基于预测位置数据的空间化音频输出的制作方法
本申请要求2016年4月8日申请的共同拥有的第15/094,620号美国非临时专利申请的优先权,其内容明确地以全文引用的方式并入本文中。
本公开大体上涉及产生空间化音频输出的装置和方法。
背景技术
技术的进步已产生更小且更强大的计算装置。举例来说,各种便携式个人计算装置(包含例如移动和智能电话的无线电话、平板计算机和笔记本计算机)体积小、重量轻且便于用户携带。这些装置可通过无线网络传达语音和数据包。此外,许多此类装置并入有额外功能,例如数字静态相机、数码摄像机、数字记录器和音频文件播放器。另外,此类装置可处理可执行指令,包含可用以接入因特网的软件应用程序,例如网络浏览器应用程序。由此,这些装置可包含相当大的计算和联网能力。
空间化音频再现系统可输出实现三维音频空间的用户感知的声音。举例来说,用户可戴上头戴式耳机或虚拟现实(vr)头戴式显示器(hmd),且用户的(例如用户头部的)移动(例如平移或旋转移动)可使声音的所感知方向或距离改变。执行空间化音频处理可能花费大量时间,从而导致音频时延。如果音频时延过大,声音的所感知方向或距离的改变就可能滞后于用户的移动,这可能对于用户来说可觉察。另外,执行空间化音频处理可能使用大量的处理资源。此类处理资源可能在至少一些电子装置(例如一些移动电话)中不可用,由此限制此类装置的空间化音频处理功能。
技术实现要素:
在特定方面,一种音频处理装置包含经配置以基于位置数据确定预测位置数据的位置预测器。所述音频处理装置进一步包含处理器,其经配置以基于所述预测位置数据产生输出空间化音频信号。
在特定方面,一种音频处理方法包含在处理器处接收来自一或多个传感器的位置数据。所述方法包含在所述处理器处基于所述位置数据来确定预测位置数据。所述方法进一步包含在所述处理器处基于所述预测位置数据来产生输出空间化音频信号。
在特定方面,一种设备包含用于基于位置数据而确定预测位置数据的装置。所述设备进一步包含用于基于所述预测位置数据而产生输出空间化音频信号的装置。
在特定方面,一种非暂时性计算机可读媒体存储指令,所述指令在由处理器执行时使所述处理器从一或多个传感器接收位置数据。所述指令使所述处理器基于所述位置数据来确定预测位置数据。所述指令进一步使所述处理器基于所述预测位置数据来产生输出空间化音频信号。
本公开的其它方面、优点和特征将在审阅整个申请之后变得显而易见,所述整个申请包含以下部分:附图说明、具体实施方式和权利要求书。
附图说明
图1a是经配置以基于预测位置数据而产生输出空间化音频信号的音频处理装置的第一实施方案的框图;
图1b是经配置以基于预测位置数据而产生输出空间化音频信号的音频处理装置的第二实施方案的框图;
图1c是经配置以基于预测位置数据而产生输出空间化音频信号的音频处理装置的第三实施方案的框图;
图2是包含或耦合到虚拟现实系统的头戴式显示器的音频处理装置的说明性实施方案的框图;
图3是包含或耦合到扬声器阵列的音频处理装置的说明性实施方案的框图;
图4是经配置以使用预测位置数据执行音频空间化的音频处理装置的说明性实施方案的框图;
图5是示出音频处理的特定方法的流程图;
图6是说明基于预测位置数据产生输出空间化音频信号的特定方法的流程图;以及
图7是可操作以根据图1a到c和2到6的系统和方法执行操作的无线装置的框图。
具体实施方式
下文参考图式描述本公开的特定方面。在描述中,贯穿图式由共同附图标记指示共同特征。如本文所使用,各种术语仅出于描述特定实施方案的目的而使用,且并非意在进行限制。举例来说,除非上下文另作明确指示,否则单数形式“一”和“所述”也意欲包含复数形式。可进一步理解,词语“包括”可与“包含”互换使用。另外,应理解,词语“其中(wherein)”可与“其中(where)”互换使用。如本文所使用,“示范性”可指示实例、实施方案和/或方面,且不应理解为限制或指示偏好或优选实施方案。如本文所使用,用于修饰例如结构、组件、操作等元件的序数词(例如“第一”、“第二”、“第三”等)自身并不指示所述元件相对于另一元件的任何优先权或次序,而是仅仅区别所述元件与具有相同名称(但所用序数词不同)的另一元件。如本文所使用,词语“组”是指一或多个元件的分组,且词语“多个”是指多个元件。
公开用于基于预测位置数据产生空间化音频信号的系统、装置和方法。位置数据可指示音频装置的位置或用户的位置。音频处理装置可基于位置数据确定预测位置数据,所述预测位置数据指示音频装置(或用户)在特定(例如未来)时间的预测位置。举例来说,音频处理装置可存储历史位置数据,且位置数据和历史位置数据可经分析以确定预测移动路径的速度、所估计轨迹或其它指示。预测位置数据可指示沿着预测移动路径(例如轨迹)在特定时间的预测位置。所述特定时间可经选择以考虑与处理空间化音频信号相关联的时延(例如延迟)。
作为说明,音频处理装置可将空间化音频信号提供到为用户产生音频输出(例如听觉声音)的音频装置。在特定实施方案中,音频处理装置可集成在虚拟现实(vr)系统或扩增现实(ar)系统中。音频输出可以是三维(3d)音频输出,其使用户能够感知3d音频空间中的声音相对于用户位置(在游戏(或其它虚拟现实环境)或现实中)的方向或距离。举例来说,如果用户在玩游戏且在游戏中汽车驶到用户左侧,那么音频输出使用户能够感知来自用户左侧的汽车声音。如果用户在游戏中右转以使得汽车在用户后方,那么音频处理装置会处理空间化音频信号以使得音频输出改变,使得用户体会到来自用户后方的汽车声音。然而,与处理空间化音频信号相关联的时延(例如延迟)可能导致音频输出的改变滞后于用户位置或定向的改变,这对于用户来说可能可觉察。
为了防止或减小音频输出滞后于用户移动的可能性,音频处理装置可基于预测位置数据而非基于位置数据(例如指示用户“当前”、“实际”或“实时”位置的数据)来产生输出空间化音频信号。作为说明,音频处理装置可估计时延大约为10毫秒(ms),且作为响应,音频处理装置可确定指示用户的预测位置(例如,预测用户或用户头部在未来10ms中将在何处)的预测位置数据。音频处理装置可基于预测位置数据处理空间化音频信号,使得空间化音频信号改变声音的所感知方向或距离以对应于预测位置数据。作为特定的非限制性实例,音频处理装置可基于预测位置数据产生旋转矩阵,且音频处理装置可将旋转矩阵应用于空间化音频信号以产生输出空间化音频信号。因此,当空间化音频信号的处理完成时(例如在时延之后),输出空间化音频信号与用户的位置和定向同步,这可防止或减小音频滞后的可能性且改进用户体验。
作为进一步说明,音频处理装置可从一或多个传感器接收位置数据,所述一或多个传感器经配置以跟踪用户(或用户穿戴的音频装置)的位置和定向,或跟踪用户在虚拟环境中的位置和定向。举例来说,音频处理装置可从集成于vr系统的头戴式显示器(hmd)内的一或多个位置传感器、一或多个运动传感器或其组合接收位置数据。作为另一实例,音频处理装置可从跟踪用户位置和定向的一或多个相机或其它光学传感器接收位置数据。作为另一实例,音频处理装置可从vr系统的控制器、姿势捕捉装置、运动捕捉装置或用于vr系统或ar系统的某一其它控制装置接收位置数据。在特定实施方案中,音频处理装置耦合到音频装置。举例来说,音频处理装置可以是以通信方式耦合到音频装置(例如hmd、头戴装置、扬声器阵列等)的移动电话。在另一特定实施方案中,音频处理装置集成于音频装置内。举例来说,音频处理装置可包含集成于音频装置(例如hmd、头戴装置、扬声器阵列等)内且经配置以执行本文所描述的一或多个操作的处理器。
在一些实施方案中,音频处理装置可基于当前位置数据、历史位置数据或这两者确定预测位置数据。举例来说,音频处理装置可分析当前位置数据和历史位置数据以确定用户(或用户头部)的预测轨迹,且预测位置数据可指示沿着预测轨迹在特定时间的位置。可基于速度、基于加速度、使用卡尔曼滤波(kalmanfiltering)、使用粒子滤波或使用其它方法来确定预测轨迹。如上文所描述,可基于与在音频处理装置处处理空间化音频信号相关联的时延来确定所述特定时间。音频装置可基于预测位置数据处理空间化音频信号(例如特定实例:通过产生应用旋转矩阵以及执行立体声化)以使得声音的所感知方向或距离改变,使得在处理完成时(例如在时延之后),声音的所感知方向或距离将对应于或通过与用户(在vr世界或现实中)的位置和定向同步。因此,声音的所感知方向或距离的改变可更密切跟踪用户的移动(在vr世界或现实中),这可改进用户体验。
在另一实施方案中,音频处理装置可在再现特定空间化音频信号期间存储对应于用户(在vr世界或现实中)的移动的多个预测轨迹。另外或替代地,音频处理装置可接入至少一个其它装置(例如经由无线接口或其它网络接口),所述至少一个其它装置存储预测轨迹数据和空间化音频信号。举例来说,音频装置可从另一装置(例如服务器)接收包含预测轨迹数据、空间化音频信号或这两者的数据流。音频处理装置可选择最密切匹配所估计轨迹的所存储预测轨迹,且音频处理装置可存取对应于所存储预测轨迹的经处理空间化音频信号。经处理空间化音频信号可用于在音频装置处起始音频输出。在其中(例如在存储器处)预处理且存储经处理音频信号的此类实施方案中,音频处理装置可在不实时处理空间化音频信号的情况下提供空间化音频输出体验。另外,在一些实施方案中,音频处理装置可确定可用处理资源对于实时处理(例如基于预测位置数据)来说是否足够,或是否将基于预处理空间化音频信号产生输出,且可基于音频处理装置处变化的条件而在实时与预处理模式之间切换。
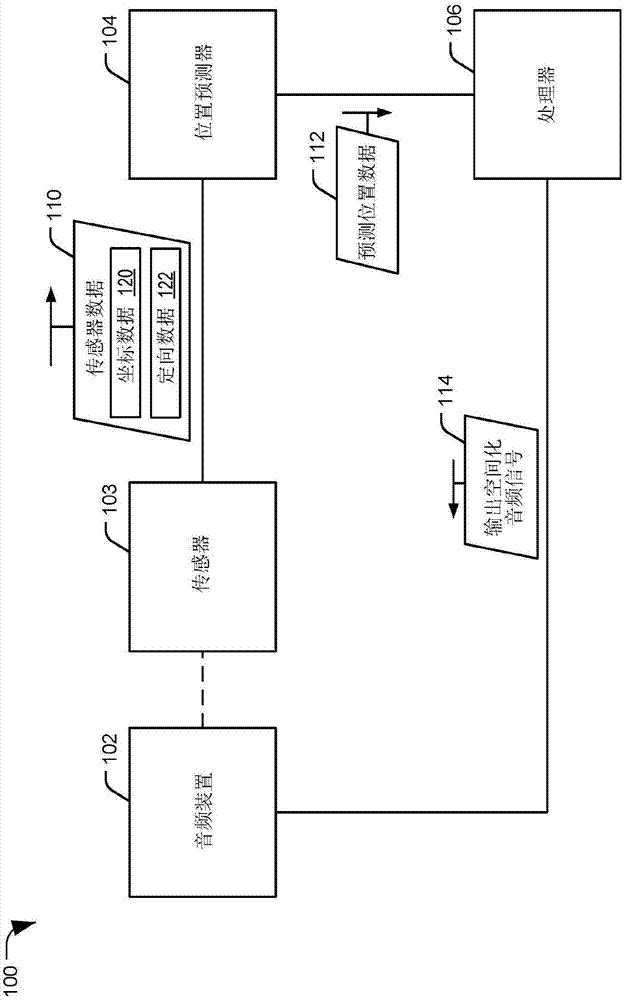
参考图1a,展示音频处理装置的第一实施方案,且将其总体上指示为100。音频处理装置100经配置以基于预测位置数据产生输出空间化音频信号。音频处理装置100包含音频装置102、一或多个传感器103、位置预测器104和处理器106。在图1a中说明的特定实施方案中,位置预测器104在传感器103和处理器106外部且与之不同。在另一特定实施方案中,位置预测器104可包含在传感器103中,如参考图1b进一步描述。在另一特定实施方案中,位置预测器104可包含在处理器106中,如参考图1c进一步描述。
音频装置102可包含经配置以向用户输出听觉声音的一或多个装置。举例来说,音频装置102可包含换能器(或多个换能器)。如在本文中进一步描述,可使用三维(3d)再现技术再现空间化音频信号以使得音频装置102输出听觉声音。作为非限制性实例,可使用高阶立体混响(hoa)技术再现空间化音频信号。归因于3d再现,用户可将听觉声音感知为3d状态,这可使用户能够感知对应于听觉声音的一或多个声源的方向、距离或这两者。举例来说,对于开门的听觉声音,用户可感知门在其右侧(而非其左侧)打开的声音。
在特定实施方案中,音频装置102包含虚拟现实(vr)系统或扩增现实(ar)系统的头戴式显示器(hmd)(或集成于所述hmd内)。举例来说,除用于显示视觉信息的显示屏之外,hmd还可包含用于播放音频的头戴式耳机。vr系统(或ar系统)可经配置以显示媒体内容,例如电影,且提供交互内容,例如视频游戏、演示、虚拟会议等。虚拟现实系统输出的视觉图和音频可基于用户的移动(例如用户头部的移动)而改变。举例来说,如果用户向侧方转头,虚拟现实系统输出的视觉图可改变以表示侧方视图,且虚拟现实系统输出的音频可改变以使得在旋转之后,先前感知为出自侧方的声音似出自正向方向。另外或替代地,传感器103可包含在或集成在用户与vr系统(或ar系统)之间的控制接口(例如控制器)中。举例来说,vr系统(或ar系统)可包含经配置以接收用户输入的手持式控制器,且用户在虚拟环境内的位置、定向和移动可基于用户输入而确定。举例来说,用户可使用操纵杆、控制垫、平板计算机、鼠标或其它外围装置输入控制用户通过由vr系统(或ar系统)呈现的虚拟环境的移动。传感器103还可包含一或多个触摸传感器、姿势传感器、语音传感器或其它传感器装置,且用户输入可包含语音命令、姿势、移动或触摸垫上的压力改变或其它形式的用户输入以控制vr系统(或ar系统)。
在另一特定实施方案中,音频装置102可包含头戴装置(例如一对头戴式耳机)。通过头戴装置输出的声音可基于用户移动(例如用户头部的移动)而改变。举例来说,用户可能在听音乐会,且可能感知到左侧在奏长笛。如果用户转向左侧,声音可改变,使得用户感知到长笛在用户前方演奏。因此,通过音频装置102输出的声音可基于音频装置102的位置、音频装置102的定向或这两者而改变。在一些实施方案中,音频装置102的位置(和定向)可对应于用户头部的位置(和定向)。举例来说,由于用户将hmd(或头戴装置)戴在其头上,因此音频装置102的位置(和定向)表示用户头部的位置(和定向)。
在另一特定实施方案中,音频装置102可包含布置为扬声器阵列的一或多个扬声器。一或多个扬声器可包含一或多个音频放大器和一或多个音频滤波器,其经配置以实施波束成形以在特定方向上引导音频波(例如音频输出)。在此实施方案中,音频装置102(例如音频滤波器)可经配置以基于空间化音频信号而在特定方向上引导音频输出。因此,经由扬声器阵列收听音频内容的用户可因波束成形而能够基于用户(例如用户头部)的移动感知声源的方向或距离的改变。在一些实施方案中,为了实现波束成形,除空间化音频信号之外,音频装置102还可接收控制数据。控制数据可由音频滤波器用以执行波束成形操作。
一或多个传感器103可经配置以确定可对应于位置数据的传感器数据110。举例来说,一或多个传感器103可包含加速度计、陀螺仪传感器、定向传感器、线性位置传感器、近程传感器、运动传感器、角位置传感器、全球定位系统(gps)传感器、超声波传感器,或能够确定平移位置(例如,x-y-z坐标等坐标空间中的位置)、定向(例如俯仰、侧转和横滚角度,如参考图2进一步描述)或这两者的任何其它传感器。传感器数据110可因此包含坐标数据120、定向数据122或这两者。
在一些实施方案中,一或多个传感器103集成于音频装置102内。举例来说,音频装置102可包含虚拟现实系统的hmd,所述hmd具有经配置以确定音频装置102以及(相关地)用户的位置和定向的多个传感器。在其它实施方案中,一或多个传感器103可与音频装置102分开(例如在其外部)。举例来说,一或多个传感器103可包含一或多个光学传感器,例如相机,其经配置以确定用户的位置和定向。所述一或多个光学传感器可经配置以跟踪用户的位置、用户的移动或这两者。在一些实施方案中,所述移动和定向可能限于用户头部的移动和定向。在其它实施方案中,用户的移动和定向可包含用户躯干、整个用户或其它测量方面的移动和定向。一或多个光学传感器可经配置以输出指示用户位置和定向的传感器数据110。在其它实施方案中,传感器103可集成在与音频装置102相关联的控制接口中,且传感器数据110可指示用户在虚拟环境(或扩增现实环境)中的位置。因此,如本文所使用,“位置数据”可指用户(或音频装置102)在“现实世界”中的位置或用户在虚拟环境或扩增现实环境中的位置。
位置预测器104经配置以基于位置数据(例如传感器数据110)产生预测位置数据112。在特定实施方案中,位置预测器104经配置以存储历史位置数据,且基于所述历史位置数据和传感器数据110确定预测位置数据112。举例来说,位置预测器104可将传感器数据110指示的位置、定向或这两者与历史位置数据指示的一或多个先前位置和定向进行比较以确定用户的预测轨迹。作为说明,可内插不同测量位置或定向(或这两者)以确定预测位置或预测定向(或这两者)。位置预测器104可使用预测轨迹确定用户(或音频装置102)的预测位置(例如,预测位置可以是沿着预测轨迹的与特定时间相关联的位置)。另外或替代地,位置预测器104可基于传感器数据110和历史位置数据来确定音频装置102(或用户)的速度、音频装置102(或用户)的加速度或这两者。预测位置可基于速度、加速度或这两者而确定,且预测位置可通过预测位置数据112指示。举例来说,预测位置数据112可指示预测坐标、预测定向测量值、指示预测位置的其它信息或其组合。
位置预测器104可经配置以将预测位置数据112提供到处理器106。处理器106可包含一或多个处理器或处理单元、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其组合。在一些实例中,处理器106可经配置以执行一或多个计算机可读指令以执行本文所描述的操作。举例来说,处理器可耦合到存储可通过所述处理器执行的指令的存储器或其它非暂时性计算机可读媒体。或者或另外,本文所描述的一或多个操作可使用硬件(例如专用电路)执行。
处理器106可经配置以基于预测位置数据112产生输出空间化音频信号114。输出空间化音频信号114可包含已基于预测位置数据112修改或选择的空间化音频信号。输出空间化音频信号114可提供到音频装置102以用于产生音频输出(例如听觉声音)。在特定实施方案中,处理器106(或音频处理装置100的额外组件)可经配置以执行3d声音再现以产生3d输出音频信号,且3d输出音频信号可用于在音频装置102处产生音频输出。执行3d声音再现可包含执行立体声化、高阶立体混响(hoa)处理、头部相关传递函数(hrtf)滤波、立体声空间脉冲响应(brir)滤波、基于对象的3d音频处理、基于通道环绕声处理、其它3d音频再现操作或其组合。另外,在一些实施方案中,可在使用3d输出音频信号以在音频装置102处产生音频输出之前执行后加工,例如放大、阻抗匹配、额外滤波、数/模转换或其组合。在特定实施方案中,输出空间化音频信号114是hoa信号。
在一些实施方案中,音频处理装置可从至少一个其它装置接收空间化音频信号以用于处理。举例来说,音频处理装置100可包含无线接口(或其它网络接口),其经配置以发送数据到至少一个其它装置以及从至少一个其它装置接收数据,且所述至少一个其它装置可存储空间化音频信号。作为说明,音频处理装置100可经由无线接口从另一装置(例如服务器)接收一或多个数据流。所述一或多个数据流可包含空间化音频信号、用于处理空间化音频信号(如参考图2进一步描述)的其它数据或这两者。另外或替代地,音频处理装置100可包含存储空间化音频信号、其它数据(例如预测轨迹数据)或这两者的存储器。
在特定实施方案中,处理器106可经配置以“实时”(或近实时)处理空间化音频信号。实时(或近实时)处理是指在空间化音频信号的播放期间处理空间化音频信号以修改空间化音频信号,使得空间化音频信号被感知为与用户移动同步。处理器106可经配置以基于预测位置数据112处理输入空间化音频信号以产生输出空间化音频信号114。作为说明,如果用户头部移动或旋转,或如果用户在虚拟环境中移动或旋转,处理器106会修改输入空间化音频文件,使得3d空间中的一或多个声源的所感知方向或距离基于所述移动而被修改。作为非限制性实例,声源可以是电影中说话的人物、音乐会中演奏的乐器、电话会议期间说话的个人、虚拟现实视频游戏中发出噪声的车辆或对应于输入空间化音频信号的任何其它声源。
处理器106可经配置以基于预测位置数据112确定旋转,且所述旋转可应用于输入空间化音频信号以产生输出空间化音频信号114。在特定实施方案中,所述旋转可对应于旋转矩阵,且处理器106可确定旋转矩阵且将其应用于输入空间化音频信号以产生输出空间化音频信号114。参考图4进一步描述旋转矩阵。在另一特定实施方案中,处理器106可经配置以基于预测位置数据112确定一或多个向量且将所述一或多个向量应用于输入空间化音频信号以应用所述旋转。在另一特定实施方案中,处理器106可经配置以基于预测位置数据112确定数据集且将所述数据集的一或多个元素应用于输入空间化音频信号以应用所述旋转。在另一特定实施方案中,处理器106可经配置以基于方位角和仰角或预测位置数据112所指示的其它信息而从查找表、数据库或另一存储位置检索一或多个值。处理器106可进一步经配置以将所述一或多个值应用于输入空间化音频信号以应用所述旋转。
因为处理(例如产生和应用旋转矩阵、执行额外再现步骤或这两者)输入空间化音频信号对于处理器106来说可能是个复杂和资源密集的过程,所以可能引入时延。举例来说,10ms的时延可与处理输入空间化音频信号以产生输出空间化音频信号相关联。参考图4进一步描述确定音频处理时延的说明性实例。因此,音频输出的改变(例如声音的所感知方向或距离的改变)可能滞后于用户的移动达所述时延量,这可导致用户可察觉的同步问题。
为了避免(或减小)同步问题和滞后时间,处理器106可经配置以基于预测位置数据112产生输出空间化音频信号114。举例来说,替代基于指示当前位置的位置数据处理输入空间化信号,处理器106可基于指示在某一未来时间的预测位置的预测位置数据来处理输入空间化音频信号。所述未来时间可经选择以补偿时延。举例来说,如果时延是10ms,那么处理器106可基于对应于未来10ms的预测位置处理输入空间化音频信号,使得在预测位置正确的情况下,在未来时间处的声音输出匹配音频装置102(或用户)在该未来时间处的位置和定向。因此,通过基于预测位置数据112产生输出空间化音频信号114,用户移动与声音方向或距离的感知的改变之间的迟滞可消除(或减小)。在一些实施方案中,处理器106可周期性地比较预测位置数据112与后续位置数据以优化用于产生预测位置数据112的方程式或算法或确认先前预测位置在指定容限内是准确的。
在另一特定实施方案中,处理器106可能不实时处理空间化音频信号。替代地,可一或多次预处理输入空间化音频信号,且经处理空间化音频信号可存储在存储器处。每一经处理空间化音频信号可对应于轨迹。举例来说,可在输入空间化音频信号的呈现期间测量音频装置102(或用户)的轨迹,且可基于所述轨迹来处理输入空间化音频信号以产生经处理空间化音频信号。作为说明,输入空间化音频信号可对应于电影,多个用户的头部移动可在用户观看电影时被跟踪,且每一用户的移动可转换为轨迹。归因于头部大小、对电影主题的相关兴趣等的不同,可针对成人与儿童等确定不同轨迹。轨迹中的每一者可用于预处理和存储空间化音频信号。接着,当新用户观看电影时,处理器106可经配置以基于新用户的预测位置数据112确定预测轨迹。在确定预测轨迹之后,处理器106可存取(例如通过从存储器检索)与大体上匹配(或最接近)预测轨迹的轨迹相关联的预处理空间化音频信号。作为说明,如果新用户是儿童,儿童的移动可引起选择预处理的“儿童用”空间化音频信号而非预处理的“成人用”空间化音频信号。处理器106可将检索到的空间化音频信号用作输出空间化音频信号114。以此方式,处理器106能够在消除或减小滞后时以及在不必实时处理空间化音频信号的情况下提供3d音频功能。这可使具有较少计算资源的处理器或装置(例如,作为非限制性实例,移动装置中的一些处理器)能够提供原本会过于计算密集的3d音频功能。参考图2进一步描述基于预测轨迹选择经处理音频信号。
另外,在特定实施方案中,处理器106可经配置以基于可用处理资源确定是执行实时音频处理还是使用经处理音频信号。参考图2进一步描述此类确定。
在特定实施方案中,音频处理装置100的一或多个组件可包含在或集成在车辆中。作为说明性实例,汽车内部的座位可配备有多个扬声器(例如音频装置102),且汽车内的显示单元可经配置以执行vr游戏(或ar游戏)。坐在汽车中的用户可使用包含传感器103的用户接口装置(例如手持式控制器)与vr游戏(或ar游戏)交互。位置预测器104和处理器106可并入于车辆的电子组件中。当用户与vr游戏交互且移动通过与vr游戏相关联的虚拟环境时,座位中的扬声器输出的声音可经修改以实现用户对声音的方向性或距离改变的感知。为了防止声音改变滞后于用户位置或定向在虚拟世界中的改变,可基于预测位置数据产生输出空间化音频信号,如上文所描述。在其它实施方案中,空间化音频信号可经处理以用于3d音频应用、电话会议应用、多媒体应用或其它应用。
在另一特定实施方案中,音频处理装置的一或多个组件可包含在或集成在“无人操作装置”(例如无人驾驶的车辆,例如远程控制车辆或自主车辆)中。作为非限制性实例,所述无人操作装置可以是无人驾驶飞行器(uav)。作为说明,无人操作装置可包含传感器103,且可经配置以例如使用一或多个相机或其它光学传感器检测用户的位置和定向。作为另一实例,无人操作装置可包含麦克风阵列,其经配置以捕捉在空间化音频处理期间使用的3d声音,如本文所描述。
尽管将位置预测器104和处理器106描述为独立组件,但在另一特定实施方案中,位置预测器104可以是处理器106的部分。举例来说,处理器106可包含经配置以执行位置预测器104的操作的电路。替代地,处理器106可经配置以执行指令,从而执行位置预测器104的操作。在特定实施方案中,位置预测器104和处理器106可集成于移动装置内,例如移动电话、平板计算机、笔记本计算机、计算机化手表(或其它可穿戴装置)、pda或其组合,且所述移动装置可以通信方式耦合到音频装置102,例如hmd、头戴装置或另一音频装置。在此实施方案中,移动装置可经配置以为音频装置102提供音频处理,且音频装置102可仅经配置以基于音频信号产生音频输出。
在操作期间,用户可打开音频装置102且起始特定音频文件的播放(或可经由网络流式传输内容)。一或多个传感器103可产生传感器数据110且将传感器数据110提供(例如发送)到位置预测器104。传感器数据110可包含坐标数据120和定向数据122。在一些实施方案中,音频装置102可戴在用户头上,且因此传感器数据110可表示用户头部。在其它实施方案中,音频装置102是稳定或固定的(例如,音频装置是扬声器阵列),且传感器103跟踪用户的位置和定向。在一些实例中,传感器数据110可指示音频装置102、用户或用户头部在用户对音频文件或内容的呈现进行反应时的平移位置(例如x-y-z坐标)和定向(例如俯仰、横滚和侧转)。另外或替代地,传感器数据110可指示用户在虚拟环境(或ar环境)中的位置和定向。
位置预测器104可基于传感器数据110产生预测位置数据112。举例来说,位置预测器104可基于传感器数据110(例如位置数据)预测音频装置102(或用户)在某一未来时间的位置。处理器106可基于预测位置数据112产生输出空间化音频信号114,且可(在3d再现和后处理之后)将输出空间化音频信号114提供到音频装置102以用于产生音频输出(例如听觉声音)。在各种实施方案中,如本文所描述,确定预测位置数据112和产生输出空间化音频信号114可涉及存取历史数据、执行实时或近实时计算、确定最接近先前计算轨迹、检索先前计算的空间化音频信号、应用旋转等。音频装置102处的音频输出可使用户能够感知声源方向或距离因用户(在现实世界或在虚拟或ar环境中)的移动或预测移动所致的改变。另外或替代地,输出空间化音频信号114可存储在存储器处以用于后续检索和播放。
图1a的音频处理装置100可因此通过基于预测位置数据112产生输出空间化音频信号114而补偿与产生空间化音频信号相关联的延迟(例如时延)。因为处理器106基于预测位置数据112(例如指示音频装置102或用户在未来时间的位置的数据)而非指示音频装置102或用户的当前位置的位置数据来产生输出空间化音频信号114,所以时延得以补偿且用户可能不会感知到其移动与对应的空间化音频输出改变之间的迟滞。
参考图1b,展示音频处理装置的第二实施方案,且将其总体上指示为150。音频处理装置150经配置以基于预测位置数据产生输出空间化音频信号。音频处理装置150包含音频装置102、一或多个传感器103和处理器106。
在图1b中说明的实施方案中,传感器103包含位置预测器104。举例来说,传感器103可包含含有电路的传感器块或传感器系统,例如位置预测器104,其经配置以执行除产生传感器数据110外的操作。作为另一实例,传感器103(例如传感器块或传感器系统)可包含经配置以执行位置预测器104的操作的处理器。
在特定实施方案中,传感器103可包含传感器存储器130。传感器存储器130可经配置以存储由传感器103产生的数据,例如传感器数据110(例如坐标数据120和定向数据122)。所述数据可供位置预测器104存取以执行一或多个操作,例如确定预测位置数据112。
在操作期间,传感器103可确定(例如测量)传感器数据110,如参考图1a所描述。在特定实施方案中,可存储传感器数据110(例如在传感器存储器130中)。位置预测器104可基于传感器数据110(和历史位置数据)确定预测位置数据112,如参考图1a进一步描述。位置预测器104可将预测位置数据112提供到处理器106。处理器106可接收预测位置数据112且基于预测位置数据112产生输出空间化音频信号114,如参考图1a进一步描述。
图1b的音频处理装置150可因此通过基于预测位置数据112产生输出空间化音频信号114而补偿与产生空间化音频信号相关联的延迟(例如时延)。因为处理器106基于预测位置数据112(例如指示音频装置102或用户在未来时间的位置的数据)而非指示音频装置102或用户的当前位置的位置数据来产生输出空间化音频信号114,所以时延得以补偿且用户可能不会感知到其移动与对应的空间化音频输出改变之间的迟滞。因为在图1b中说明的实施方案中,位置预测器104包含在传感器103中,所以与处理空间化音频信号的其它音频处理装置相比,在处理器106处执行的操作量可减小。
参考图1c,展示音频处理装置的第三实施方案,且将其总体上指示为160。音频处理装置160经配置以基于预测位置数据产生输出空间化音频信号。音频处理装置160包含音频装置102、一或多个传感器103和处理器106。
在图1c中说明的实施方案中,处理器106包含位置预测器104。举例来说,处理器106可包含经配置以执行参考位置预测器104所描述的操作的电路或其它硬件。作为另一实例,处理器106可执行存储在非暂时性计算机可读媒体上的一或多个指令,其使处理器106执行位置预测器104的操作。
在操作期间,传感器103可确定(例如测量)传感器数据110,如参考图1a所描述。处理器106可从传感器103接收传感器数据110。位置预测器104(例如处理器106)可基于传感器数据110(和历史位置数据)确定预测位置数据112,如参考图1a进一步描述。举例来说,处理器106可执行一或多个操作以确定预测位置数据112。在特定实施方案中,处理器106可使预测位置数据112被存储(例如在处理器106可存取的存储器中)。另外,处理器106可基于预测位置数据112产生输出空间化音频信号114,如参考图1a进一步描述。
图1c的音频处理装置160可因此通过基于预测位置数据112产生输出空间化音频信号114而补偿与产生空间化音频信号相关联的延迟(例如时延)。因为处理器106基于预测位置数据112(例如指示音频装置102或用户在未来时间的位置的数据)而非指示音频装置102或用户的当前位置的位置数据来产生输出空间化音频信号114,所以时延得以补偿且用户可能不会感知到其移动与对应的空间化音频输出改变之间的迟滞。因为在图1c中说明的实施方案中,位置预测器104包含在处理器106中,所以与处理空间化音频信号的其它音频处理装置相比,音频处理装置160中的组件的量可减小。
在以上描述中,由图1a的音频处理装置100、图1b的音频处理装置150和图1c的音频处理装置160执行的各种功能被描述为由某些组件执行。然而,组件的此划分仅用于说明。在替代实施方案中,由特定组件执行的功能可改为分到多个组件当中。此外,在替代实施方案中,图1a到c的两个或更多个组件可集成到单个组件中。举例来说,位置预测器104和处理器106可集成在单个组件中。替代地,音频装置102、位置预测器104和处理器106可集成在单个组件中。图1a到c中说明的每一组件可使用硬件(例如现场可编程门阵列(fpga)装置、专用集成电路(asic)、dsp、控制器等)、软件(例如可由处理器执行的指令)或其组合实施。
参考图2,展示包含或耦合到虚拟现实系统的hmd的音频处理装置的说明性实施方案,且将其总体上指示为200。音频处理装置200包含音频装置102、位置预测器104、处理器106、存储器240和无线接口270。在图2中,音频装置102被说明为虚拟现实系统的hmd。在其它实施方案中,音频装置102可以是能够输出3d再现音频信号的头戴装置或另一装置。尽管将位置预测器104、处理器106和存储器240说明为与音频装置102分开,但在其它实施方案中,位置预测器104、处理器106、存储器240或其组合可集成于音频装置102内。举例来说,位置预测器104、处理器106和存储器240可集成于虚拟现实系统内。替代地,音频装置102可以是头戴装置,且所说明hmd可以是一副虚拟现实护目镜,其可以通信方式耦合到经配置以提供视觉和音频输出的移动装置,例如移动电话或平板计算机。在此实施方案中,位置预测器104、处理器106、存储器240或其组合可集成于移动装置内。在另一替代实施方案中,音频装置102可以是扬声器阵列,如参考图1a到c所描述,且传感器数据110可由传感器提供,所述传感器与扬声器阵列分开(或经配置以跟踪用户而非音频装置102的位置及所述定向)。
位置预测器104包含算术电路202、滤波电路208和存储器220。处理器106包含资源分析器260和一或多个音频缓冲器262。尽管说明为单独(例如不同)组件,但在其它实施方案中,存储器220和存储器240可以是位置预测器104和处理器106两者均可存取的单个存储器。另外或替代地,尽管存储器220被说明为集成于位置预测器104内(或与所述位置预测器在相同芯片上),且存储器240被说明为与处理器106分开的装置,但在其它实施方案中,存储器220可以是与位置预测器104分开的装置,存储器240可集成于处理器106内(或与所述处理器在相同芯片上)。
存储器220可经配置以存储历史位置数据222、时延数据224、用户响应数据226、第一预测轨迹数据228、第二预测轨迹数据230和用户兴趣分析数据232。历史位置数据222可表示从音频装置102(例如从一或多个传感器103)接收的先前传感器数据。时延数据224可指示与在处理器106处处理空间化音频信号相关联的时延。在特定实施方案中,位置预测器104经配置以通过执行处理器106的操作的一或多个测量来确定时延数据224。在替代实施方案中,处理器106确定时延数据224且将时延数据224提供到位置预测器104。用户响应数据226可指示所述用户或其他用户对一或多个空间化音频信号的呈现的响应。举例来说,用户响应数据226可指示音频装置102(例如用户头部)在特定空间化音频信号的前一呈现期间的轨迹。用户兴趣分析数据232可指示与相关或类似空间化音频信号的呈现相关联的用户兴趣等级。举例来说,用户兴趣分析数据232可指示用户在空间化音频信号的呈现期间远离响亮声音或转向特定声音(例如汽车发动声音、爆炸声等)的可能性。另外或替代地,用户兴趣分析数据232可指示用户对各种主题的兴趣等级。举例来说,作为非限制性实例,用户兴趣分析数据232可指示用户更喜欢听音乐会而非看电影、用户更喜欢看动作片而非纪录片或用户更喜欢教育虚拟现实内容而非体育比赛。
存储器220还可存储多个预测轨迹数据,例如第一预测轨迹数据228和第二预测轨迹数据230,其可由位置预测器104(或处理器106)用于选择经处理空间化音频信号以从存储器240进行检索,如本文进一步描述。另外或替代地,可从至少一个其它装置接收(例如存取)预测轨迹数据228、230。作为说明,音频处理装置200可经配置以经由无线接口270从至少一个装置(例如服务器)接收一或多个流(例如数据流、媒体流等)。作为非限制性实例,所述至少一个装置可包含多媒体服务器、基于云的存储装置或可经由无线通信存取的另一移动装置。处理器106可经配置以经由无线接口270将预测轨迹数据、经处理空间化音频信号或这两者的请求发送到至少一个其它装置,且音频处理装置200可响应于发送所述请求而从所述至少一个装置接收至少一个数据流。
如参考图1a到c所描述,位置预测器104可经配置以基于传感器数据110确定预测位置数据112。传感器数据110可包含图1a到c的坐标数据120和定向数据122。如图2中所说明,坐标数据120可包含指示用户(或音频装置102)的平移位置的x-y-z坐标(例如平移位置数据)。在一些实例中,用户的平移位置可与固定原点(例如空间或虚拟现实环境的中心)、用户在文件的播放或内容的流式传输开始时的位置等相关。另外,定向数据122可包含横滚、俯仰和侧转角度,其指示用户(或音频装置102)相对于坐标平面的定向。在一些实例中,定向角度可与固定原点(例如陀螺仪传感器的原点)相关。因此,在至少一些实施方案中,传感器数据包含六个测量值(例如x坐标值、y坐标值、z坐标值、横滚角、俯仰角和侧转角)。在其它实施方案中,六个测量值中的一或多个未包含在传感器数据110中,或传感器数据110包含额外测量值,例如移动、角动量、速度、加速度或其它。在其它实施方案中,传感器数据110指示用户在虚拟环境或ar环境中的位置。举例来说,控制接口可耦合到vr系统,且控制接口可包含基于用户输入产生传感器数据的传感器。用户输入可包含按压手持式控制器上的按钮或垫片、语音输入、触摸式输入、姿势输入或另一类别的用户输入。
在一些实例中,可进一步基于历史位置数据222确定预测位置数据112,其中历史位置数据222对应于穿戴所说明hmd的用户的先前移动、其他用户的先前移动或这两者。位置预测器104可包含算术电路202,其经配置以执行一或多个数学运算以确定预测位置数据112。举例来说,算术电路202可包含一或多个加法器、乘法器、逻辑门、移位器或使位置预测器104能够执行计算以确定预测位置数据112的其它电路。作为特定实例,位置预测器104可使用算术电路202执行一或多个计算以将传感器数据110与历史位置数据222进行比较。传感器数据110与历史位置数据222之间的差可用于估计在未来时间处的预测位置(例如预测位置数据112)。
另外,算术电路202可经配置以基于传感器数据110和历史位置数据222执行运算以确定速度204、加速度206或这两者。在其它实施方案中,速度204、加速度206或这两者可通过一或多个传感器103确定且可提供到位置预测器104(例如作为传感器数据110的部分)。预测位置数据112可基于速度204、加速度206或这两者而确定。作为一个实例,速度204可乘以时延数据224以确定预测移动,且所述预测移动可应用于当前位置(由传感器数据110指示)以确定由预测位置数据112指示的预测位置。
在一些实施方案中,位置预测器104可使用滤波电路208确定预测位置数据112。在特定实施方案中,滤波电路208包含卡尔曼滤波器210,且卡尔曼滤波器210应用于传感器数据110(例如当前位置)以确定预测位置数据112。在另一特定实施方案中,速度204可用作卡尔曼滤波器210的额外输入。在其它实施方案中,滤波电路208可包含粒子滤波器或粒子滤波器跟踪器。粒子滤波器可基于传感器数据110确定一或多个预测轨迹,且所述一或多个预测轨迹可通过预测位置数据112指示。对于所述一或多个预测轨迹中的每一者,处理器106可产生(或检索)空间化音频信号,且输出空间化音频信号114可选择为对应于在空间化音频信号完成处理时最接近某一位置的轨迹的空间化音频信号。
如参考图1a到c所描述,位置预测器104可经配置以基于传感器数据110确定预测轨迹。预测轨迹可基于对用户响应数据226、用户兴趣分析数据232或这两者以及传感器数据110的分析。作为说明,位置预测器104可确定多个预测轨迹,例如第一预测轨迹数据228和第二预测轨迹数据230所指示的预测轨迹。预测轨迹可基于用户响应数据226而确定。举例来说,用户响应数据226可包含在时间上经同步以指示用户在空间化音频信号的其它呈现期间的响应(例如移动)的位置数据或定向数据,且多个预测轨迹可基于所述响应而确定。另外或替代地,预测轨迹可基于用户兴趣分析数据232而确定。举例来说,位置预测器104可存取用户兴趣分析数据232以确定空间化音频信号中的特定声音将受用户关注,且位置预测器104可基于此分析来确定一或多个预测轨迹。
预测轨迹数据228、230可在特定空间化音频文件的播放之前产生,且可在所述播放期间存取以确定预测轨迹。举例来说,位置预测器104可通过将传感器数据110和历史位置数据222与所存储的预测轨迹数据(或经由无线接口270存取的预测轨迹数据)进行比较以确定哪一预测轨迹最密切匹配传感器数据110和历史位置数据222来确定预测轨迹。存储器220处存储(或经由无线接口270存取)的最密切匹配预测轨迹可选为待由预测位置数据112指示的预测轨迹。举例来说,响应于确定第一预测轨迹数据228是传感器数据110和历史位置数据222的最密切匹配对象,位置预测器104可将第一预测轨迹数据228(指示第一预测轨迹)作为预测位置数据112输出。在另一特定实施方案中,传感器数据110和历史位置数据222可能不足以确定预测轨迹,且位置预测器104可输出对应于最可能轨迹的轨迹数据,所述最可能轨迹基于用户响应数据226、用户兴趣分析数据232或这两者来确定。
处理器106可经配置以接收预测位置数据112且基于预测位置数据112产生输出空间化音频信号114,如参考图1a到c所描述。在特定实施方案中,处理器106经配置以基于预测位置数据112处理输入空间化音频信号246以产生输出空间化音频信号114。作为说明,处理器106可基于预测位置数据112产生旋转(例如旋转数据)。在特定实施方案中,所述旋转可通过旋转矩阵指示,如参考图4进一步描述。处理器106可将所述旋转应用于输入空间化音频信号246以使输入空间化音频信号246“旋转”,使得一或多个声音的所感知方向或距离基于预测位置数据112而改变。在其它实施方案中,可执行其它处理以产生(例如确定)和应用旋转。在其它实施方案中,处理器106可执行基于通道的音频处理、基于对象的音频处理或其它音频处理(例如作为非限制性实例的基于向量的振幅平移(vbap))以修改输入空间化音频信号246,使得一或多个声音的所感知方向或距离基于预测位置数据112而改变。处理器106可经配置以将输入空间化音频信号246的经处理帧存储在音频缓冲器262中,且将所述经处理帧作为输出空间化音频信号114从音频缓冲器262提供到音频装置102。
在另一特定实施方案中,处理器106可经配置以基于预测位置数据112确定预测轨迹且从存储器240检索对应于所述预测轨迹的经处理空间化音频信号。作为说明,存储器240可经配置以存储基于多个预测轨迹的多个经处理空间化音频信号。举例来说,存储器240可存储基于第一预测轨迹的第一经处理空间化音频信号242以及基于第二预测轨迹的第二经处理空间化音频信号244。可在接收空间化音频信号的播放请求之前产生经处理空间化音频信号。举例来说,可在音频处理装置200的初始设置过程期间、在音频处理装置200的更新期间或在处理资源可供使用以产生和存储经处理空间化音频文件的时间期间将经处理音频信号存储在存储器240处。作为额外实例,可周期性地或如所需要从另一装置(例如服务器)请求经处理空间化音频文件,可经由通过无线接口270接收到的一或多个数据流接收所述空间化音频文件且存储在存储器240处,空间化音频文件可由用户下载或存储,空间化音频文件可作为用户所存储的其它内容(例如电影、视频游戏等)的部分或作为自动更新的部分而存储。
预测位置数据112可指示预测轨迹,且处理器106可接入存储器240且检索对应于预测轨迹的经处理空间化音频信号。举例来说,响应于确定第一预测轨迹(其与第一经处理空间化音频信号242相关联)对应于预测位置数据112所指示的预测轨迹,处理器106可从存储器240检索第一经处理空间化音频信号242,且可将所述第一经处理空间化音频信号用作输出空间化音频信号114。作为进一步说明,第一经处理空间化音频信号242的帧可从存储器240检索到且存储在音频缓冲器262中,且所述帧可作为输出空间化音频信号114从音频缓冲器262提供到音频装置102。
在另一特定实施方案中,位置预测器104可基于传感器数据110(例如位置数据)的改变而更新预测位置数据112以指示不同预测轨迹。作为说明,在时间t0,预测位置数据112可指示基于传感器数据110的第一预测轨迹。在时间t1,位置预测器104可确定与时间t1相关联的传感器数据指示:第二预测轨迹是当前用户轨迹的最密切匹配对象。在时间t1,位置预测器104可将第二预测位置数据提供(例如发送)到处理器106。第二预测位置数据可指示第二预测轨迹。响应于接收到指示第二预测轨迹的第二预测位置数据,处理器106可检索对应于第二预测轨迹的第二经处理空间化音频信号244。
在时间t0,处理器106可将第一经处理空间化音频信号242的帧存储在音频缓冲器262中,且所述帧可作为输出空间化音频信号114从音频缓冲器262提供到音频装置102。在时间t1,响应于接收到第二预测位置数据,处理器106可开始将来自第一经处理空间化音频信号242和第二经处理空间化音频信号244的帧存储在音频缓冲器262中。基于存储在存储器240处的渐消因子252,根据以下方程式,对应于来自两个经处理空间化音频信号的帧的输出数据可存储在音频缓冲器262中:
输出数据=a*l1r1+(1-a)*l2r2方程式1
其中a表示渐消因子,l1r1表示对应于第一经处理空间化音频信号(例如第一经处理空间化音频信号242)的流,且l2r2表示对应于第二经处理空间化音频信号(例如第二经处理空间化音频信号244)的流。渐消因子252a可以是在转变时间期间从0转变到1的渐现/渐逝函数。在特定实施方案中,渐消因子252对应于线性函数。在另一特定实施方案中,渐消因子252对应于非线性函数。可基于系统响应性(例如系统应基于用户移动改变音频流的快速程度)与音频平滑度(例如避免输出可听音频伪声)之间的协调来确定转变时间。转变时间可约为几十毫秒。在特定实施方案中,转变时间是10ms。
在另一特定实施方案中,两个经处理空间化音频信号之间的转变可受对应的预测轨迹重叠的时间限制。举例来说,如果第一预测轨迹和第二预测轨迹在时间t2重叠,那么处理器106可在时间t2从将第一经处理空间化音频信号242的帧存储在音频缓冲器262中切换到将第二经处理空间化音频信号244的帧存储在音频缓冲器262中。将不同经处理空间化音频信号之间的转变限制于预测轨迹重叠的时间可减小由经处理空间化音频信号之间的不同所致的音频伪声。
在另一特定实施方案中,处理器106可经配置以在两个经处理空间化音频信号之间平移以实现与音频装置102(或用户)的位置的更密切匹配。在此实施方案中,位置预测器104可提供预测位置数据112,其指示多个最密切匹配预测轨迹。举例来说,响应于确定第一预测轨迹和第二预测轨迹是传感器数据110的最密切匹配对象,位置预测器104可将第一预测轨迹数据228和第二预测轨迹数据230包含在预测位置数据112中。响应于预测位置数据112包含第一预测轨迹数据228和第二预测轨迹数据230,处理器106可从存储器240检索第一经处理空间化音频信号242(对应于第一预测轨迹)和第二经处理空间化音频信号244(对应于第二预测轨迹)。
基于存储在存储器240处的平移因子250,根据以下方程式,对应于来自两个经处理空间化音频信号的帧的输出数据可存储在音频缓冲器262中:
输出数据=b*l1r1+(1-b)*l2r2方程式2
其中b表示平移因子,l1r1表示对应于第一经处理空间化音频信号(例如第一经处理空间化音频信号242)的流,且l2r2表示对应于第二经处理空间化音频信号(例如第二经处理空间化音频信号244)的流。平移因子250可由以下方程式限定:
b=|(p(t)-p1)|/|p1-p2|方程式3
其中p(t)表示当前位置(基于传感器数据110),p1表示来自第一预测轨迹的对应位置,且p2表示来自第二预测轨迹的对应预测轨迹。因此,基于平移因子250,来自多个空间化音频信号的音频帧可存储在音频缓冲器262中,且所述音频帧可作为输出空间化音频信号114从音频缓冲器262提供到音频装置102。
在特定实施方案中,处理器106包含资源分析器260。资源分析器260可经配置以分析可用处理资源以确定音频处理装置200的操作模式。举例来说,基于可用处理资源,资源分析器可确定处理器106是否实时(或近实时)处理空间化音频信号或处理器106是否从存储器240检索经处理空间化音频信号。作为说明,资源分析器260可经配置以将可用资源与存储在存储器240处的一或多个阈值248进行比较。可在处理器利用率、可用存储器、电池电量等方面表示阈值248。阈值248可以是固定的或可以是可调整的(例如基于用户输入、基于hmd销售商的编程等)。响应于确定可用资源超出阈值248(例如基于比较),资源分析器260可确定音频处理装置200(例如位置预测器104和处理器106)要实时(或近实时)处理空间化音频信号。因此,资源分析器260可产生第一控制信号,其使处理器106处理空间化音频信号(例如输入空间化音频信号246)以产生输出空间化音频信号114。响应于确定可用资源未能超出(例如小于或等于)阈值248,资源分析器260可确定音频处理装置200(例如位置预测器104和处理器106)要使用存储在存储器240处的经处理空间化音频信号而非实时处理空间化音频信号。因此,资源分析器260可产生第二控制信号,其使处理器106基于预测位置数据112检索存储在存储器240处的经处理空间化音频信号。在一些实施方案中,资源分析器260可经配置以周期性地执行所述确定,因为可用处理资源可在不同时间改变。在其它实施方案中,处理器106不包含资源分析器260,且音频处理装置200不在操作模式之间(例如,实时处理空间化音频信号或检索存储器240处存储的经处理空间化音频信号之间)切换。
在操作期间,位置预测器104从传感器103接收传感器数据110。传感器数据110指示音频装置102(例如用户头部)的位置和定向。另外或替代地,传感器数据110指示用户在虚拟或ar环境中的位置和定向。位置预测器104基于传感器数据110确定预测位置数据112。举例来说,算术电路202可执行一或多个操作以确定预测位置数据112。预测位置数据112可提供到处理器106,且处理器106可基于预测位置数据112产生输出空间化音频信号114。输出空间化音频信号114可提供到音频装置102以在音频装置102处起始音频输出。另外或替代地,输出空间化音频信号114可存储在存储器240处。
在特定实施方案中,处理器106可基于预测位置数据112处理输入空间化音频信号246以产生输出空间化音频信号114。在另一特定实施方案中,处理器106可基于预测位置数据112所指示的预测轨迹从存储器240检索经处理空间化音频信号。在另一特定实施方案中,音频处理装置200的操作模式(例如是否实时处理空间化音频信号,或是否从存储器240检索经处理空间化音频信号)可由资源分析器260通过比较可用处理资源与阈值248来确定。
图2的音频处理装置200可因此通过基于预测位置数据112产生输出空间化音频信号114而补偿与产生空间化音频信号相关联的延迟(例如时延)。因为处理器106基于预测位置数据112(例如指示音频装置102或用户在未来时间的位置的数据)而非指示音频装置102或用户的当前位置的位置数据来产生输出空间化音频信号114,所以时延得以补偿且用户不会体会到其移动与对应的空间化音频输出改变之间的迟滞。另外,如果可用计算资源不足(例如小于或等于阈值248),处理器106就可从存储器240检索经处理空间化音频信号而非实时处理空间化音频信号。与针对个别用户移动实时处理空间化音频信号、同时继续粗略估计空间化音频输出相比,使用预处理空间化音频信号可减小处理器106上的负荷。
在以上描述中,将图2的音频处理装置200所执行的各种功能描述为通过某些组件执行。然而,组件的此划分仅用于说明。在替代实施方案中,由特定组件执行的功能可改为分到多个组件当中。此外,在替代实施方案中,图2的两个或更多个组件可集成到单个组件中。举例来说,位置预测器104、处理器106和存储器240可集成在单个组件中。替代地,音频装置102、位置预测器104、处理器106和存储器240可集成在单个组件中。图2中所说明的每一组件可使用硬件(例如现场可编程门阵列(fpga)装置、专用集成电路(asic)、dsp、控制器等)、软件(例如可由处理器执行的指令)或其组合来实施。
参考图3,展示包含或耦合到扬声器阵列的音频处理装置的说明性实施方案,且将其总体上指示为300。音频处理装置300包含音频装置102、传感器103、位置预测器104、处理器106、存储器240和无线接口270。在图3中说明的实施方案中,音频装置102包含扬声器阵列,且传感器103与音频装置102分开且经配置以确定用户的位置和定向。举例来说,传感器103可包含相机或其它光学装置,其经配置以确定用户的位置和定向。在另一特定实施方案中,传感器103可以是用户穿戴(例如耦合到用户)的其它移动传感器,例如位置传感器、加速度计、定向传感器等。在另一特定实施方案中,传感器103可集成于用户接口装置内,且传感器数据110可指示用户在虚拟或ar环境中的位置和定向。
音频处理装置300可经配置以类似于图2的音频处理装置200进行操作。举例来说,位置预测器104可基于传感器数据110确定预测位置数据112,且处理器106可基于预测位置数据112产生输出空间化音频信号114。音频装置102可经配置以基于输出空间化音频信号114执行波束成形(例如以产生在特定方向上引导的音频输出304,例如音频波)。举例来说,音频装置102可包含一或多个音频放大器和一或多个音频滤波器,其经配置以实施波束成形以在特定方向上引导音频波(例如音频输出)。在此实施方案中,音频装置102(例如音频滤波器)可经配置以基于空间化音频信号而在特定方向上引导音频输出(例如音频波)。在一些实施方案中,处理器106可进一步经配置以产生使音频装置102(例如扬声器阵列)能够执行波束成形的控制信号302。举例来说,控制信号302可包含音频装置102的音频滤波器用以执行波束成形的一或多个滤波器系数。
图3的音频处理装置300可通过基于预测位置数据112产生输出空间化音频信号114而补偿与产生空间化音频信号相关联的延迟(例如时延)。另外,音频处理装置300可使扬声器阵列(例如音频装置102)能够执行波束成形以输出所述输出空间化音频信号114。因此,本公开的技术可改善与立体声头戴式耳机输出以及多通道扬声器输出相关联的空间化音频收听体验。
在以上描述中,将图3的音频处理装置300所执行的各种功能描述为通过某些组件执行。然而,组件的此划分仅用于说明。在替代实施方案中,由特定组件执行的功能可改为分到多个组件当中。此外,在替代实施方案中,图3的两个或更多个组件可集成到单个组件中。举例来说,位置预测器104、处理器106和存储器240可集成在单个组件中。替代地,音频装置102、位置预测器104、处理器106和存储器240可集成在单个组件中。图3中说明的每一组件可使用硬件(例如现场可编程门阵列(fpga)装置、专用集成电路(asic)、dsp、控制器等)、软件(例如可由处理器执行的指令)或其组合来实施。
参考图4,展示经配置以使用预测位置数据执行音频空间化的音频处理装置的说明性实施方案,且将其总体上指示为400。音频处理装置400包含位置预测器104、四元数产生器404、音频空间化电路410和数/模转换器(dac)418以及如所展示耦合的相应输入和输出。音频空间化电路410包含旋转矩阵产生器412、旋转矩阵施用器414和立体声化器416以及如所展示耦合的相应输入和输出。
位置预测器104可经配置以确定预测位置数据,例如图1a到c、2和3的预测位置数据112。四元数产生器404可经配置以从位置预测器104接收预测位置数据且基于所述预测位置数据产生四元数数据。四元数数据可表示呈四元数格式的预测位置数据。在一些实施方案中,四元数数据可指示与预测位置数据相关联的方位角、仰角和翻转。替代地,四元数数据可用于使用已知方程式确定方位角、仰角和翻转。
旋转矩阵产生器412可经配置以从四元数产生器404接收四元数数据且基于所述四元数数据产生旋转矩阵。尽管图4说明旋转矩阵产生器412个别地接收方位角、仰角和翻转,但此类说明是为方便起见且不应视为限制性。在一些实施方案中,音频空间化电路410的一部分可接收四元数数据且产生方位角、仰角和翻转。替代地,旋转矩阵产生器412可接收四元数数据且可产生方位角、仰角和翻转。产生旋转矩阵可包含将四元数数据转换到球面或笛卡尔(cartesian)坐标、旋转所述坐标、应用本征麦克风(mic)权重、应用高阶立体混响(hoa)排序,以及反转坐标。
旋转矩阵施用器414可经配置以从旋转矩阵产生器412接收旋转矩阵。旋转矩阵施用器414可进一步经配置以将旋转矩阵应用于四阶hoa音频信号420以产生音频数据。将旋转矩阵应用于四阶hoa音频信号420可使声音(或声源)的所感知方向或距离改变。在其它实施方案中,hoa音频信号可低于或高于四阶。应用旋转矩阵可包含将旋转矩阵乘以四阶hoa音频信号420的样本的向量。在一些实施方案中,应用旋转矩阵或执行加法处理还考虑到位置的改变。举例来说,x-y-z坐标数据可经加权以补偿位置的改变。
旋转矩阵产生器412和旋转矩阵施用器414可以是任选的。在其它实施方案中,音频空间化电路410可包含经配置以将旋转应用于空间化音频信号的其它组件。举例来说,音频空间化电路410可包含向量产生器、向量施用器、旋转数据集产生器、旋转数据集施用器,或经配置以确定旋转数据(例如一或多个向量、数据集的一或多个元素、来自查找表或数据库的一或多个元素等)且将旋转数据应用于输入空间化音频信号(例如四阶hoa音频信号420)以执行音频空间化处理的其它电路或硬件。
立体声化器416可经配置以基于立体声空间脉冲响应(brir)422和解码器矩阵424对音频数据执行立体声化以产生数字空间化音频信号。执行立体声化可包含利用brir(或头部相关传递函数(hrtf))和解码器矩阵卷积音频数据(例如经旋转音频样本)。在音频装置102是头戴装置或虚拟现实系统的hmd的特定实施方案中,立体声化可包含基于解码器矩阵424产生每一耳部的解码器矩阵(例如左解码器矩阵和右解码器矩阵)、将brir422应用于左解码器矩阵和右解码器矩阵以产生brir解码器矩阵、对brir解码器矩阵执行快速傅立叶变换(fft,fastfouriertransform)、将fftbrir解码器矩阵应用于音频数据(例如由旋转矩阵施用器414产生的经旋转音频样本)、执行经解码样本的重叠添加以及在多个通道上对结果求和。在其它实施方案中,例如与扬声器阵列相关联的实施方案,并未包含立体声化器416。另外或替代地,可包含一或多个其它组件,例如产生用于执行波束成形的滤波器系数的滤波器系数产生器。
dac418可经配置以接收数字空间化音频信号(例如立体声化器416的输出)且将数字空间化音频信号转换到模拟空间化音频信号。模拟空间化音频信号可存储在存储器240处,或可提供到音频装置102以产生音频输出,如参考图1a到c、2和3所描述。数字空间化音频信号(例如立体声化器416的输出)还可提供到音频空间化电路410的反馈输入。
如参考图1a到c所描述,位置预测器104确定对应于未来时间(例如特定时间量)的预测位置数据。选择所述未来时间以考虑与处理空间化音频信号相关联的所估计音频播放时延(例如延迟),且预测位置数据对应于所述未来时间。时延可包含或考虑到与使用至少音频空间化电路410(例如旋转矩阵产生器412、旋转矩阵施用器414和立体声化器416)和dac418相关联的时延。在其它实施方案中,时延还可包含或考虑到与四元数产生器404相关联的时延。位置预测器104可确定时延(或时延可例如通过图1a到c、2和3的处理器106提供到位置预测器104),且时延可选择未来时间以使得未来时间与当前时间之间的差等于所述时延。作为说明性非限制性实例,可在音频处理装置处理测试数据时使用音频处理装置的内部定时器来确定时延。作为另一说明性非限制性实例,指示时延的数据可在音频处理装置的制造/测试期间确定,且可在操作期间可用于检索(例如从因特网数据库、从装置处的只读存储器等)。因此,位置预测器104可确定足够远的未来时间的预测位置数据以顾及所述时延。以此方式,音频处理装置400的用户可能不会体会到用户头部(或音频装置)的移动与声音的所感知方向或距离的改变之间的迟滞。
图4说明音频处理装置的特定实施方案,其经配置以使用立体声化来处理hoa信号。然而,在其它实施方案中,可基于预测位置数据来执行其它类型的音频处理。作为特定实例,音频处理装置可经配置以处理基于对象的3d音频(例如,具有表示为个别对象的音频源的音频,所述个别对象具有3d坐标和方向性)。音频处理装置可经配置以在执行立体声化(例如利用brir或hrtf卷积音频样本)之前基于预测位置数据重新计算坐标系中的对象位置。作为另一实例,音频处理装置可经配置以处理基于通道的环绕声音频信号,例如5.1通道音频内容、7.1通道音频内容、11.1通道音频内容和77.1.4通道音频内容。音频处理装置可经配置以将每一扬声器当作音频对象,且在执行立体声化之前对每一扬声器执行基于对象的音频处理。作为另一实例,音频处理装置可经配置以将hoa音频内容再现到基于通道的格式(例如作为非限制性实例的7.1通道音频内容或11.1通道音频内容),且经再现信号可处理为基于通道的环绕声音频信号。
在以上描述中,将图4的音频处理装置400所执行的各种功能描述为通过某些组件执行。然而,组件的此划分仅用于说明。在替代实施方案中,由特定组件执行的功能可改为分到多个组件当中。此外,在替代实施方案中,图4的两个或更多个组件可集成到单个组件中。图4中说明的每一组件可使用硬件(例如现场可编程门阵列(fpga)装置、专用集成电路(asic)、dsp、控制器等)、软件(例如可由处理器执行的指令)或其组合来实施。
图5说明音频处理的方法500。方法500可在图1a到c的音频处理装置100、图2的音频处理装置200、图3的音频处理装置300或图4的音频处理装置400处执行。方法500包含在502处接收输入空间化音频信号。举例来说,处理器106可从存储器240接收输入空间化音频信号246。方法500包含在504处确定用户(或音频装置)的位置以及在506处估计与处理空间化音频信号相关联的时延。举例来说,用户的预测位置可通过一或多个传感器103所产生的传感器数据110来指示,且与处理空间化音频信号相关联的时延可通过位置预测器104(或处理器106)进行估计。
方法500包含在508处基于所述位置和所述时延确定用户的预测位置。举例来说,位置预测器104可基于传感器数据110确定预测位置数据112。预测位置数据112可指示用户(或音频装置102)在未来时间的预测位置,且所述未来时间可经选择以使得所述未来时间与当前时间之间的差等于时延。方法500包含在510处基于输入空间化音频信号和预测位置来产生输出空间化音频信号。举例来说,处理器106可通过基于预测位置数据112处理输入空间化音频信号246来产生输出空间化音频信号114,如参考图2进一步描述。
在特定实施方案中,产生输出空间化信号包含在512处旋转和重新定位音频空间中的声源、在514处立体声化音频、在516处填充输出缓冲器以及在518处执行数/模转换。时延可对应于步骤512到518中的一或多个的持续时间。方法500进一步包含在520处基于输出空间化音频信号而起始听觉输出的产生或将输出空间化音频信号存储在存储器处。举例来说,处理器106可将输出空间化音频信号114提供到音频装置102以在音频装置102处起始音频输出。另外或替代地,处理器106可将输出空间化音频信号114存储在存储器240处。
参考图6,展示基于预测位置数据产生输出空间化音频信号的方法的特定说明性实施方案的流程图,且将其总体上指示为600。方法600可通过图1a到c、2和3的处理器106以及图4的音频处理装置400执行。
方法600包含在602处在处理器处从一或多个传感器接收位置数据。举例来说,参考图1a,位置预测器104可从传感器103接收传感器数据110(例如位置数据)。在一些实施方案中,位置预测器可集成于处理器内。位置数据可表示用户头部的位置、头部定向或这两者。举例来说,一或多个传感器可集成在用户头上穿戴的音频装置(例如头戴装置或虚拟现实系统的hmd)中,且所述一或多个传感器可确定音频装置的位置和定向,其表示用户头部的位置和定向。在另一特定实施方案中,位置数据表示用户在虚拟环境内的位置,且所述位置数据接收自虚拟现实(vr)系统的控制器。
方法600包含在604处在处理器处基于所述位置数据来确定预测位置数据。举例来说,参考图1a到c,位置预测器104可基于传感器数据110确定预测位置数据112。
方法600进一步包含在606处在处理器处基于所述预测位置数据来产生输出空间化音频信号。举例来说,参考图1a到c,处理器106可基于预测位置数据112产生输出空间化音频信号114。
在特定实施方案中,方法600包含在处理器处确定与产生空间化音频信号相关联的估计时延。位置数据可对应于第一时间,预测位置数据可对应于第二时间,且第一时间与第二时间之间的差可等于所估计时延。估计时延且针对与所估计时延对应的时间产生预测位置数据可防止音频输出的改变滞后于导致所述改变的(例如音频装置或用户的)移动。
在另一特定实施方案中,方法600包含基于预测位置数据产生旋转以及将所述旋转应用于输入空间化音频信号以产生输出空间化音频信号。举例来说,所述旋转可包含或对应于通过图4的旋转矩阵产生器412产生的旋转矩阵。替代地,所述旋转可包含或对应于其它数据,例如一或多个向量、从查找表检索到的一或多个值或指示旋转的其它数据。
在另一特定实施方案中,方法600包含在处理器处基于预测位置数据来确定第一预测轨迹。第一预测轨迹可对应于输入空间化音频信号对用户的呈现。举例来说,第一预测轨迹可由图2的第一预测轨迹数据228指示。方法600进一步包含从存储器检索对应于第一预测轨迹的第一经处理空间化音频信号。举例来说,第一经处理空间化音频信号可以是图2的第一经处理空间化音频信号242。输出空间化音频信号可包含第一经处理空间化音频信号。
在另一特定实施方案中,方法600包含在处理器处基于位置数据来确定第一预测轨迹和第二预测轨迹。第一预测轨迹可对应于输入空间化音频信号对用户的第一呈现。第二预测轨迹可对应于输入空间化音频信号对用户的第二呈现。举例来说,第一预测轨迹可由图2的第一预测轨迹数据228指示,且第二预测轨迹可由图2的第二预测轨迹数据230指示。方法600进一步包含从存储器检索对应于第一预测轨迹的第一经处理空间化音频信号和对应于第二预测轨迹的第二经处理空间化音频信号。举例来说,第一经处理空间化音频信号可以是图2的第一经处理空间化音频信号242,且第二经处理空间化音频信号可以是图2的第二经处理空间化音频信号244。输出空间化音频信号的第一部分可包含第一经处理空间化音频信号,且输出空间化音频信号的第二部分可包含第二经处理空间化音频信号。第一经处理空间化音频信号和第二经处理空间化音频信号可在接收位置数据之前产生。
方法600还可包含缓冲基于第一经处理空间化音频信号的第一组音频帧、缓冲基于第一经处理空间化音频信号、第二经处理空间化音频信号和渐消因子的第二组音频帧以及缓冲基于第二经处理空间化音频信号的第三组音频帧。举例来说,渐消因子可包含图2的渐消因子252。方法600还可包含缓冲基于第一经处理空间化音频信号、第二经处理空间化音频信号和平移因子的一组音频帧。平移因子可指示基于第一经处理空间化音频信号的帧与基于第二经处理音频信号的帧的比率。举例来说,平移因子可包含图2的平移因子250。
在另一特定实施方案中,方法600包含在处理器处比较可用资源与一或多个阈值,以及响应于确定所述可用资源超出所述一或多个阈值而基于预测位置数据处理输入空间化音频信号以产生输出空间化音频信号。举例来说,图2的资源分析器260可比较可用资源与阈值248。在另一特定实施方案中,方法600包含在处理器处比较可用资源与一或多个阈值,以及响应于确定所述可用资源未能超出所述一或多个阈值而基于预测位置数据从存储器检索经处理音频信号。举例来说,可响应于可用资源未能超出阈值248而检索第一经处理空间化音频信号242或第二经处理空间化音频信号244中的一者。
方法600补偿与通过基于预测位置数据而非基于当前位置数据产生输出空间化音频信号来产生空间化音频信号相关联的延迟(例如时延)。以此方式,声音的所感知方向或距离的改变不会因音频处理时延而滞后于用户(或音频装置)的移动,这可增强用户体验。
参考图7,描绘装置(例如无线通信装置)的特定说明性实施方案的框图,且且将其总体上指示为700。在各种实施方案中,装置700可具有比图7中所说明的组件少或多的组件。
在特定实施方案中,装置700包含耦合到存储器732的处理器710,例如中央处理单元(cpu)或数字信号处理器(dsp)。处理器710可包含或对应于图1a到c、2和3的处理器106。处理器710可包含图1a到c和2到4的位置预测器104。举例来说,处理器710可包含含有位置预测器104的组件(例如电路、fpga、asic等)。
存储器732包含指令768(例如可执行指令),例如计算机可读指令或处理器可读指令。指令768可包含可由计算机(例如处理器710)执行的一或多个指令。在一些实施方案中,存储器732还包含图1a到c、2和3的预测位置数据112和输出空间化音频信号114。作为说明,位置预测器104可经配置以接收传感器数据(例如位置数据)且基于所述传感器数据产生预测位置数据112。处理器710可经配置以基于预测位置数据112产生输出空间化音频信号114,如参考图1a到c、2和3所描述。
图7还说明耦合到处理器710和显示器728的显示器控制器726。译码器/解码器(codec)734还可耦合到处理器710。扬声器736和麦克风738可耦合到codec734。
图7还说明:例如无线控制器的无线接口740和收发器746可耦合到处理器710且到天线742,使得经由天线742、收发器746和无线接口740接收到的无线数据可提供到处理器710。在一些实施方案中,处理器710、显示器控制器726、存储器732、codec734、无线接口740和收发器746包含在系统级封装或芯片上系统装置722中。在一些实施方案中,输入装置730和电源744耦合到芯片上系统装置722。此外,在特定实施方案中,如图7中所说明,显示器728、输入装置730、扬声器736、麦克风738、天线742和电源744在芯片上系统装置722外部。在特定实施方案中,显示器728、输入装置730、扬声器736、麦克风738、天线742和电源744中的每一者可耦合到芯片上系统装置722的组件,例如接口或控制器。
装置700可包含头戴装置、移动通信装置、智能电话、蜂窝式电话、笔记本计算机、计算机、平板计算机、个人数字助理、显示装置、电视机、游戏控制台、音乐播放器、无线电装置、数字视频播放器、数字视频光盘(dvd)播放器、调谐器、相机、导航装置、车辆、车辆的组件或其任何组合。
在说明性实施方案中,存储器732包含或存储指令768(例如可执行指令),例如计算机可读指令或处理器可读指令。举例来说,存储器732可包含或对应于存储指令768的非暂时性计算机可读媒体。指令768可包含可由计算机(例如处理器710)执行的一或多个指令。指令768可使处理器710执行图5的方法500或图6的方法600。
在特定实施方案中,指令768在由处理器710执行时可使处理器710从一或多个传感器接收位置数据。举例来说,处理器710可经配置以经由天线742与一或多个传感器(例如图1a到c、2和3的传感器103)无线通信以接收传感器数据。指令768可使处理器710基于位置数据确定预测位置数据112,如参考图1a到c和2所描述。指令768可进一步使处理器710基于预测位置数据112产生输出空间化音频信号114。在特定实施方案中,处理器710可基于预测位置数据112通过实时(或近实时)处理输入空间化音频信号来产生输出空间化音频信号114。在另一特定实施方案中,处理器710可基于预测位置数据112而从存储器732检索经处理空间化音频信号。指令768可进一步使处理器710基于输出空间化音频信号114而在音频装置处起始音频输出。
结合所描述的方面,第一设备包含用于基于位置数据确定预测位置数据的装置。用于确定的装置可包含或对应于图1a到c、2到4以及7的位置预测器104、经配置以基于位置数据确定预测位置数据的一或多个其它结构或电路,或其任何组合。
第一设备进一步包含用于基于预测位置数据产生输出空间化音频信号的装置。用于产生的装置可包含或对应于图1a到c、2和3的处理器106、图7的处理器710、经配置以基于预测位置数据产生输出空间化音频信号的一或多个其它结构或电路,或其任何组合。
在特定实施方案中,第一设备进一步包含用于处理高阶立体混响(hoa)信号的装置。举例来说,用于处理的装置可包含图1a到c、2和3的处理器106、图4的音频空间化电路410、图7的处理器710、经配置以处理hoa信号的一或多个其它结构或电路,或其任何组合。在另一特定实施方案中,第一设备进一步包含用于基于可用资源确定是基于实时输入空间化音频信号还是基于预处理空间化音频信号来产生输出空间化音频信号的装置。举例来说,用于确定是否产生输出空间化信号的装置可包含图1a到c、2和3的处理器106、图2到3的资源分析器260、图7的处理器710、经配置以基于可用资源确定是基于实时输入空间化音频信号还是基于预处理空间化音频信号来产生输出空间化音频信号的一或多个其它结构或电路,或其任何组合。
所公开方面中的一或多者可在例如装置700的系统或设备中实施,所述系统或设备可包含通信装置、固定位置数据单元、移动位置数据单元、移动电话、蜂窝式电话、卫星电话、计算机、平板计算机、便携式计算机、显示装置、媒体播放器或桌上型计算机。替代地或另外,装置700可包含机顶盒、娱乐单元、导航装置、个人数字助理(pda)、监视器、计算机监视器、电视、调谐器、无线电装置、卫星无线电装置、音乐播放器、数字音乐播放器、便携式音乐播放器、视频播放器、数字视频播放器、数字视频光盘(dvd)播放器、便携式数字视频播放器、卫星、车辆、集成于车辆内的组件、包含处理器或存储或检索数据或计算机指令的任何其它装置,或其组合。作为另一说明性非限制性实例,所述系统或所述设备可包含远程单元,例如手持式个人通信系统(pcs)单元、便携式数据单元(例如支持全球定位系统(gps)的裝置)、仪表读取设备,或包含处理器或存储或检索数据或计算机指令的任何其它装置,或其任何组合。
尽管图1a到c以及2到7中的一或多者可说明根据本公开的教示的系统、设备和/或方法,但本公开不限于所说明的这些系统、设备和/或方法。如本文所说明或描述的图1a到c以及2到7中的任一者的一或多个功能或组件可与图1a到c以及2到7中的另一者的一或多个其它部分组合。因此,本文所描述的单个实施例不应被解释为限制性的,且本公开的实施方案可在不脱离本公开的教示的情况下进行适当组合。举例来说,图6的方法600可通过图1a到c和2的处理器106或图7的处理器710执行。另外,参考图5和6所描述的一或多个操作可以是任选的,可至少部分地同时执行,和/或可按与所展示或所描述的不同的次序执行。
所属领域的技术人员将进一步了解,结合本文公开的实施方案所描述的各种说明性的逻辑块、配置、模块、电路以及算法步骤可实施为电子硬件、通过处理器执行的计算机软件,或两者的组合。上文已大体在其功能方面描述了各种说明性组件、块、配置、模块、电路和步骤。此类功能是实施为硬件还是处理器可执行指令取决于特定应用和施加于整个系统的设计约束。所属领域的技术人员可针对每一特定应用以不同方式实施所描述的功能,但此类实施决策不应被解释为引起对本公开的范围的偏离。
本文中结合本公开所描述的方法或算法的步骤可直接实施在硬件中、在处理器执行的软件模块中或这两者的组合中。软件模块可驻存在随机存取存储器(ram)、快闪存储器、只读存储器(rom)、可编程只读存储器(prom)、可擦除可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)、寄存器、硬盘、可移除式磁盘、压缩光盘只读存储器(cd-rom)或所属领域中已知的任何其它形式的非暂时性存储媒体中。示范性存储媒体耦合到处理器,使得处理器可从存储媒体读取信息并将信息写入到存储媒体。在替代方案中,存储媒体可与处理器成整体。处理器和存储媒体可驻存在专用集成电路(asic)中。asic可驻存在计算装置或用户终端中。在替代方案中,处理器和存储媒体可作为离散组件驻存在计算装置或用户终端中。
提供先前描述以使所属领域的技术人员能够进行或使用所公开的实施方案。对于所属领域的技术人员来说,对这些实施方案的各种修改将显而易见,且本文中定义的原理可在不脱离本公开的范围的情况下应用于其它实施方案。因此,本公开并不希望限于本文展示的实施方案,而应被赋予与所附权利要求书所定义的原理和新颖特征一致的可能的最广范围。
- 还没有人留言评论。精彩留言会获得点赞!