虚拟现实/增强现实设备和方法与流程
本发明总体上涉及计算机处理器领域。更具体地,本发明涉及一种虚拟现实/增强现实设备和方法。
背景技术:
虚拟现实(vr)指的是通过模拟用户在现实的或想象的环境中的物理存在来复制所述环境的数据处理技术,并且在一些实施方式中,所述用户配备有用于与所述环境进行交互的能力。许多当前vr环境被显示在计算机屏幕上或使用特殊虚拟现实头戴式显示设备来显示。一些模拟包括比如来自针对vr用户的扬声器或耳机的声音等附加传感信息。
相比于利用虚拟世界来完全代替现实世界的vr,增强现实(ar)提供了物理、现实世界环境的视图,其元素已经由诸如图形、音频、视频和/或gps数据等补充传感输入来增强。
附图说明
可以结合以下附图根据以下详细说明获得对本发明的更好理解,在附图中:
图1是具有处理器的计算机系统的实施例的框图,所述处理器具有一个或多个处理器核以及图形处理器;
图2是处理器的一个实施例的框图,所述处理器具有一个或多个处理器核、集成存储器控制器、以及集成图形处理器;
图3是图形处理器的一个实施例的框图,所述图形处理器可以是分立的图形处理单元、或者可以是集成有多个处理核的图形处理器;
图4是用于图形处理器的图形处理引擎的实施例的框图;
图5是图形处理器的另一实施例的框图;
图6是包括处理元件阵列的线程执行逻辑的框图;
图7展示了根据实施例的图形处理器执行单元指令格式;
图8是图形处理器的另一实施例的框图,所述图形处理器包括图形流水线、媒体流水线、显示引擎、线程执行逻辑、以及渲染输出流水线;
图9a是框图,展示了根据实施例的图形处理器命令格式;
图9b是框图,展示了根据实施例的图形处理器命令序列;
图10展示了根据实施例的数据处理系统的示例性图形软件架构;
图11展示了根据实施例的可以用于制造集成电路以执行操作的示例性ip核开发系统;
图12展示了根据实施例的可以使用一个或多个ip核来制造的示例性片上系统集成电路;
图13展示了可以使用一个或多个ip核来制造的片上系统集成电路的示例性图形处理器;
图14展示了可以使用一个或多个ip核来制造的片上系统集成电路的附加示例性图形处理器;
图15a至图15c展示了具有多个图形引擎/流水线的本发明的不同实施例;
图16展示了通过一个或多个流水线级来执行中央凹化控制的一个实施例;
图17展示了根据本发明的一个实施例执行的时间扭曲;
图18展示了根据本发明的一个实施例的音频处理;
图19展示了在本发明的一个实施例中所采用的物理引擎;
图20展示了包括镜头匹配着色和多投影电路系统的一个实施例;
图21展示了分布式虚拟现实实施方式的一个实施例;
图22展示了根据本发明的一个实施例的方法;
图23展示了本发明的具有可调式头戴式显示器的一个实施例;
图24展示了根据本发明的一个实施例的方法;
图25展示了根据本发明的一个实施例的另一种方法;
图26展示了用于执行时间扭曲的架构的一个实施例;
图27展示了用于执行时间扭曲的架构的另一个实施例;
图28展示了根据本发明的一个实施例的方法;
图29展示了根据一个实施例的时间扭曲设备的一个实施例;
图30展示了根据本发明的一个实施例的增强现实系统;
图31展示了根据本发明的一个实施例的增强现实系统;
图32展示了根据本发明的一个实施例的方法;
图33展示了一个实施例,其中,具有不同性能特性的图形处理单元用于左显示器和右显示器;
图34展示了一个实施例,其中,具有不同性能特性的执行资源用于左显示器和右显示器;
图35和图36a至图36b展示了针对左显示器和右显示器来不同地配置执行级的实施例;
图37至图38展示了根据本发明的实施例的方法;
图39展示了具有感兴趣区、次要区和不精确区的示例性图像帧;以及
图40展示了帧内可变帧速率渲染器的一个实施例。
具体实施方式
在以下描述中,出于解释的目的,阐述了许多具体的细节以便提供对以下所述的本发明的实施例的透彻理解。然而,对于本领域技术人员而言,可以在不具有这些具体细节中的一些具体细节的情况下实践本发明的实施例将是明显的。在其他实例中,以框图的形式示出了公知的结构和装置以避免模糊本发明的实施例的基本原理。
示例性图形处理器架构和数据类型
系统概述
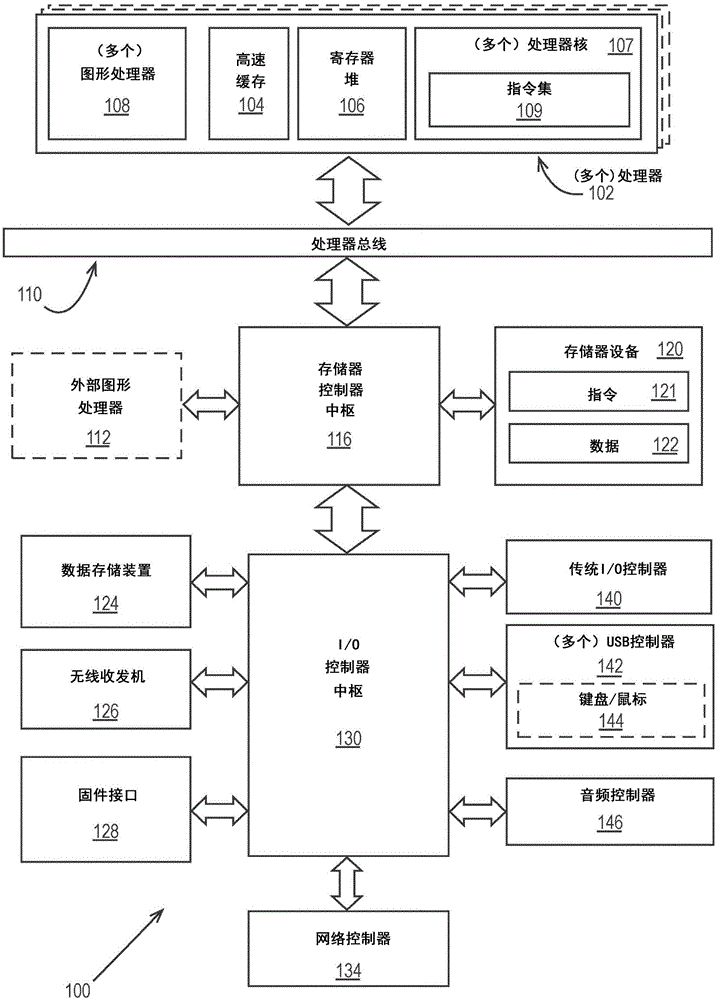
图1是根据实施例的处理系统100的框图。在各实施例中,系统100包括一个或多个处理器102以及一个或多个图形处理器108,并且可以是单处理器台式系统、多处理器工作站系统或具有大量处理器102或处理器核107的服务器系统。在一个实施例中,系统100是被纳入到用于在移动设备、手持式设备或嵌入式设备中使用的芯片上系统(soc)集成电路内的处理平台。
系统100的实施例可以包括或并入基于服务器的游戏平台、游戏控制台,包括游戏与媒体控制台、移动游戏控制台、手持式游戏控制台、或在线游戏控制台。在一些实施例中,系统100是移动电话、智能电话、平板计算设备或移动互联网设备。数据处理系统100还可包括可穿戴设备(诸如智能手表可穿戴设备、智能眼镜设备、增强现实设备、或虚拟现实设备)、与所述可穿戴设备耦合、或者集成在所述可穿戴设备中。在一些实施例中,数据处理系统100是电视或机顶盒设备,所述电视或机顶盒设备具有一个或多个处理器102以及由一个或多个图形处理器108生成的图形界面。
在一些实施例中,一个或多个处理器102每个包括用于处理指令的一个或多个处理器核107,所述指令在被执行时执行系统和用户软件的操作。在一些实施例中,一个或多个处理器核107中的每个处理器核被配置成用于处理特定的指令集109。在一些实施例中,指令集109可以促进复杂指令集计算(cisc)、精简指令集计算(risc)、或经由超长指令字(vliw)的计算。多个处理器核107可以各自处理不同的指令集109,所述指令集可以包括用于促进对其他指令集进行仿真的指令。处理器核107还可以包括其他处理设备,如数字信号处理器(dsp)。
在一些实施例中,处理器102包括高速缓存存储器104。取决于架构,处理器102可以具有单个内部高速缓存或内部高速缓存的多个级。在一些实施例中,在处理器102的各部件当中共享高速缓存存储器。在一些实施例中,处理器102还使用外部高速缓存(例如,3级(l3)高速缓存或末级高速缓存(llc))(未示出),可以使用已知的高速缓存一致性技术来在处理器核107当中共享外部高速缓存。另外地,寄存器堆106包括在处理器102中,所述处理器可以包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器、和指令指针寄存器)。一些寄存器可以是通用寄存器,而其他寄存器可以特定于处理器102的设计。
在一些实施例中,处理器102耦合至处理器总线110,所述处理器总线用于在处理器102与系统100内的其他部件之间传输通信信号,例如地址、数据、或控制信号。在一个实施例中,系统100使用示例性‘中枢’系统架构,包括存储器控制器中枢116和输入输出(i/o)控制器中枢130。存储器控制器中枢116促进存储器设备与系统100的其他部件之间的通信,而i/o控制器中枢(ich)130经由本地i/o总线提供与i/o设备的连接。在一个实施例中,存储器控制器中枢116的逻辑集成在处理器内。
存储器设备120可以是动态随机存取存储器(dram)设备、静态随机存取存储器(sram)设备、闪存设备、相变存储器设备、或具有合适的性能用作处理存储器的某个其他存储器设备。在一个实施例中,存储器设备120可作为系统100的系统存储器进行操作,以存储数据122和指令121,以供在一个或多个处理器102执行应用或进程时使用。存储器控制器中枢116还与可选的外部图形处理器112耦合,所述可选的外部图形处理器可以与处理器102中的一个或多个图形处理器108通信,从而执行图形和媒体操作。
在一些实施例中,ich130使得外围部件经由高速i/o总线连接至存储器设备120和处理器102。i/o外围装置包括但不限于:音频控制器146、固件接口128、无线收发机126(例如,wi-fi、蓝牙)、数据存储设备124(例如,硬盘驱动器、闪存等)、以及用于将传统(例如,个人系统2(ps/2))设备耦合至所述系统的传统i/o控制器140。一个或多个通用串行总线(usb)控制器142连接多个输入设备,例如键盘和鼠标144组合。网络控制器134还可以耦合至ich130。在一些实施例中,高性能网络控制器(未示出)耦合至处理器总线110。应当理解,所示出的系统100是示例性的而非限制性的,因为还可以使用以不同方式配置的其他类型的数据处理系统。例如,i/o控制器中枢130可以集成在一个或多个处理器102内,或者存储器控制器中枢116和i/o控制器中枢130可以集成在分立式外部图形处理器(诸如外部图形处理器112)内。
图2是处理器200的实施例的框图,所述处理器具有一个或多个处理器核202a至202n、集成存储器控制器214、以及集成图形处理器208。图2的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。处理器200可包括多达且包括由虚线框表示的附加核202n的附加核。处理器核202a至202n各自包括一个或多个内部高速缓存单元204a至204n。在一些实施例中,每个处理器核还可以访问一个或多个共享的高速缓存单元206。
内部高速缓存单元204a至204n和共享高速缓存单元206表示处理器200内部的高速缓存存储器层级结构。高速缓存存储器层级结构可以包括每个处理器核内的至少一级指令和数据高速缓存以及一级或多级共享中级高速缓存,诸如2级(l2)、3级(l3)、4级(l4)、或其他级的高速缓存,其中,最高级的高速缓存在外部存储器之前被分类为llc。在一些实施例中,高速缓存一致性逻辑维持各高速缓存单元206与204a至204n之间的一致性。
在一些实施例中,处理器200还可以包括一组一个或多个总线控制器单元216和系统代理核210。一个或多个总线控制器单元216管理一组外围总线,诸如一个或多个外围部件互连总线(例如,pci、pciexpress)。系统代理核210提供对各处理器部件的管理功能。在一些实施例中,系统代理核210包括一个或多个集成存储器控制器214用于管理对各外部存储器设备(未示出)的访问。
在一些实施例中,处理器核202a至202n中的一个或多个包括对同步多线程的支持。在这种实施例中,系统代理核210包括用于在多线程处理过程中协调和操作核202a至202n的部件。另外,系统代理核210还可以包括功率控制单元(pcu),所述功率控制单元包括用于调节处理器核202a至202n的功率状态的逻辑和部件以及图形处理器208。
在一些实施例中,另外,处理器200还包括用于执行图形处理操作的图形处理器208。在一些实施例中,图形处理器208耦合至共享高速缓存单元206集以及系统代理核210,所述系统代理核包括一个或多个集成存储器控制器214。在一些实施例中,显示控制器211与图形处理器208耦合以便将图形处理器输出驱动到一个或多个耦合的显示器。在一些实施例中,显示控制器211可以是经由至少一个互连与图形处理器耦合的单独模块,或者可以集成在图形处理器208或系统代理核210内。
在一些实施例中,基于环的互连单元212用于耦合处理器200的内部部件。然而,可以使用替代性互连单元,比如点到点互连、切换式互连、或其他技术,包括本领域众所周知的技术。在一些实施例中,图形处理器208经由i/o链路213与环形互连212耦合。
示例性i/o链路213表示多个i/o互连中的多个品种中的至少一种,包括促进各处理器部件与高性能嵌入式存储器模块218(比如edram模块)之间的通信的封装体i/o互连。在一些实施例中,处理器核202a至202n中的每个处理器核以及图形处理器208将嵌入式存储器模块218用作共享末级高速缓存。
在一些实施例中,处理器核202a至202n是执行相同指令集架构的均质核。在另一实施例中,处理器核202a至202n在指令集架构(isa)方面是异构的,其中,处理器核202a至202n中的一者或多者执行第一指令集,而其他核中的至少一者执行所述第一指令集的子集或不同的指令集。在一个实施例中,处理器核202a至202n就微架构而言是同质的,其中,具有相对较高功耗的一个或多个核与具有较低功耗的一个或多个功率核耦合。另外,处理器200可以实现在一个或多个芯片上或者被实现为具有除其他部件之外的所展示的部件的soc集成电路。
图3是图形处理器300的框图,所述图形处理器可以是分立式图形处理单元、或者可以是与多个处理核集成的图形处理器。在一些实施例中,图形处理器经由到图形处理器上的寄存器的映射i/o接口并且利用被放置在处理器存储器中的命令与存储器进行通信。在一些实施例中,图形处理器300包括用于访问存储器的存储器接口314。存储器接口314可以是到本地存储器、一个或多个内部高速缓存、一个或多个共享外部高速缓存、和/或到系统存储器的接口。
在一些实施例中,图形处理器300还包括显示控制器302,所述显示控制器用于将显示输出数据驱动到显示设备320。显示控制器302包括用于显示器的一个或多个重叠平面的硬件以及多层视频或用户接口元件的组成。在一些实施例中,图形处理器300包括用于编码、解码、或者向、从或在一个或多个媒体编码格式之间进行媒体代码转换的视频编解码器引擎306,包括但不限于:运动图像专家组(mpeg)(诸如mpeg-2)、高级视频编码(avc)格式(诸如h.264/mpeg-4avc)、以及电影&电视工程师协会(smpte)421m/vc-1、和联合图像专家组(jpeg)格式(诸如jpeg、以及运动jpeg(mjpeg)格式)。
在一些实施例中,图形处理器300包括用于执行二维(2d)光栅化器操作包括例如位边界块传递的块图像传递(blit)引擎304。然而,在一个实施例中,使用图形处理引擎(gpe)310的一个或多个部件执行2d图形操作。在一些实施例中,gpe310是用于执行图形操作的计算引擎,所述图形操作包括三维(3d)图形操作和媒体操作。
在一些实施例中,gpe310包括用于执行3d操作的3d流水线312,比如使用作用于3d图元形状(例如,矩形、三角形等)的处理功能来渲染三维图像和场景。3d流水线312包括可编程且固定的功能元件,所述可编程且固定的功能元件在到3d/媒体子系统315的元件和/或生成的执行线程内执行各种任务。虽然3d流水线312可以用于执行媒体操作,但是gpe310的实施例还包括媒体流水线316,所述媒体流水线具体地用于执行媒体操作,诸如视频后处理和图像增强。
在一些实施例中,媒体流水线316包括固定功能或可编程逻辑单元以便代替、或代表视频编解码器引擎306来执行一种或多种专门的媒体操作,比如视频解码加速、视频解交织、以及视频编码加速。在一些实施例中,另外,媒体流水线316还包括线程生成单元以便生成用于在3d/媒体子系统315上执行的线程。所生成的线程对3d/媒体子系统315中所包括的一个或多个图形执行单元执行对媒体操作的计算。
在一些实施例中,3d/媒体子系统315包括用于执行3d流水线312和媒体流水线316生成的线程的逻辑。在一个实施例中,流水线向3d/媒体子系统315发送线程执行请求,所述3d/媒体子系统包括用于仲裁并将各请求分派到可用的线程执行资源的线程分派逻辑。执行资源包括用于处理3d和媒体线程的图形执行单元阵列。在一些实施例中,3d/媒体子系统315包括用于线程指令和数据的一个或多个内部高速缓存。在一些实施例中,所述子系统还包括共享存储器(包括寄存器和可寻址存储器)以便在线程之间共享数据并用于存储输出数据。
图形处理引擎
图4是根据一些实施例的图形处理器的图形处理引擎410的框图。在一个实施例中,图形处理引擎(gpe)410是图3所示的gpe310的一个版本。图4的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。例如,展示了图3的3d流水线312和媒体流水线316。媒体流水线316在gpe410的一些实施例中是可选的,并且可以不显式地地包括在gpe410内。例如以及在至少一个实施例中,单独的媒体和/或图像处理器被耦合至gpe410。
在一些实施例中,gpe410与命令流转化器403耦合或包括所述命令流转化器,所述命令流转化器向3d流水线312和/或媒体流水线316提供命令流。在一些实施例中,命令流转化器403与存储器耦合,所述存储器可以是系统存储器、或内部高速缓存存储器和共享高速缓存存储器中的一个或多个高速缓存存储器。在一些实施例中,命令流转化器403从存储器接收命令并将这些命令发送至3d流水线312和/或媒体流水线316。所述命令是从存储用于3d流水线312和媒体流水线316的环形缓冲器获取的指示。在一个实施例中,另外,环形缓冲器还可以包括存储多批多命令的批命令缓冲器。用于3d流水线312的命令还可以包括对在存储器中存储的数据的引用,诸如但不限于用于3d流水线312的顶点和几何数据和/或用于媒体流水线316的图像数据和存储器对象。3d流水线312和媒体流水线316通过经由各自流水线内的逻辑执行操作或者通过将一个或多个执行线程分派至执行单元阵列414来处理所述命令。
在各种实施例中,3d流水线312可以通过处理指令并将执行线程分派给图形核阵列414来执行一个或多个着色器程序,诸如顶点着色器、几何着色器、像素着色器、片段着色器、计算着色器或其他着色器程序。图形核阵列414提供统一的执行资源块。图形核阵列414内的多用途执行逻辑(例如,执行单元)包括对各种3dapi着色器语言的支持,并且可以执行与多个着色器相关联的多个同时执行线程。
在一些实施例中,图形核阵列414还包括用于执行诸如视频和/或图像处理的媒体功能的执行逻辑。在一个实施例中,除了图形处理操作之外,执行单元还包括可编程以执行并行通用计算操作的通用逻辑。通用逻辑可以与图1的(多个)处理器核107或图2中的核202a至202n内的通用逻辑并行地或结合地执行处理操作。
由在图形核阵列414上执行的线程生成的输出数据可以将数据输出到统一返回缓冲器(urb)418中的存储器。urb418可以存储多个线程的数据。在一些实施例中,urb418可以用于在图形核阵列414上执行的不同线程之间发送数据。在一些实施例中,urb418可以另外用于图形核阵列上的线程与共享功能逻辑420内的固定功能逻辑之间的同步。
在一些实施例中,图形核阵列414是可缩放的,使得所述阵列包括可变数量的图形核,这些图形核各自具有基于gpe410的目标功率和性能等级的可变数量的执行单元。在一个实施例中,执行资源是动态可缩放的,从而可以根据需要启用或禁用执行资源。
图形核阵列414与共享功能逻辑420耦合,所述共享功能逻辑包括在图形核阵列中的图形核之间共享的多个资源。共享功能逻辑420内的共享功能是向图形核阵列414提供专用补充功能的硬件逻辑单元。在各种实施例中,共享功能逻辑420包括但不限于采样器421、数学422和线程间通信(itc)423逻辑。另外,一些实施例实现共享功能逻辑420内的一个或多个高速缓存425。在给定的专用功能的需求不足以包含在图形核阵列414中的情况下实现共享功能。相反,所述专用功能的单个实例被实现为共享功能逻辑420中的独立实体并且在图形核阵列414内的执行资源之间共享。在图形核阵列414之间共享并包括在图形核阵列414内的精确的一组功能在各实施例之间变化。
图5是图形处理器500的另一个实施例的框图。图5的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。
在一些实施例中,图形处理器500包括环形互连502、流水线前端504、媒体引擎537、以及图形核580a至580n。在一些实施例中,环形互连502将图形处理器耦合至其他处理单元,包括其他图形处理器或者一个或多个通用处理器核。在一些实施例中,图形处理器是集成在多核处理系统内的多个处理器之一。
在一些实施例中,图形处理器500经由环形互连502接收多批命令。传入命令由流水线前端504中的命令流转化器503来解译。在一些实施例中,图形处理器500包括用于经由(多个)图形核580a至580n执行3d几何处理和媒体处理的可缩放执行逻辑。对于3d几何处理命令,命令流转化器503将命令供应至几何流水线536。针对至少一些媒体处理命令,命令流转化器503将命令供应至视频前端534,所述视频前端与媒体引擎537耦合。在一些实施例中,媒体引擎537包括用于视频和图像后处理的视频质量引擎(vqe)530以及用于提供硬件加速的媒体数据编码和解码的多格式编码/解码(mfx)533引擎。在一些实施例中,几何流水线536和媒体引擎537各自生成执行线程,所述执行线程用于由至少一个图形核580a提供的线程执行资源。
在一些实施例中,图形处理器500包括可扩展线程执行资源表征模块核580a至580n(有时被称为核分片),各个可扩展线程执行资源表征模块核具有多个子核550a至550n、560a至560n(有时被称为核子分片)。在一些实施例中,图形处理器500可以具有任意数量的图形核580a至580n。在一些实施例中,图形处理器500包括图形核580a,所述图形核至少具有第一子核550a和第二子核560a。在其他实施例中,图形处理器是具有单个子核(例如,550a)的低功率处理器。在一些实施例中,图形处理器500包括多个图形核580a至580n,所述图形核各自包括一组第一子核550a至550n和一组第二子核560a至560n。所述一组第一子核550a至550n中的每个子核至少包括第一组执行单元552a至552n和媒体/纹理采样器554a至554n。所述一组第二子核560a至560n中的每个子核至少包括第二组执行单元562a至562n和采样器564a至564n。在一些实施例中,每个子核550a至550n、560a至560n共享一组共享资源570a至570n。在一些实施例中,所述共享资源包括共享高速缓存存储器和像素操作逻辑。其他共享资源也可以包括在图形处理器的各实施例中。
执行单元
图6展示了线程执行逻辑600,所述线程执行逻辑包括在gpe的一些实施例中采用的处理元件阵列。图6的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。
在一些实施例中,线程执行逻辑600包括着色器处理器602、线程分派器604、指令高速缓存606、包括多个执行单元608a至608n的可扩展执行单元阵列、采样器610、数据高速缓存612、以及数据端口614。在一个实施例中,可缩放执行单元阵列可以通过基于工作负荷的计算需求来启用或禁用一个或多个执行单元(例如,执行单元608a,608b,608c,608d,一直到608n-1和608n中的任一个)来动态地缩放。在一个实施例中,所包括的部件经由互连结构而互连,所述互连结构链接到部件中的每个部件。在一些实施例中,线程执行逻辑600包括通过指令高速缓存606、数据端口614、采样器610、以及执行单元阵列608a至608n中的一者或多者到存储器(如系统存储器或高速缓存存储器)的一个或多个连接件。在一些实施例中,每个执行单元(例如,608a)是能够执行多个同步硬件线程同时针对每个线程并行地处理多个数据元素的独立可编程通用计算单元。在各种实施例中,执行单元608a至608n的阵列是可缩放的以包括任意数量的单独执行单元。
在一些实施例中,执行单元608a至608n主要用于执行着色器程序。着色器处理器602可以处理各种着色器程序并且经由线程分派器604分派与着色器程序相关联的执行线程。在一个实施例中,线程分派器包括用于对来自图形和媒体流水线的线程发起请求进行仲裁并且在一个或多个执行单元608a至608n上实例化所请求的线程的逻辑。例如,几何流水线(例如,图5的536)可以将顶点处理、曲面细分或几何处理线程分派至线程执行逻辑600(图6)进行处理。在一些实施例中,线程分派器604还可处理来自执行着色器程序的运行时间线程生成请求。
在一些实施例中,执行单元608a至608n支持指令集(所述指令集包括对许多标准3d图形着色器指令的原生支持),从而使得以最小的转换执行来自图形库(例如,direct3d和opengl)的着色器程序。这些执行单元支持顶点和几何处理(例如,顶点程序、几何程序、顶点着色器)、像素处理(例如,像素着色器、片段着色器)以及通用处理(例如,计算和媒体着色器)。执行单元608a至608n中的每一个都能够执行多发布单指令多数据(simd),并且多线程操作能够在面对较高等待时间的存储器访问时实现高效的执行环境。每个执行单元内的每个硬件线程都具有专用的高带宽寄存器堆和相关的独立线程状态。对于具有整数、单精度浮点运算和双精度浮点运算、simd分支功能、逻辑运算、超越运算和其他混杂的运算的流水线,执行是每个时钟的多发布。在等待来自存储器或共享功能之一的数据时,执行单元608a至608n内的依赖性逻辑使等待线程休眠,直到所请求的数据已返回。当等待线程正在休眠时,硬件资源可能会专门用于处理其他线程。例如,在与顶点着色器操作相关联的延迟期间,执行单元可以执行像素着色器、片段着色器或包括不同顶点着色器的另一种类型的着色器程序的操作。
执行单元608a至608n中的每个执行单元在数据元素阵列上进行操作。数据元素的数量是“执行尺寸”、或指令的信道数。执行通道是执行数据元素访问、掩蔽、和指令内的流控制的逻辑单元。通道的数量可以与针对特定图形处理器的物理算术逻辑单元(alu)或浮点单元(fpu)的数量无关。在一些实施例中,执行单元608a至608n支持整数和浮点数据类型。
执行单元指令集包括simd指令。各种数据元素可作为压缩数据类型存储在寄存器中,并且执行单元将基于元素的数据尺寸来处理各种元素。例如,当在256位宽的向量上进行操作时,所述256位的向量存储在寄存器中,并且所述执行单元作为四个单独64位压缩数据元素(四倍字长(qw)尺寸的数据元素)、八个单独32位压缩数据元素(双倍字长(dw)尺寸的数据元素)、十六个单独16位压缩数据元素(字长(w)尺寸的数据元素)、或三十二个单独8位数据元素(字节(b)尺寸的数据元素)在所述向量上进行操作。然而,不同的向量宽度和寄存器尺寸是可能的。
一个或多个内部指令高速缓存(例如,606)包括在所述线程执行逻辑600中以便高速缓存所述执行单元的线程指令。在一些实施例中,一个或多个数据高速缓存(例如,612)被包括用于高速缓存在线程执行过程中的线程数据。在一些实施例中,采样器610被包括用于为3d操作提供纹理采样并且为媒体操作提供媒体采样。在一些实施例中,采样器610包括专门的纹理或媒体采样功能,以便在向执行单元提供采样数据之前在采样过程中处理纹理或媒体数据。
在执行过程中,图形和媒体流水线经由线程生成和分派逻辑向线程执行逻辑600发送线程发起请求。一旦一组几何对象已经被处理并被光栅化成像素数据,则着色器处理器602内的像素处理器逻辑(例如,像素着色器逻辑、片段着色器逻辑等)被调用以便进一步计算输出信息并且使得结果被写入到输出表面(例如,色彩缓冲器、深度缓冲器、模板印刷缓冲器等)。在一些实施例中,像素着色器或片段着色器计算各顶点属性的值,所述各顶点属性跨光栅化对象被内插。在一些实施例中,着色器处理器602内的像素处理器逻辑然后执行应用编程接口(api)供应的像素或片段着色器程序。为了执行着色器程序,着色器处理器602经由线程分派器604将线程分派至执行单元(例如,608a)。在一些实施例中,像素着色器602使用采样器610中的纹理采样逻辑来访问存储器中所存储的纹理图中的纹理数据。对纹理数据和输入几何数据的算术运算计算每个几何片段的像素颜色数据,或丢弃一个或多个像素而不进行进一步处理。
在一些实施例中,数据端口614提供存储器访问机制,供线程执行逻辑600将经处理的数据输出至存储器以便在图形处理器输出流水线上进行处理。在一些实施例中,数据端口614包括或耦合至一个或多个高速缓存存储器(例如,数据高速缓存612)从而经由数据端口高速缓存数据以供存储器访问。
图7是展示了根据一些实施例的图形处理器指令格式700的框图。在一个或多个实施例中,图形处理器执行单元支持具有多种格式的指令的指令集。实线框展示了通常包括在执行单元指令中的部件,而虚线包括可选的部件或仅包括在指令子集中的部件。在一些实施例中,所描述和展示的指令格式700是宏指令,因为它们是供应至执行单元的指令,这与从指令解码产生的微操作相反(一旦所述指令被处理)。
在一些实施例中,图形处理器执行单元原生地支持采用128位指令格式710的指令。64位紧凑指令格式730可用于基于所选指令、多个指令选项和操作数数量的一些指令。原生128位指令格式710提供对所有指令选项的访问,而一些选项和操作限制在64位指令格式730中。64位指令格式730中可用的原生指令根据实施例而不同。在一些实施例中,使用索引字段713中的一组索引值将指令部分地压缩。执行单元硬件基于索引值来参考一组压缩表,并使用压缩表输出来重构采用128位指令格式710的原生指令。
针对每种格式,指令操作码712限定执行单元要执行的操作。执行单元跨每个操作数的多个数据元素来并行地执行每条指令。例如,响应于添加指令,执行单元跨每个颜色通道执行同步添加操作,所述颜色通道表示纹理元素或图片元素。默认地,执行单元跨操作数的所有数据通道执行每条指令。在一些实施例中,指令控制字段714使能控制某些执行选项,诸如通道选择(例如,预测)以及数据通道排序(例如,混合)。针对采用128位指令格式710的指令,执行尺寸字段716限制了将并行执行的数据通道的数量。在一些实施例中,执行尺寸字段716不可用于64位紧凑指令格式730。
一些执行单元指令具有多达三个操作数,包括两个源操作数(src0720、src1722)和一个目的地718。在一些实施例中,执行单元支持双目的地指令,其中这些目的地之一是隐式的。数据操作指令可以具有第三源操作数(例如,src2724),其中,指令操作码712确定源操作数的数量。指令的最后的源操作数可以是利用所述指令传递的即时(例如,硬编码)值。
在一些实施例中,128位指令格式710包括访问/地址模式字段726,所述访问/地址模式信息例如限定了是使用直接寄存器寻址模式还是间接寄存器寻址模式。当使用直接寄存器寻址模式时,直接由指令中的位来提供一个或多个操作数的寄存器地址。
在一些实施例中,128位指令格式710包括访问/地址模式字段726,所述访问/地址模式字段指定指令的地址模式和/或访问模式。在一个实施例中,访问模式用于限定针对指令的数据访问对齐。一些实施例支持访问模式,包括16字节对齐访问模式和1字节对齐访问模式,其中,访问模式的字节对齐确定了指令操作数的访问对齐。例如,当在第一模式中时,指令可以使用字节对齐寻址以用于源操作数和目的地操作数,并且当在第二模式中时,指令可以使用16字节对齐寻址以用于所有的源操作数和目的地操作数。
在一个实施例中,访问/地址模式字段726的地址模式部分确定指令是使用直接寻址还是间接寻址。当使用直接寄存器寻址模式时,指令中的位直接提供一个或多个操作数的寄存器地址。当使用间接寄存器寻址模式时,可以基于指令中的地址寄存器值和地址立即数字段来计算一个或多个操作数的寄存器地址。
在一些实施例中,基于操作码712位字段对指令进行分组从而简化操作码解码740。针对8位的操作码,第4、5、和6位允许执行单元确定操作码的类型。所示出的精确操作码分组仅是示例性的。在一些实施例中,移动和逻辑操作码组742包括数据移动和逻辑指令(例如,移动(mov)、比较(cmp))。在一些实施例中,移动和逻辑组742共享五个最高有效位(msb),其中移动(mov)指令采用0000xxxxb的形式,而逻辑指令采用0001xxxxb的形式。流控制指令组744(例如,调用(call)、跳(jmp))包括采用0010xxxxb形式(例如,0x20)的指令。混杂的指令组746包括指令的混合,包括采用0011xxxxb形式(例如,0x30)的同步指令(例如,等待(wait)、发送(send))。并行数学指令组748包括采用0100xxxxb形式(例如,0x40)的按分量的算术指令(例如,加(add)、乘(mul))。并行数学组748跨数据通道并行地执行算术运算。向量数学组750包括采用0101xxxxb形式(例如,0x50)的算术指令(例如,dp4)。向量数学组对向量操作数执行算术运算,诸如点积运算。
图形流水线
图8是图形处理器800的另一个实施例的框图。图8的具有与此处任何其他附图中的元件相同的参考号(或名称)的那些元件可采用与在本文中其他地方描述的方式相类似的任何方式进行操作或起作用,但不限于这些。
在一些实施例中,图形处理器800包括图形流水线820、媒体流水线830、显示引擎840、线程执行逻辑850、以及渲染输出流水线870。在一些实施例中,图形处理器800是包括一个或多个通用处理核的多核处理系统内的图形处理器。图形处理器受到至一个或多个控制寄存器(未示出)的寄存器写入的控制或者经由环形互连802经由发布至图形处理器800的命令被控制。在一些实施例中,环形互连802将图形处理器800耦合至其他处理部件,比如其他图形处理器或通用处理器。来自环形互连802的命令通过命令流转化器803被解译,所述命令流转化器将指令供应至图形流水线820或媒体流水线830的单独部件。
在一些实施例中,命令流转化器803引导顶点获取器805的操作,所述顶点获取器从存储器读取顶点数据并执行由命令流转化器803所提供的顶点处理命令。在一些实施例中,顶点获取器805将顶点数据提供给顶点着色器807,所述顶点着色器对每个顶点执行坐标空间变换和照明操作。在一些实施例中,顶点获取器805和顶点着色器807通过经由线程分派器831向执行单元852a至852b分派执行线程来执行顶点处理指令。
在一些实施例中,执行单元852a至852b是具有用于执行图形和媒体操作的指令集的向量处理器阵列。在一些实施例中,执行单元852a至852b具有附接的l1高速缓存851,所述高速缓存专用于每个阵列或在阵列之间共享。高速缓存可以被配置为数据高速缓存、指令高速缓存、或单个高速缓存,所述单个高速缓存被分区为包含不同分区中的数据和指令。
在一些实施例中,图形流水线820包括用于执行3d对象的硬件加速曲面细分的曲面细分部件。在一些实施例中,可编程的外壳着色器811配置曲面细分操作。可编程域着色器817提供对曲面细分输出的后端评估。曲面细分器813在外壳着色器811的方向上进行操作并且包含专用逻辑,所述专用逻辑用于基于粗糙几何模型来生成详细的几何对象集合,所述粗糙几何模型作为输入被提供至图形流水线820。在一些实施例中,如果未使用曲面细分,则可以对曲面细分部件(例如,外壳着色器811、曲面细分器813、域着色器817)进行旁路。
在一些实施例中,完整的几何对象可以由几何着色器819经由被分派至所述执行单元852a至852b的一个或多个线程来处理、或者可以直接行进至剪辑器829。在一些实施例中,几何着色器在整个几何对象(而非顶点或者如图形流水线的先前级中的顶点补片)上进行操作。如果禁用曲面细分,则几何着色器819从顶点着色器807接收输入。在一些实施例中,几何着色器819可由几何着色器程序编程以便在曲面细分单元被禁用时执行几何曲面细分。
在光栅化之前,剪辑器829处理顶点数据。剪辑器829可以是固定功能的剪辑器或者具有剪辑和几何着色器功能的可编程剪辑器。在一些实施例中,渲染输出流水线870中的光栅和深度测试部件873分派像素着色器以将几何对象转换成其每像素表示。在一些实施例中,像素着色器逻辑包括在线程执行逻辑850中。在一些实施例中,应用可对光栅和深度测试部件873进行旁路并且经由流出单元823访问未光栅化的顶点数据。
图形处理器800具有互连总线、互连结构、或某个其他的互连机制,所述互连机制允许数据和消息在所述图形处理器的主要部件之中传递。在一些实施例中,执行单元852a至852b和(多个)相关联的高速缓存851、纹理和媒体采样器854、以及纹理/采样器高速缓存858经由数据端口856进行互连,以便执行存储器访问并且与处理器的渲染输出流水线部件进行通信。在一些实施例中,采样器854、高速缓存851、858以及执行单元852a至852b各自具有单独的存储器访问路径。
在一些实施例中,渲染输出流水线870包含光栅和深度测试部件873,所述光栅和深度测试部件将基于顶点的对象转换为相关联的基于像素的表示。在一些实施例中,光栅化器逻辑包括用于执行固定功能三角形和线光栅化的窗口器/掩蔽器单元。相关联的渲染高速缓存878和深度高速缓存879在一些实施例中也是可用的。像素操作部件877对数据进行基于像素的操作,然而在一些实例中,与2d操作(例如,利用混合的位块图像传递)相关联的像素操作由2d引擎841执行、或者在显示时间由显示控制器843使用重叠显示平面来代替。在一些实施例中,共享的l3高速缓存875可用于所有的图形部件,从而允许在无需使用主系统存储器的情况下共享数据。
在一些实施例中,图形处理器媒体流水线830包括媒体引擎837和视频前端834。在一些实施例中,视频前端834从命令流转化器803接收流水线命令。在一些实施例中,媒体流水线830包括单独的命令流转化器。在一些实施例中,视频前端834在将所述命令发送至媒体引擎837之前处理媒体命令。在一些实施例中,媒体引擎837包括用于生成线程以用于经由线程分派器831分派至线程执行逻辑850的线程生成功能。
在一些实施例中,图形处理器800包括显示引擎840。在一些实施例中,显示引擎840在处理器800外部并且经由环形互连802、或某个其他互连总线或机构与图形处理器耦合。在一些实施例中,显示引擎840包括2d引擎841和显示控制器843。在一些实施例中,显示引擎840包含能够独立于3d流水线而操作的专用逻辑。在一些实施例中,显示控制器843与显示设备(未示出)耦合,所述显示设备可以是系统集成显示设备(如在膝上型计算机中)、或者经由显示设备连接器附接的外部显示设备。
在一些实施例中,图形流水线820和媒体流水线830可被配置成用于基于多个图形和媒体编程接口执行操作并且并非专用于任何一种应用编程接口(api)。在一些实施例中,图形处理器的驱动器软件将专用于特定图形或媒体库的api调度转换成可由图形处理器处理的命令。在一些实施例中,为全部来自khronosgroup的开放图形库(opengl)、开放计算语言(opencl)和/或vulkan图形和计算api提供了支持。在一些实施例中,也可以为微软公司的direct3d库提供支持。在一些实施例中,可以支持这些库的组合。还可以为开源计算机视觉库(opencv)提供支持。如果可做出从未来api的流水线到图形处理器的流水线的映射,则具有兼容3d流水线的未来api也将受到支持。
图形流水线编程
图9a是展示了根据一些实施例的图形处理器命令格式900的框图。图9b是展示了根据实施例的图形处理器命令序列910的框图。图9a中的实线框展示了通常包括在图形命令中的部件,而虚线包括是可选的或者仅包括在所述图形命令的子集中的部件。图9a的示例性图形处理器命令格式900包括用于标识命令的目标客户端902、命令操作代码(操作码)904、以及用于命令的相关数据906的数据字段。一些命令中还包括子操作码905和命令尺寸908。
在一些实施例中,客户端902限定了处理命令数据的图形设备的客户端单元。在一些实施例中,图形处理器命令解析器检查每个命令的客户端字段以便调整对命令的进一步处理并将命令数据路由至合适的客户端单元。在一些实施例中,图形处理器客户端单元包括存储器接口单元、渲染单元、2d单元、3d单元、和媒体单元。每个客户端单元具有对命令进行处理的相应处理流水线。一旦命令被客户端单元接收到,客户端单元就读取操作码904以及子操作码905(如果存在的话)从而确定要执行的操作。客户端单元使用数据字段906内的信息来执行命令。针对一些命令,期望显式地的命令尺寸908来限定命令的尺寸。在一些实施例中,命令解析器基于命令操作码自动地确定命令中的至少一些命令的尺寸。在一些实施例中,经由双倍字长的倍数对命令进行对齐。
图9b中的流程图示出了示例性图形处理器命令序列910。在一些实施例中,以图形处理器的实施例为特征的数据处理系统的软件或固件使用所示出的命令序列的版本来启动、执行并终止图形操作集合。仅出于示例性目的示出并描述了样本命令序列,如实施例并不限于这些特定命令或者此命令序列。而且,所述命令可以作为一批命令以命令序列被发布,从而使得图形处理器将以至少部分同时的方式处理命令序列。
在一些实施例中,图形处理器命令序列910可以以流水线转储清除命令912开始以便使得任一活跃图形流水线完成针对所述流水线的当前未决命令。在一些实施例中,3d流水线922和媒体流水线924不同时进行操作。执行流水线转储清除以使得活动图形流水线完成任何未决命令。响应于流水线转储清除,用于图形处理器的命令解析器将停止命令处理直到活跃绘画引擎完成未决操作并且使得相关的读高速缓存失效。可选地,渲染高速缓存中被标记为‘脏’的任何数据可以被转储清除到存储器中。在一些实施例中,流水线转储清除命令912可以用于流水线同步或者用在将图形处理器置于低功率状态之前。
在一些实施例中,当命令序列需要图形处理器在流水线之间显式地地切换时,使用流水线选择命令913。在一些实施例中,在发布流水线命令之前在执行情境中仅需要一次流水线选择命令913,除非所述情境要发布针对两条流水线的命令。在一些实施例中,在经由流水线选择命令913的流水线切换之前正好需要流水线转储清除命令912。
在一些实施例中,流水线控制命令914配置用于操作的图形流水线并且用于对3d流水线922和媒体流水线924进行编程。在一些实施例中,流水线控制命令914配置活跃流水线的流水线状态。在一个实施例中,流水线控制命令914用于流水线同步并且用于在处理一批命令之前清除来自活跃流水线内的一个或多个高速缓存存储器中的数据。
在一些实施例中,用于返回缓冲器状态916的命令用于配置返回缓冲器的集合以供相应的流水线写入数据。一些流水线操作需要分配、选择、或配置一个或多个返回缓冲器,在处理过程中所述操作将中间数据写入所述一个或多个返回缓冲器中。在一些实施例中,图形处理器还使用一个或多个返回缓冲器以便存储输出数据并且执行跨线程通信。在一些实施例中,配置返回缓冲器状态916包括选择返回缓冲器的尺寸和数量以用于流水线操作集合。
命令序列中的剩余命令基于用于操作的活跃流水线而不同。基于流水线判定920,所述命令序列被定制用于以3d流水线状态930开始的3d流水线922、或者在媒体流水线状态940处开始的媒体流水线924。
用于3d流水线状态930的命令包括用于顶点缓冲器状态、顶点元素状态、常量颜色状态、深度缓冲器状态、以及有待在处理3d图元命令之前配置的其他状态变量的3d状态设置命令。这些命令的值至少部分地基于使用中的特定3dapi来确定。在一些实施例中,3d流水线状态930命令还能够选择性地禁用或旁路掉特定流水线元件(如果将不使用那些元件的话)。
在一些实施例中,3d图元932命令用于提交待由3d流水线处理的3d图元。经由3d图元932命令传递给图形处理器的命令和相关联参数将被转发到所述图形流水线中的顶点获取功能。顶点获取功能使用3d图元932命令数据来生成多个顶点数据结构。所述顶点数据结构被存储在一个或多个返回缓冲器中。在一些实施例中,3d图元932命令用于经由顶点着色器对3d图元执行顶点操作。为了处理顶点着色器,3d流水线922将着色器执行线程分派至图形处理器执行单元。
在一些实施例中,经由执行934命令或事件触发3d流水线922。在一些实施例中,寄存器写入触发命令执行。在一些实施例中,经由命令序列中的‘前进’(‘go’)或‘拣选’(‘kick’)命令来触发执行。在一个实施例中,使用流水线同步命令来触发命令执行以便通过图形流水线转储清除命令序列。3d流水线将针对3d图元来执行几何处理。一旦完成操作,则对所产生的几何对象进行光栅化,并且像素引擎对所产生的像素进行着色。对于这些操作,还可以包括用于控制像素着色和像素后端操作的附加命令。
在一些实施例中,当执行媒体操作时,图形处理器命令序列910跟随在媒体流水线924路径之后。一般地,针对媒体流水线924进行编程的具体用途和方式取决于待执行的媒体或计算操作。在媒体解码过程中,特定的媒体解码操作可以被卸载到所述媒体流水线。在一些实施例中,还可对媒体流水线进行旁路,并且可使用由一个或多个通用处理核提供的资源来整体地或部分地执行媒体解码。在一个实施例中,媒体流水线还包括用于通用图形处理器单元(gpgpu)操作的元件,其中,所述图形处理器用于使用计算着色器程序来执行simd向量运算,所述计算着色器程序与渲染图形图元不是显式地相关的。
在一些实施例中,以与3d流水线922相似的方式对媒体流水线924进行配置。将用于配置媒体流水线状态940的一组命令分派或放置到命令队列中,在媒体对象命令942之前。在一些实施例中,用于媒体流水线状态940的命令包括用于配置媒体流水线元件的数据,所述媒体流水线元件将用于处理媒体对象。这包括用于在媒体流水线内配置视频解码和视频编码逻辑的数据,诸如编码或解码格式。在一些实施例中,用于媒体流水线状态940的命令还支持将一个或多个指针用于包含一批状态设置的“间接”状态元件。
在一些实施例中,媒体对象命令942将指针供应至媒体对象以用于由媒体流水线进行处理。媒体对象包括存储器缓冲器,所述存储器缓冲器包含待处理的视频数据。在一些实施例中,在发布媒体对象命令942之前,所有的媒体流水线状态必须是有效的。一旦流水线状态被配置并且媒体对象命令942被排队,则经由执行944命令或等效的执行事件(例如,寄存器写入)来触发媒体流水线924。然后可以通过由3d流水线922或媒体流水线924提供的操作对来自媒体流水线924的输出进行后处理。在一些实施例中,以与媒体操作类似的方式来配置和执行gpgpu操作。
图形软件架构
图10展示了根据一些实施例的数据处理系统1000的示例性图形软件架构。在一些实施例中,软件架构包括3d图形应用1010、操作系统1020、以及至少一个处理器1030。在一些实施例中,处理器1030包括图形处理器1032以及一个或多个通用处理器核1034。图形应用1010和操作系统1020各自在数据处理系统的系统存储器1050中执行。
在一些实施例中,3d图形应用1010包含一个或多个着色器程序,所述一个或多个着色器程序包括着色器指令1012。着色器语言指令可以采用高级着色器语言,诸如高级着色器语言(hlsl)或opengl着色器语言(glsl)。所述应用还包括可执行指令1014,所述可执行指令采用适合用于由通用处理器核1034执行的机器语言。所述应用还包括由顶点数据限定的图形对象1016。
在一些实施例中,操作系统1020是来自微软公司的
在一些实施例中,用户模式图形驱动器1026包含后端着色器编译器1027,所述后端着色器编译器用于将着色器指令1012转换成硬件专用的表示。当在使用openglapi时,将采用glsl高级语言的着色器指令1012传递至用户模式图形驱动器1026以用于编译。在一些实施例中,用户模式图形驱动器1026使用操作系统内核模式功能1028来与内核模式图形驱动器1029进行通信。在一些实施例中,内核模式图形驱动器1029与图形处理器1032进行通信以便分派命令和指令。
ip核实现
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性代码实现,所述机器可读介质表示和/或限定集成电路诸如处理器内的逻辑。例如,机器可读介质可以包括表示处理器内的各个逻辑的指令。当由机器读取时,所述指令可以使机器制造用于执行本文所述的技术的逻辑。这类表示(称为“ip核”)是集成电路的逻辑的可重复使用单元,所述可重复使用单元可以作为对集成电路的结构进行描述的硬件模型而存储在有形、机器可读介质上。可以将硬件模型供应至在制造集成电路的制造机器上加载硬件模型的各消费者或制造设施。可以制造集成电路,从而使得电路执行与本文所述的实施例中的任一实施例相关联地描述的操作。
图11是展示了根据实施例的可以用于制造集成电路以执行操作的ip核开发系统1100的框图。ip核开发系统1100可以用于生成可并入到更大的设计中或用于构建整个集成电路(例如,soc集成电路)的模块化、可重复使用设计。设计设施1130可采用高级编程语言(例如,c/c++)生成对ip核设计的软件仿真1110。软件仿真1110可用于使用仿真模型1112来设计、测试并验证ip核的行为。仿真模型1112可以包括功能、行为和/或时序仿真。然后可由仿真模型1112来创建或合成寄存器传输级(rtl)设计1115。rtl设计1115是对硬件寄存器之间的数字信号的流动进行建模的集成电路(包括使用建模的数字信号执行的相关联逻辑)的行为的抽象。除了rtl设计1115之外,还可以创建、设计或合成逻辑电平或晶体管电平处的较低层次设计。由此,初始设计和仿真的具体细节可以发生变化。
可以由设计设施将rtl设计1115或等效方案进一步合成为硬件模型1120,所述硬件模型可以采用硬件描述语言(hdl)或物理设计数据的某种其他表示。可以进一步仿真或测试hdl以验证ip核设计。可使用非易失性存储器1140(例如,硬盘、闪存、或任何非易失性存储介质)来存储ip核设计以用于递送至第3方制造设施1165。可替代地,可以通过有线连接1150或无线连接1160来传输(例如,经由互联网)ip核设计。制造设施1165然后可以制造至少部分地基于ip核设计的集成电路。所制造的集成电路可被配置用于执行根据本文所述的至少一个实施例的操作。
示例性芯片上系统集成电路
图12至图14展示了根据本文所述的各种实施例的可以使用一个或多个ip核来制造的示例性集成电路和相关图形处理器。除了所展示的之外,还可以包括其他逻辑和电路,包括附加的图形处理器/核、外围接口控制器或通用处理器核。
图12是展示了根据实施例的可以使用一个或多个ip核来制造的示例性芯片上系统集成电路1200的框图。示例性集成电路1200包括一个或多个应用处理器1205(例如,cpu)、至少一个图形处理器1210,并且另外还可以包括图像处理器1215和/或视频处理器1220,其中的任一项都可以是来自相同或多个不同设计设施的模块化ip核。集成电路1200包括外围或总线逻辑,包括usb控制器1225、uart控制器1230、spi/sdio控制器1235和i2s/i2c控制器1240。另外,集成电路还可以包括显示设备1245,所述显示设备耦合至高清晰度多媒体接口(hdmi)控制器1250和移动行业处理器接口(mipi)显示界面1255中的一项或多项。可以由闪存子系统1260(包括闪存和闪存控制器)来提供存储。可以经由存储器控制器1265来提供存储器接口以访问sdram或sram存储器设备。另外,一些集成电路还包括嵌入式安全引擎1270。
图13是展示了根据实施例的可以使用一个或多个ip核来制造的芯片上系统集成电路的示例性图形处理器1310的框图。图形处理器1310可以是图12的图形处理器1210的变体。图形处理器1310包括顶点处理器1305和一个或多个片段处理器1315a至1315n(例如,1315a,1315b,1315c,1315d,一直到1315n-1和1315n)。图形处理器1310可以经由单独的逻辑执行不同的着色器程序,使得顶点处理器1305被优化以执行顶点着色器程序的操作,而一个或多个片段处理器1315a至1315n执行片段(例如,像素)着色操作以用于片段或像素着色器程序。顶点处理器1305执行3d图形流水线的顶点处理阶段并生成图元和顶点数据。(多个)片段处理器1315a至1315n使用由顶点处理器1305生成的图元和顶点数据来产生显示在显示设备上的帧缓冲器。在一个实施例中,(多个)片段处理器1315a至1315n被优化以执行openglapi中提供的片段着色器程序,这些片段着色器程序可以用于执行与direct3dapi中提供的像素着色器程序相似的操作。
另外,图形处理器1310还包括一个或多个存储器管理单元(mmu)1320a至1320b、一个或多个高速缓存1325a至1325b和(多个)电路互连1330a至1330b。一个或多个mmu1320a至1320b为图形处理器1310包括为顶点处理器1305和/或一个或多个片段处理器1315a至1315n提供虚拟到物理地址映射,除了存储在一个或多个高速缓存1325a至1325b中的顶点或图像/纹理数据之外,所述虚拟到物理地址映射还可以引用存储在存储器中的顶点或图像/纹理数据。在一个实施例中,一个或多个mmu1320a至1320b可以与系统内的其他mmu包括与图12的一个或多个应用处理器1205、图像处理器1215和/或视频处理器1220相关联的一个或多个mmu同步,使得每个处理器1205至1220可以参与共享或统一的虚拟存储器系统。根据实施例,一个或多个电路互连1330a至1330b使得图形处理器1310能够经由soc的内部总线或经由直接连接来与soc内的其他ip核交互。
图14是展示了根据实施例的可以使用一个或多个ip核来制造的芯片上系统集成电路的附加示例性图形处理器1410的框图。图形处理器1410可以是图12的图形处理器1210的变体。图形处理器1410包括图13的集成电路1300的一个或多个mmu1320a至1320b、高速缓存1325a至1325b和电路互连1330a至1330b。
图形处理器1410包括一个或多个着色器核1415a至1415n(例如,1415a、1415b、1415c、1415d、1415e、1415f、一直到1415n-1和1415n),所述一个或多个着色器核提供统一的着色器核架构,其中单个核或类型或核可以执行所有类型的可编程着色器代码包括着色器程序代码以实现顶点着色器、片段着色器和/或计算着色器。存在的着色器核的确切数量可以在实施例和实现中变化。另外,图形处理器1410还包括核间任务管理器1405,所述核间任务管理器充当用于将执行线程分派给一个或多个着色器核1415a至1415n的线程分派器和用于加快分块操作以进行基于图块的渲染的分块单元1418,其中场景的渲染操作在图像空间中被细分,例如以利用场景内的本地空间一致性或优化内部高速缓存的使用。
增强现实/虚拟现实设备和方法
a.概述
本发明的实施例可以在诸如图15a中展示的包括图形系统部件1580和头戴式显示器(hmd)1550的虚拟现实系统等虚拟现实系统中实施。在一个实施例中,hmd1550包括右显示器1551和左显示器1552,在右显示器上图像帧被渲染以供用户右眼查看,并且在左显示器上图像帧被渲染以供用户左眼查看。单独的图形引擎1556和1557包括用于响应于执行特定虚拟现实应用1561而分别对右图像帧和左图像帧进行渲染的图形处理流水线。每个图形引擎1556至1557可以包括单独的图形处理单元(gpu)。可替代地,图形引擎1556至1557可以包括单个gpu内的或跨多个gpu分布的不同组图形执行资源。例如,在虚拟化环境中,可以向每个显示器1551至1552分配单独的虚拟gpu(vgpu)。无论gpu资源是如何划分的,图形引擎1556至1557可以实施本文所描述的任何图形处理技术。
在一个实施例中,集成在hmd1550上的用户/眼睛跟踪装置1553包括用于检测用户头部的当前取向以及用户凝视的方向的传感器。例如,可以使用光学传感器和加速度计来捕获用户头部的取向,同时可以利用诸如相机等光学眼睛跟踪装置来捕获用户凝视的当前方向。如所展示的,用户/眼睛跟踪装置1553向图形系统1580提供用户的当前视图1560,所述图形系统然后相应地调整图形处理(即,以便确保正被渲染的当前图像帧是从用户的当前视角来看的)。
在一个实施例中,虚拟现实应用1561利用图形应用编程接口(api)1562来实施如本文所描述的图形引擎1556至1557的特征。例如,图形api1562可以配备有虚拟现实软件开发包(sdk)1563,开发人员可以使用所述软件开发包来生成虚拟现实应用1561的应用程序代码。例如,虚拟现实sdk1563可以包编译器(和/或其他设计工具),所述编译器括用于生成针对使用api1562(例如,通过调用所述api中所包括的功能/命令)的虚拟现实应用1561的目标代码。本文所描述的技术中的一种或多种技术可以使用图形api1562、图形引擎1556至1557内的硬件、和/或其组合来实施。
图15b展示了根据一个实施例的针对右显示器和左显示器1551至1552的两个图形流水线的各个级。具体地,基于光栅化的流水线被展示为包括从存储器1515中读取索引和顶点数据的输入汇集器(ia)1521a-b、以及顶点着色器(vs)1522a-b。如所提及的,可以由ia1521a-b经由图形api1562接收命令。顶点着色器1522a-b对每个顶点执行着色操作(例如,将虚拟空间中的每个顶点的3d位置变换成其出现在屏幕上的2d坐标)并生成采用图元形式(例如,三角形)的结果。几何着色器(gs)1523a-b将整个图元用作输入,可能具有邻接信息。例如,当对三角形进行操作时,这三个顶点作为几何着色器的输入。然后,几何着色器1523a-b可以发射零个或更多个图元,所述图元在光栅化级1524a-b处被光栅化,并且所得片段最终被传递到像素着色器(ps)1525a-b,所述像素着色器对在被显示在hmd上之前逐帧存储在帧缓冲器1526a-b内的各个像素中的每个像素执行着色操作。
在一个实施例中,可以采用诸如视线追踪架构等全局照明图形处理架构。图15c例如展示了示例性基于视线追踪的图形流水线1500,其中,一个或多个流水线级1501a-b至1505a-b针对左显示器和右显示器1551至1552执行基于视线追踪的渲染。所展示的各个级包括生成视线以供处理的视线生成模块1501a-b。例如,一个实施例每个图像图块地执行广度优先视线追踪,其中,图块表示较小的固定大小矩形区。在广度优先实施方式的一个实施例中,针对图像图块上的每次迭代生成每个像素一条视线。视线遍历模块1502a-b针对包围体层次(boundingvolumehierarchy,bvh)或其他加速度数据结构遍历每条视线。一个或多个相交模块1503a-b对一个或多个三角形或其他图元测试视线,并且最后,遍历单元和相交单元必须找到每条视线所相交的最接近图元。然后,一个或多个着色器单元1504a-b对在被显示在hmd1550上之前逐帧存储在帧缓冲器1505a-b内的所得像素执行着色操作。
b.中央凹化渲染
本发明的一个实施例采用中央凹化渲染、数字图像处理技术,其中,图像分辨率、或细节量根据一个或多个“注视点”而跨图像变化。注视点指图像的最高分辨率区并且与中央凹——眼睛视网膜中心相对应。可以采用不同的方式来指定注视点位置。例如,在虚拟现实实施方式中,使用精确地测量眼睛的位置和运动的眼睛跟踪装置来确定注视点。可以在注视点周围的区中使用比在图像的其他区中更高的分辨率。例如,如图16中所展示的,中央凹化控制模块1620可以控制光栅化器1404针对图像的中央凹化区域使用更高的样本或像素密度。
c.时间扭曲
可以在使用时间扭曲的vr系统中采用本发明的一些实施例。时间扭曲是一种用于改善当前虚拟现实(vr)系统的性能的技术。根据这种技术,根据用户头部和/或眼睛的当前取向(即,如从头戴式显示器(hmd)上的眼睛跟踪装置和/或其他传感器中所读取的,用于检测用户头部的运动)来渲染每个图像帧。就在显示下一个图像帧之前,再次捕获传感器数据并用其来变换场景以适于最近的传感器数据(即,“扭曲”当前图像帧)。通过利用已经生成的深度图(即,z缓冲器),时间扭曲可以以相对较低的计算需求来移动3d空间中的对象。
将关于图17来描述一个实施例,此图展示了通信地耦合到头戴式显示器(hmd)1350的图形处理引擎1300。执行vr应用1310,从而生成有待由图形处理引擎1300执行的图形数据和图形命令。图形处理引擎1300可以包括一个或多个图形处理单元(gpu),所述gpu包括用于执行图形命令并对有待在hmd1350上显示的图像帧进行渲染的图形流水线(例如,诸如本文所描述的图形流水线)。为了简单起见,图17中仅示出了单个显示器1717,其可以是左显示器和/或右显示器。
在操作中,图像渲染模块1305对有待在左显示器和右显示器1717中显示的图像帧进行渲染。在一个实施例中,根据如由hmd1350上所集成的用户/眼睛跟踪模块1353提供的用户头部和/或眼睛的当前取向来对每个图像进行渲染。具体地,hmd1350可以包括用于跟踪用户头部的当前取向的各种传感器、以及用于跟踪用户眼睛的当前焦点的相机及相关联电路系统/逻辑。在虚拟现实实施方式中,此数据用于从正确的视角(即,基于用户当前凝视的方向和焦点)对左/右图像进行渲染。
虽然为了简单起见在图17中被展示为单个部件,但是可以针对左图像帧和右图像帧使用分开的图像渲染电路系统和逻辑。此外,为了避免模糊本发明的基本原理,未展示各种其他图形流水线级,包括例如顶点着色器、几何着色器和纹理映射器。在一个实施例中所采用的视线追踪架构可以包括视线生成模块、视线遍历模块、相交模块以及着色模块。在任何实施方式中,渲染模块1705基于用户的当前取向/凝视来对左显示器和右显示器1717的图像进行渲染。
在所展示的实施例中,第一帧缓冲器1716正存储有当前在hmd的左/右显示器1717内显示的图像帧n-1。然后,在第二帧缓冲器1715内对有待显示的下一个图像帧(图像帧n)进行渲染。在一个实施例中,图像渲染模块1705使用由用户/眼睛跟踪模块1553提供的坐标数据来在帧缓冲器1715内对所述下一帧进行渲染。在需要在左显示器和/或右显示器1717内显示所述下一帧时,时间扭曲模块1720对图像帧n-1或图像帧n(如果对图像帧n的渲染完成)进行变换以适于由用户/眼睛跟踪模块1553提供的最近的传感器数据。此变换是由时间扭曲模块1720使用存储在处理引擎的z缓冲器1718中的先前生成的深度图来执行的。此变换以相对较小的计算需求来移动3d空间中的对象,从而产生最近完成的产品而无需对场景进行重新渲染。因此,在大多数情况下,其应该基本上类似于在如果渲染发生得更快的情况下所渲染的图像帧。
d.附加vr实施例
如图18中所展示的,在一个实施例中,音频处理逻辑1802响应于当前视图1860而产生左音频流和右音频流。具体地,在一个实施例中,音频处理逻辑1802根据用户头部在虚拟环境内的当前取向来生成集成在hmd1550上的左扬声器1851和右扬声器1852的音频。例如,如果汽车经过用户的左侧,则音频处理逻辑1802将使所述汽车的声音在左扬声器1851中更加明显,从而产生更加逼真的效果。音频处理逻辑1802可以实施各种类型的音频处理技术,通过举例而非限制的方式,包括杜比数字影院、杜比3d、dts耳机:x、以及dtsneo:pc等。
如图19中所展示的,本发明的一个实施例包括用于提供对触摸交互和触觉反馈的逼真建模的物理引擎1901。这可以通过附加的用户跟踪装置1953来实现,所述用户跟踪装置可以包括例如使用手动控制器的触摸交互性、位置跟踪和触觉。物理引擎1901的一个实施例检测手动控制器何时与虚拟对象进行交互并使得图形引擎1301至1302和/或vr应用1310能够提供物理上精确的视觉和触觉响应。物理引擎1901还可以对虚拟世界的物理行为进行建模,以确保所有交互都是精确的并且表现得与现实世界中所预期的一样。
如图20中所展示的,本发明的实施例可以在(多个)图形引擎1501至1502的像素着色级内采用多分辨率着色和/或镜头匹配着色2001。在一个实施例中,多分辨率着色是一种用于虚拟现实的渲染技术,在这种技术中,以更好地匹配经镜头校正图像的像素密度的分辨率来对图像的每一部分进行渲染。可以使用能够在单轮次中对多个缩放视口进行渲染的专用gpu电路系统。在一个实施例中,镜头匹配着色利用gpu内的多投影硬件来显著提高像素着色性能。具体地,本实施例渲染到更近似于输出到左/右显示器1551至1552的经镜头校正图像的表面。本实施例避免对将会在图像被输出到hmd1550之前以其他方式被丢弃的许多像素进行渲染。
在一个实施例中,多投影电路系统2002包括同步多投影架构,所述同步多投影架构仅对几何结构渲染一次并且然后将所述几何结构的右眼视图和左眼视图两者同时投影在左/右显示器1551至1552内。这种架构显著地减少了在对几何结构绘制两次(即,一次针对左眼并且一次针对右眼)的传统虚拟现实应用中所需的处理资源。因此,有效地加倍了虚拟现实应用的几何复杂性。
e.基于服务器的vr实施例
本发明的一个实施例包括分布式虚拟现实(vr)架构,在所述架构中,高功率服务器或“计算集群”通过网络耦合到vr渲染节点。在一个实施例中,计算集群使用例如视线追踪图形流水线来执行所有图形处理,所述视线追踪图形流水线生成图像帧、压缩图像帧、并且然后将经压缩图像帧传输到渲染节点以便进行解压缩和显示。在一个实施例中,计算集群使用诸如视线追踪等全局照明技术来执行图形应用并生成样本。其然后通过网络将样本流送到渲染节点。在一个实施例中,计算集群基于由渲染节点提供的预期视点来确定要生成/流送的样本,所述渲染节点具有用于执行光场渲染的gpu并且耦合到诸如头戴式显示器(hmd)等vr显示器。计算集群持续生成样本流,所述样本流被存储在渲染节点上的缓冲器内。渲染节点的gpu消耗来自所述缓冲器的样本来对vr显示器的光场进行渲染。
图21展示了通过网络2120通信地耦合到渲染节点2160的示例性计算集群2100。在一个实施例中,计算集群2100包括高性能图形处理资源(例如,gpu、cpu、存储器、执行单元等),用于执行全局照明/视线追踪操作以生成样本,所述样本然后被渲染节点2160用于在虚拟现实设备2150(诸如hmd)上执行光场渲染。具体地,在所展示的实施例中,计算集群2100包括用于响应于虚拟现实应用2104而执行全局照明/视线追踪操作的全局照明/视线追踪电路系统和/或逻辑2105(在下文中被称为“gi模块2105”)。由gi模块2105生成样本流,所述样本流然后可以被滤波/压缩模块2110滤波和/或压缩。然后,可以通过网络2120将经滤波/经压缩样本经由网络接口流送到渲染节点2160,所述网络可以是任何形式的数据通信网络(例如,诸如互联网等公用网络或私有局域网或广域网、或不同网络类型的组合)。
如果样本在传输之前被压缩,则在将它们存储在样本缓冲器2131中之前在渲染节点2160上由解压缩模块2130对其进行解压缩。渲染节点2160上的gpu2165消耗来自样本缓冲器2131的样本来对显示在vr显示器2150上的图像帧的光场进行渲染。具体地,在一个实施例中,样本插入逻辑2135将样本异步地插入到由光场渲染逻辑2140渲染的光场中。
如图21中所展示的,在一个实施例中,视点分析和处理逻辑2145从vr设备2150接收对用户当前视点的指示,并且(可能结合之前存储的视点数据)确定其向渲染节点2160上的gpu2165及向计算集群2100两者提供的“预期”视点。如本文所使用的,“视点”是指用户的凝视在虚拟现实环境内的取向(例如,用户正看着和/或注视的方向)。vr设备2150可以使用各种传感器来确定用户的视点,所述传感器包括例如用于确定每个图像帧内用户眼睛所注视的位置的眼睛跟踪传感器、以及诸如用于确定用户头部/身体的取向的加速度计等运动传感器。可以使用各种其他/附加传感器来确定当前视点,同时仍然符合本发明的基本原理。
视点分析和处理逻辑2145基于当前视点与之前视点(例如,根据之前帧所确定的)的组合来确定预期视点。例如,如果在过去的n帧内用户的视点一直在向右方向上移动,则预期视点可以是在当前视点的右侧(即,由于可以预期视点的变化在同一方向上继续)。可以基于视点在过去的帧内改变的速度来计算变化量。如此,gi模块2105可以基于用户的视点可能在同一方向上继续移动的预期来生成样本。因此,所述模块将根据此视点以及此视点周围的视点生成样本以便覆盖图像帧的各部分(即,以确保在视点不在同一方向上线性继续的情况下所述样本是可用的)。以类似的方式,gpu2165可以基于预期视点从样本缓冲器2131中检索样本,即读取样本以覆盖预期视点以及预期视点周围的样本。
在一个实施例中,计算集群2100被实施为基于云的虚拟化图形处理服务,其具有根据需要被动态地分配给诸如渲染节点2160等客户端的图形资源阵列。虽然在图21中仅示出了单个渲染节点2160,但是许多其他渲染节点可以同时连接到计算集群2100,所述计算集群可以根据需要来分配图形处理资源以支持每个个别vr实施。在一个实施例中,计算集群支持其中向每个请求客户端分配虚拟机的虚拟化图形处理环境。然后,可以基于客户端的处理需求来向虚拟机分配图形处理资源。例如,对于高性能应用(诸如,vr),可以向客户端分配一个或多个完整gpu,而对于较低性能应用,则可以向客户端分配gpu的一小部分。然而,应当注意的是,本发明的基本原则不限于任何特定的计算集群器架构。
图22中展示了根据一个实施例的方法。所述方法可以在以上所述的系统架构的上下文中实施,但不限于任何特定的系统架构。
在2200处,计算集群从渲染节点接收对预期视点的指示,并且在2201处,基于所述预期视点生成样本。如所提及的,可以在预期视点周围的指定区中生成样本,以解释用户头部/眼睛的非预期运动。在2202处,计算集群通过网络(例如,互联网)将样本流送到渲染节点中的样本缓冲器。在2203处,渲染节点从样本缓冲器中读取样本(例如,基于视点或预期视点),并将所述样本插入到光场中。在2204处,渲染节点gpu使用所述样本来对光场进行渲染。在2205处,渲染节点接收当前视点,计算预期视点,并将预期视点传输到计算集群。
本文所描述的本发明实施例可以用于实施诸如视线追踪架构等用于虚拟现实的实时全局照明架构。因为是在计算集群2200上执行大量计算,所以渲染节点2260不需要执行视线追踪/全局照明可能以其他方式所需的大量处理资源。相反,使用这些技术,渲染节点的gpu2265仅需要足够的功率以使用样本缓冲器2231中所存储的预先计算样本来执行光场渲染。
f.动态可调式vr头戴式显示设备
在本发明的一个实施例中,线性致动器耦合在镜头与虚拟现实设备的视频显示器(诸如,头戴式显示器(hmd))之间。线性致动器用于更改显示器表面与镜头之间的距离,由此调整聚焦距离,从而允许软件控制焦距。在一个实施例中,使用眼睛跟踪技术来确定期望的聚焦距离。用于测量用户眼睛的焦点的跟踪装置可以集成到hmd中。如果对双眼进行跟踪,则计算会聚距离并将其用作期望聚焦距离。如果仅对一只眼睛进行跟踪,则在凝视方向上追踪视线进入虚拟场景,以确定用户正看着的表面。然后,将表面距离用作期望聚焦距离。
图23展示了具有线性致动器2301的hmd2303的示例性实施例,所述线性致动器耦合到hmd显示器2302中的镜头2304以基于期望聚焦距离来调整镜头2304的位置。在一个实施例中,集成在hmd2303上的眼睛跟踪装置2330检测用户眼睛2300的当前方向/焦点,并且将此信息提供至在图形处理装置2560上执行的虚拟现实(vr)应用2340,hmd通信地耦合到所述图形处理装置。通过举例的方式,图形处理装置2360可以是通过双向通信接口通信地耦合到hmd2303的计算机系统。可替代地,图形处理装置2360可以集成在hmd内。
vr应用2340可以是利用图形处理引擎2350来渲染显示器2302上的图像帧的任何形式的虚拟现实应用。在一个实施例中,图形处理引擎包括用于响应于用户输入而执行由vr应用2340生成的图形命令的图形处理单元(gpu)。所述用户输入可以包括响应于用户的运动而收集的运动数据,以及经由游戏控制器、键盘、鼠标或任何其他形式的输入装置提供的输入。
在一个实施例中,vr应用2340使用由眼睛跟踪装置2330提供的用户眼睛的当前方向/焦点来生成期望的聚焦距离。hmd2303上的控制电路2520控制hmd中的线性致动器2301以根据期望聚焦距离来调整镜头2304与显示器2302之间的距离。如所提及的,如果对用户的双眼进行跟踪,则计算会聚距离并将其用作期望聚焦距离。如果仅对一只眼睛进行跟踪,则可以在凝视方向上追踪视线进入虚拟场景,以确定用户正看着的表面。然后,将表面距离用作期望聚焦距离。
图24中展示了根据本发明的一个实施例的方法。所述方法可以在以上所述的系统架构的上下文中实施,但不限于任何特定的系统架构。
在2400处,从应用中获得期望聚焦距离。如所提及的,在上述实施方式中,聚焦距离可以由vr应用来确定并被提供至hmd上的控制电路。在2401处,基于期望聚焦距离来确定线性致动器位置。如果致动器当前位于在1402处所确定的期望位置处,则过程返回到2400。如果否,则在2404处,致动器移动到所确定位置。
图25展示了用于动态地调整聚焦距离的方法的一个实施例,其可以由vr应用2540使用来自眼睛跟踪模块2530和/或图形处理引擎2550的信息来实施。然而,应当注意的是,所述方法可以以各种不同的硬件/软件架构来实施。
从眼睛跟踪器2530获得2500中的眼睛跟踪信息。如果在2501处确定对双眼进行跟踪,则在2503处计算会聚点。在一个实施例中,会聚点被计算为离源自每只眼睛的凝视视线的最近距离最小的点。如果在2502处确定对一只眼睛进行跟踪,则在2504处计算交点。在一个实施例中,所述交点是通过对源自被跟踪眼睛的视线进行视线追踪、计算与虚拟环境的交点来计算的。在其他实施例中,可以从gpu2550中读回用于被跟踪眼睛的深度缓冲器,并且与被跟踪眼睛的凝视方向相对应的像素的深度值可以用于计算凝视-场景交点。在一些实施例中,在2505中计算的硬件输入信号可以是至交点的距离。在其他实施例中,所述点可以直接用作硬件输入信号,从而使硬件控制单元执行任何所需处理。在仍其他实施例中,可以计算一个或多个致动器位置并将其用作硬件输入信号。所述硬件输入信号被传输到硬件控制单元2520。在一些实施例中,此传输使用usb协议,但不限于任何特定通信协议。
g.时间扭曲实施方式
时间扭曲是一种用于改善当前虚拟现实(vr)系统的性能的技术。根据这种技术,根据用户头部和/或眼睛的当前取向(即,如从头戴式显示器(hmd)上的眼睛跟踪装置和/或其他传感器中所读取的,用于检测用户头部的运动)来渲染每个图像帧。就在显示下一个图像帧之前,再次捕获传感器数据并用其来变换场景以适于最近的传感器数据(即,“扭曲”当前图像帧)。通过利用已经生成的深度图(即,z缓冲器),时间扭曲可以以相对较低的计算需求来移动3d空间中的对象。
本发明的一个实施例使用时间扭曲技术来对先前渲染的图像帧的一部分进行扭曲,并将结果与被部分渲染的当前帧进行组合。例如,当前渲染的帧可以具有已经由于传输错误或其他数据处理错误而丢失或损坏的数据区。类似地,当到时间要显示下一图像帧时,图形渲染流水线可能仅能够渲染所述图像帧的一部分(例如,在给定vr系统的所需或指定帧速率的情况下)。在本发明的一个实施例中,在当前图像帧的一部分尚未被渲染和/或已经丢失/损坏时,从之前图像帧中读取相应的部分,然后根据当前传感器数据对所述部分进行扭曲。然后将之前图像帧的被扭曲部分与当前图像帧的被正确渲染的部分相组合并显示在vr显示器上。
将关于图26来描述一个实施例,此图展示了通信地耦合到头戴式显示器(hmd)2650的图形处理引擎2600。执行vr应用2610,从而生成有待由图形处理引擎2600执行的图形数据和图形命令。图形处理引擎2600可以包括一个或多个图形处理单元(gpu),所述gpu包括用于执行图形命令并对有待在hmd2650上显示的图像帧进行渲染的图形流水线。具体地,hmd可以包括用于显示用户左眼图像的左显示器、以及用于显示用户右眼图像的右显示器。为了简单起见,图26中仅示出了单个显示器2640,其可以是左显示器或右显示器。
在操作中,图像渲染模块2605对有待在左显示器和右显示器2640中显示的图像帧进行渲染。在一个实施例中,根据如由hmd2650上所集成的用户/眼睛跟踪模块2630提供的用户头部和/或眼睛的当前取向来对每个图像进行渲染。具体地,hmd可以包括用于跟踪用户头部的当前取向的各种传感器、以及用于跟踪用户眼睛的当前焦点的相机及相关联电路系统/逻辑。在虚拟现实实施方式中,此数据用于从正确的视角(即,基于用户当前凝视的方向和焦点)对左/右图像进行渲染。
虽然为了简单起见在图26中被展示为单个部件,但是可以针对左图像帧和右图像帧使用分开的图像渲染电路系统和逻辑。此外,为了避免模糊本发明的基本原理,未展示各种其他图形流水线级,包括例如顶点着色器、几何着色器和纹理映射器。在一个实施例中所采用的视线追踪架构可以包括视线生成模块、视线遍历模块、相交模块以及着色模块。在任何实施方式中,渲染模块2605基于用户的当前取向/凝视来对左显示器和右显示器2640的图像进行渲染。
在所展示的实施例中,第一帧缓冲器2616正存储有当前在hmd2650的左/右显示器2640内显示的图像帧n-1。在第二帧缓冲器2606内正对有待显示的下一个图像帧(图像帧n)进行渲染。具体地,图像帧的第一部分2615已经被正确地渲染,而第二部分2617尚未被渲染。如所提及的,部分2617可能由于通信错误或其他形式的错误而损坏。可替代地,图像渲染模块2605可能没有足够快地对完整图像进行渲染以满足hmd2650所需的帧速率。
在任一情况下,在一个实施例中,时间扭曲模块2620选择帧缓冲器2616中的图像帧n-1的相应部分2616a,对部分2616a的内容执行时间扭曲操作以生成被扭曲部分2616b,所述被扭曲部分然后与图像2615的被渲染部分相组合以得出右/左显示器2640上的最终图像。具体地,时间扭曲模块2620从用户/眼睛跟踪模块2630中读取传感器数据,以对之前图像的部分2616a进行变换以适于最近的传感器数据。此变换是由时间扭曲模块使用存储在处理引擎的z缓冲器2618中的先前生成的深度图来执行的。此变换以相对较小的计算需求来移动3d空间中的对象,从而产生最近完成的产品而无需对场景进行重新渲染。因此,在大多数情况下,其应该基本上类似于在如果正确地发生渲染的情况下所生成的部分2617。
如图27中所展示的,代替将被扭曲部分2816b直接传递到左/右显示器2840,时间扭曲模块2820的一个实施例将所述图像部分复制到帧缓冲器2806,从所述帧缓冲器中将最终图像(2815+2816b)读取到显示器2840。本发明的基本原理并不限于用于将之前图像帧的被扭曲部分2816b与被渲染帧的部分2815相组合的任何特定技术。
图28中展示了根据本发明的一个实施例的方法。所述方法可以在以上所述的系统架构的上下文中实施,但不限于任何特定的一组处理资源。
在2800处,针对左/右显示器对图像帧n-1进行渲染。在2801处,针对图像帧n开始渲染,并且在2802处,到时间要显示图像帧n。如果在2803处确定图像帧n不完整,则在2804处,标识图像帧n中的不完整区以及图像帧n-1中的相应区。在2805处,基于由hmd传感器提供的当前坐标来对图像帧n-1中的相应区进行扭曲,并且将扭曲后结果与来自帧n的完整区相组合。在2806处显示所得图像。
如今的时间扭曲算法渲染比所需大得多的图像。然后,当读出每条扫描线时,时间扭曲基于用户的实际头部位置对此图像进行采样。这导致扫描线被“剪切”,从而需要更大的绘制区域。本发明的一个实施例基于头部运动来预测将发生哪种时间扭曲,并且将渲染工作集中到帧的所预测区中。一个实施例利用视线追踪器来对被扭曲图像进行渲染(调整每条扫描线的视图位置和方向)。在一个实施例中,光栅化器使用剪切投影矩阵。可以利用运动数据、加速度数据、以及来自其他传感器的数据来预测用户头部和眼睛的位置和取向。简而言之,能够预测到将在重采样期间发生的剪切效果意味着可以使用更小的过度绘制区,并且因此实现更快/更便宜的渲染。
时间扭曲算法的基本原理是:良好的vr体验要求头部运动与像素显示之间的极低延迟。然而,在头戴式显示器(hmd)中,帧缓冲器不是瞬时填充的,而是逐行扫描的;因此,在快速头部运动期间,到读出给定扫描线时的实际头部方向可能不再与在渲染帧时所使用的相机方向相对应。“时间扭曲”算法通过以下行为解释了这个事实:在每帧开始时对单个较大帧进行渲染,将其发送到vr装置,并使hmd装置在读出扫描线时使用对应头部取向来针对每个像素(或扫描线)对这个大的、易于渲染的帧缓冲器进行采样。实际上,在快速头部运动期间,这意味着从原始帧缓冲器(重)采样的实际像素在此帧缓冲器内被“剪切”。具体地,为了确保所有的剪切样本都落入此原始图像的有效像素,所述原始图像必须显著大于样本的最终数量,这意味着所述原始图像必须花费时间、功率和工作来计算最终将不会被任何样本访问的像素。
然而,如果可以预测hmd将实际访问的可能剪切样本图案,则可以避免一些这种“过度绘制”,以便进行更快和/或更便宜的渲染。在一个实施例中,使用剪切投影矩阵(针对光栅化器)或者使用适当剪切视线生成代码(针对视线追踪器)来对剪切图像进行直接渲染。在另一个实施例中,对完整帧进行渲染(利用常规视图矩阵和完整过度绘制),但是在由所投影剪切指示的感兴趣区中对渲染质量进行调整。例如,在极端情况下,剪切区之外的任何像素都可能完全被印出;在不太极端的设置中,这些像素仍然会被渲染但质量较低(较低的渲染分辨率、较低的抗混叠设置、较便宜的着色器等)。
图29展示了一个实施例,其中,由配备有左/右图像渲染流水线2905的图形处理引擎2900来执行vr应用,所述左/右流水线将渲染图像输出到一个或多个渲染缓冲器2906中。如图29中所展示的,在这些实施例中的第一实施例中(对经剪切的输入图像进行渲染),预测逻辑2921基于用户眼睛的预测运动来生成剪切投影矩阵2935。剪切矩阵2935被传递到包括剪切补偿逻辑2940的hmd2950,所述剪切补偿逻辑通过从时间扭曲算法2920所需的实际剪切中减去预剪切来解释此预剪切。然后,结果显示在hmd的左/右显示器2945上。在第二实施例中(改变剪切区中的渲染质量),这是不需要的。
为了让所述方法起作用,所需要的是适当的运动矢量和加速度矢量,用于确定将由hmd读出第一条和最后一条扫描线时的相机位置。在使用单个剪切矩阵的情况下,然后我们可以计算覆盖这整个时间间隔的共享投影矩阵(使用单个固定相机原点);在使用视线追踪器的情况下,我们实际上可以为每条扫描线单独地计算眼睛位置和相机取向两者,即使每条扫描线具有不同的相机原点。
当前的增强现实(ar)系统针对“真实”图像以及一个或多个“虚拟”图像来渲染单独的图像流。可以经由头戴式显示器(hmd)上所包括的相机或光学镜头来捕获真实图像,同时虚拟图像由3d图形流水线来渲染并且与真实图像相组合以产生“增强的”现实。
h.利用控制表面来组合虚拟与现实内容的设备和方法
为了减少渲染虚拟图像所需的图形处理资源,使用在元数据中所指定的控制表面来指示基于每个图块显示(或不显示)虚拟内容的地方。例如,元数据可以将图块标记为完全透明,在这种情况下,不在显示器上取出和/或处理与这些图块相关联的图形数据以节省处理资源,从而导致更低带宽和更高效渲染。ar系统的一个实施例还可以使用控制表面来组合虚拟与真实内容。例如,可以指定α值用于指示每个虚拟图块的透明度水平。另外的实施例可以利用光场压缩,并且可以使用高带宽存储器来加载/存储虚拟图形数据。
图30展示了本发明的一个实施例的基本原理。具体地,ar系统3010包括用于根据一组元数据3015来对一个或多个虚拟图像3002的图块进行处理的图形渲染引擎。在一个实施例中,元数据3015限定控制表面,所述控制表面指定各个虚拟图像3005至3007的虚拟图块是否将与经由集成在头戴式显示器(hmd)上的相机或镜头捕获的真实图像3001的图块相组合。在所展示的示例中,真实图像3001是房间,并且虚拟图像3002包括悬挂的植物3005、枝形吊灯3006和沙发3007。本示例的元数据3015指定枝形吊灯3006和沙发3007的图块将由图形处理引擎来渲染并与真实图像组合,从而产生最终ar图像3003。然而,如所展示的,元数据还指定不渲染悬挂植物3005的图像图块(例如,悬挂植物是完全透明的)。在一种实施方式中,元数据包括每虚拟图块一个位用于指示图块是否要在最终图像中显示(例如,1=显示,0=不显示)。在另一种实施方式中,元数据可以包括每图块两个或更多个位用于指示是否要显示图块、以及是否将使用α值来指定每个虚拟图块的透明度水平。例如,在两个位的情况下,值00可以表明虚拟图块完全透明(不显示);值01可以表明虚拟图块完全不透明(在相应的图像图块上显示);值10可以表明虚拟图块将根据特定的α值与相应的真实图块混合;并且值11可以表明虚拟图块被压缩并且将被混合。在其他实施例中,在元数据内包括附加位用于实现对虚拟图块的更精确控制以及将虚拟图块与真实图块组合的方式(例如,混合的水平/类型、压缩水平等)。
图31展示了示例性图形处理引擎3120,其包括用于根据元数据3130来取出虚拟图像数据3124的图像渲染流水线3125。在一个实施例中,图像渲染流水线3125仅取出将在hmd3150的(多个)显示器3152上可见的虚拟图像图块的虚拟图像数据3124(即,如由元数据3130指定的那样不完全透明或被遮挡)。图像渲染流水线3125将虚拟图像图块与经由hmd3150上的相机和/或镜头3154捕获的真实图像图块相组合,根据指定的α值混合这些图块,并将所得图像帧存储在帧缓冲器3135内。在一个实施例中,集成在hmd3150上的用户/眼睛跟踪装置3156跟踪用户和/或用户眼睛的取向和运动。图像渲染流水线3125根据此数据来调整虚拟3d图像(例如,使得虚拟图像具有相对于真实图像的正确取向)。一旦组合了真实图像与虚拟图像来渲染帧缓冲器3135内的最终图像,就将所述最终图像显示在hmd上的左或右显示器3152内。虽然为了简单起见仅示出了单个显示器3152,但是将理解的是,本发明的基本原理可以用于具有单独的左显示器和右显示器(除了左图形处理引擎和右图形处理引擎3120之外)的立体hmd3150。
使用限定控制表面的元数据3130来指定将不被显示的虚拟图像图块导致了相对于当前ar系统的显著提高的性能。具体地,使用这些技术,不会从存储器中取出将不在最终图像中显示的虚拟图像图块,从而节省存储器带宽。此外,使用这些图块将不会执行其他图形处理操作,从而进一步提高性能。
图32中展示了根据本发明的一个实施例的方法。所述方法可以在以上所述的系统架构的上下文中实施,但不限于任何特定的一组处理资源。
在3200处,从hmd上的相机和/或一组镜头处捕获真实图像数据。在3201处,读取控制表面元数据以确定需要取出(例如,从存储器子系统加载)的虚拟图块。例如,仅可以取出将被显示的那些虚拟图块。在3202处,取出虚拟图块,并且在3203处,将虚拟图块与真实图像图块组合以渲染增强现实图像。如所提及的,部分地透明的虚拟图块可以与来自真实图像的相应图块混合。
在实施例中,术语“引擎”或“模块”或“逻辑”可以指以下各项、是以下各项的一部分或者包括以下各项:执行一个或多个软件或固件程序的应用专用集成电路(asic)、电子电路、处理器(共享处理器、专用处理器或组处理器)和/或存储器(共享存储器、专用存储器或组存储器)、组合逻辑电路、和/或提供所描述功能的其他合适部件。在实施例中,引擎或模块可以以固件、硬件、软件、或者固件、硬件和软件的任何组合来实施。
i.非平衡vr渲染
如果用户具有一只优势眼和一只非优势眼,则可以将较低质量的视频递送给非优势眼。实际上,即使用户不具有优势眼,相同的原理也可以适用,因为人类视觉系统会将呈现给左眼的图像与呈现给右眼的图像混合在一起成为具有深度的单个感知图像。所以,在下文中,我们将使用术语低质量(low-quality,le)眼睛和高质量眼睛(high-quality,he)而不是优势和非优势。
使用以下各项的组合来将低质量渲染成le:(1)较低的le分辨率,然后按比例放大;(2)较粗的le像素着色;(3)每隔一帧的le时间扭曲,而无需另外渲染;(4)降低的le环境遮挡的质量;(5)执行不同的着色器代码(细节的着色器水平),例如,较低的le着色质量;(6)较低的le帧速率。
当前的虚拟现实(vr)系统使用同类的一组执行资源来对用户的左眼和右眼的单独图像流进行渲染。例如,可以将一个gpu分配给用户的左眼,并且可以将完全相同的gpu分配给用户的右眼。
本发明的一个实施例利用以下事实:用户可以有一只眼睛比另一只眼睛更优势,并且可以相应地分配图形处理资源。实际上,即使用户不具有优势眼,相同的原理也可以适用,因为人类视觉系统会将呈现给左眼的图像与呈现给右眼的图像混合在一起成为具有深度的单个感知图像。所以,在下文中,我们将使用术语低质量(low-quality,le)眼睛和高质量眼睛(high-quality,he)而不是优势和非优势。这简单地意味着我们可以针对le渲染较低质量图像,并且针对he渲染较高质量图像。例如,如果gpu具有不同的性能水平,则较低性能的gpu将用于le。这可以推广到基于哪个是优势的或者选择以较低质量渲染哪只眼睛而选择不同组的gpu/cpu硬件资源来渲染左眼/右眼。
将关于图33来描述一个实施例,此图展示了通信地耦合到头戴式显示器(hmd)3350的图形处理系统3300。执行vr应用3310,以生成有待由图形处理系统3300来执行的图形命令和图形数据。图形处理系统3300可以包括一个或多个图形处理单元(gpu)3301至3302,每个图形处理单元具有单独的图形流水线用于执行图形命令并对左显示器3340(用于显示用户左眼的图像)和右显示器3341(用于显示用户右眼的图像)上的图像帧进行渲染。
可以采用各种技术来确定用户左眼与右眼之间的视差水平。例如,可以提示用户手动输入与用户视力相关的数据(例如,近视或远视的程度、散光程度等)。在一个实施例中,hmd3350上的眼睛跟踪/评估模块3353确定用户的优势眼并相应地配置gpu3301至3302。例如,可以在执行vr应用3310之前对用户进行眼睛测试,可能是使用眼睛跟踪/评估模块3353的相机来自动识别用户的优势眼和非优势眼以及可能地左眼/右眼之间的视差水平。然后可以存储眼睛测试的结果并将其与用户的账户相关联。可替代地,由于人类视觉系统能够混合左眼与右眼的图像,因此人们可以随机选择质量较低的眼睛。
无论如何确定用户的视力,在一个实施例中,发送配置信号3360以将较高性能的gpu3301与用户的高质量眼睛(在所展示示例中的右眼)相关联并且将较低性能的gpu3302与用户的低质量眼睛(示例中的左眼)相关联。因此,可以在由用户的优势眼或he观看的显示器3351上实现更高质量的图像(例如,更高的分辨率、帧速率等),从而提高最终用户体验。
在一个实施例中,代替将整个gpu分配给每只眼睛,而是可以根据用户的视力来分配各个执行资源。图34例如展示了这样一个实施例,在其中,第一组(较高性能)执行资源3401被分配用于对用户he的图像帧进行渲染,而第二组(较低性能)资源3402被分配用于对用户le的图像帧进行渲染。执行资源组3401至3402可以是单个gpu上的或跨多个gpu分布的资源。
如图35中所展示的,可以在图形流水线的各级分配不同组的执行资源3501a至3506a、3501b至3506b,包括:从存储器中读取索引和顶点数据的输入汇集器(ia)3501a-b、以及顶点着色器(vs)3502a-b;顶点着色器级3502a-b,其对每个顶点执行着色操作(例如,将虚拟空间中的每个顶点的3d位置变换成其出现在屏幕上的2d坐标)并生成图元形式(例如,三角形)的结果;几何着色器(gs)级3503a-b,其将整个图元作为输入,可能具有邻接信息(例如,每个三角形的三个顶点);光栅化级3504a-b,其对由几何着色器提供的图元进行光栅化;以及像素着色器(ps)级3505a-b,其对在被显示在hmd3550上之前逐帧存储在帧缓冲器3506a-b内的各个像素中的每个像素执行着色操作。例如,在一个实施例中,可以将不同数量的执行单元分配给右显示器和左显示器3551至3552,用于执行光栅化和像素着色操作(例如,将更多的执行单元分配给优势眼)。
另外,在一个实施例中,可以在每个流水线级应用不同的图形处理和/或视频处理技术,用于向le提供较低质量的视频。可以使用以下组合来将较低质量的图形或视频渲染到非优势眼或le:(1)较低分辨率(通过按比例放大);(2)较粗的像素着色;(3)对le周期性地(例如,每隔一帧)使用时间扭曲操作,而无需另外渲染;(4)降低的环境遮挡质量;(5)执行不同的着色器代码;以及(6)较低的帧速率。当然,可以使用导致差异化图形/视频质量的任何技术或技术组合来实施本发明的基本原理。
一个实施例使用单个gpu。想法是基本上相同的,区别在于首先分配整个gpu以将图像渲染到le,并且然后对其进行分配以渲染he(或反之亦然)。在对le和he进行渲染时也可能存在一些重叠。例如,在对le的渲染结束期间,如果存在可用资源,则人们可以并行地开始渲染he。还可以将le的一些渲染与he的一些渲染交织。例如,对le然后是he渲染仅深度轮次、或者同时进行两者可能是有益的。同样的想法也适用于视线追踪。
虽然在图35中展示了基于光栅化的流水线,但是本发明的基本原理不限于此。例如,图36展示了在具有各种流水线级3601a至3605a、3601a至3605a的基于视线追踪的流水线内实施的本发明的一个实施例,在其中,可以根据用户的优势/非优势眼或le/he来分配资源。所展示的各个级包括生成视线以供进一步处理的视线生成模块3601a-b。例如,一个实施例对每个图像图块执行广度优先的视线追踪,其中,一个图块表示较小的固定大小的矩形区。在广度优先实施方式的一个实施例中,针对图像图块上的每次迭代生成每个像素一条视线。视线遍历模块3602a-b针对包围体层次(bvh)或其他加速度数据结构来遍历每条视线。一个或多个相交模块3603a-b对一个或多个三角形或其他图元测试视线,并且最后,遍历单元和相交单元必须找到每条视线所相交的最接近图元。然后,一个或多个着色器单元3604a-b对在被显示在hmd3550上之前逐帧存储在帧缓冲器3605a-b内的所得像素执行着色操作。可以根据用户的视力来在每个流水线级分配各种不同类型的硬件和软件(例如,用于执行着色操作的不同数量的执行单元)。
图37中展示了根据本发明的一个实施例的方法。所述方法可以在本文所述的系统架构的上下文中实施,但不限于任何特定的系统架构。
在3700处,评估用户的眼睛以识别哪只(如果有的话)眼睛是优势的(例如,通过执行眼睛测试并监测用户的响应)。如所提及的,代替执行评估,用户可以手动地识别哪只眼睛是优势的。可替代地,人们仅可以选择一只眼睛为le,而另一只眼睛为he。
在3701处,基于对用户左眼和右眼的评估来分配图形处理单元(gpu)和/或图形处理资源。例如,可以在图形处理流水线的一个或多个级上分配更多数量的硬件资源。另外,可以根据用户的视力在每级采用不同的图形/视频处理技术(例如,可以针对用户的非优势眼更频繁地使用时间扭曲)。
在3702处,使用所分配的gpu和/或图形处理资源来渲染左/右显示器的图像帧。
j.多平面传输
在将显示图像传输到头戴式显示器(hmd)之前,已经在主机系统上执行了针对虚拟现实(vr)的时间扭曲。此过程需要抢占主机系统的gpu工作负载,并导致运动时间延迟。相反,主机系统可以将非扭曲图像传输到hmd,并使hmd执行时间扭曲。然而,非扭曲图像由比相应的扭曲图像显著更多的数据组成,因此显示链路带宽需求将显著增加。
本发明的实施例包括用于将具有类似带宽需求的非扭曲图像传输到扭曲图像的技术,使得能够以非常低的运动时间延迟进行基于hmd的扭曲。在一个实施例中,主机系统渲染一组平面投影,所述一组平面投影一起覆盖所显示的立体角。与渲染单个投影相比,渲染多个投影而不是一个投影需要2倍到3倍以下的像素来计算和传递。为了显示新帧,整组平面投影被一个投影接着另一个投影地从主机传输到hmd,伴随着与每个投影相关联的一些元数据。然后,就在显示图像之前,hmd基于位置数据的最新读取来执行时间扭曲。如果已知平面投影的子组对最终图像没有贡献,则可以从传输中省略这些子组,从而进一步降低带宽需求。
主机系统可以包括cpu、gpu、存储器和软件(包括操作系统、用户应用程序、驱动器、库、中间件、固件),并且可选地跟踪诸如相机等外围设备,统称为“主机”。在主机上执行的处理可以在任何这些硬件资源上进行,如由任何软件部件所指导的。虚拟现实头戴式显示设备可以包括若干各种传感器、处理单元、显示器、存储器和软件,统称为“hmd”。
在图38a中所展示的一个实施例中,在3800处,主机通过读取最新的可用头部跟踪数据来开始帧处理,并且可选地将此信息外推到预期的帧显示时间。在3801处,然后,主机估计在所述帧将对用户可见时显示的视野将是什么。可以填充或不填充视野估计以适应估计不准确性。
在3802处,然后,主机对一起对向整个估计视野的一个或多个平面投影进行配置。此外,主机可以确定平面投影的子组可能在估计视野之外并且将这些子组标记为不可见。如3803处所指示的,标记为不可见的这些区被称为“掩蔽(masked)”。
在3804处,然后,主机渲染所有这些平面投影,可能省略掩蔽区。在3805处,然后,渲染的投影被传输到hmd,一次一个。渲染的投影包括投影变换、每个(非掩蔽的)像素的颜色、以及可能的每个(非掩蔽的)像素的深度、以及关于哪些像素被掩蔽的可能信息。重复此过程直到应用在3806处终止。
图38b展示了vr图形系统3810的一个实施例,在所述vr图形系统上,平面投影渲染器3820响应于vr应用3815而渲染一起覆盖所显示的立体角的一组平面投影。如所提及的,所述平面投影渲染器对一起对向整个估计视野的一个或多个平面投影进行配置。为了显示新帧,整组平面投影被从平面投影渲染器3820传输到hmd3850上的右显示缓冲器和左显示缓冲器3851至3852。在一个实施例中,一个投影接着另一个投影地被传输,伴随着与每个投影相关联的一些元数据。然后,就在显示图像之前,hmd3850上的时间扭曲模块3853基于由眼睛/用户跟踪传感器3854提供的位置数据的最新读取来执行时间扭曲。如所提及的,如果已知平面投影的子组对最终图像没有贡献,则可以从传输中省略这些子组,从而进一步降低带宽需求。
图39展示了根据本发明的一个实施例的在hmd上执行的方法。对于每个所显示帧,在3900处,hmd通过读取最新的跟踪数据而开始,并且可选地此该信息外推到预期的帧显示时间。在3901处,然后,hmd定位已经完成来自主机的传输的最新一组投影。即使后续的一组投影在所述帧处理期间完成传输,此最新的一组投影也将用于帧处理的剩余部分。
对于每个显示像素,在3902处,在显示像素将被点亮时,hmd确定哪个投影平面以及所述投影平面的哪个像素将在此显示像素处可见。在3903处,最终将使用相应投影平面的确定像素的颜色来点亮显示像素。重复此过程直到hmd在3806处关闭。
确定哪个投影平面的哪个像素将可见可以使用或不使用深度信息来校正头部位置估计不准确性。传输的投影变换可以采用3×3矩阵的形式。在其他实施例中,可以使用其他形式,诸如不同的矩阵、或四元数和矢量,以传达投影平面的等效描述。在一些实施例中,关于哪些像素被掩蔽的信息可以没有每帧那么频繁地传递。在这样的实施例中,hmd将假设以相同的方式掩蔽后续帧,直到传输关于被掩蔽像素的新信息。
本发明的实施例提供了许多有益的特征,包括但不限于:将未扭曲图像传输到hmd;在hmd上执行时间扭曲;同时传输所显示的若干投影;传输每个投影的投影信息;以及省略对被掩蔽像素的传输。
j.帧内可变帧速率
虚拟现实需要高帧速率来创造稳定环境的幻觉。在渲染视觉密集型内容时实现高帧速率在计算上要求很高,达到最终用户的硬件通常无法跟上计算需求的程度。当给定帧的渲染时间超过显示刷新周期时,这可能导致丢失帧。这样的丢失帧可能会使最终用户感到刺耳。
在一个实施例中,每两帧仅渲染以用户凝视为中心的帧的一部分,或者如果没有凝视信息可用则直接向前。相反,通过重新投影前一帧来填充未渲染的部分。可以动态地确定可以被渲染的部分帧的范围,使得平均帧时间适于显示刷新周期内。为了使工作负载均匀,可以在偶数帧上渲染一半外围区,并且可以在奇数帧上渲染另一半外围区。
整个过程可以由硬件、软件、或其任何组合执行。在一个实施例中,所述过程由应用执行,或由应用与图形驱动器共同执行。
在一个实施例中,vr应用跟踪在4000处渲染每个帧所需的时间。其还保持在零与一之间的质量分数。如果在4001处确定渲染时间接近或超过时间预算,则在4003处减小质量分数,但是不会低于某个预先指定的质量阈值。如果在4002处确定渲染时间远低于时间预算,则在4004处增大质量分数,但是不会超过一。在一个实施例中,在4001,确定渲染时间是否超过第一指定阈值,并且在4002,确定渲染时间是否低于第二指定阈值。在一个实施例中,如果渲染时间在这两个阈值之间,则不采取动作,并且假设在4005确定应用未被终止,针对下一帧重复所述过程。
通过确定针对所述帧将要精确渲染的区(以下称为“精确区”)而开始对帧的渲染4000。所述精确区由两个子组组成,即(1)感兴趣区、以及(2)大约一半剩余帧(以下称为次要区)。如果凝视信息可用,则感兴趣区可以是以围绕用户凝视为中心的矩形区。如果凝视信息不可用,则可以是图像的中心。虽然这些是最有用的情况,但是其他实施例也是可能的,诸如图像中的区周围的重要对象。在一个实施例中,质量分数指定可以在感兴趣区中包括总帧的多大一部分。因此,质量分数意味着整个图像是感兴趣区的一部分。
在一个实施例中,次要区被确定如下。将未包括在感兴趣区中的帧部分拆分成两个子组。在一些实施例中,此拆分就是帧的左半部分和右半部分。在其他实施例中,根据棋盘状图案来划分帧,在所述图案中,每个图块的大小可以是一个或多个像素。选择这两个子组中的一个作为偶数帧上的次要区,并且选择另一个子组作为奇数帧上的次要区。
然后照常渲染精确区。可以采用诸如模板印刷缓冲器等标准机构来排除不是精确区的一部分的帧部分,以下称为“不精确区”。在一些实施例中,如果硬件支持空间变化的质量设置,诸如有损帧缓冲压缩算法,则次要区可以被配置用于使用比感兴趣区更低的质量设置。
最后,在一个实施例中,通过重新投影前一帧的内容来填充不精确区。在一些实施例中,可以基于用户的头部运动来进行重新投影。在其他实施例中,可以采用头部运动与每像素速度信息的组合。在仍其他实施例中,还可以采用每像素深度信息。
图41展示了一组示例性区,其中,黑色指示感兴趣区,深灰色指示次要区,而浅灰色指示不精确区。在一个实施例中,每隔一帧,灰色棋盘状图案被反转。
图42展示了具有帧内可变帧速率渲染器4220的虚拟现实图形系统4210,所述渲染器仅对每第n帧的以用户注视为中心的帧部分进行渲染(或者如果没有凝视信息可用则直接向前)。如所展示的,可以根据眼睛/用户跟踪传感器4254确定用户的凝视。在一个实施例中,通过重新投影前一帧来替代地填充未在(多个)hmd显示器4251上渲染的帧的部分。可以动态地确定可以被渲染的部分帧的范围,使得平均帧时间适于显示刷新周期内。如所提及的,为了使工作负载均匀,可以在偶数帧上渲染一半外围区,并且可以在奇数帧上渲染另一半外围区。
整个过程可以由硬件、软件、或其任何组合执行。在一个实施例中,所述过程由应用执行,或由应用与图形驱动器共同执行。
在一个实施例中,vr应用跟踪在4000处渲染每个帧所需的时间。其还保持在零与一之间的质量分数。如果在4001处确定渲染时间接近或超过时间预算,则在4003处减小质量分数,但是不会低于某个预先指定的质量阈值。如果在4002处确定渲染时间远低于时间预算,则在4004处增大质量分数,但是不会超过一。在一个实施例中,在4001,确定渲染时间是否超过第一指定阈值,并且在4002,确定渲染时间是否低于第二指定阈值。在一个实施例中,如果渲染时间在这两个阈值之间,则不采取动作,并且假设在4005确定应用未被终止,针对下一帧重复所述过程。
在本申请中使用的术语“模块”、“逻辑”和“单元”可以指用于执行指定功能的电路。在一些实施例中,所指定的功能可以通过电路结合软件来执行,诸如通过由通用处理器执行的软件。
本发明的实施例可以包括以上已经描述的各步骤。这些步骤可以被具体化为机器可执行指令,所述机器可执行指令可以用于使通用或专用处理器执行这些步骤。可替代地,这些步骤可以由包含用于执行这些步骤的硬接线逻辑的特定硬件部件来执行,或者由程序化计算机部件和自定义硬件部件的任意组合来执行。
如在此描述的,指令可以指硬件(诸如专用集成电路(asic))的特定配置,所述专用集成电路被配置用于执行某些操作或者具有预定功能或存储在被具体化为非暂态计算机可读介质的存储器中的软件指令。因此,可以使用在一个或多个电子装置(例如,端站、网络元件等)上存储并执行的代码和数据来实施附图中示出的技术。这样的电子装置使用计算机机器可读介质(比如,非暂态计算机机器可读存储介质(例如,磁盘;光盘;随机存取存储器;只读存储器;闪存装置;相变存储器)以及暂态计算机机器可读通信介质(例如,电、光、声或其他形式的传播信号—比如载波、红外信号、数字信号等))来(在内部和/或通过网络与其他电子装置)存储和传达代码和数据。
此外,这样的电子装置典型地包括耦合到一个或多个其他部件(比如,一个或多个存储装置(非暂态机器可读存储介质)、用户输入/输出装置(例如键盘、触摸屏和/或显示器)、以及网络连接件)的一组一个或多个处理器。所述一组处理器和其他部件的耦合通常通过一个或多个总线和桥接器(也被称为总线控制器)进行。承载网络业务量的存储装置和信号分别表示一个或多个机器可读存储介质和机器可读通信介质。因此,给定电子装置的存储装置典型地存储用于在该电子装置的所述一组一个或多个处理器上执行的代码和/或数据。当然,可以使用软件、固件、和/或硬件的不同组合来实施本发明的实施例的一个或多个部分。贯穿本详细说明,出于解释的目的,阐述了大量的具体细节以便提供对本发明的透彻理解。然而,对于本领域的技术人员而言将明显的是,可以在没有这些具体细节中的一些的情况下实践本发明。在某些实例中,未详细描述公知结构和功能以避免模糊本发明的主题。因此,本发明的范围和精神应根据以下权利要求来判定。
- 还没有人留言评论。精彩留言会获得点赞!