或正在评估的候选人或组织。输入的项可以包括身份证号码,姓名,姓,和雇主姓名,居住国家/地区,职位描述或提供最佳匹配的任何其他信息。在(58)处,搜索项被编程为网络爬虫以在互联网中爬行获得搜索项。搜索的数据类型可以包括任何数字媒体,例如文本,视频,图像,照片,语音,电子书,网页,网站等。根据网络爬虫检索的数据,与搜索项最匹配的在(56)被编译的项在(60)处被识别。例如,当超过80%的搜索文本与通过爬虫/api输入的受试者文本匹配时,定义为正匹配。如果未找到(或不充分)匹配,则可以将匹配百分比调整为较低百分比,或者如果识别出太多结果,则可以将匹配百分比调整为更高百分比。在(62)处,将与搜索项相关联的数据与关于候选人的文本一起导入社交监听器32,这对于分配分数是重要的。在(64),从互联网接收的所有数据都以正确的文本格式准备,读取在搜索项上搜集/收集的所有相关信息,用于从网络搜索个人或组织,并从非结构化格式标准化为结构化格式。在图4中,流程图(80)示出了通过数据结构和语言转换层如何将数据翻译成英语。在(82)处分析数据的文本并确定该语言是否是英语。如果语言是英语,则执行指向(84)并且不需要翻译文本。如果在(82)确定文本不是英语,则执行指向(86),其中检测到语言并且为文本分配语言标识符代码。例如,可以使用以下语言示例:在(88),系统使用系统自动分配的语言标识符代码将文本字段连接到正确的语言字典以转换成英语。在(90),文本被翻译成英文。图5示出了流程图(100)中的评分引擎的数据文件准备的操作。数据文件准备构成图1的方法的一部分。在(102),按照图4所示的方法从数据结构和语言转换层接收英语文本。评分引擎利用自然语言处理(nlp)。通过使用特定于从文本分析的方面的预定义词典和模板,从英语文本中提取语言信息。这些字典和模板通过与各种评分方面相关的自动在线分析收集技术不断更新和增强。这可确保词典保持相关性并保持最新,以确保分析的准确性。在(102),受试者的意识形态是通过分析受试者使用的词来确定的。在(104)处分析文本的语调以确定受试者是否具有激进的,被动的,不耐烦的,烦躁的或正常的语调等。例如,某些单词将与不同的语调相关联,例如积极的-爱的,深情的,多情的,宽容的消极的-暂时的,冷漠的,悲观的,超然的,沮丧的,不安的,被扰乱的,愤世嫉俗的在(106)处,分析文本以实现情绪分析算法以确定受试者的当前状态。例如,受试者的情绪状态将被分类为诸如恐惧,厌恶,悲伤,快乐,愤怒等类别。例如,某些单词将与情绪状态相关联,例如:在(108),文本被分析以将语言分类为和平,激进,政治,坏语言,粗俗,性,骚扰,种族,性别等。例如,某些单词将与某一类别的语言相关联,在(110)处分析社交媒体上与受试者的联系。例如,编辑包含与受试者链接或通信的人,组织,国家等的列表。在(112)处分析文本以确定受试者的兴趣,例如足球,旅行,钓鱼,橄榄球,烹饪,音乐,阅读,汽车等。该流程图终止于(112),其中从(102)到(112)中列出的各种评分方面计算的信息现在被转发到图2和6中的评分引擎(46)。应当理解,在确定社交媒体存在得分时,需要包括(102)至(112)中列出的所有上述因素。在本发明的各种实施例中,用于确定社交媒体存在分数的公式以及可用于确定是否显示活动指示符的较低阈值将变化。图6示出了评分引擎(46)的功能框图。应当理解,以下描述仅提供了如何生成得分的示例。用于计算社交媒体存在得分的参数如下所示:每个因素都可以加权,如下所示注意:各个因子权重的总和应始终等于100风险带的定义如下:0102030405060708090100其中介于0和50%之间的顾客是低风险介于51和80%之间的顾客是中等风险介于81和100%之间的顾客是高风险分数计算器的操作如下面的两个例子所示:示例2:·候选人是民主党人·她使用“爱”和“分享”等和平话语·她对环境问题非常感兴趣·她是拯救狗基金会的成员·她的语气非常平和在确定了受试者的总分后,将得分除以3(每个因子的最大点)对于候选人x:100/3=33.3使用风险带,这个人将处于低风险,因为她的得分低于50%。如图7中示意性所示,可以将任何第三方数据(130)导入分数计算器以进行分析。数据可以是供应商数据,员工数据或客户数据。该数据允许一次导入许多记录的批量导入。导入后,数据将自动进入搜索引擎,以便与执行手动搜索时的方式匹配社交媒体渠道和web中的数据。图8示意性地示出了数据库(130),其中存储了作为图1的方法的一方面生成的数据。数据库的数据字段在图10中进一步说明。在将分数分配给受试者的社交媒体存在的方法中生成的所有数据存储在数据库(130)中的图10所示的数据字段中。字段(150)存储唯一的系统标识符,字段(152)存储发现信息的来源,例如新闻,博客,论坛,网站,广播,社交媒体网站等。字段(154)存储受试者标识符,例如姓名,社交媒体帐户,身份证号码,物理地址,移动号码,雇主详细信息等。字段(156)存储从来源中提取的信息,其中的受试者标识符搜索中的信息也最匹配。field(158)存储在分析文本后分配给受试者的意识形态。字段(160)存储受试者的情绪分数,例如快乐,悲伤,紧张,担心,等。字段(162)存储语言使用分数,例如犯规,冒犯,亵渎,坏话,咒骂词,政治,性,种族等。字段(164)存储与受试者相关联的实体或个体。字段(166)存储受试者使用的语调,例如欣赏,热情,傲慢,苦涩,顺从,批判,困惑,居高临下等。字段(168)存储受试者的兴趣,如飞机定位,喷枪,气枪,表演,航模,业余天文,业余无线电,动物/宠物/狗,射箭,足球,柔道,定点跳伞,篮球海滩/日晒,赶海等。图9示意性地示出了如何分析由评分系统生成数据并且如图11中进一步示出数据分析的操作的示例。图11示出了对图9中所示的数据分析的评估。如上所述,社交媒体存在分析系统的用户可以搜索满足上面图3中所示的各种搜索要求的受试者。例如,搜索潜在雇员作为受试者的雇主可以输入适当的搜索查询并启动如图3的(58)和(60)中所示的搜索。作为搜索的一部分找到的一个或多个搜索目标然后可以通过应用程序(140)向搜索者显示,如图9所示。图9示意性地示出了执行搜索并查看搜索结果的应用程序。该应用程序是易于使用的图形用户界面(gui),其执行图3中所示的方法。由应用程序(140)生成的搜索结果可以包括与搜索标准匹配的每个目标的摘要信息,并且目标可以按以下顺序排序:一个或多个因素。一些因素可能包括得分,例如风险得分。还可以向应用程序(140)的用户提供查看任何目标信息的完整或部分概述的选项。该申请还提供了一种比较评分方法,以建立可以评估概况的比较基线。评分的比较方法可用于消除与其他可比得分明显不一致的分数。可以向社交媒体存在分析系统的用户显示所有搜索数据。社交媒体存在分析系统,特别是应用程序(140)可以与其他应用程序集成,以将受试者的附加信息在社交媒体存在分析系统进行检索,例如工资单系统,供应商数据库,客户数据库或员工制度。社交媒体存在分数可以被应用程序(140)作为自身的搜索字段。例如,社交媒体存在分析系统的用户可以请求超过或低于某个预定社交媒体阈值的所有受试者的列表。发明人认为,将分数分配给受试者的互联网存在的方法提供了一种评估与受试者可能参与的各种交易相关的风险的新方法,例如就业,信用评级等。类似地,社交媒体存在分析系统提供了一种新系统,该系统可用于评估与受试者的社交媒体存在相关联的风险。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1