利用事件摄像机同时进行定位和映射的制作方法
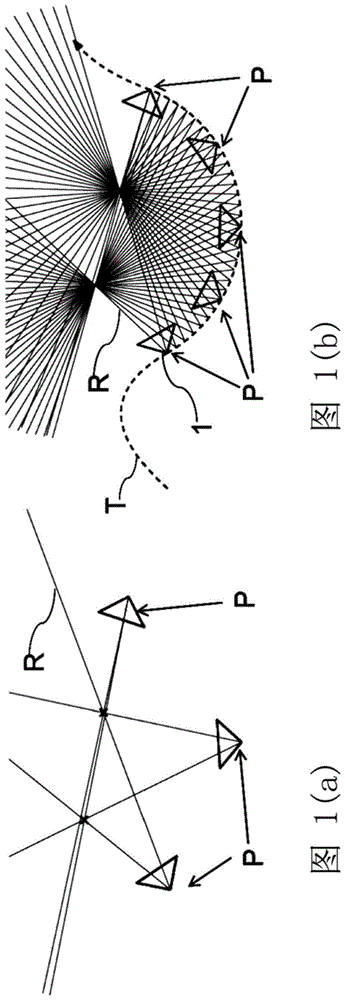
本发明涉及用于场景的3d重建(reconstruct,重现)的方法,特别是算法,而且涉及用于执行这种方法/算法的计算机程序和设备。此外,本发明涉及通过将由事件摄像机获得的事件图像与模板图像进行配准来关于现有的半密集3d映射图(map,贴图、映像)定位事件摄像机的方法。传统的多视图立体算法/方法的目标是由从已知的摄像机视点拍摄的图像集合来重建完整的三维(3d)对象模型。就此而言,本发明的根本问题是提供一种允许以简单且有效的方式执行场景的3d重建的方法。该问题通过具有权利要求1的特征的方法解决。本发明的其他方面涉及对应的计算机程序和对应的设备。根据本发明的方法的优选实施方式在对应的从属权利要求中陈述并在下面描述。根据权利要求1,公开了一种用于场景的3d重建的方法,其中,事件摄像机沿着要在三维(3d)中重建的场景在一轨迹上移动,其中,事件摄像机包括多个独立像元(pixel,像素),该多个独立像元被配置为仅在事件(ek)发生所在的时间(tk)处在场景中存在亮度变化的情况下输出该事件,其中,每个事件包括其发生所在的时间(tk)、检测到亮度变化的相应像元的地址(例如,坐标)(xk,yk)以及指示亮度变化的符号的极性值(pk),其中,由事件摄像机沿着所述轨迹生成的多个连续事件根据事件摄像机的视点被反投射(project,投影)为通过离散化体积(也称为视差空间图像或dsi)的观察射线,该离散化体积定位在虚拟事件摄像机的参考视点处,该参考视点选自与所述多个事件相关联的那些事件摄像机视点,其中,所述离散化体积包括体元(voxel,体素),并且其中,确定与离散化体积相关联的得分函数该得分函数f(x)是穿过具有中心x的相应体元的反投射观察射线的数量,并且其中,所述得分函数f(x)(其也表示为射线密度函数)用于确定在相应体元中是否存在场景的3d重建的3d点。与根据一组已知视点解决估计密集3d结构的问题的传统mvs方法不同,根据本发明的方法——也称为用于基于事件的多视图立体声的emvs——根据事件摄像机特别是根据仅单个事件摄像机利用已知轨迹来估计半密集3d结构。特别地,根据本发明的方法考究地利用事件摄像机的两个固有属性:(i)其响应场景边缘的能力,这自然地提供半密集几何信息而无需任何预处理操作,以及(ii)其随着摄像机移动提供连续测量的事实。尽管其简单(可以以几行代码来实现它),但是根据本发明的方法/算法能够产生准确的半密集深度映射图。特别地,根据本发明的方法在计算上非常有效并且在cpu上实时运行。在本发明的框架中,事件摄像机是包括多个独立光敏像元的传感器,该多个独立光敏像元被配置为仅在事件发生时场景中存在亮度变化的情况下发送称为“事件”的信息。特别地,每个事件包括其发生所在的时间、检测到亮度变化的相应像元的地址(例如坐标)以及指示亮度变化的符号的极性值。特别地,事件摄像机的每个像元仅在下述情况下输出事件:自来自相应像元的上一事件起,由于照射在该相应像元上的光引起的相应信号增加大于第一阈值(θon)的量或者减小大于第二阈值(θoff)的量,其中,每个事件携带上述信息,即像元的地址、事件发生所在的时间、极性值,该极性值指示相应时间对比事件是处于所述信号增加大于所述第一阈值(θon)的量时的on事件(例如,+常数(例如+1)的极性值)还是处于所述信号减小大于所述第二阈值(θoff)的量时的off事件(例如,-常数(例如-1)的极性值)。因此,特别地,这种事件摄像机的输出不是强度图像而是微秒分辨率的异步事件流,其中每个事件包括它的时空坐标和亮度变化的符号(即没有强度)。由于事件是由亮度随时间变化引起的,因此事件摄像机在存在相对运动的情况下自然地响应场景中的边缘。事件摄像机相较标准摄像机具有许多优点:延迟为大约微秒、功耗低、以及动态范围高(130db对60db)。这种事件摄像机的示例是davis[1]。这些特性使传感器在下述中是理想的:在所有那些快速响应和高效率是至关重要的应用中,而且在具有广泛照明变化的场景中。此外,由于仅在存在亮度变化的情况下发送信息,因此事件摄像机会消除标准摄像机的所有固有冗余,因此需要非常低的数据速率(千字节对兆字节)。到目前为止,现有技术尚未解决从单个事件摄像机进行深度估计。所有相关的工作都解决了完全不同的问题,即利用两个或更多个事件摄像机进行场景的3d重建,该两个或更多个事件摄像机刚性附接(即,利用固定基线)并共享公共时钟。这些方法遵循两步法:首先,它们解决图像平面上的事件对应问题,然后对3d点的位置进行三角测量。事件以两种方式匹配:要么对通过随时间累积的事件生成的人工帧使用传统立体方法[6、9],要么利用跨传感器的事件的同时性和时间相关性[2、5、7、8]。然而,特别地,根据本发明的基于事件的方法以两种方式显著地脱离现有技术:(i)考虑单个摄像机,(ii)不需要同时事件观察。从单个事件摄像机进行深度估计更具挑战性,因为不能利用跨多个图像平面的事件之间的时间相关性。尽管如此,本发明证明了单个事件摄像机足以估计深度,而且,与先前基于事件的立体重建方法相反,能够在不解决数据相关联问题的情况下估计深度。根据本发明的优选实施方式,所述离散化体积(dsi)具有大小w×h×nz,其中,w和h是事件摄像机在x和y方向上的像元的数量(即,传感器的大小),并且其中nz是深度平面的数量,并且其中特别地,离散化体积(dsi)适于虚拟事件摄像机在所述参考视点处的视场和透视投射。此外,根据本发明的优选实施方式,当对于与所述参考视点相关联的离散化体积的一体元而言所述得分函数f(x)呈现出局部最大值时,确定/检测到在该体元中存在场景的3d点。换句话说,通过确定离散化体积(dsi)的得分函数的局部最大值来检测所述3d点。此外,根据本发明的实施方式,在两步过程之后检测得分函数f(x)的局部最大值。首先,生成所述参考视点处的密集深度映射图z*(x,y)和相关联的置信度映射图c(x,y),其中z*(x,y)存储沿着与像元(x,y)对应的体元行的最大得分的位置,并且c(x,y)存储所述最大的值,c(x,y):=f(x(x),y(y),z*(x,y))。其次,通过使用所述置信度映射图c(x,y)选择像元(具有深度)的子集,从z*创建半密集深度映射图。对所述置信度映射图c(x,y)进行自适应阈值化产生二元置信度掩模,该二元置信度掩模选择映射图z*中的像元子集的位置,产生半密集深度映射图。具体地,如果c(x,y)>t(x,y),则选择像元(x,y),其中,t(x,y)=c(x,y)*g(x,y)-c,其中,*表示二维(2d)卷积,g是高斯核,以及c是恒定偏移量。特别地,在可缩放设计的推动下,对事件流的多个子集执行该方法,从而在多个参考视点处恢复场景的半密集深度映射图。因此,根据本发明的实施方式,由事件摄像机沿着所述轨迹生成的所述多个连续事件形成由事件摄像机沿着所述轨迹生成的事件流的事件子集,其中,所述流被分成多个相继的事件子集,其中每个子集包含由事件摄像机生成的多个连续事件,其中每个子集的连续事件根据事件摄像机的视点被反投射为通过离散化体积(dsi)的观察射线,该离散化体积定位在与相应子集相关联的虚拟事件摄像机的参考视点(具体地,该参考视点选自相应子集的那些事件摄像机视点)处,其中,所述离散化体积包括体元,并且其中确定与相应离散化体积相关联的得分函数该得分函数f(x)是相应子集穿过相应离散化体积的具有中心x的相应体元(v')的反投射观察射线的数量,并且其中相应得分函数f(x)用于确定在与相应子集相关联的相应离散化体积的相应体元中是否存在场景的3d重建的3d点。具体地,当到前一参考视点的距离超过平均场景深度的一定百分比时,选择新的参考视点,其中,在下一参考视点之前,由事件摄像机生成的现在的多个事件(该多个事件再次形成所述流的子集)用于估计另一对应的半密集深度映射图,该另一对应的半密集深度映射图包含场景的3d重建的3d点。再次,如上所述,使用针对每个参考视点的虚拟事件摄像机中的密集深度映射图z*(x,y)并且通过针对每个参考视点生成相关联的置信度映射图c(x,y):=f(x(x),y(y),z*)来检测相应得分函数f(x)的局部最大值。此外,根据实施方式,使用对所选择的置信像元位置进行作用的中值滤波器来优选地使半密集深度映射图平滑,然后将该半密集深度映射图转换为点云,其中特别地从其处于给定半径内的邻居的数量小于阈值的那些孤立点清理出相应点云,并且其中使用虚拟事件摄像机在相应参考视点处的已知位置将所述点云合并成全局点云,其中,所述全局点云包括场景的3d重建的3d点。此外,根据本发明的实施方式,事件摄像机沿着所述轨迹手动移动。此外,根据本发明的实施方式,事件摄像机借助于移动生成装置沿着所述轨迹移动。特别地,所述移动生成装置由以下之一形成:电机、机动车辆、火车、飞机、机器人、机械臂、自行车。根据本发明的方法的特定应用是特别需要在会使标准摄像机失效的相当高的速度下运行的任何3d扫描过程。例如,目前的列车基础设施检查是利用安装在特殊检查列车上的激光雷达或标准摄像机进行的,与在超过100km/h下运行的标准列车相比,该特殊检查列车的运行速度要慢得多。根据本发明的方法允许将事件摄像机安装在观看轨道的常规列车上或侧面,并且对所有普通列车上的轨道和隧道或其他附近的列车基础设施进行检查。其他可能的应用是利用快速机械臂进行检查。特别地,根据本发明的方法的实施方式,事件摄像机沿着所述轨迹以在下述范围内的速度移动:该速度范围为从0km/h至500km/h、特别是1km/h至500km/h、特别是100km/h至500km/h、特别是150km/h至500km/h、特别是200km/h至500km/h、特别是250km/h至500km/h、特别是300km/h至500km/h、特别是350km/h至500km/h、特别是400km/h至500km/h。根据本发明的另一方面,公开了一种用于场景的3d重建的计算机程序,其中该计算机程序包括用于当在计算机上执行该计算机程序时执行以下步骤的程序代码:-将借助于事件摄像机生成的多个事件根据事件摄像机的视点反投射为通过离散化体积(dsi)的观察射线,该离散化体积定位在虚拟事件摄像机的参考视点处,该参考视点选自与所述多个事件相关联的那些事件摄相机视点,其中所述离散化体积包括体元,以及-确定与离散化体积相关联的得分函数该得分函数f(x)是穿过具有中心x的相应体元的反投射观察射线的数量,以及-使用所述得分函数f(x)来确定在相应体元中是否存在场景的3d重建的3d点。此外,程序代码优选地适于当在计算机上执行该计算机程序时执行根据权利要求2至11中的一项描述的方法步骤。此外,根据本发明的又一方面,公开了一种设备,该设备包括事件摄像机和分析装置,其中,所述事件摄像机和所述分析装置被配置为当事件摄像机沿着场景在一轨迹上移动时执行根据权利要求1至11中的一项所述的方法。特别地,所述设备可以是手持设备,诸如移动电话(特别是智能电话)。此外,本发明的另一方面涉及一种通过将由事件摄像机获得的事件图像与模板图像进行配准来关于现有的半密集3d映射图定位事件摄像机的方法,其中,通过将利用事件摄像机获得的多个事件聚合到边缘映射图中来获得事件图像,并且其中,模板图像包括场景的根据事件摄像机的已知位姿(pose,姿势)的、投射的半密集3d映射图,其中,借助于将事件图像与模板图像进行配准来估计事件摄像机的6个自由度相对位姿。在下文中,参考附图描述了本发明的其他优点和特征以及本发明的实施方式和实施例,其中:图1示出了经典空间扫掠(sweep,扫描)和基于事件的空间扫掠中的反投射步骤的比较。这里2d图示与由两个点组成的场景一起使用。图1(a)示出了经典(基于帧)的空间扫掠,其中只有固定数量的视图可用。边缘映射图的两个点在每个图像中是可见的。通过反投射图像点获得的射线的交叉点被用作用于检测场景特征(对象点)的证据。另外,图1(b)示出了基于事件的空间扫掠,其中,在这里,当事件摄像机移动时,在事件摄像机上触发事件。每个观察到的事件对应于横跨可能的3d结构位置的射线(通过反投射)。高射线密度区域对应于两个点的位置,并随着事件摄像机的移动而逐渐被发现;图2示出了以处于参考视点(rv)的虚拟摄像机为中心的dsi射线计数器,其中其形状适于摄像机的透视投射。来自反投射事件(箭头)的每个进入的观察射线投票给它穿过的所有dsi体元(浅灰色);图3示出了在位于不同深度(近、中、远)处的三个纹理平面上方移动的事件摄像机。已经构建了如本文所述的射线密度dsif(x),其中示出了在不同深度处对它进行截片(slice,切片)的效果,以便模拟扫掠通过dsi的平面。当扫掠平面与对象平面重合时,后者看起来非常清晰,而场景的其余部分则“失焦”;图4示出了根据本发明的emvs方法的单个步骤,其中建立了射线密度dsif(x)(a),根据此,在虚拟摄像机中提取了置信度映射图(b)和半密集深度映射图(c)。半密集深度映射图给出了场景边缘的点云(d)(与图3中的相同的数据集);图5示出了合成实验:在三个数据集(a)-(c)中,估计的半密集深度映射图叠加在场景的屏幕截图上。深度是灰度编码的,从近(暗)到远(亮)。即使没有正则化或异常值滤波,根据本发明的emvs方法也成功地恢复大多数边缘,(d):在所有三个数据集中随着深度平面的数量nz变化的相对误差。图6hdr实验:顶部:场景和照明设置,其中davis(事件摄像机)在机动化线性滑动器(a)和灯(b)上。样本帧示出了hdr照明中的曝光不足水平和曝光过度水平(b)。相比之下,由于事件传感器的高动态范围,事件(叠加在帧上)不受影响。底部:重建的点云;图7示出了高速实验,即来自处于376像元/秒的davis(事件摄像机)的帧和事件。帧经受了运动模糊,而事件则没有,因此保留了视觉内容;图8示出了桌面数据集:具有对象和遮挡的场景;图9示出了盒子数据集:利用手持式davis(事件摄像机)进行的大规模半密集3d重建;以及图10示出了(a)配准过程中涉及的3d场景和位姿;(b)投射的半密集映射图m(c),和(c)事件图像i,其中位姿跟踪通过将事件图像i与投射的半密集映射图m对准来计算事件摄像机关于参考位姿的位姿。事件传感器/摄像机不捕获与摄像机运动平行的边缘。具有传统摄像机的多视图立体声(mvs)解决了从已知视点拍摄的图像的集合进行3d结构估计的问题[11]。根据本发明的基于事件的mvs(emvs)具有相同的目标;但是,有一些关键的区别:-传统的mvs算法对完整图像作用,因此它们不能应用于由事件摄像机传感器提供的异步事件流。emvs必须考虑事件的稀疏和异步性质。-因为如果事件摄像机和场景都是静态的,事件摄像机不输出数据,emvs要求移动事件摄像机以便获取视觉内容。在传统的mvs中,摄像机不需要运动来获取视觉内容。-因为事件是由强度边缘引起的,所以emvs的自然输出是半密集的3d映射图,而不是传统mvs的密集映射图。因此,emvs问题包括从通过具有已知视点的移动事件摄像机获取的事件的稀疏异步流获得场景的3d重建。不失通用性,考虑一个事件摄像机的情况就足够了。为了解决emvs问题,不能直接应用经典的mvs方法,因为它们对强度图像作用。然而,根据本发明的基于事件的方法建立在传统mvs的先前工作之上[10]。特别地,通过使用(参见下文)场景空间mvs方法的求解策略[10],其包括两个主要步骤:通过对图像测量进行变形(wrap,扭曲)来计算离散化的感兴趣体积中的聚合密实度得分(所谓的差异空间图像(dsi)),然后在该体积中查找3d结构信息。特别地,术语dsi用于表示离散化的感兴趣体积和在其上定义的得分函数。dsi由像元网格和深度平面的数量nz定义,即,其具有大小w×h×nz,其中w和h是事件摄像机在x和y方向上的像元的数量。深度zi可以自由选择。两个示例选择是:在最小和最大深度之间线性地采样深度,以及在最小和最大深度之间线性地采样反深度。存储在dsi中的得分是通过具有中心x=(x,y,z)t的每个体元v'的反投射观察射线r的数量。只要考虑提供视觉信息的方式,就可以指出mvs和emvs中的dsi方法之间的两个关键差异:-在经典mvs中,使用像元强度密集填充dsi。在emvs中,dsi可能具有孔(没有得分值的体元),因为变形事件也是稀疏的。-在经典mvs中,通过在dsi中找到最佳表面来获得场景对象。相比之下,在emvs中,找到半密集结构(例如,点、曲线)更好地匹配dsi的稀疏度。特别地,本发明通过引入基于事件的多视图立体声(emvs)的概念,特别是借助于使用空间扫掠[3]投票和最大化策略来估计在所选择的视点处的半密集深度映射图,然后通过合并深度映射图来构建更大的3d模型,以解决利用单个事件摄像机的结构估计的问题。在合成数据和实际数据两者上评估根据本发明的方法。分析结果并将结果与地面实况(groundtruth,地面真值)进行比较,表明了根据本发明的方法的成功执行。特别地,本发明通过构建仅包含边缘的几何信息的虚拟摄像机的dsi[12]并找到其中的3d点来概括对于移动事件摄像机的情况的空间扫掠方法。与大多数依赖于像元强度值的经典mvs方法相比,空间扫掠方法[3]仅依赖于场景的来自不同视点的二元边缘图像(例如canny)。因此,它利用视点相关边缘映射图的稀疏度或半密度来确定3d结构。更具体地,该方法包括三个步骤:-将图像特征变形(即,反投射)为通过dsi的射线,-记录穿过每个dsi体元的射线的数量,以及最后-确定在每个体元中是否存在3d点。dsi得分以非常简单的方式测量边缘的几何密实度:到dsi上的变形边缘映射图的每个像元对边缘的存在或不存在进行投票。然后,对dsi得分进行阈值化以确定最可能解释图像边缘的场景点。在下文中,空间扫掠算法被扩展以解决emvs。要注意的是,由事件摄像机提供的事件流是空间扫掠算法的理想输入,这是因为(i)事件摄像机自然地突出硬件的边缘,并且(ii)因为边缘触发来自许多连续视点的事件而不是来自几个稀疏视点的事件(参见图1)。基于事件的空间扫掠方法的三个步骤,即反投射、射线计数和确定场景结构的存在,可以如下得出:首先,由事件摄像机1生成的事件ek=(xk,yk,tk,pk)被正式定义为包含像元位置(xk,yk)、时间戳tk和亮度变化的极性pk(即符号)的元组。我们通过将由事件摄像机1输出的事件流{ek}用作变形为dsi中的类似输入点的特征来将空间扫掠方法扩展到基于事件的范例。根据事件摄像机在时间tk的视点对每个事件ek进行反投射,这根据mvs的假设是已知的。从几何观点来看,人们可以使用图1来比较经典的基于帧的设置中的反投射步骤和基于事件的设置中的反投射步骤。注意到,在基于帧的mvs中,视点p的数量与在事件摄像机1的高度采样轨迹(在时间{tk}时)中的数量相比较小。在基于事件的设置(图1(b))中的这种更丰富的测量和视点p生成了比基于帧的mvs更多的观察射线r,且因此,其促进了通过分析高射线密度的区域来检测场景点。根据本发明的方法的主要优点是不需要明确的数据关联。这是根据本发明的方法与现有的基于事件的深度估计方法之间的主要区别。虽然先前的工作主要是试图通过首先解决图像平面中的立体对应问题(使用累积事件的帧[6、9]、事件的时间相关性[2、5、7、8]等)来估计深度,但是根据本发明的方法特别地是直接在3d空间中工作。这在图1(b)中示出:不需要将事件与能够恢复3d位置的特定3d点相关联。在空间扫掠的第二步中,包含3d场景的体积被离散化,并且使用dsi对穿过每个体元的观察射线的数量进行计数。为了允许以可缩放的方式重建大场景,将包含场景的3d体积沿着事件摄像机的轨迹分成较小的3d体积,计算局部3d重建,然后将其合并,如将在下面更详细地解释的。具体地,为了根据事件子集计算场景的局部3d重建,考虑了位于参考视点rv处的虚拟事件摄像机1,该参考视点选自与事件子集相关联的那些事件摄像机视点p,并且定义了体积v中的dsi,其包括体元v'并且适于事件摄像机1的视场和透视投射,如图2中所示(参见[12])。dsi由事件摄像机像元和深度平面的数量nz定义,即,其具有大小w×h×nz,其中w和h是事件摄像机的宽度和高度,即在x和y方向上的像元数量。存储在dsi中的得分是穿过具有中心x=(x,y,z)t的每个体元v'的反投射观察射线r的数量,如图2所示。在空间扫掠的第三步中,我们通过确定每个dsi体元v'中是否存在3d点来获得虚拟事件摄像机中的半密集深度映射图。基于存储在dsi中的得分或射线密度函数,即f(x)来做出该决定。改述空间扫掠方法的假设[3],场景点可能出现在几个观察射线r几乎相交的区域(参见图1(b)),其对应于高射线密度的区域。因此,场景点可能出现在射线密度函数的局部最大值处。图3示出了以不同深度对实际数据集的dsi进行截片的实施例;对焦区域证明了射线密度函数的局部最大值的存在。特别地,在本发明的框架中,在两步过程之后检测dsif(x)的局部最大值:首先,通过记录沿着每个像元(x,y)的观察射线r中的体元v'行的最佳局部最大值f(x(x),y(y),z*)=:c(x,y)的位置和幅度,在虚拟事件摄像机中生成(密集)深度映射图z*(x,y)和相关联的置信度映射图c(x,y)。然后,特别地,通过对置信度映射图进行阈值化来选择深度映射图中最确信的像元,从而产生半密集深度映射图(图4)。特别地,可以使用自适应高斯阈值化,其中在这里如果c(x,y)>t(x,y),则选择像元(x,y),其中t(x,y)=c(x,y)*gσ(x,y)-c。特别地,使用gσ中的5×5邻域和c=-6。这种自适应方法产生比全局阈值化[3]好的结果。此外,在图4中给出了特别在本发明中使用的dsi方法的以上讨论元素的概述。因此,可以重建与参考视图周围的事件子集对应的场景的结构。如上面已经指出的,在可缩放设计的推动下,该操作优选地对事件流的多个子集执行,从而在多个关键参考视图处恢复场景的半密集深度映射图。具体地,一旦离前一个关键参考视点的距离超过平均场景深度的一定百分比,就选择新的关键参考视点,并使用在下一个关键参考视点之前的事件子集来估计场景的对应半密集深度映射图。可选地使用对置信像元位置进行作用的2d中值滤波器来使半密集深度映射图平滑,然后将半密集深度映射图转换为点云,孤立点(在给定半径内的邻居的数量小于阈值的那些点)清理出来,以及使用虚拟摄像机的已知位置合并为全局点云。也可以使用/实现其他深度映射图融合策略。即使不需要复杂的融合方法或正则化,根据本发明的方法也示出了引人注目的大规模3d重建结果。实施例在下文中,在合成和实际数据集两者上评估上述根据本发明的基于事件的空间扫掠方法的性能。已经借助于事件摄像机模拟器生成了具有地面实况信息的三个合成数据集。已经将空间分辨率设置为240×180像元,对应于商业事件传感器的分辨率。数据集还包括沿事件摄像机视点的强度图像。然而,这些没有用在根据本发明的emvs算法中;它们仅被示出以帮助使利用根据本发明的方法获得的半密集深度映射图可视化。数据集展示了各种深度剖面和运动:沙丘包括光滑表面(两个沙丘)并且处于两个自由度(dof)的平移和旋转的摄像机;3个平面示出了在不同深度处的三个平面(即,具有遮挡的不连续深度剖面)和线性摄像机运动;最后,3个壁示出了具有三个壁的房间(即具有锐利过渡的平滑深度剖面)和通常的6-dof摄像机运动。对每个数据集执行根据本发明的emvs算法。首先,关于用于对dsi进行采样的深度平面的数量nz来评估根据本发明的方法的灵敏度。特别地,在dsi中使用深度而不是反深度,因为它在具有有限深度变化的场景中提供了更好的结果。图5(d)示出了随nz变化的相对深度误差,其被定义为(在估计的深度映射图与地面状况之间的)平均深度误差除以场景的深度范围。正如预期的那样,误差随着nz的增加而减小,但是对于适度的nz值,它会停滞。因此,从那时起,已经使用了固定数量的nz=100个深度平面。表1报告了估计的3d点的平均深度误差,以及所有三个数据集的相对深度误差。深度误差较小,大约10%或更小,表明根据本发明的emvs算法的良好性能及其处理遮挡和各种表面和摄像机运动的能力。表1:合成数据集中的深度估计准确度(nz=100)沙丘3个平面3个壁深度范围3.00m1.30m7.60m平均误差0.14m0.15m0.52m相对误差4.63%11.31%6.86%此外,还已经评估了根据本发明的emvs算法对来自davis传感器[1]的数据集的性能。除了事件流之外,davis还以低帧速率(24hz)输出像标准摄像机那样的强度帧。然而,这里,根据本发明的emvs算法不使用帧;它们在这里被显示仅用于说明该方法的半密集结果。已经考虑两种方法来向根据本发明的emvs算法提供摄像机位姿信息:机动化线性滑动器或对davis帧的视觉测距算法。特别地,机动化滑动器已经被用于分析对照实验(因为它保证非常准确的位姿信息)中的表现,并且视觉测距算法(svo[4])表明我们的方法在手持(即,不受约束)的6-dof运动中的适用性。特别地,发现根据本发明的emvs算法能够在两个具有挑战性的场景——即(i)高动态范围(hdr)照明情况下和(ii)高速运动——中恢复准确的半密集结构。为此,将davis放置在机动化线性滑动器上,面向离传感器已知恒定深度的纹理壁。在两个实验中,测量了半密集映射图对地面实况的准确度,其中发现了令人信服的深度估计准确度,即大约5%的相对误差,该准确度是非常高的,特别是考虑到传感器的低分辨率(仅240×180像元)。此外,除了照明之外,已经记录了在相同的获取条件下的两个数据集(图6):首先在整个场景中恒定照明的情况下,其次,用强大的灯照亮场景的仅一半的情况下。在后一种情况下,标准摄像机无法应对场景中间的宽强度变化,因为图像的一些区域曝光不足而其他区域过度曝光。这里,执行了具有两个不同壁距(近和远)的高动态范围(hdr)实验。在图6和表2中给出了根据本发明的emvs算法的结果。表2:hdr实验中的深度估计准确度已经观察到重建的质量不受照明条件的影响。在两种情况下,根据本发明的emvs方法具有非常高的准确度(平均相对误差≈5%),并且不管事件摄像机/传感器的空间分辨率低还是缺乏正则化。而且,要注意的是,准确度不受照明条件的影响。因此,传感器的高动态范围能力允许了成功的hdr深度估计。此外,为了表明事件传感器的高速能力可以用于3d重建,已经利用离壁40.5cm并且以0.45m/s移动的davis记录了数据集。这对应于图像平面中的376像元/s的速度,这在davis帧中导致运动模糊(参见图7)。运动模糊使视觉信息难以理解。相比之下,事件流的高时间分辨率仍然准确地捕获场景的边缘信息。根据本发明的emvs方法产生3d重建,其具有1.26cm的平均深度误差和4.84%的相对误差。准确度与之前的实验的准确度(≈5%)一致,因此支持了根据本发明的方法的显著性能及其利用事件摄像机/传感器的高速特性的能力。图8和图9示出了通过根据本发明的emvs方法获得的对于非平坦场景的一些结果。两者都示出了半密集点云及其在帧上的投射(为了更好地理解)。在图8中,davis(事件摄像机)在场景的前面移动,该场景包括具有不同形状和处于不同深度的各种对象。尽管由前景对象对远距离对象产生了大遮挡,但是根据本发明的emvs算法能够可靠地恢复场景的结构。最后,图9示出了根据本发明的emvs算法在较大规模数据集上的结果。传感器是在带有各种纹理盒子的大房间里手持移动的。沿着轨迹估计多个局部点云,然后将其合并为全局的大规模3d重建。此外,本发明的又一方面涉及一种用于定位事件摄像机的方法。在这里,对应跟踪模块依赖于图像到模型的对准,该对准也用于基于帧的直接vo流水线[13]、[14]中。在这些方法中,3d刚体变形用于将每个进入的强度图像与关键帧进行配准。它们最小化了一组选择的像元上的光度误差,上述选择的像元在场景中的3d对应关系是已经建立好的。特别地,遵循相同的全局图像对准策略,但是,由于事件摄像机自然地响应场景中的边缘,因此光度误差被两个边缘图像之间的几何对准误差代替(参见方程式(1))。配准过程中涉及的两个图像是(参见图10):事件图像i,该事件图像通过将少量事件聚合到边缘映射图中获得;以及模板m,该模板包括场景的根据事件摄像机1的已知位姿的投射的半密集3d映射图。在这方面,图10(a)示出了配准过程中涉及的3d场景和位姿,其中图10(b)示出了投射的半密集映射图m,并且图10(c)示出了事件图像i。特别地,使用反向合成lucas-kanade(lk)方法[15]、[16],通过下述来进行配准:迭代计算使∑u(m(w(u;δt))-i(w(u;t)))2,(1)最小化的增量位姿δt,然后更新变形w,这引起刚体变换t从m的帧到i的帧的以下更新:t←t·(δt)-1。(2)在反向方法(方程(1))中,投射的映射图m进行变形,直到它与由配准变换t的当前估计给出的变形事件图像对准。3d刚体变形w由下述定义:w(u;t):=π(t·π-1(u,du)),(3)其中,u是m的图像平面中的点,t是刚体变换,π和π-1分别表示摄像机投射和反投射,并且du是投射在像元u上的3d点的已知深度。因此,方程式(1)中的总和是在m的域中的所有候选像元u上,针对其存在相关联的深度估计du。定义3d刚体变形,使得w(u;id)=u是如[15]中要求的身份。特别地,使用扭曲坐标[17]:来参数化刚体变换,其中并且李代数元素由于i和m两者都携带关于边缘的信息,因此目标函数方程式(1)可以被解读为对两个边缘映射图——使用事件的测量的边缘映射图和根据3d边缘映射图的投射预测的边缘映射图——之间的配准误差的测量。由于事件摄像机1的操作原理,事件图像i捕获除了与表观运动平行的边缘之外的所有边缘。反向合成lk方法相对于其他lk公式具有低计算复杂度的优点[15]:可以预先计算依赖于m的导数,因为m在迭代期间保持恒定。另外,这些计算可以重新用于关于相同的m对准多个事件图像i。为了效率,在实施例中,已经使用了误差函数方程式(1)的分析导数,该分析导数涉及通过链规则关于未知增量位姿δt的指数坐标计算梯度▽m和变形函数的导数。使用校准坐标并假设镜头失真已被消除,x=(u,v)t≡k-1u,后者导数由相互作用矩阵给出[18]最后,使用平均滤波器对lk方法方程式(2)收敛时获得的位姿t进行滤波,以得到事件摄像机的更平滑的轨迹。参考文献[1]c.brandli,r.berner,m.yang,s.-c.liu,andt.delbruck.a240x180130db3uslatencyglobalshutterspatiotemporalvisionsensor.ieeej.ofsolid-statecircuits,49(10):2333-2341,2014.[2]l.a.camunas-mesa,t.serrano-gotarredona,s.-h.leng,r.benosman,andb.linares-barranco.ontheuseoforientationfiltersfor3dreconstructioninevent-drivenstereovision.front.neurosci.,8(48),2014.[3]r.t.collins.aspace-sweepapproachtotruemulti-imagematching.inieeeint.conf.computervisionandpatternrecognition(cvpr),pages358-363,jun1996.[4]c.forster,m.pizzoli,andd.scaramuzza.svo:fastsemi-directmonocularvisualodometry.inieeeint.conf.onroboticsandautomation(icra),pages15-22,2014.[5]j.kogler,m.humenberger,andc.sulzbachner.event-basedstereomatchingapproachesforframelessaddresseventstereodata.inadvancesinvisualcomputing,volume6938oflecturenotesincomputerscience,pages674-685.springer,2011.[6]j.kogler,c.sulzbachner,m.humenberger,andf.eibensteiner.address-eventbasedstereovisionwithbio-inspiredsiliconretinaimagers.inadvancesintheoryandapplicationsofstereovision,pages165-188.intech,2011.[7]j.lee,t.delbruck,p.park,m.pfeiffer,c.shin,h.ryu,andb.c.kang.gesturebasedremotecontrolusingstereopairofdynamicvisionsensors.inint.conf.oncircuitsandsystems(iscas),2012.[8]p.rogister,r.benosman,s.-h.leng,p.lichtsteiner,andt.delbruck.asynchronousevent-basedbinocularstereomatching.ieeetrans.neuralnetworksandlearningsystems,23(2):347-353,feb2012.[9]s.schraml,a.n.belbachir,n.milosevic,andp.schon.dynamicstereovisionsystemforreal-timetracking.inint.conf.oncircuitsandsystems(iscas),2010.[10]s.m.seitz,b.curless,j.diebel,d.scharstein,andr.szeliski.acomparisonandevaluationofmulti-viewstereoreconstructionalgorithms.inieeeint.conf.computervisionandpatternrecognition(cvpr),2006.[11]r.szeliski.computervision:algorithmsandapplications.textsincomputerscience.springer,2010.[12]r.szeliskiandp.golland.stereomatchingwithtransparencyandmatting.int.j.comput.vis.,32(1):45-61,1999.[13]c.forster,m.pizzoli,andd.scaramuzza,"svo:fastsemi-directmonocularvisualodometry,"inieeeint.conf.onroboticsandautomation(icra),2014,pp.15-22.[14]j.engel,j.andd.cremers,"lsd-slam:large-scaledirectmonocularslam,"ineur.conf.oncomputervision(eccv),2014.[15]s.bakerandi.matthews,"lucas-kanade20yearson:aunifyingframework,"int.j.comput.vis.,vol.56,no.3,pp.221-255,2004.[16]a.crivellaro,p.fua,andv.lepetit,"densemethodsforimagealignmentwithanapplicationto3dtracking,"epfl,tech.rep.197866,2014.[17]y.ma,s.soatto,j.kosecka,ands.s.sastry,aninvitationto3-dvision:fromimagestogeometricmodels.springerverlag,2004.[18]p.corke,robotics,visionandcontrol:fundamentalalgorithmsinmatlab,ser.springertractsinadvancedrobotics.springer,2011。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1