具有深度学习传感器的增强现实显示装置的制作方法
本申请要求2016年8月22日提交的题为“systemsandmethodsforaugmentedreality(用于增强现实的系统和方法)”的美国专利申请no.62/377,835的优先权,其全部内容通过引用结合于此。
本公开涉及使用深度学习神经网络将多个传感器输入(例如,惯性测量单元、相机、深度传感器、麦克风)组合成包括共享层和执行多个功能(例如,面部识别、位置和构建地图、对象检测、深度估计等)的上层的统一路径的增强现实系统。
背景技术:
现代计算和显示技术促进了用于所谓的“虚拟现实”或“增强现实”体验的系统的开发,其中数字再现图像或其部分以它们看起来真实或者可能被感知为真实的方式呈现给用户。虚拟现实或“vr”场景通常涉及呈现数字或虚拟图像信息,而对其它实际的真实世界视觉输入不透明;增强现实或“ar”场景通常涉及呈现数字或虚拟图像信息,作为对用户周围的实际世界的可视化的增强。
技术实现要素:
在一个方面,头戴式增强现实(ar)装置可以包括硬件处理器,该硬件处理器被编程为从多个传感器(例如,惯性测量单元、面向外相机、深度感测相机、眼睛成像相机或麦克风)接收不同类型的传感器数据;以及使用不同类型的传感器数据和水螅神经网络来确定多个事件中的事件(例如,面部识别、视觉搜索、手势识别、语义分割、对象检测、照明检测、同时定位和构建地图、重定位)。在另一方面,还公开了一种用于训练水螅神经网络的系统。在另一方面,公开了一种用于训练水螅神经网络或使用训练的水螅神经网络来确定多个不同类型的事件中的事件的方法。
在附图和以下描述中阐述了本说明书中描述的主题的一个或多个实施方式的细节。从说明书、附图和权利要求,其它特征、方面和优点将变得显而易见。该概述和以下详细描述都不旨在限定或限制本发明主题的范围。
附图说明
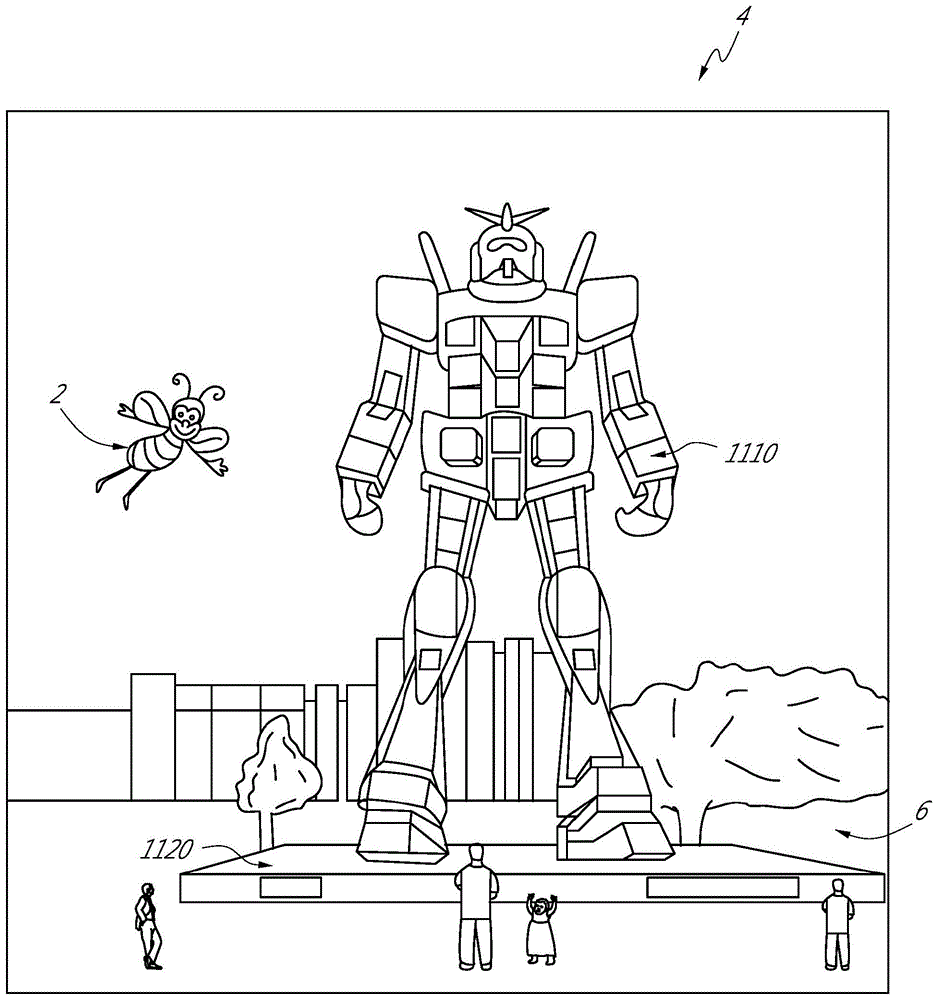
图1描绘了具有某些虚拟现实对象以及由人观看的某些物理对象的增强现实场景的图示。
图2a-2d示意性地示出可穿戴系统的示例。
图3示意性地示出云计算资产和本地处理资产之间的协调。
图4示意性地示出了电磁(em)跟踪系统的示例系统图。
图5是描述电磁跟踪系统的实施例的示例功能的流程图。
图6示意性地示出与ar系统结合的电磁跟踪系统的示例。
图7是描述ar装置的情况下的电磁跟踪系统的示例的功能的流程图。
图8示意性地示出ar系统的实施例的部件的示例。
图9a-9f示意性地示出快速释放模块的示例。
图10示意性地示出头戴式显示系统。
图11a和图11b示意性地示出耦接到头戴式显示器的电磁感测线圈的示例。
图12a-12e示意性地示出可以耦接到电磁传感器的铁氧体磁芯的示例配置。
图13a是示意性地示出频分复用(fdm)的em发射器电路(em发射器)的示例的框图。
图13b是示意性地示出频分复用的em接收器电路(em传感器)的示例的框图。
图13c是示意性地示出时分复用(tdm)的em发射器电路的示例的框图。
图13d是示意性地示出用于em发射器的动态可调谐电路的示例的框图。
图13e是示出可以通过动态调谐图13d中所示的电路来实现的谐振的示例的曲线图。
图13f示出时分复用em发射器和接收器的时序图的示例。
图13g示出时分复用em发射器和接收器的扫描时序的示例。
图13h是示意性地示出em跟踪系统中的tdm接收器的示例的框图。
图13i是示意性地示出没有自动增益控制(agc)的em接收器的示例的框图。
图13j是示意性地示出采用agc的em发射器的示例的框图。
图14和图15是示出在头戴式ar系统中采用电磁跟踪系统的姿势跟踪的示例的流程图。
图16a和图16b示意性地示出ar系统的其它实施例的部件的示例。
图17a示意性地示出电磁跟踪系统中的发射器中的谐振电路的示例。
图17b是示出图17a的谐振电路中的22khz的谐振的示例的曲线图。
图17c是示出流过谐振电路的电流的示例的曲线图。
图17d和图17e示意性地示出用于电磁跟踪系统的em场发射器中的谐振电路的动态可调谐配置的示例。
图17f是通过改变图17e所示的示例电路中的电容器c4的电容值来示出动态调谐的谐振的示例的曲线图。
图17g是示出在各种谐振频率下实现的最大电流的示例的曲线图。
图18a是示意性地示出与音频扬声器相邻的电磁场传感器的示例的框图。
图18b是示意性地示出具有噪声消除系统的电磁场传感器的示例的框图,该噪声消除系统接收来自传感器和外部音频扬声器二者的输入。
图18c是示出如何反转和添加信号以消除由音频扬声器引起的磁干扰的示例的曲线图。
图18d是示出用于消除被em跟踪系统中的em传感器接收的干扰的示例方法的流程图。
图19示意性地示出使用光图案来辅助视觉系统的校准。
图20a-20c是可用于可穿戴显示装置的子系统或部件的示例电路的框图。
图21是示出来自imu、电磁跟踪传感器和光学传感器的融合输出的示例的曲线图。
图22a-22c示意性地示出耦接到头戴式显示器的电磁感测线圈的附加示例。
图23a-23c示意性地示出使用电磁信号和声学信号重新校准头戴式显示器的示例。
图24a-24d示意性地示出使用相机或深度传感器重新校准头戴式显示器的附加示例。
图25a和图25b示意性地示出用于解决可与电磁跟踪系统相关联的位置模糊的技术。
图26示意性地示出稀疏3-d映射点的特征提取和生成的示例。
图27是示出用于基于视觉的姿势计算的方法的示例的流程图。
图28a-28f示意性地示出传感器融合的示例。
图29示意性地示出水螅(hydra)神经网络架构的示例。
在整个附图中,可以重复使用参考标号来指示参考元素之间的对应关系。提供附图是为了说明在此描述的示例实施例,并且不旨在限制本公开的范围。
具体实施方式
ar、vr和本地化系统概述
在图1中,描绘了增强现实场景(4),其中ar技术的用户看到以人、树、背景中的建筑物和混凝土平台(1120)为特征的真实世界公园式设置(6)。除了这些项目之外,ar技术的用户还感知到他“看到”站立在真实世界平台(1120)上的机器人雕像(1110),以及似乎是大黄蜂的拟人化的飞行的卡通式头像角色(2),即使这些元素(2,1110)在真实世界中不存在。事实证明,人类视觉感知系统非常复杂,并且产生vr或ar技术,其促进虚拟图像元素在其它虚拟或真实世界图像元素中的舒适、自然感觉、丰富呈现是具有挑战性的。
例如,头戴式ar显示器(或头盔式显示器或智能眼镜)通常至少松散地耦接到用户的头部,并因此在用户的头部移动时移动。如果显示系统检测到用户的头部运动,则可以更新正在显示的数据以考虑头部姿势的变化。
作为示例,如果佩戴头戴式显示器的用户在显示器上观看三维(3d)对象的虚拟表示并在3d对象出现的区域周围行走,则可以针对每个视点重新渲染3d对象,使用户感觉到他或她正在围绕占据真实空间的对象行走。如果头戴式显示器用于在虚拟空间(例如,丰富的虚拟世界)内呈现多个对象,则可以使用头部姿势的测量(例如,用户头部的位置和取向)来重新渲染场景以匹配用户动态改变的头部位置和取向,并提供增加的虚拟空间沉浸感。
在ar系统中,头部姿势的检测或计算可以促进显示系统渲染虚拟对象,使得它们看起来以对用户有意义的方式占据真实世界中的空间。此外,与用户头部或者ar系统相关的真实对象(诸如手持装置(也可以称为“图腾”)、触觉装置)或其它真实物理对象的位置和/或取向的检测还可以便于显示系统向用户呈现显示信息,以使用户能够有效地与ar系统的某些方面进行交互。当用户的头部在真实世界中移动时,虚拟对象可以作为头部姿势的函数被重新渲染,使得虚拟对象看起来相对于真实世界保持稳定。至少对于ar应用,虚拟对象与物理对象的空间关系的放置(例如,呈现为在二维或三维中空间上接近物理对象)可能是非平凡的问题。例如,头部运动可能使周围环境视图中的虚拟对象的放置显著复杂化。无论视图是作为周围环境的图像被捕获并且然后投影或显示给终端用户,还是终端用户是否直接感知周围环境的视图,都是如此。例如,头部运动将可能导致终端用户的视场改变,这可能需要更新到在终端用户的视场中显示各种虚拟对象的位置。另外,头部运动可以在多种范围和速度内发生。头部运动速度可以不仅在不同的头部运动之间变化,而是在单个头部运动的范围内或跨越单个头部运动的范围改变。例如,头部运动速度可以最初从起点(例如,线性地或不是线性地)增加,并且可以在达到终点时减小,从而在头部运动的起点和结点之间的某处获得最大速度。快速的头部运动甚至可能超过特定显示器或投影技术的能力,以向终端用户渲染看起来均匀和/或平滑运动的图像。
头部跟踪准确度和延迟(例如,用户移动他或她的头部时与图像被更新并显示给用户时之间所经过时间)已经成为vr和ar系统的挑战。特别是对于用虚拟元素填充用户视场的大部分的显示系统,如果头部跟踪的准确度高并且从头部运动的第一次检测到由显示器传递给用户的视觉系统的光的更新的整体系统延迟非常低,则是有利的。如果延迟很高,则系统可能会在用户的前庭和视觉感官系统之间产生不匹配,并产生可能导致晕动病或晕动症的用户感知情景。如果系统延迟很高,则虚拟对象的明显位置在快速头部运动期间将显得不稳定。
除了头戴式显示系统之外,其它显示系统可受益于准确且低延迟的头部姿势检测。这些包括头部跟踪显示系统,其中显示器没有佩戴在用户的身体上,而是例如安装在墙壁或其它表面上。头部跟踪显示器就像窗口作用到场景上,并且随着用户相对于“窗口”移动他的头部,场景被重新渲染以匹配用户的改变视点。其它系统包括头戴式投影系统,其中头戴式显示器将光投射到真实世界中。
另外,为了提供逼真的增强现实体验,ar系统可以被设计为与用户交互。例如,多个用户可以与虚拟球和/或其它虚拟对象玩球类游戏。一个用户可以“抓住”虚拟球,并将球扔回到另一个用户。在另一个实施例中,可以向第一用户提供图腾(例如,通信地耦接到ar系统的真实球棒)以击中虚拟球。在其它实施例中,可以向ar用户呈现虚拟用户界面以允许用户选择许多选项中的一个选项。用户可以使用图腾、触觉装置、可穿戴部件,或者简单地触摸虚拟屏幕以与系统交互。
检测用户的头部姿势和取向,以及检测空间中的真实对象的物理位置使得ar系统能够以有效且愉快的方式显示虚拟内容。然而,虽然这些功能是ar系统的关键,但很难实现。换句话说,ar系统可以识别真实对象(例如,用户的头部、图腾、触觉装置、可穿戴部件、用户的手等)的物理位置并且将真实对象的物理坐标与对应于正向用户显示的一个或多个虚拟对象的虚拟坐标相关联。这通常需要高度准确的传感器和传感器识别系统,其以快速速率跟踪一个或多个对象的位置和取向。目前的方法不能以令人满意的速度或精度标准执行定位。
因此,在ar和vr装置的情况下需要更好的定位系统。
示例ar和vr系统和部件
参考图2a-2d,示出了一些通用部件选项。在图2a-2d的讨论之后的详细描述的部分中,呈现了各种系统、子系统和部件,用于解决为人vr和/或ar提供高质量、舒适感知的显示系统的目标。
如图2a中所示,ar系统用户(60)被描绘为佩戴头戴式部件(58),该头戴式部件(58)以耦接到位于用户眼睛前方的显示系统(62)的框架(64)结构为特征。扬声器(66)以所示的配置耦接到框架(64)并且位于用户的耳道附近(在一个实施例中,未示出的另一个扬声器位于用户的另一个耳道附近以提供立体声/可塑形声音控制)。显示器(62)可操作地(诸如通过有线引线或无线连接)耦接(68)到本地处理和数据模块(70),该本地处理和数据模块(70)可以以各种配置安装,诸如固定地附接到框架(64),固定地附接到如图2b的实施例中所示的头盔或帽子(80),嵌入耳机中,以如图2c的实施例中所示的背包式配置可拆卸地附接到用户(60)的躯干(82),或者以如图2d的实施例中所示的皮带耦接式配置可拆卸地附接到用户(60)的臀部(84)。
本地处理和数据模块(70)可以包括功率有效的处理器或控制器,以及诸如闪存的数字存储器,两者都可以用于辅助处理、缓存和存储如下数据:a)从可以可操作地耦接到框架(64)的传感器(诸如图像捕获装置(诸如相机)、麦克风、惯性测量单元、加速度计、指南针、gps单元、无线装置和/或陀螺仪)捕获的;和/或b)使用远程处理模块(72)和/或远程数据存储库(74)获取和/或处理的,可能用于在这种处理或检索之后传递到显示器(62)。本地处理和数据模块(70)可以可操作地诸如经由有线或无线通信链路耦接(76,78)到远程处理模块(72)和远程数据存储库(74),使得这些远程模块(72,74)可操作地彼此耦接并且可用作本地处理和数据模块(70)的资源。
在一个实施例中,远程处理模块(72)可包括被配置为分析和处理数据和/或图像信息的一个或多个相对强大的处理器或控制器。在一个实施例中,远程数据仓库(74)可包括相对大规模的数字数据存储设施,其可通过因特网或在“云”资源配置中的其它网络配置来获得。在一个实施例中,在本地处理和数据模块中存储全部数据并执行全部计算,允许从任何远程模块完全自主的使用。
现在参考图3,示意图示出了云计算资产(46)和本地处理资产之间的协调,其可以例如驻留在耦接到用户头部(120)的头戴式部件(58)和耦接到用户的皮带(308;因此部件70也可以称为“皮带腰包”70)的本地处理和数据模块(70)中,如图3中所示。在一个实施例中,云(46)资产(诸如一个或多个服务器系统(110))诸如经由有线或无线网络(无线优选用于移动性,有线优选用于可能需要的某些高带宽或高数据量传输)可操作地直接(40,42)耦接(115)到本地计算资产中的一个或二者,诸如如上所述的耦接到用户头部(120)和皮带(308)的处理器和存储器配置。对于用户是本地的这些计算资产也可以经由有线和/或无线连接配置(44)(诸如下面参考图8讨论的有线耦接(68))可操作地彼此耦接。在一个实施例中,为了保持安装到用户头部(120)的低惯性和小尺寸子系统,用户和云(46)之间的主要传输可以经由安装在皮带(308)的子系统和云之间的链路,其中头戴式(120)子系统主要使用无线连接(诸如超宽带(“uwb”)连接)用数据联系到基于皮带(308)的子系统,如当前在例如个人计算外围连接应用中所采用的那样。
通过有效的本地和远程处理协调,以及用于用户的适当的显示设备,诸如图2a所示的用户界面或用户显示系统(62)或其变体,与用户的当前实际或虚拟位置相关的一个世界的方面可以被传送或“传递”给用户并以有效的方式更新。换句话说,可以在可能部分存在于用户的ar系统上并且部分存在于云资源中的存储位置处不断地更新世界的地图。地图(map)(也称为“可通行的世界模型”)可以是包括光栅图像、3-d和2-d点、参数信息以及关于真实世界的其它信息的大型数据库。随着越来越多的ar用户不断地捕获关于它们的真实环境的信息(例如,通过照相机、传感器、imu等),地图变得越来越准确和完整。
利用如上所述的配置,其中存在可以驻留在云计算资源上并且从那里分发的一个世界模型,这种世界可以以相对低的带宽形式“通行”给一个或多个用户,优选地尝试传递实时视频数据等。可以通过基于云的世界模型来通知站在雕像附近的人的增强体验(例如,如图1中所示),其中的子集可以向下传递给他们和他们的本地显示装置以完成观看。坐在远程显示装置处的人(这像坐在桌子上的个人计算机一样简单)可以有效地从云中下载相同的信息部分并将其渲染在他们的显示器上。实际上,实际出现在雕像附近的公园里的一个人可能会带着位于远方的朋友在那个公园散步,朋友通过虚拟和增强现实加入。系统将需要知道街道在哪里,树木在哪里,雕像在哪里-但是采用在云上的该信息,加入的朋友可以从场景的云方面下载,并且然后作为相对于实际在公园里的人的本地增强现实开始行走。
可以从环境捕获三维(3-d)点,并且可以确定捕获那些图像或点的相机的姿势(例如,相对于世界的矢量和/或原点位置信息),使得这些点或图像可以用该姿势信息“标记”或与该姿势信息相关联。然后,可以利用由第二相机捕获的点来确定第二相机的姿势。换句话说,可以基于与来自第一相机的标记图像的比较来取向和/或定位第二相机。然后,可以利用这些知识来提取纹理、制作地图、并创建真实世界的虚拟副本(因为然后围绕其存在两个相机被注册)。
因此,在基础水平上,在一个实施例中,可以利用人佩戴的系统来捕获3-d点和产生该点的2-d图像,并且可以将这些点和图像发送到云存储和处理资源。它们也可以用嵌入的姿势信息在本地缓存(例如,缓存标记的图像);因此,云可以具有准备好的(例如,在可用的缓存中)标记的2-d图像(例如,用3-d姿势标记)以及3-d点。如果用户正在观察动态的东西,则他还可以将附加信息向上发送到与运动相关的云(例如,如果观看另一个人的面部,则用户可以获取面部的纹理地图并以优化的频率向上推送,即使周围的世界另外基本上是静态的)。关于对象识别器和可通行的世界模型的更多信息可以在题为“systemandmethodforaugmentedandvirtualreality(用于增强和虚拟现实的系统和方法)”的美国专利公开no.2014/0306866中找到,其与以下附加公开的全部内容通过引用并入本文,附加公开涉及诸如由佛罗里达州plantation的magicleap公司开发的这些增强和虚拟现实系统:美国专利公开no.2015/0178939;美国专利公开no.2015/0205126;美国专利公开no.2014/0267420;美国专利公开no.2015/0302652;美国专利公开no.2013/0117377;以及美国专利公开no.2013/0128230,其各自通过引用整体并入在此。
gps和其它本地化信息可以用作这种处理的输入。用户的头部、图腾、手势、触觉装置等的高度准确定位可能是有利的,以便向用户显示适当的虚拟内容。
头戴式装置(58)可包括可定位在装置的佩戴者眼睛前方的显示器。显示器可包括光场显示器。显示器可以被配置为在多个深度平面处向佩戴者呈现图像。显示器可包括具有衍射元件的平面波导。在美国专利公开no.2015/0016777中描述了可与在此公开的任何实施例一起使用的显示器、头戴式装置和其它ar部件的示例。美国专利公开no.2015/0016777通过引用整体并入在此。
电磁定位的示例
实现高精度定位的一种方法可以涉及使用与电磁传感器耦接的电磁(em)场,该电磁传感器策略性地放置在用户的ar头部装置、皮带腰包和/或其它辅助装置(例如,图腾、触觉装置、游戏仪器等)上。电磁跟踪系统通常包括至少电磁场发射器和至少一个电磁场传感器。电磁场发射器在ar耳机的佩戴者的环境中生成具有已知空间(和/或时间)分布的电磁场。电磁场传感器测量传感器位置处生成的电磁场。基于这些测量和所生成的电磁场的分布的知识,可以确定场传感器相对于发射器的姿势(例如,位置和/或取向)。因此,可以确定传感器附接到其上的对象的姿势。
现在参考图4,示出了电磁跟踪系统(例如,诸如由biosensedivisionofjohnson&johnsoncorporation、polhemus,inc.ofcolchester,vermont的组织开发、由sixenseentertainment,inc.oflosgatos,california和其它跟踪公司制造的那些系统)的示例系统图。在一个或多个实施例中,电磁跟踪系统包括电磁场发射器402,该电磁场发射器402被配置为发射已知的磁场。如图4中所示,电磁场发射器可以耦接到电力供给(例如,电流、电池等)以向发射器402提供电力。
在一个或多个实施例中,电磁场发射器402包括生成磁场的若干线圈(例如,彼此垂直放置以在x、y和z方向中产生场的至少三个线圈)。该磁场用于建立坐标空间(例如,x-y-z笛卡尔坐标空间)。这允许系统相对于已知磁场映射传感器的位置(例如,(x,y,z)位置),并帮助确定传感器的位置和/或取向。在一个或多个实施例中,电磁传感器404a、404b等可以附接到一个或多个真实对象。电磁传感器404可以包括较小的线圈,其中可以通过发射的电磁场感应出电流。通常,“传感器”部件(404)可以包括小线圈或回路,诸如一组三个不同取向的(例如,诸如相对于彼此正交取向)线圈,线圈在诸如立方体或其它容器的小结构内耦接在一起,该线圈被定位/取向以捕获来自由发射器(402)发射的磁场的入射磁通量,并通过比较通过这些线圈感应的电流,并且知道线圈相对于彼此的相对位置和取向,可以计算传感器相对于发射器的相对位置和取向。
可以测量与可操作地耦接到电磁跟踪传感器的线圈和惯性测量单元(“imu”)部件的行为有关的一个或多个参数,以检测传感器(及其所附接的对象)相对于电磁场发射器所耦接的坐标系的位置和/或取向。在一个或多个实施例中,可以相对于电磁发射器使用多个传感器来检测坐标空间内的每个传感器的位置和取向。电磁跟踪系统可以在三个方向(例如,x、y和z方向)中并且进一步在两个或三个取向角中提供位置。在一个或多个实施例中,可以将imu的测量与线圈的测量进行比较,以确定传感器的位置和取向。在一个或多个实施例中,电磁(em)数据和imu数据二者以及各种其它数据源(诸如相机、深度传感器和其它传感器)可以组合以确定位置和取向。该信息可以被发送(例如,无线通信、蓝牙等)到控制器406。在一个或多个实施例中,可以在传统系统中以相对高的刷新率报告姿势(或位置和取向)。传统上,电磁场发射器耦接到相对稳定且大的对象,诸如桌子、手术台、墙壁或天花板,并且一个或多个传感器耦接到较小的对象,诸如医疗装置、手持游戏部件等。可替代地,如下面参考图6所述,可以采用电磁跟踪系统的各种特征来产生如下配置,其中可以跟踪在空间中相对于更稳定的全局坐标系统移动的两个对象之间的位置和/或取向的变化或变化量;换句话说,图6中示出了一种配置,其中电磁跟踪系统的变型可以用于跟踪头戴式部件和手持部件之间的位置和取向变化量,同时诸如通过使用可以耦接到系统的头戴式部件的外向捕获相机的同时定位和建图(“slam”)技术以其它方式确定相对于全局坐标系统(例如,用户本地的房间环境)的头部姿势。
控制器406可以控制电磁场发生器402,并且还可以捕获来自各种电磁传感器404的数据。应当理解,系统的各种部件可以通过任何机电或无线/蓝牙工具耦接到彼此。控制器406还可以包括关于已知磁场的数据,以及与磁场相关的坐标空间。然后,该信息用于检测传感器相对于与已知电磁场对应的坐标空间的位置和取向。
电磁跟踪系统的一个优点是它们以最小的延迟和高分辨率产生高度准确的跟踪结果。另外,电磁跟踪系统不一定依赖于光学跟踪器,并且可以容易地跟踪不在用户视线中的传感器/对象。
应当理解,电磁场v的强度作为距线圈发射器(例如,电磁场发射器402)的距离r的三次函数下降。因此,可以基于远离电磁场发射器的距离来使用算法。控制器406可以配置有这种算法,以确定传感器/对象在远离电磁场发射器的不同距离处的位置和取向。随着传感器越来越远离电磁发射器,电磁场强度迅速下降,在准确度、效率和低延迟方面,可以在更近的距离实现最优结果。在典型的电磁跟踪系统中,电磁场发射器由电流(例如,插入式电力供给)供电,并且具有位于远离电磁场发射器20英尺半径内的传感器。在包括ar应用的许多应用中,传感器和场发射器之间的较短半径可能是更期望的。
现在参考图5,简要描述了描述典型电磁跟踪系统的功能的示例流程图。在502处,发射已知的电磁场。在一个或多个实施例中,磁场发射器可以生成磁场,每个线圈可以在一个方向(例如,x、y或z)中生成电场。可以用任意波形生成磁场。在一个或多个实施例中,沿每个轴的磁场分量可以以与沿其它方向的其它磁场分量略微不同的频率振荡。在504处,可确定与电磁场对应的坐标空间。例如,图4的控制406可以基于电磁场自动确定发射器周围的坐标空间。在506处,可以检测传感器处的线圈(可以附接到已知对象)的行为。例如,可以计算在线圈处感应的电流。在其它实施例中,可以跟踪和测量线圈的旋转或任何其它可量化的行为。在508处,该行为可用于检测传感器和/或已知对象的位置或取向。例如,控制器406可以查阅映射表,该映射表将传感器处的线圈的行为与各种位置或取向相关联。基于这些计算,可以确定坐标空间中的位置以及传感器的取向。
在ar系统的情况下,可能需要修改电磁跟踪系统的一个或多个部件以促进移动部件的准确跟踪。如上所述,在许多ar应用中可能需要跟踪用户的头部姿势和取向。准确确定用户的头部姿势和取向允许ar系统向用户显示正确的虚拟内容。例如,虚拟场景可以包括隐藏在真实建筑物后面的怪物。取决于用户头部相对于建筑物的姿势和取向,可能需要修改虚拟怪物的视图,使得提供真实的ar体验。或者,图腾、触觉装置或与虚拟内容交互的一些其它工具的位置和/或取向对于使ar用户能够与ar系统交互可能是重要的。例如,在许多游戏应用中,ar系统可以检测相对于虚拟内容的真实对象的位置和取向。或者,当显示虚拟界面时,可以相对于所显示的虚拟界面知道图腾、用户的手、触觉装置或被配置用于与ar系统交互的任何其它真实对象的位置,以便系统理解命令等。包括光学跟踪和其它方法的传统定位方法通常受到高延迟和低分辨率问题的困扰,这使得在许多增强现实应用中渲染虚拟内容具有挑战性。
在一个或多个实施例中,关于图4和图5讨论的电磁跟踪系统可以适于ar系统以检测一个或多个对象相对于发射的电磁场的位置和取向。典型的电磁系统倾向于具有大且笨重的电磁发射器(例如,图4中的402),这对于头戴式ar装置是有问题的。然而,较小的电磁发射器(例如,在毫米范围内)可用于在ar系统的情况下发射已知的电磁场。
现在参考图6,电磁跟踪系统可以与如图所示的ar系统结合,电磁场发射器602结合为手持控制器606的一部分。控制器606可以相对于ar耳机(或皮带腰包70)独立移动。例如,用户可以将控制器606保持在他或她的手中,或者控制器可以安装到用户的手或手臂(例如,作为戒指或手镯或作为用户佩戴的手套的一部分)。在一个或多个实施例中,手持控制器可以是在游戏场景中使用的图腾(例如,多自由度控制器)或者在ar环境中提供丰富的用户体验或者允许用户与ar系统的交互。在其它实施例中,手持控制器可以是触觉装置。在其它实施例中,电磁场发射器可以简单地结合为皮带腰包70的一部分。手持控制器606可以包括电池610或为该电磁场发射器602供电的其它电力供给。应当理解,电磁场发射器602还可以包括imu650部件或耦接到imu650部件,该imu650部件被配置为帮助确定电磁场发射器602相对于其它部件的定位和/或取向。在场发射器602和传感器(604)都是移动的情况下,这可能是特别有利的。如图6的实施例中所示,将电磁场发射器602放置在手持控制器而不是皮带腰包中,有助于确保电磁场发射器不会在皮带腰包处竞争资源,而是在手持控制器606处使用其自己的电池电源。在其它实施例中,电磁场发射器602可以设置在ar耳机上,并且传感器604可以设置在控制器606或皮带腰包70上。
在一个或多个实施例中,电磁传感器604可以连同诸如一个或多个imu或附加磁通量捕获线圈608的其它感测装置放置在用户的耳机上的一个或多个位置处。例如,如图6中所示,传感器(604,608)可以放置在头戴式耳机(58)的一侧或两侧。由于这些传感器设计得相当小(并且因此在一些情况下可能不太敏感),因此具有多个传感器可以提高效率和精度。在一个或多个实施例中,一个或多个传感器也可以放置在皮带腰包70或用户身体的任何其它部位上。传感器(604,608)可以无线地或通过蓝牙与计算设备通信,该计算设备确定传感器(以及其附接到的ar耳机)的姿势和取向。在一个或多个实施例中,计算设备可以驻留在皮带腰包70处。在其它实施例中,计算设备可以驻留在耳机本身处,或甚至驻留在手持控制器606处。在一个或多个实施例中,计算设备进而可以包括映射数据库(例如,可通行的世界模型、坐标空间等)以检测姿势,确定真实对象和虚拟对象的坐标,并且甚至可以连接到云资源和可通行的世界模型。
如上所述,传统的电磁发射器对于ar装置而言可能太笨重。因此,与传统系统相比,可以使用更小的线圈将电磁场发射器设计成紧凑的。然而,假设电磁场的强度随着远离场发射器的距离的三次函数而减小,则与诸如图4中详述的系统的传统系统相比,电磁传感器604和电磁场发射器602之间的较短半径(例如,约3至3.5英尺)可以降低功耗。
在一个或多个实施例中,该方面可以用于延长可以为控制器606和电磁场发射器602供电的电池610的寿命。或者,在其它实施例中,该方面可用于减小在电磁场发射器602处生成磁场的线圈的大小。然而,为了获得相同的磁场强度,可能需要增加功率。这允许紧凑的电磁场发射器单元602可以紧凑地配合在手持控制器606处。
当使用电磁跟踪系统用于ar装置时,可以进行若干其它改变。虽然该姿势报告率相当好,但ar系统可能需要更高效的姿势报告率。为此,可以(另外地或可替代地)在传感器中使用基于imu的姿势跟踪。有利地,imu可以保持尽可能稳定,以便提高姿势检测过程的效率。可以设计imu使得它们在至多50-100毫秒的时间保持稳定。应当理解,一些实施例可利用外部姿势估计器模块(例如,imu可随时间推移漂移),该外部姿势估计器模块可使得能够以10至20hz的速率报告姿势更新。通过使imu以合理的速率保持稳定,姿势更新的速率可以显著降低到10至20hz(与传统系统中的更高频率相比)。
如果电磁跟踪系统可以以例如10%的占空比运行(例如,每100毫秒仅对地面实况进行ping操作),这将是节省ar系统处功率的另一种方式。这意味着电磁跟踪系统每100毫秒中每10毫秒唤醒一次,以生成姿势估计。这直接转化为功耗节省,这进而可能影响ar装置的大小、电池寿命和成本。
在一个或多个实施例中,可以通过提供两个手持控制器(未示出)而不是仅仅一个手持控制器来策略性地利用占空比的该减小。例如,用户可能正在玩需要两个图腾等的游戏。或者,在多用户游戏中,两个用户可以具有他们自己的图腾/手持控制器来玩游戏。当使用两个控制器(例如,每只手的对称控制器)而不是一个控制器时,控制器可以在偏移(offset)占空比下操作。例如,相同的概念也可以应用于由玩多人游戏的两个不同用户使用的控制器。
现在参考图7,描述了描述ar装置的情况下的电磁跟踪系统的示例流程图。在702处,便携式(例如,手持)控制器发射磁场。在704处,电磁传感器(放置在耳机、皮带腰包等上)检测磁场。在706处,基于传感器处的线圈/imu的行为来确定耳机/皮带的姿势(例如,位置或取向)。在708处,将姿势信息传送到计算设备(例如,在皮带腰包或耳机处)。在710处,可选地,可以查阅映射数据库(例如,可通行的世界模型)以将真实世界坐标(例如,用于耳机/皮带的姿势的确定)与虚拟世界坐标相关联。在712处,虚拟内容可以在ar耳机处传递给用户并显示给用户(例如,经由在此描述的光场显示器)。应当理解,上述流程图仅用于说明目的,并且不应理解为限制。
有利地,使用类似于图6中概述的电磁跟踪系统的一个电磁跟踪系统使得姿势跟踪(例如,头部位置和取向,图腾的位置和取向,以及其它控制器的位置和取向)可行。与光学跟踪技术相比,这允许ar系统以更高的准确度和非常低的延迟来投影虚拟内容(至少部分地基于所确定的姿势)。
参考图8,示出了系统配置,其中以许多感测部件为特征。头戴式可穿戴部件(58)被示出可操作地耦接(68)到本地处理和数据模块(70),诸如皮带腰包,这里使用物理多芯引线,该物理多芯引线还以如下面参考图9a-9f所述的控制和快速释放模块(86)为特征。本地处理和数据模块(70)可操作地耦接(100)到手持部件(606),这里通过诸如低功率蓝牙的无线连接;手持部件(606)还可以诸如通过诸如低功率蓝牙的无线连接可操作地直接耦接(94)到头戴式可穿戴部件(58)。通常,在传递imu数据以协调各种部件的姿势检测的情况下,诸如在数百或数千周期/秒或更高的范围内,需要高频连接;诸如通过传感器(604)和发射器(602)配对,每秒数十个周期对于电磁定位感测可能是足够的。还示出了全局坐标系统(10),其代表用户周围的真实世界中的固定对象,诸如墙壁(8)。
云资源(46)还可以分别可操作地耦接(42,40,88,90)到本地处理和数据模块(70),到头戴式可穿戴部件(58),到可以耦接到墙壁(8)或相对于全局坐标系统(10)固定的其它项目的资源。耦接到墙壁(8)或具有相对于全局坐标系统(10)的已知位置和/或取向的资源可包括无线收发器(114)、电磁发射器(602)和/或接收器(604)、被配置为发射或反射给定类型的辐射的信标或反射器(112)(诸如红外led信标)、蜂窝网络收发器(110)、radar发射器或检测器(108)、lidar发射器或检测器(106)、gps收发器(118)、具有已知可检测图案的海报或标记(122)、以及相机(124)。
头戴式可穿戴部件(58)以与所示相似的部件为特征,除了被配置为辅助相机(124)检测器的照明发射器(130)(诸如用于红外相机(124)的红外发射器(130))之外;在头戴式可穿戴部件(58)上还具有一个或多个应变仪(116),其可固定地耦接到头戴式可穿戴部件(58)的框架或机械平台,并被配置为确定诸如电磁接收器传感器(604)或显示元件(62)的部件之间的这种平台的偏转,其中可以有价值地理解平台是否已经发生弯曲,诸如在平台的变薄部分处,诸如图8中所示的眼镜状平台上的鼻子上方的部分。
头戴式可穿戴部件(58)还以处理器(128)和一个或多个imu(102)为特征。每个部件优选地可操作地耦接到处理器(128)。示出了手持部件(606)和本地处理和数据模块(70),其以类似的部件为特征。如图8中所示,由于具有如此多的感测和连接工具,这种系统可能很重、耗电、大且相对昂贵。然而,出于说明性目的,可以利用这种系统来提供非常高水平的连接、系统部件集成和位置/取向跟踪。例如,采用这种配置,各种主要移动部件(58,70,606)可以使用wifi、gps或蜂窝信号三角测量在相对于全局坐标系的位置方面进行定位;信标、电磁跟踪(如在此所述)、radar和lidar系统可以提供更进一步的位置和/或取向信息和反馈。标记和相机也可用于提供关于相对和绝对位置和取向的进一步信息。例如,各种相机部件(124),诸如示为耦接到头戴式可穿戴部件(58)的那些相机部件,可以用于捕获可以在同时定位和建图协议或“slam”中使用的数据,以确定部件(58)所在的位置以及它如何相对于其它部件取向。
参考图9a-9f,描绘了控制和快速释放模块(86)的各个方面。参考图9a,两个外壳部件(132,134)使用磁耦接配置耦接在一起,该磁耦接配置可以采用机械闭锁来增强。可以包括用于相关联系统的操作的按钮(136),例如开/关按钮(圆形按钮)和上/下音量控制(三角形按钮)。模块86的相对端可以连接到在本地处理和数据模块(70)与显示器(62)之间运行的电引线,如图8中所示。
图9b示出了移除外壳(132)的局部剖视图,示出了按钮(136)和下面的顶部印刷电路板(138)。参考图9c,在移除按钮(136)和下面的顶部印刷电路板(138)的情况下,母触引脚阵列(140)是可见的。参考图9d,在移除壳体(134)的相对部分的情况下,下部印刷电路板(142)是可见的。在移除下部印刷电路板(142)的情况下,如图9e中所示,公触引脚阵列(144)是可见的。
参考图9f的横截面视图,公引脚或母引脚中的至少一个引脚被配置为弹簧加载的,使得它们可沿每个引脚的纵向轴线被压下;该引脚可以称为“弹簧引脚”,并且通常包括高导电材料,诸如铜或金。导电材料可以电镀到引脚上(例如,浸镀或电镀),并且导电材料的宽度在一些情况下可以是例如至少25μm的金。当组装时,所示的配置配对46个公引脚和46个对应的母引脚,并且整个组件可以通过手动拉开两个壳体(132,134)并克服磁性界面(146)负载来快速释放解耦,该磁性界面(146)负载是使用围绕引脚阵列(140,144)的周边取向的北极和南极磁体发展的。在一个实施例中,通过磁性界面(146)提供的约4kg的闭合维持力抵消了压缩46个弹簧引脚的大约2kg的负载。阵列中的引脚可以分开约1.3mm,并且引脚可以可操作地耦接到各种类型的导线,诸如双绞线或其它组合,以支持诸如usb3.0、hdmi2.0(用于数字视频)和i2s(用于数字音频)的接口,用于高速串行数据的最小化传输差分信号(tmds),通用输入/输出(gpio),和移动接口(例如,mipi)配置,电池/电源连接,以及在一个实施例中被配置为至多约4安培和5伏特的高电流模拟线路和接地。
在一个实施例中,磁性界面(146)通常是矩形的并且围绕引脚阵列(140,144)并且约1mm宽且4.8mm高。矩形磁体的内直径约为14.6mm。围绕公引脚阵列(144)的磁体可以具有第一极性(例如,北),并且围绕母引脚阵列(140)的磁体可以具有第二(相反)极性(例如,南)。在一些情况下,每个磁体包括北极和南极的混合,其中相对的磁体具有对应的相反极性,以提供磁吸引以帮助将壳体(132,134)保持在一起。
阵列(140,144)中的弹簧引脚具有4.0至4.6mm范围内的高度以及0.6至0.8mm的范围内的直径。阵列中的不同引脚可以具有不同的高度、直径和间距。例如,在一种实施方式中,引脚阵列(140,144)具有约42至50mm的长度,约7至10mm的宽度以及约5mm的高度。usb2.0和其它信号的引脚阵列的间距约为1.3mm,并且高速信号的引脚阵列的间距约为2.0至2.5mm。
参考图10,具有最小化的部件/特征组以能够减少或最小化各种部件的重量或体积并且达到相对纤薄的头戴式部件(例如,诸如图10中为特征的那个头戴式部件(58))可能是有帮助的。因此可以利用图8中所示的各种部件的各种排列和组合。
ar系统中的示例电磁感测部件
参考图11a,示出了电磁感测线圈组件(604,例如耦接到壳体的3个单独线圈),其耦接到头戴式部件(58);这种配置为整个组件增加了额外的几何形状,这可能是不希望的。参考图11b,并非如图11a的配置那样将线圈容纳在盒子或单个壳体604中,而是可以将各个线圈集成到头戴式部件(58)的各种结构中,如图11b中所示。图11b示出了用于x轴线圈(148)、y轴线圈(150)和z轴线圈(152)的在头戴式显示器58上的位置的示例。因此,感测线圈可以在空间上分布在头戴式显示器(58)上或周围,以通过电磁跟踪系统提供显示器(58)的定位和/或取向的所需空间分辨率或准确度。
图12a-12e示出了使用耦接到电磁传感器以增加场灵敏度的铁氧体磁芯1200a-1200e的各种配置。图12a示出了立方体形状的实心铁氧体磁芯1200a,图12b示出了配置为彼此间隔开的多个矩形磁盘的铁氧体磁芯1200b,图12c示出了具有单轴空气芯的铁氧体磁芯1200c,图12d示出了具有三轴空气芯的铁氧体磁芯1200d,并且图12e示出了在壳体(其可以由塑料制成)中包括多个铁氧体棒的铁氧体磁芯1200e。图12b-12e的实施例1200b-1200e的重量比图12a的实心磁芯实施例1200a重量上轻,并且可用于节省质量。尽管在图12a-12e中示出为立方体,但是在其它实施例中铁氧体磁芯的形状可以不同。
em跟踪系统的频分复用、时分复用和增益控制
传统的em跟踪解决方案通常利用频分复用(fdm)电路设计或时分复用(tdm)电路设计。然而,fdm设计通常使用更多电流,而tdm设计通常仅支持有限数量的用户。如下面进一步描述的,合并fdm和tdm设计的电路设计可以实现两者的益处。与传统设计相比,这种设计的优点可包括印刷电路板(pcb)的面积、材料成本、所用部件的数量和/或电流损耗上的节省。该设计还可以允许多个用户获得改进或最优性能。
图13a是示意性地示出频分复用的em发射器(tx)电路1302的示例的框图。em发射器电路可以在em跟踪系统中驱动三个调谐的正交线圈。由emtx生成的随时间变化的em场可以由em接收器感测(例如,参考图13b描述)。该电路使用主控制单元(mcu)控制以三个不同射频(rf)频率(f1、f2和f3)的三个不同合成器,其输出被滤波(例如,在带通滤波器(bpf)和可选的铁氧体磁珠(fb)处)并放大(例如,经由前置放大器(pa))并馈送到相应的x、y、z线圈。该电路还利用电流感测控制电路(r-感测(r-sense)和电流控制(currentctrl)),确保进入每个线圈的电流保持恒定。该电路还具有连接到mcu的rf无线通信接口(例如,蓝牙低能耗(ble)),其与参考图13b描述的em接收器单元通信。
图13b是示意性地示出频分复用的em接收器(rx)电路1304的示例的框图。em接收器使用三个正交线圈(以频率f1操作的x线圈,以频率f2操作的y线圈,以及以频率f3操作的z线圈)来接收由emtx电路1302生成的随时间变化的em信号(参见例如,图13a)。三个信号被单独放大(例如,经由前置放大器(pa))并且并行地滤波(例如,通过带通滤波器(bpf))。可选地,可以进一步放大滤波器输出。然后将放大的输出馈送到模-数(adc)中,并且数字信号由数字信号处理器(dsp)处理。dsp可以控制前置放大器的增益,以防止adc饱和。该接收器设计还具有连接到dsp(或mcu)的射频(rf)通信链路(例如,参考图13b描述),射频(rf)通信链路与em发射器通信。rf链路可以被配置为支持任何合适的无线标准,包括蓝牙低能耗(ble)。
图13a和图13b中所示的emtx和rx电路1302、1304(以及下面参考图13c-13j描述的tx和rx电路)可以用于em跟踪。例如,emtx电路1302可以用在em场发射器402中,并且emrx电路1304用在em场传感器404中,参考图4描述的。将描述emtx和rx电路的附加实施例,其提供诸如减少的部件数量、减小的pcb面积、较低的材料成本以及可以允许多个用户获得最优性能的优点。
图13c是示意性地示出是时分复用的em发射器电路1302的示例的框图。在该实施例中,图13a的fdm电路已经改变为时分复用电路。tdm电路仅使用一条路径,该路径被分成3个正交线圈。x、y和z线圈分别在频率f1、f2和f3下操作,以生成由em接收器电路接收的随时间改变的em场。tdm电路可以根据tdm时序协议在相应的时间t1、t2和t3操作这些线圈(参见例如图13f和图13g)。自动增益控制(agc)可以被包括在发射器电路中(下面参考图13i和13j进一步描述)。可以将每个线圈动态地频率调谐到由mcu分配的所需频率。
动态频率调谐
动态频率调谐可用于在每个线圈上实现谐振,以在emtx电路中获得增加的或最大的电流。动态频率调谐可用于适应多个用户。图13d是示意性地示出动态可调谐电路1306的示例的框图。参考图17d-17g描述动态可调谐电路1306的其它实施例。在图13d中所示的电路中,发射线圈由电感l1表示。静电电容器(c2)与可调谐电容器(c1)并联。在该示例中,由线圈通过调谐电容器c1生成的频率来覆盖16khz至30khz的频率范围。图13e是示出可以通过动态调谐图13d中所示的电路1306来实现的各种频率(从16khz至30khz)的谐振的示例的曲线图。为了适应多个用户,示例动态频率调谐电路可以利用每个用户一个发送(tx)频率。频率分配的示例如表1中所示。
表1
时分复用
在一些实施例中,为了在发射器上实现时分复用,可以利用发射器和接收器电路之间的同步。下面讨论两种可能的同步场景。
第一场景通过接收器和发射器二者的rf无线接口(例如,ble)来使用同步。无线rf链路可用于同步发射器和接收器二者的时钟。在实现同步之后,时分复用可以参考机载实时时钟(rtc)。
第二场景通过电磁脉冲来使用同步。em脉冲的飞行时间将明显短于tdm电路中通常使用的容差,并且可以忽略。txem脉冲由发射器发送到接收器,其计算接收器时钟和发射器时钟之间的时间差。该时间差作为已知偏移通过rf无线链路传送,或者用于调整无线接口(例如,ble)时钟上的参考。
在一些实施例中,可以实施这些同步场景中的一个或二者。在完成同步之后,可以建立用于发射器和接收器的tdm的时间序列。图13f示出了tdm时序图1308的示例。x线圈上的tx将在第一时间段保持开启,该第一时间段允许接收器的x、y和z线圈接收由x线圈生成的磁通量。在第一时间段期间,y线圈和z线圈上的tx基本上关闭(例如,线圈完全关闭或以比正常操作电压低得多(例如,<10%、<5%、<1%等)的电压操作。在x线圈传输之后,y线圈上的tx将开启(并且x线圈将基本上关闭,而z线圈保持基本上关闭),以及接收器的x、y和z线圈将接收由txy线圈生成的磁通量。在y线圈传输之后,z线圈上的tx将开启(并且y线圈将基本上关闭,而x线圈保持基本上关闭),以及接收器的x、y和z线圈将接收由txz线圈生成的磁通量。然后在em发射器操作时连续重复该时序序列。
以下描述了适应多个用户的非限制性的说明性示例。例如,为了适应至多具有两个发射器的四个用户,每个发射器需要八个tx频率。如果不重复这些频率通常是有利的。在这种实施例中,可以由em接收器实施扫描过程以确定特定频率是否正被紧密使用。图13g示出了扫描时序1310的示例。该扫描可以由em接收器1304在初始化时以及在用户会话期间周期性地完成。可以通过有意地关闭发射器1302中的tx并循环通过rx(在接收器1304中)来测量无意干扰的存在来执行扫描。如果确定在该频率处存在能量,则可以选择备用频率。通过监控三个正交线圈中的一个或两个(而不是全部三个)线圈,也可以缩短该扫描,因为在该槽中不需要位置和取向(pn0)。
图13h是示意性地示出em跟踪系统中的接收器1304的另一示例的框图。与图13b中所示的示例fdm接收器相比,tdm开关已经替换了来自三个正交线圈的各个路径。tdm开关可以由rf无线接口(例如,ble)控制。tdm开关可以利用图13f中所示的时序协议1308。
在各种实施例中,参考图13c-13h描述的时分复用tx和/或rx电路可以提供以下优点中的一个或多个。(a)电流消耗和电池寿命。通过时间复用发射器和接收器,可以降低使用的电流量。该减少来自如下事实:诸如发射器的高电流电路不再在100%的时间内被利用。与图13a和图13b中所示的fdm电路相比,系统的电流消耗可以减少到略微超过1/3。(b)材料成本清单。在上述tdm实施例中,用于实现相同结果的部件的数量已经减少(与图13a和图13b中的fdm电路相比)。通过相同的路径多路复用信号减少了部件数量,并且在该情况下,与fdm对应部件相比,部件的成本也应该降低到略微超过1/3。(c)pcb面积。部件减少的另一个好处是pcb面积中获得的节省。部件数量减少了近2/3,并且因此pcb上所需的空间减少。
其它可能的优点可以是减少质量的tx和rx电路。例如,图13a和图13b中所示的fdmtx和rx电路对于三个正交线圈中的每一个线圈利用单独的滤波器和放大器路径。相比之下,图13c和图13h中所示的tdmtx和rx电路共享滤波器和放大器路径。
除了移除传感器壳体和多路复用以节省硬件开销之外,可以通过具有多于一组的电磁传感器来增加信噪比,每组电磁传感器相对于单个较大的线圈组是相对较小。此外,可以改进通常需要具有紧密接近的多个感测线圈的低侧频率限制,以便于带宽需求的改进。通常存在与td多路复用的折衷,因为多路复用通常在时间上扩展rf信号的接收,这导致通常更嘈杂的信号;因此,较大的线圈直径可用于多路复用系统。例如,在多路复用系统可以利用9mm侧尺寸的立方线圈传感器盒的情况下,非多路复用系统可以仅利用7mm侧尺寸的立方线圈盒以获得类似的性能;因此,在最小化几何形状和质量以及在fdm和tdm电路的实施例之间进行选择可能存在折衷。
电磁跟踪系统的自动增益控制示例
参考图13a和图13b,fdm接收器(图13b)实施闭环增益控制,而fdm发射器(图13a)不实施增益控制并且被留下以其最大输出功率进行发射,而无论所接收的电平。可以通过dsp设置接收器的增益。例如,接收器线圈上的所接收的电压直接馈入到第一级中,该第一级具有增益控制。可以在dsp中确定大电压,并且dsp可以自动调节第一级的增益。将增益控制放置在接收器中可以利用发射器中的更多功率,即使在不需要时也是如此。因此,在发射器侧(而不是接收器侧)上采用自动增益控制(agc,有时也称为自适应增益控制)可能是有利的,这可以节省接收器系统中的空间(否则将用于agc),从而允许更小和更便携的接收器。
图13i是示意性地示出不利用自动增益控制(agc)的em接收器1304的示例的框图。第一级不再是agc电路(与图13b相比),并且接收器被设计为仅具有恒定增益。线圈上的所接收的电压的电平由dsp确定,并且dsp将该信息提供给无线(例如,ble)链路。该ble链路可以将该信息提供给发射器(参见图13j)以控制tx电平。
图13j是示意性地示出采用agc的em发射器1302的示例的框图。图13j的em发射器1302可以与图13i的接收器1304通信。无线链路(例如,ble)将(从接收器上的ble链路)接收的电压电平通信到mcu。放大级可以具有由mcu控制的可调节增益。当所需的接收电压很小时,这可以允许在发射器上节省电流。
因此,图13i和图13j中的rx和tx电路示例在em发射器1302而不是em接收器1304中采用agc。图13a和图13b中的rx和tx电路示例的这种改变可以允许更小的rx设计以及更节能的设计,因为必要时将允许降低tx功率。
用户头部姿势或手部姿势的em跟踪示例
参考图14,在一个实施例中,在用户给他或她的可穿戴计算系统加电之后(160),头戴式部件组件可以捕获imu和相机数据(例如,诸如在其中可能存在更多的原始处理马力的皮带腰包处理器处,用于slam分析的相机数据)的组合,以确定和更新相对于真实世界全局坐标系的头部姿势(例如,位置或取向)(162)。用户还可以激活手持部件以例如玩增强现实游戏(164),并且手持部件可以包括可操作地耦接到皮带腰包和头戴式部件中的一个或二者的电磁发射器(166)。一个或多个电磁场线圈接收器组(例如,一组是3个不同取向的单个线圈)耦接到头戴式部件以捕获来自发射器的磁通量,其可用于确定在头戴式部件和手持部件之间的位置或取向差异(或“差量(delta)”)(168)。有助于确定相对于全局坐标系的姿势的头戴式部件,以及有助于确定手持相对于头戴式部件的相对位置和取向的手持的组合,允许系统通常确定每个部件相对于全局坐标系在哪,并且因此优选地以相对低的延迟可以跟踪用户的头部姿势和手持姿势,用于使用手持部件的运动和旋转来呈现增强现实图像特征和交互(170)。
参考图15,示出了与图14的实施例有些类似的实施例,不同之处在于系统具有更多可用的感测装置和配置以帮助确定头戴式部件(172)和手持部件的姿势(176,178),使得可以优选地以相对低的延迟跟踪用户的头部姿势和手持姿势,用于使用手持部件的运动和旋转来呈现增强现实图像特征和交互(180)。
示例立体和飞行时间深度感测
参考图16a和图16b,示出了与图8的配置类似的配置的各个方面。图16a的配置与图8的配置的不同之处在于,除了lidar(106)类型的深度传感器之外,图16a的配置还以用于说明目的以通用深度相机或深度传感器(154)为特征,其例如可以是立体三角测量式深度传感器(诸如被动立体深度传感器、纹理投影立体深度传感器或结构光立体深度传感器)或时间或飞行式深度传感器(诸如lidar深度传感器或调制发射深度传感器);此外,图16a的配置具有附加的前向“世界”相机(124,其可以是灰度相机,具有能够具有720p范围分辨率的传感器)以及相对高分辨率的“图片相机”(156,例如其可以是全色相机,具有能够具有两百万像素或更高分辨率的传感器)。图16b示出了用于说明目的的图16a的配置的部分正交视图,如下面参考图16b进一步描述的。
返回参考图16a以及上面提到的立体与飞行时间式深度传感器,这些深度传感器类型中的每一个深度传感器类型可以与在此所公开的可穿戴计算解决方案一起使用,尽管每个都具有各种优点和缺点。例如,许多深度传感器具有黑表面和光泽或反射表面的挑战。被动立体深度感测是利用深度相机或传感器进行三角测量以计算深度的相对简单的方式,但如果需要宽视场(“fov”)并且可能需要相对重要的计算资源,则可能会受到挑战;此外,这种传感器类型可能具有带有边缘检测的挑战,这对于手头的特定用例可能是重要的。被动立体可能对无纹理墙壁、低光情况和重复图案构成挑战。被动立体深度传感器可从诸如英特尔和aquifi的制造商获得。具有纹理投影的立体(也称为“主动立体”)类似于被动立体,但是纹理投影仪将投影图案广播到环境上,并且广播的纹理越多,在用于深度计算的三角测量中可获得的准确度越高。主动立体也可能需要相对较高的计算资源,当需要宽fov时存在挑战,并且在检测边缘方面有些欠佳,但它确实解决了被动立体的一些挑战,因为它对无纹理墙壁有效,在低光上良好,并且通常不具有重复图案的问题。主动立体深度传感器可从诸如英特尔和aquifi的制造商获得。
具有结构光的立体,诸如由primesense公司开发并且以商品名kinect可用的系统,以及可从mantisvision公司获得的系统,通常利用单个相机/投影仪配对,并且投影仪的专门之处在于它被配置为广播先验已知的点图案。本质上,系统知道广播的图案,并且它知道要确定的变量是深度。这种配置在计算负载上可以是相对有效的,并且可以在宽fov需求场景以及具有从其它附近装置广播的环境光和图案的场景中受到挑战,但是在许多场景中可以非常有效和高效。采用调制的飞行时间式深度传感器,诸如可从pmd技术、a.g和softkinetic公司获得的那些深度传感器,发射器可以被配置为发出调幅光的波(诸如正弦波);可以在一些配置中位于附近或甚至重叠的相机部件在相机部件的每个像素上接收返回信号,并且可以确定/计算深度地图。这种配置在几何形状上可以相对紧凑,准确度高并且计算负荷低,但是可能在图像分辨率(诸如在对象的边缘处)、多路径误差(诸如其中传感器瞄准反射或有光泽的角落并且检测器最终接收多于一个的返回路径)方面有挑战,使得存在一些深度检测混叠。
直接飞行时间传感器(也可称为前述lidar)可从诸如luminar和advancedscientificconcepts公司的供应商获得。采用这些飞行时间配置,通常光脉冲(诸如皮秒、纳秒或飞秒的长脉冲光)发送出,以用该光脉冲沐浴围绕它取向的世界;然后,相机传感器上的每个像素等待该脉冲返回,并且知道光速,可以计算每个像素处的距离。这种配置可以具有调制的飞行时间传感器配置(没有基线、相对宽的fov、高准确度、相对低的计算负载等)以及相对高的帧速率(诸如成千上万赫兹)的许多优点。它们也可能相对昂贵,具有相对低的分辨率,对强光敏感,并且易受多径误差的影响;它们也可能相对大且重。
参考图16b,示出了部分顶视图,用于说明目的,其特征在于用户的眼睛(12)以及具有视场(28,30)的相机(14,诸如红外相机)和指向眼睛(12)以便于眼睛跟踪、观察和/或图像捕获的光源或辐射源(16,诸如红外线)。三个面向外的世界捕获相机(124)以其fov(18,20,22)示出,深度相机(154)及其fov(24)和图像相机(156)及其fov(26)也是如此。可以通过使用来自其它前向相机的重叠fov和数据来支持从深度相机(154)获得的深度信息。例如,系统可能最终得到诸如来自深度传感器(154)的子vga图像、来自世界相机(124)的720p图像、以及偶尔来自图片相机(156)的2百万像素彩色图像。这种配置具有共享公共fov的四个相机,其中的两个具有异构可见光谱图像,一个具有颜色,并且第三个具有相对低分辨率的深度。该系统可以被配置为在灰度和彩色图像中进行分割,融合这两者并从它们制作相对高分辨率的图像,获得一些立体对应,使用深度传感器来提供关于立体深度的假设,并使用立体对应来获得更精确的深度地图,该深度地图可能明显优于仅从深度传感器获得的深度地图。这种过程可以在本地移动处理硬件上运行,或者可以使用云计算资源运行,也可以与该区域中其他人(诸如彼此坐在桌子对面的两个人)的数据一起运行,并且最后得到相当精细的地图。在另一个实施例中,所有上述传感器可以组合成一个集成传感器以实现这种功能。
用于em跟踪的传输线圈的动态调谐示例
参考图17a-17g,示出了用于电磁跟踪的动态传输线圈调谐配置的各方面,以便于传输线圈在每个正交轴的多个频率下最优地操作,这允许多个用户在同一系统上操作。通常,电磁跟踪发射器将被设计为在每个正交轴的固定频率下操作。采用这种方法,每个传输线圈都使用静态串联电容进行调谐,该静态串联电容仅在操作频率下产生谐振。这种谐振允许最大可能的电流流过线圈,这进而使生成的磁通量最大化。图17a示出了用于在固定操作频率下产生谐振的典型谐振电路1305。电感“l”表示具有1mh电感的单轴传输线圈,并且电容设置为52nf,在22khz处产生谐振,如图17b中所示。图17c示出了相对于频率绘制的通过图17a的电路1305的电流,并且可以看出电流在谐振频率处是最大的。如果预期该系统在任何其它频率下操作,则操作电路将不会处于可能的最大电流(其发生在22khz的谐振频率下)。
图17d示出了用于电磁跟踪系统的发射器1302的发射器电路1306的动态可调谐配置的实施例。图17d中所示的示例电路1306可以用在在此描述的em场发射器402、602、1302的实施例中。图17d中的电路包括振荡电压源1702、发射(tx)线圈、高压(hv)电容器和电容器组1704中的多个低压(lv)电容器,该电容器可被选择以对于所需的谐振频率提供调谐。可以设置动态频率调谐以在线圈上实现谐振(在所需的动态可调节的频率下)以获得最大电流。图17e中示出了动态可调谐电路1306的另一示例,其中可调谐电容器1706(“c4”)可被调谐以产生不同频率下的谐振,如图17f中所示的模拟数据中所示。调谐可调谐电容器可以包括在多个不同电容器之间切换,如图17d中所示电路中示意性示出的。如图17e的实施例中所示,电磁跟踪器的正交线圈中的一个被模拟为电感“l”,而静态电容器(“c5”)是固定的高压电容器。由于谐振,该高压电容器将看到更高的电压,并且因此其封装大小通常会更大。电容器c4将是以不同值动态切换的电容器,并且因此可以看到较低的最大电压,并且通常是较小的几何封装以节省放置空间。电感l3也可用于微调谐振频率。
图17f示出可由图17e的电路1306实现的谐振的示例。在图17f中,较高的曲线(248)示出了电容器c5两端的电压vmid-vout,而较低的曲线(250)示出了电容器c4两端的电压vout。随着c4的电容变化,谐振频率改变(在该示例中在约22khz和30khz之间),并且值得注意的是,c5两端的电压(vmid-vout;曲线248)高于c4两端的电压(vout;曲线250)。这通常将允许c4上的较小封装部件,因为该电容器的多个电容器通常将用于系统中,例如,每个谐振操作频率一个电容器(参见例如图17d中所示的电容器组1704中的多个lv电容器)。图17g是电流与频率的曲线,示出无论电容器两端的电压如何,所达到的最大电流都遵循谐振。因此,动态可调谐电路的实施例可以横跨多个频率在发射器线圈中提供增加的或最大的电流,从而允许单个em跟踪系统的多个用户的改进或优化的性能。
em跟踪系统的音频噪声消除示例
音频扬声器(或任何外部磁体)可以产生磁场,该磁场可以无意地干扰由em跟踪系统的em场发射器产生的磁场。这种干扰会劣化由em跟踪系统提供的位置估计的准确性或可靠性。
随着ar装置发展,它们变得更加复杂并且集成了必须共存并独立执行的更多技术。em跟踪系统依赖于(通过em传感器)接收的(由em场发射器生成)磁通量的微小变化以确定em传感器的3-d位置(并且从而确定传感器所附接或结合的对象的3-d位置)。驻留在em跟踪传感器线圈附近的音频扬声器可以发出磁通量,该磁通量可干扰em跟踪系统计算真实位置的能力。
参考图18a-18c,电磁跟踪系统可以被限制在大约30khz以下工作,这略高于人类听觉的可听范围。图18a示出了音频扬声器1820紧邻em传感器604的配置。音频扬声器1820由随时间改变的电压源1822和放大器1824驱动。扬声器1820的磁场可能导致对em跟踪系统的无意磁场干扰,因为扬声器在由em传感器604的线圈感测的磁场中生成噪声。在一些实施方式中,可以增加音频扬声器1820和em传感器604之间的距离以减少接收的干扰。但是因为来自扬声器的磁通量与距传感器的距离的立方(1/r3)衰减,所以将存在大距离上提供干涉中非常小的衰减的点。音频扬声器(例如,图2a-2d中所示的扬声器66)将通常用于ar装置中,以向ar装置的佩戴者提供音频体验;因此,音频扬声器相对靠近也设置在ar装置上的em传感器可能是常见的(例如,参见图11a中所示的示例可穿戴显示装置58中设置在扬声器66附近的em传感器604)。来自音频扬声器的磁场可能干扰由em跟踪系统的em传感器感测的em场。
参考图18a,可能存在一些音频系统,该音频系统在用于这种电磁跟踪系统的可用频率中产生噪声。此外,音频扬声器通常具有磁场和一个或多个线圈,这也可能干扰电磁跟踪系统。参考图18b,示出了用于电磁跟踪系统的噪声消除系统1830的示例的框图。由于无意的em干扰是已知实体(因为由电压源1822提供给音频扬声器1820的信号是已知的或可以被测量),所以该知识可用于消除来自音频扬声器1820的em干扰并提高em跟踪系统的性能。换句话说,由系统生成的音频信号可用于消除由em传感器604的线圈接收的来自扬声器的磁干扰。如图18b中示意性所示,噪声消除电路1830可被配置为接受来自em传感器604的损坏信号1850a以及来自音频系统的信号1850b。噪声消除系统可以组合信号1850a、1850b以抵消从音频扬声器1820接收的干扰并提供未损坏的传感器信号1850c。
图18c是示出如何将音频信号1850b反转并添加到损坏的传感器信号1850a以消除干扰并提供基本上未损坏的传感器信号1850c的说明性非限制性示例的曲线。顶部曲线v(噪声)是由音频扬声器1820添加到em跟踪系统的噪声信号1850b。底部曲线v(抵消)是反相音频信号(例如,-v(噪声)),当这些加在一起时,效果是没有来自音频的噪声降低。换句话说,噪声消除系统接收损坏的信号1850a,该信号1850a是真实的em传感器信号、表示来自em发射器线圈的信号的v(传感器)和噪声信号的总和:v(传感器)+v(噪声)。通过将反转音频信号-v(噪声)添加到损坏信号1850a,恢复未损坏信号v(传感器)1850c。未损坏的信号1850c反映传感器604的响应,如同音频扬声器604不存在并且因此反映传感器604的位置处的em发射器场。等效地,可以从损坏的信号1850a中减去噪声信号1850b,以恢复未损坏的信号v(传感器)1850c。噪声消除可导致基本上消除全部(例如,>80%、>90%、>95%或更多)噪声信号(例如,来自音频扬声器)。该噪声消除技术不仅限于消除音频扬声器噪声,而且如果可以确定噪声信号的测量(或估计)(使得它可以如上所述从em传感器信号中移除)则可以应用于对em传感器信号干扰的其它噪声源。
图18d是示出用于消除em跟踪系统中的em传感器所接收的干扰的示例方法1800的流程图。方法1800可以由ar装置中的硬件处理器(诸如例如本地处理和数据模块70)或者由em跟踪系统中的硬件处理器执行。在框1802处,该方法从电磁传感器接收噪声信号。如上所述,噪声信号可由来自附近音频扬声器的干扰引起,该附近音频扬声器生成电磁干扰。在框1804处,该方法从em干扰的源接收信号。例如,信号可以是用于驱动音频扬声器的信号1850b(参见例如图18b)。在框1806处,组合有噪声信号和干扰信号以获得去噪声em信号。例如,可以反转干扰信号并将其添加到有噪声信号,或者可以从有噪声信号中减去干扰信号。在框1808处,去噪声信号可用于确定em传感器的位置。使用去噪声信号获得的位置(与使用有噪声信号相比)更准确可靠。
因此,前述提供了一种方法,以移除由em跟踪器传感器附近的音频扬声器产生的无意噪声。该方法采用噪声消除方法,该噪声消除方法使用关于音频的已知信息将其从em跟踪信号中移除。当不能实现音频扬声器和em传感器线圈的充分物理分离时(使得干扰足够低),可以使用该系统。尽管在上文中,干扰噪声已被描述为由音频扬声器生成,但这仅用于说明而非限制。前述实施例可以应用于可以测量的任何干扰信号,并且然后从损坏的传感器信号中减去。
视觉系统的示例校准
参考图19,在一个实施例中,可利用光或其它发射器的已知图案1900(诸如圆形图案)来辅助视觉系统的校准。例如,圆形图案可以用作基准;当具有已知取向的相机或其它捕捉装置捕获图案的形状,同时重新定向耦接到图案的对象时,可以确定对象(诸如手持图腾装置606)的取向;可以将这种取向与来自对象(例如,图腾)上的相关联imu的取向进行比较,以用于误差确定和校准中的使用。进一步参考图19,光1900的图案可以由手持图腾606(在图19中示意性地表示为圆柱)上的光发射器(例如,多个led)产生。如图19中所示,当由ar耳机58上的相机正面观看图腾时,光1900的图案呈圆形。当图腾606以其它取向倾斜时,图案1900看起来是椭圆形的。可以使用计算机视觉技术识别光1900的图案,并且可以确定图腾606的取向。
在各种实施方式中,增强现实装置可以包括计算机视觉系统,该计算机视觉系统被配置为实施一种或多种计算机视觉技术以识别光的图案(或执行在此使用或描述的其它计算机视觉过程)。计算机视觉技术的非限制性示例包括:尺度不变特征变换(sift)、加速鲁棒特征(surf)、定向fast和旋转brief(orb)、二进制鲁棒不变可缩放关键点(brisk)、快速视网膜关键点(freak)、viola-jones算法、eigenfaces方法、lucas-kanade算法、horn-schunk算法、mean-shift算法、视觉同时定位和地图构建(vslam)技术、顺序贝叶斯估计(例如,卡尔曼滤波器、扩展卡尔曼滤波器等)、光束法平差、自适应阈值化(和其它阈值化技术)、迭代最近点(icp)、半全局匹配(sgm)、半全局块匹配(sgbm)、特征点直方图、各种机器学习算法(诸如例如支持矢量机、k-最近邻算法、朴素贝叶斯、神经网络(包括卷积或深度神经网络),或其它有监督/无监督模型等)等等。
可穿戴显示装置的子系统的示例电路
参考图20a-20c,示出了具有求和放大器2002的配置,以简化可穿戴计算配置的两个子系统或部件(诸如头戴式部件和皮带腰包部件)之间的电路。采用传统配置,电磁跟踪传感器604的每个线圈2004(在图20a的左侧)与放大器2006相关联,并且三个不同的放大信号可以通过求和放大器2002和电缆发送到另一个部件(例如,如图20b中所示的处理电路)。在所示的实施例中,三个不同的放大信号可以被引导到求和放大器2002,该求和放大器2002产生被向下引导到有利地简化的电缆2008的一个放大信号,并且每个信号可以处于不同的频率。求和放大器2002可以被配置为放大由放大器接收的所有三个信号;然后(如图20b中所示)在模数转换之后,接收数字信号处理器在另一端分离信号。可以使用增益控制。图20c示出了针对每个频率(f1、f2和f3)的滤波器-因此可以在这种阶段将信号分离回来。可以通过计算算法来分析这三个信号(例如,确定传感器姿势),并且ar系统可以使用位置或取向结果(例如,基于用户的瞬时头部姿势向用户正确地显示虚拟内容)。
em跟踪系统更新示例
参考图21,在便携式系统的功率方面,电磁(“em”)跟踪更新可能相对“昂贵”,并且可能不能进行非常高频率的更新。在“传感器融合”配置中,可以组合来自诸如imu的另一传感器的更频繁更新的定位信息以及来自诸如光学传感器(例如,相机或深度相机)的另一传感器的数据,该光学传感器可以处于或者可以不处于相对较高的频率;融合所有这些输入的网络对em系统提出了较低的要求,并提供了更快的更新。
返回参考图11b,示出了用于ar装置58的分布式传感器线圈配置。参考图22a,如上所述,具有单个电磁传感器装置(604)的ar装置58,单个电磁传感器装置(604)诸如包含三个正交感测线圈(一个正交感测线圈用于x、y、z的每个方向)的壳体可以耦接到可穿戴部件(58)用于6个自由度跟踪。同样如上所述,这种装置可以是分离的,其中三个子部分(例如,线圈)附接在可穿戴部件(58)的不同位置处,如图22b和图22c中所示。参考图22c,为了提供进一步的设计备选方案,每个单独的传感器线圈可以用一组类似取向的线圈代替,使得对于任何给定的正交方向的总磁通量由一组(148,150,152)而不是每个正交方向的单个线圈捕获。换句话说,对于每个正交方向而不是一个线圈,可以利用一组较小的线圈,并且它们的信号被聚集以形成该正交方向的信号。在另一个实施例中,其中特定系统部件,诸如头戴式部件(58)以两个或多个电磁线圈传感器组为特征,该系统可以被配置为选择性地利用彼此最接近(例如,在1厘米、2厘米、3厘米、4厘米、5厘米或10厘米内)的传感器和发射器配对,以改善或优化系统的性能。
重新校准可穿戴显示系统的示例
参考图23a-23c,重新校准诸如在此所讨论的可穿戴计算系统可能是有用的,并且在一个实施例中,发射器处生成的声学(例如,超声波)信号以及接收器处的声学传感器(例如,麦克风)和声学飞行时间计算可以用于确定发射器和接收器之间的声音传播延迟,并且从而确定发射器和接收器之间的距离(因为声速已知)。图23a示出了在一个实施例中,发射器上的三个线圈用脉冲串(burst)正弦波激励,同时超声换能器可以用脉冲串正弦波激励,优选地与线圈之一相同的频率。图23b示出了em接收器可以被配置为使用x、y、z传感器线圈接收三个em波,并且使用麦克风(mic)接收声学超声波。可以根据三个em信号的幅度计算总距离。可以通过将声学(麦克风)响应的时序2302与em线圈的响应2304进行比较来计算飞行时间(声音传播延迟时间2300)(参见例如图23c)。这也可以用于计算距离。将电磁计算的距离与声学延迟时间2300进行比较可以用于校准emtx或rx电路(例如,通过校正因子)。
参考图24a,在另一个实施例中,在以照相机为特征的增强现实系统中,可以通过在诸如手持控制器(例如,控制器606)的另一装置上测量已知大小对准特征(在图24a中描绘为箭头)的像素大小来计算距离。
参考图24b,在另一个实施例中,在以深度传感器(诸如红外(“ir”)深度传感器)为特征的增强现实系统中,该距离可以由这种深度传感器计算并直接报告给控制器。
参考图24c和图24d,一旦知道总距离,可以使用相机或深度传感器来确定空间中的位置。增强现实系统可以被配置为将一个或多个虚拟对准目标投射到用户。用户可以将控制器与目标对准,并且系统可以根据em响应以及根据虚拟目标的方向加上先前计算的距离二者来计算位置。可以通过将控制器上的已知特征与投射给用户的虚拟目标对准来完成滚动角校准;可以通过向用户呈现虚拟目标并且让用户将控制器上的两个特征与目标对准(非常像瞄准步枪)来校准偏航角和俯仰角。
参考图25a和图25b,可能存在与em跟踪系统相关联的固有模糊性:接收器将在发射器周围的两个对角相对的位置中生成类似的响应。例如,图25a示出了手持装置606和生成类似响应的重影(ghost)装置606a。这种挑战在其中发射器和接收器二者可以相对于彼此移动的系统中特别相关。
在一个实施例中,系统可以使用imu传感器来确定用户是否在参考(例如,对称)轴的正侧或负侧。在诸如上述以世界相机和深度相机为特征的实施例的实施例中,系统可以使用该信息来检测手持部件(例如,图25b中的手持装置2500)是否在参考轴的正侧或负侧;如果手持装置2500在相机和/或深度传感器的视场之外,则系统可以被配置为决定(或者用户可以决定)手持部件2500直接位于用户后面的180度区域中,例如,如图25b中所示的重影位置2500a处。
返回参考上述实施例,其中向外的相机装置(124,154,156)耦接到诸如头戴式部件(58)的系统部件,可以使用从这些相机装置收集的信息,使用诸如同时定位和地图构建或“slam”技术(也称为并行跟踪和地图构建,或“ptam”技术)的技术来确定耦接到这种头戴式部件(58)的头部的位置和取向。实时或接近实时(例如,优选地具有低延迟的确定和更新)理解用户头部的位置和取向(也称为用户的“头部姿势”)在确定用户在他或她周围的实际环境内的位置以及如何相对于用户和与用户的增强或混合现实体验相关的环境放置和呈现虚拟内容是有价值的。典型的slam或ptam配置涉及从输入图像信息中提取特征并使用它来三角测量3-d映射点,并且然后跟踪这些3-d映射点。slam技术已经在许多实施方式中被利用,诸如在自动驾驶汽车中,其中计算、功率和感测资源与板载可穿戴计算装置(诸如头戴式部件(58))上可用的那些计算、功率和感测资源相比可能相对丰富。
经由相机特征的提取进行姿势计算和位置映射的示例
参考图26,在一个实施例中,可穿戴计算装置(诸如头戴式部件(58))可包括两个面向外的相机,产生两个相机图像(左-204,右-206)。在一个实施例中,相对轻便、便携且功率高效的嵌入式处理器(诸如由
在充分远离原始的一组映射点(202)移动之后,一个或两个相机图像(204,206)可能开始丢失新传入图像中的映射点(例如,如果用户的头部在空间中向右旋转,则原始映射点可能开始向左消失,并且可能只出现在左图像中,并且然后根本没有更多旋转)。一旦用户旋转离原始的一组映射点太远,系统可以被配置为创建新的映射点,诸如通过使用类似于上述过程的过程(检测特征,创建新的映射点)-这是系统如何配置以保持填充地图的示例。在一个实施例中,该过程可以每10到20帧重复一次,这取决于用户相对于他的环境平移和/或旋转他的头部多少,并且从而平移和/或旋转相关联的相机。与新创建的映射点相关联的帧可以被视为“关键帧”,并且系统可以被配置为采用关键帧来延迟特征检测过程,或者可替代地,可以对每个帧进行特征检测以尝试建立匹配,并且然后当系统准备好创建新的关键帧时,系统已经完成了相关联的特征检测。因此,在一个实施例中,基本范例是开始创建地图,并且然后跟踪、跟踪、跟踪,直到系统需要创建另一个地图或其附加部分为止。
参考图27,在一个实施例中,基于视觉的姿势计算可以被分成5个阶段(例如,预跟踪216、跟踪218、低延迟映射220、延迟容受映射222、后映射/清除224)以帮助用于嵌入式处理器配置的精确度和优化,嵌入式处理器配置的计算、功率和感测资源可能受限。基于视觉的姿势计算可以由本地处理和数据模块70或远程处理和数据模块72、74执行。
关于预跟踪(216),系统可以被配置为在图像信息到达之前识别哪些映射点投影到图像中。换句话说,系统可以被配置为识别哪些映射点将投射到图像中,假定系统知道用户之前在哪里,并且具有用户正在去哪里的感觉。下面进一步讨论“传感器融合”的概念,但是这里值得注意的是,系统可以从传感器融合模块或功能获得的输入之一可以是“后估计”信息,以相对快速率,诸如来自惯性测量单元(“imu”)或其它传感器或装置的250hz(这是相对于例如30hz的高速率,在该频率处,基于视觉的姿势计算操作可以提供更新)。因此,相对于基于视觉的姿势计算,可以存在从imu或其它装置导出姿势信息的更精细的时间分辨率;但是值得注意的是,来自诸如imu的装置的数据往往有些噪声并且易受姿势估计漂移的影响,如下所述。对于相对短的时间窗口,诸如10-15毫秒,imu数据在预测姿势方面可能非常有用,并且再次,当与传感器融合配置中的其它数据组合时,可以确定优化的总体结果。
来自传感器融合模块或功能的姿势信息可以被称为“姿势先验”,并且系统可以利用该姿势先验来估计哪些组点将投射到当前图像中。因此,在一个实施例中,系统被配置在“预跟踪”步骤(216)中来预提取这些映射点并进行一些有助于减少整体处理的延迟的预处理。每个3-d映射点可以与描述符相关联,使得系统可以唯一地识别它们并将它们匹配到图像中的区域。例如,如果给定的映射点使用其周围有补丁(patch)的特征来创建,则系统可以配置为保持该补丁的一些外观以及映射点,使得当看到映射点投射到其它图像上时,系统可以回顾用于创建地图的原始图像,检查补丁相关性,并确定它们是否是相同的点。因此,在预处理中,系统可以被配置为执行一些量的映射点的提取,以及和与那些映射点相关联的补丁相关联的一些量的预处理。因此,在预跟踪(216)中,系统可以被配置为预提取映射点,并且预扭曲图像补丁(可以完成图像的“扭曲”以确保系统可以将与映射点相关联的补丁与当前图像匹配;扭曲是确保所比较的数据兼容的一种方法的示例)。
返回参考图27,跟踪阶段可以包括若干成分,诸如特征检测、光流分析、特征匹配和姿势估计。在检测输入图像数据中的特征时,系统可以被配置为通过尝试跟随来自一个或多个先前图像的特征来利用光流分析以节省特征检测中的计算时间。一旦在当前图像中识别出特征,系统可以被配置为尝试将特征与投影的映射点匹配-这可以被认为是配置的“特征匹配”部分。在预跟踪阶段(216)中,系统优选地已经识别出哪些映射点是感兴趣的并且提取它们;在特征映射中,它们被投影到当前图像中,并且系统会尝试将它们与特征匹配。特征映射的输出是一组2-d到3-d对应关系,并且在手中,系统被配置为估计姿势。
当用户跟踪耦接到头戴式部件(58)的他的头部时,系统优选地被配置为识别用户是否正在查看环境的新区域,以确定是否需要新关键帧。在一个实施例中,对是否需要新关键帧的这种分析几乎可以纯粹基于几何形状;例如,系统可以被配置为查看从当前帧到剩余的关键帧的距离(平移距离;也是视场捕获重定向-用户的头部可以接近平移但是重新定向,使得例如可能需要全新的映射点)。一旦系统确定应该插入新的关键帧,就可以开始映射阶段。如上所述,系统可以被配置为将映射操作为三种不同的操作(低延迟映射、延迟容受映射、后/映射或清除),而不是在传统slam或ptam操作中更可能看到的单个映射操作。
可以以简单形式被视为三角测量和新映射点的创建的低延迟映射(220)是关键阶段,其中系统优选地被配置为立即进行这种阶段,因为在此讨论的跟踪范例依赖于映射点,其中系统仅在有可用于跟踪的映射点时找到位置。“低延迟”定名指的是对无故延迟没有容受的概念(换句话说,映射的该部分需要尽快进行或者系统具有跟踪问题)。
可以以简单形式将延迟容受映射(222)视为优化阶段。整个过程并不绝对需要低延迟来进行称为“束调节”的操作,这提供了全局优化的结果。该系统可以被配置为检查3-d点的位置以及从哪观察到它们。在创建映射点的过程中,有许多错误可以链接在一起。束调节过程可以采取例如从两个不同视图位置观察到的特定点,并使用所有该信息来更好地感知实际的3-d几何形状。结果可以是3-d点以及计算的轨迹(例如,捕获相机的位置、路径)可以被少量调节。期望进行这些类型的过程以通过映射/跟踪过程不累积错误。
后映射/清除(224)阶段是其中系统可以被配置为移除地图上不在映射和跟踪分析中提供有价值信息的点的阶段。在该阶段中,将移除不提供有关场景的有用信息的这些点,并且这种分析有助于保持整个映射和跟踪过程可伸缩。
在视觉姿势计算过程期间,存在这种假设:面向外相机正在观看的特征是静态特征(例如,相对于全局坐标系不是逐帧移动)。在各种实施例中,可以利用语义分割和/或对象检测技术从相关场移除移动对象,诸如人、移动车辆等,使得不从各种图像的这些区域提取用于映射和跟踪的特征。在一个实施例中,可以利用深度学习技术(诸如下面描述的那些技术)来分割出这些非静态对象。
传感器融合的示例
参考图28a-28f,传感器融合配置可以用于受益于来自具有相对高的更新频率的传感器的一个信息源(诸如以诸如250hz的频率与头部姿势相关的imu更新陀螺仪、加速度计和/或磁力计数据)和以较低频率(诸如以诸如30hz的频率更新的基于视觉的头部姿势测量过程)更新的另一信息源。在各种实施例中,较高频率传感器数据处于高于100hz的频率,并且较低频率传感器数据处于低于100hz的频率。在一些实施例中,较高频率传感器数据处于大于较低频率传感器获取数据的频率的3倍、5倍、10倍、25倍、100倍或大于该较低频率传感器获取数据的频率的频率。
参考图28a,在一个实施例中,系统可以被配置为使用扩展卡尔曼滤波器(ekf,232)并跟踪关于装置的大量信息。例如,在一个实施例中,它可以考虑32个状态,诸如角速度(例如,来自imu陀螺仪)、平移加速度(例如,来自imu加速度计)、imu自身的校准信息(例如,陀螺仪和加速度计的坐标系和校准因子;imu还可以包括一个或多个磁力计)。因此,系统可以被配置为以相对高的更新频率(226)(诸如250hz)接收imu测量,以及以较低更新频率(例如,计算的视觉姿势测量、量距数据等)接收来自一些其它源的数据,例如以诸如30hz的更新频率的视觉姿势测量(228)。
每次ekf获得一轮imu测量时,系统可以被配置为对角速度信息进行积分以获得旋转信息(例如,角速度的积分(旋转位置随时间推移变化的变化)是角位置(角位置的变化));同样地,对于平移信息(换句话说,通过进行平移加速度的双重积分,系统将获得位置数据)。通过这种计算,系统可以被配置为以来自imu的高频率(例如,在一个实施例中为250hz)从头部获得6个自由度(dof)姿势信息(在x、y、z中的平移;三个旋转轴的取向)。每次完成积分时,噪声都会累积在数据中;对平移或旋转加速度进行双重积分可以传播噪声。通常,系统被配置为不依赖于这种数据,该数据由于噪声而在很长的时间窗口内(诸如在一个实施例中任何长于约100毫秒)容易“漂移”。来自视觉姿势测量(228)的输入较低频率(例如,在一个实施例中以约30hz更新)数据可用于与ekf(232)作为校正因子操作,产生校正输出(230)。
参考图28b-28f,为示出来自较高更新频率的一个源的数据如何与来自较低更新频率的另一个源的数据组合,示出了来自较高频率(诸如250hz)的imu的第一组点(234),其中点(238)从视觉姿势计算过程以较低频率(诸如30hz)进入。系统可以被配置为当这种信息可用时校正(242)到视觉姿势计算点,并且然后从imu数据(236)继续前进更多点,并从视觉姿势计算过程中可用的另一点(240)继续进行另一次校正(244)。可以使用ekf将视觉姿势数据的“更新”应用于来自imu的数据的“传播”。
值得注意的是,在一些实施例中,来自第二源的数据(例如,诸如视觉姿势数据)不仅可以以较低的更新频率进入,而且还具有一些延迟-意味着系统优选地被配置为当来自imu的信息和视觉姿势计算被集成时导航时域调节。在一个实施例中,为了确保系统在imu数据中的正确时域位置处的视觉姿势计算输入中融合,可以维持imu数据的缓冲器,以返回到imu数据中的时间(例如“tx”)进行融合并计算与视觉姿势计算的输入相关的时间的“更新”或调节,并且然后考虑前向传播到当前时间(例如“tcurrent”)中的那个“更新”或调节,其在调节的位置和/或取向数据与来自imu的最新数据之间留下间隙。为了确保在呈现给用户时没有太多的“跳跃”或“抖动”,系统可以被配置为使用平滑技术。解决该问题的一种方法是使用加权平均技术,该加权平均技术可以是线性、非线性、指数等,以最终将融合数据流向下驱动到调节路径。
参考图28c,例如可以在t0和t1之间的时域上利用加权平均技术来从未调节路径(252;例如,直接从imu)驱动到调节路径(254;例如,基于来自视觉姿势计算过程的数据)的信号;图28d中示出了一个示例,其中示出了融合结果(260),其从未调节路径(252)和时间t0开始并且以指数方式移动到调节路径(254)达t1。参考图28e,示出了一系列校正机会,其中融合结果(260)的指数时域校正从每个序列中的上部路径朝向下部路径(第一校正是从第一路径252,例如从imu,到第二路径254,例如从基于视觉的姿势计算;然后使用连续的imu数据,继续相似的模式向前,同时使用每个传入基于视觉的姿势计算点,基于来自视觉姿势的连续点,在该示例中向下朝向连续校正的下部路径256、258来校正)。参考图28f,在“更新”或校正之间具有足够短的时间窗口,整体融合结果(260)在功能上可以被感知为相对平滑的图案化结果(262)。
在其它实施例中,不是直接依赖于视觉姿势测量,而是系统可以被配置为检查导数ekf;换句话说,系统不是直接使用视觉姿势计算结果,而是使用从当前时间到之前时间的视觉姿势变化。例如,如果视觉姿势差异中的噪声量远小于绝对视觉姿势测量中的噪声量,则可以追求这种配置。优选的是不具有抛弃融合结果的瞬时错误,因为所有这些的输出都是姿势,该这些的输出作为“姿势先验”值被发送回视觉系统。
尽管某些实施例使用ekf,但是其它实施例可以使用不同的估计算法,诸如例如无迹卡尔曼滤波器、线性卡尔曼滤波器、贝叶斯模型、隐马尔可夫模型、粒子滤波器、顺序蒙特卡罗模型或其它估计技术。
姿势服务示例
姿势结果的基于外部系统的“消费者”可以被称为“姿势服务”,并且系统可以被配置为使得所有其它系统部件在任何给定时间请求姿势时进入姿势服务。姿势服务可以被配置为队列或堆栈(例如,缓冲器),具有用于时间片序列的数据,一端具有最近数据。如果姿势服务的请求是当前姿势或处于缓冲器中的某个其它姿势,则可以立即输出;在某些配置中,姿势服务将接收以下请求:从现在开始向前20毫秒的姿势是什么(例如,在视频游戏内容渲染场景中-相关服务可能需要知道从现在开始,它需要在将来略微渲染某个位置和/或取向中的东西)。在用于产生未来姿势值的一个模型中,系统可以被配置为使用恒定速度预测模型(例如,假设用户的头部以恒定速度和/或角速度移动);在用于产生未来姿势值的另一模型中,系统可以被配置为使用恒定加速度预测模型(例如,假设用户的头部以恒定加速度平移和/或旋转)。可以利用数据缓冲器中的数据来推断姿势将使用这种模型的位置。与恒定速度模型相比,恒定加速度模型使用稍长的尾部进入缓冲器的数据用于预测,并且我们已经发现本系统可以预测到未来20毫秒的范围而没有显著劣化。因此,在可用于输出姿势的数据方面,姿势服务可被配置为具有在时间上回溯以及向前约20毫秒或更多的数据缓冲器。在操作上,内容操作通常将被配置为识别下一帧绘制何时将要及时进行(例如,它将尝试在时间t或者在时间t+n处绘制,n是姿势服务提供的下一个更新数据间隔)。
可利用面向用户的(例如,面向内的,诸如朝向用户的眼睛)相机(诸如图16b中所示的相机)的使用,以进行如例如在美国专利申请序列号14/707,000和15/238,516中所述的眼睛跟踪,该专利申请的全部内容通过引用并入在此。该系统可以被配置为在眼睛跟踪中进行若干步骤,诸如首先拍摄用户眼睛的图像;然后使用分割分析来分割眼睛的解剖结构(例如,将瞳孔与虹膜、巩膜、周围皮肤分割开);然后,系统可以被配置为使用在眼睛的图像中识别的闪烁位置来估计瞳孔中心,闪烁由小的照明源(16)(诸如led)产生,该照明源(16)可以放置在头戴式部件(58)的面向内侧周围;从这些步骤,系统可以被配置为使用几何关系来确定关于特定眼睛注视的空间位置的准确估计。对于双眼来说,特别是考虑到便携式系统(诸如以板载嵌入式处理器和有限的功率为特征的头戴式部件(58))上可用的资源,这种过程是相当计算密集的。
可以训练和利用深度学习技术来解决这些和其它计算挑战。例如,在一个实施例中,可以利用深度学习网络来进行上述眼睛跟踪范例的分割部分(例如,可以利用深度卷积网络将左眼图像和右眼图像稳健地按像素分割成虹膜、瞳孔、巩膜和其它类),其他一切保持不变;这种配置采用了该过程的大量计算密集部分之一并使其显著更有效。在另一个实施例中,可以训练并利用联合深度学习模型来进行分割、瞳孔检测和闪烁检测(例如,可以利用深度卷积网络将左眼图像和右眼图像稳健地按像素分割成虹膜、瞳孔、巩膜和其它类;然后可以利用眼睛分割来缩小有源面向内led照明源的2-d闪烁位置);然后可以进行几何计算以确定注视。这种范例也简化了计算。在第三实施例中,可以训练并利用深度学习模型来基于来自面向内相机的眼睛的两个图像来直接估计注视(例如,在这种实施例中,仅使用用户眼睛的图片的深度学习模型可以被配置为告诉系统用户在三维空间中注视的位置;可以利用深度卷积网络将左眼图像和右眼图像稳健地按像素分割成虹膜、瞳孔、巩膜和其它类;然后可以利用眼睛分割来缩小有源面向内led照明源的2-d闪烁位置;2-d闪烁位置以及3-dled位置可用于检测3-d中的角膜中心;请注意,所有3-d位置可能位于相应的相机坐标系中;然后,也可以利用眼睛分割来使用椭圆拟合来检测2-d图像中的瞳孔中心;使用离线校准信息,可以将2-d瞳孔中心映射到3-d注视点,在校准期间确定深度;连接角膜3-d位置和3-d注视点位置的线是该眼睛的注视矢量);这种范例也简化了计算,并且可以训练相关的深度网络以在给定左图像和右图像的情况下直接预测3-d注视点。这种深度网络执行这种训练的损失函数可以是简单的欧几里德损失,或者还包括眼睛模型的众所周知的几何约束。
此外,可以包括深度学习模型,用于使用来自面向内相机的用户虹膜的图像进行生物度量识别。这种模型还可用于确定用户是否佩戴隐形眼镜-因为模型将在来自面向内相机的图像数据的傅里叶变换中跳出。
利用面向外相机(诸如图16a中所示的相机(124,154,156))的使用,进行slam或ptam分析以确定姿势,诸如用户头部相对于他当前佩戴头戴式部件(58)的环境的姿势,如上所述。大多数slam技术取决于几何特征的跟踪和匹配,如上述实施例中所述。通常,处于“纹理”世界中是有帮助的,其中面向外相机能够检测角落、边缘和其它特征;此外,可以对在场景中检测到的特征的持久性/静态性做出某些假设,并且采用slam或ptam过程为所有这种映射和跟踪分析提供重要的计算和功率资源是有帮助的;这种资源可能在某些系统(诸如便携式或可穿戴的一些系统)中短缺,并且可能具有有限的嵌入式处理能力和可用功率。
示例deepslam网络
深度学习网络可以结合到各种实施例中以观察图像数据的差异,并且基于训练和配置,在本系统的变体的slam分析中发挥关键作用(在slam的上下文中,在此的深度网络可以被认为是“deepslam”网络)。
在一个实施例中,可以利用deepslam网络来估计从耦接到要跟踪的部件(诸如增强现实系统的头戴式部件(58))的相机捕获的一对帧之间的姿势。该系统可以包括卷积神经网络,该卷积神经网络被配置为学习姿势的变换(例如,头戴式部件58的姿势)并以跟踪方式应用它。该系统可以被配置为开始查看特定矢量和取向,诸如在已知原点处直线向前(因此作为x,y,z的0,0,0)。然后,用户的头部可以例如向右移动一点,然后在帧0和帧1之间向左移动一点,目的是寻找姿势变换或相对姿势变换。可以在一对图像上训练相关联的深度网络,例如,其中我们知道姿势a和姿势b,以及图像a和图像b;这会导致一定的姿势变换。通过确定姿势变换,然后可以将相关联的imu数据(来自加速度计、陀螺仪等-如上所述)集成到姿势变换中,并在用户远离原点、围绕房间以及任何轨迹移动时继续跟踪。这种系统可以被称为“相对姿势网”,如上所述,基于成对的帧来训练,其中已知的姿势信息是可用的(该变换是根据一帧到另一帧确定的,并且基于实际图像中的变化,系统根据平移和旋转来学习姿势变换)。深度单应性估计或相对姿势估计已经在例如美国专利申请序列号62/339,799中进行了讨论,该申请通过引用整体并入在此。
当利用这种配置来进行从帧0到帧1的姿势估计时,结果通常不是完美的,并且系统可以实施用于处理漂移的方法。当系统从帧1向前移动到2、到3、到4,并且估计相对姿势时,在每对帧之间引入少量误差。该误差通常累积并且成为问题(例如,在没有解决这种基于误差的漂移的情况下,系统可能最终以姿势估计将用户和他或她的相关联系统部件放置在错误的位置和取向中。在一个实施例中,可以应用“循环闭合”的概念来解决所谓的“重定位”问题。换句话说,系统可以被配置为确定它是否已经在先前特定的位置-如果是,则鉴于相同位置的先前姿势信息,预测的姿势信息应该是有意义的。例如,系统可以被配置为使得当它在地图上看到之前已经看到的帧时,它重定位;如果平移关闭,比如说在x方向中平移5mm,并且旋转关闭,比如在θ方向中旋转5度,则系统将该差异与其它相关联帧的差异一起固定;因此,轨迹成为真正的轨迹,而不是错误的轨迹。在美国专利申请序列号62/263,529中讨论了重定位,该专利申请的全部内容通过引用结合在此。
还发现,当估计姿势时,特别是通过使用imu信息(例如,诸如来自相关联的加速度计、陀螺仪等的数据,如上所述),在所确定的位置和取向数据中存在噪声。例如,如果系统直接利用这些数据而无需进一步处理来呈现图像,则用户可能会经历不希望的抖动和不稳定性;这就是为什么在某些技术中,诸如上面描述的那些技术中,可以利用卡尔曼滤波器、传感器融合技术和平滑功能。采用诸如上述使用卷积神经网络来估计姿势的深度网络解决方案,可以使用类似于长期短期记忆网络的递归神经网络(rnn)来解决平滑问题。换句话说,系统可以被配置为构建卷积神经网络,并且最重要的是,放置rnn。传统的神经网络在设计上是前馈的,在时间上是静态的;给出图像或图像对,他们给你一个答案。使用rnn,层的输出被添加到下一个输入并再次反馈到同一层中-这通常是网络中唯一的层;可以设想为“穿越时间”-在每个时间点,相同的网络层重新考虑稍微时间上调整的输入,并重复该循环。此外,与前馈网络不同,rnn可以接收一系列值作为输入(例如,随时间推移排序)-并且还可以产生一系列值作为输出。具有内置反馈回路的rnn的简单结构允许其表现得像预测引擎,并且当在该实施例中与卷积神经网络结合时的结果是系统可以从卷积神经网络获取相对有噪声的轨迹数据,将其推过rnn,并且它将输出更平滑的轨迹,更像是人体运动,诸如用户头部的运动,该用户头部可以耦接到可穿戴计算系统的头戴式部件(58)。
该系统还可以被配置为从立体图像对确定对象的深度,其中您具有深度网络并且输入左图像和右图像。卷积神经网络可以被配置为输出左和右相机之间(诸如在头戴式部件58上的左眼相机和右眼相机之间)的视差;如果已知相机的焦距,则确定的视差是深度的倒数,因此系统可以被配置为有效地计算具有视差信息的深度;然后可以进行网格化和其它过程而不涉及用于感测深度的替代部件,诸如深度传感器,其可能需要相对高的计算和功率资源负载。
关于语义分析和深度网络应用于本增强现实配置的各种实施例,若干领域具有特别的兴趣和适用性,包括但不限于检测手势和关键点、面部识别和3-d对象识别。
关于手势识别,在各种实施例中,系统被配置为识别通过用户的手以控制系统某些手势。在一个实施例中,嵌入式处理器可以被配置为利用所谓的“随机森林”以及感测到的深度信息来识别用户的某些手势。随机森林模型是非确定性模型,该非确定性模型可以使用相当大的参数库,并且可以使用相对大的处理能力并因此使用功率需求。此外,深度传感器可能并不总是最适合于读取具有特定背景(诸如靠近主体手的深度的桌子或桌面或墙壁)的手势,这是由于某些深度传感器的噪声限制以及无法准确地确定例如1或2cm深度之间的差异。在某些实施例中,可以用深度学习网络替换随机森林类型的手势识别。利用深度网络进行这种配置的挑战之一是将图像信息的部分(诸如像素)标记为“手”或“非手”;训练和利用具有这种分割挑战的深度网络可能需要进行具有数百万个图像的分割,这非常昂贵且耗时。为了解决该问题,在一个实施例中,在训练时间期间,热相机(诸如可用于军事或安全目的的热相机)可以耦接到传统的面向外相机,使得热相机通过示出图像的哪些部分足够热以作为人手以及哪些不是人手,显著地进行“手”和“非手”的分割。
关于面部识别,并且考虑到本增强现实系统被配置为在与其他人的社交环境中佩戴,理解用户周围的人可能具有相对高的价值-不仅仅是为了简单地识别其他附近的人,而且也用于调节所呈现的信息(例如,如果系统将附近的人识别为成年朋友,则可能建议您下棋并协助;如果系统将附近的人识别为您的孩子,则可能建议您去踢足球并且可以协助;如果系统未能识别附近的人,或者将他们识别为已知的危险,则用户可能倾向于避免与这种人接近)。在某些实施例中,可以利用深度神经网络配置来辅助面部识别,其方式类似于上面关于深度重定位所讨论的方式。可以利用与用户的生活相关的多个不同面部来训练模型,并且然后当面部靠近系统时,诸如在头戴式部件(58)附近,系统可以在像素空间中拍摄该面部图像,平移它,例如进入128维矢量,并且然后使用矢量作为高维空间中的点,以确定该人是否存在于您已知的人员列表中。本质上,系统可以被配置为在该空间中进行“最近邻居”搜索,并且当结果出现时,这种配置可以非常准确,假阳性率在1000范围中的1个中运行。
关于3-d对象检测,在某些实施例中,结合深度神经网络是有用的,该深度神经网络将从三维视角向用户告知它们所处的空间(例如,不仅是墙壁、地板、天花板,以及填充房间的对象,诸如沙发、椅子、橱柜等-不仅仅是传统的二维感,而是真正的三维感)。例如,在一个实施例中,期望用户具有理解房间中的沙发的真实体积范围的模型-使得例如在要抛出虚拟球或其它对象的情况下,用户知道沙发的体积占据了什么体积。可以利用深度神经网络模型来形成具有高度复杂性的立方体模型。
在某些实施例中,可以利用深度强化网络或深度强化学习来有效地学习代理在特定环境下应该做什么,而用户不必直接告知代理。例如,如果用户想要总是有他的狗在他占据的房间里走动的虚拟表示,但他希望狗的表示总是可见的(例如,不隐藏在墙壁或柜子后面),则深度强化方法可以将场景变成各种游戏,其中允许虚拟代理(这里是虚拟狗)在用户附近的物理空间中漫游,但是在训练时间期间,如果狗从比如t0至t1停留在可接受的位置,则给予奖励,并且如果用户对狗的视图被遮挡、丢失或者狗碰到墙壁或对象,则会给予惩罚。采用这种实施例,深度网络开始学习它需要做什么来赢得积分而不是丢失积分,并且很快它知道它需要知道什么来提供所需功能。
该系统还可以被配置为以近似或匹配用户周围的实际世界的照明的方式解决虚拟世界的照明。例如,为了使虚拟感知尽可能最优地与增强现实中的实际感知混合,采用虚拟对象尽可能逼真地再现照明颜色、阴影和照明矢量化。换句话说,如果要将虚拟不透明咖啡杯放置在房间的实际桌面上,房间的一个特定角落发出黄色的有色光,从真实世界桌上的真实世界对象产生阴影,则最优地将虚拟咖啡杯的光着色和阴影与实际场景相匹配。在某些实施例中,可以利用深度学习模型来学习放置系统部件的实际环境的照明。例如,可以利用模型,给定来自实际环境的图像或图像序列,该模型学习房间的照明以确定诸如亮度、色调和由一个或多个光源矢量化的因素。可以从合成数据和从用户装置(诸如从用户的头戴式部件(58))捕获的图像训练这种模型。
示例水螅架构
参考图29,示出了可以被称为“水螅(hydra)”架构(272)的深度学习网络架构。采用这种配置,诸如imu数据(来自加速度计、陀螺仪、磁力计)、面向外相机数据、深度感测相机数据和/或声音或语音数据的各种输入(270)可以被引导到具有一组或多个下层(268)的多层集中处理资源,该一组或多个下层(268)进行整个处理的重要部分,将其结果传递给一组或多个中间层(266),并最终传递给表示各种处理功能(诸如面部识别、视觉搜索、手势识别、语义分割、对象检测、照明检测/确定、slam、重定位和/或深度估计(诸如来自立体图像信息,如上所述))的多个相关联“头部”(264)中的一个或多个。手势、对象、重定位或深度(或与任何功能相关联的任何状态)的发生、确定或识别可以被称为与特定功能相关联的事件。在可穿戴显示系统中,在各种实施例中,水螅架构可以在本地处理和数据模块70或远程处理模块和数据存储库72、74上实施并由其执行。多个下层(268)和中间层(266)可以称为多个中级层。
传统上,当使用深度网络来实现各种任务时,将针对每个任务构建算法。因此,如果它想要识别汽车,则将为此构建算法;如果需要识别面部,则将为此构建算法;并且这些算法可以同时运行。如果无限或高级别的功率和计算资源可用,则这种配置将很好地工作并获得结果;但是在许多场景中,诸如具有嵌入式处理器中有限电源以及有限处理能力的便携式增强现实系统的场景,计算和功率资源可能相对有限,并且可能需要一起处理任务的某些方面。此外,如果一种算法具有来自另一种算法的知识,则在一些实施例中可以使第二算法更好。例如,如果一个深度网络算法知道狗和猫,则来自该算法的知识转移(也称为“域适应”)可以帮助另一种算法更好地识别鞋子。因此,有理由在训练和推理期间在算法之间具有某种串扰。
此外,存在与算法设计和修改有关的考虑。优选地,如果相对于算法的初始版本需要进一步的能力,则不需要从头开始完全重建新的能力。所描绘的水螅架构(272)可以用于解决这些挑战,以及计算和功率效率挑战,因为如上所述,存在可以共享的某些计算过程的共同方面的情况。例如,在所描绘的水螅架构(272)中,输入(270)(诸如来自一个或多个相机的图像信息)可以被带入下层(268)中,在该下层中可以进行相对较低级别的特征提取。例如,gabor函数、高斯导数、基本上影响线条、边缘、角落、颜色的东西-这些对于低级别的许多问题是均匀的。因此,无论任务变化如何,低级别特征提取可以是相同的,无论是否是提取猫、汽车或奶牛的目标-并且因此可以共享与其相关的计算。水螅架构(272)是一种高级范例,它允许跨算法的知识共享以使每个更好,它允许特征共享,使得计算可以共享、减少,而不是冗余,并且允许人们无需重写所有内容即可扩展功能套件-相反,新功能可以在现有功能的基础上堆叠。
因此,如上所述,在所描绘的实施例中,水螅架构表示具有一个统一路径的深度神经网络。网络的底层(268)是共享的,并且它们从输入图像和其它输入(270)中提取可视图元的基本单元。该系统可以被配置为经过几层卷积以提取边缘、线条、轮廓、连接点等。程序员用于特征工程的基本部件现在已经被深层网络学习。事实证明,这些特征对于许多算法都很有用,无论算法是面部识别、跟踪等。因此,一旦完成了较低的计算工作,并且存在从图像或其它输入到所有其它算法的共享表示,然后可以存在个别路径,每个问题或功能一个路径。因此,除了该共享表示之外,还存在通向非常特定于面部的面部识别的路径,存在通向非常特定于slam的跟踪的路径,以及对于架构(272)的其它“头部”(264)的路径等等。采用这种实施例,人们具有允许基本上相乘相加的所有共享计算,并且另一方面,人们具有在一般知识之上的非常特定的路径,并且允许人们微调并找到非常特定问题的答案。
具有这种配置的同样有价值的事实是这种神经网络被设计成使得更接近输入(270)的下层(268)利用更多的计算,因为在每个计算层处,系统采用原始输入并将其转换为一些其它维度空间,通常情况下事物的维度减少。因此,一旦实现了来自底层的网络的第五层,计算量可以在比最低级别中使用的量少5、10、20、100倍(或更多)的范围内(例如,因为输入要大得多,并且使用了更大的矩阵乘法)。在一个实施例中,到系统提取共享计算时,它对于需要解决的问题是相当不可知的。几乎所有算法的大部分计算都已在下层完成,因此当针对面部识别、跟踪、深度、照明等添加新路径时,这些对计算约束的贡献相对较小-并且因此这种架构提供了充足的扩展能力。在一个实施例中,对于前几个层,可能不存在池化来保留最高分辨率数据;中间层可具有池化过程,因为在那时,不需要高分辨率(例如,不需要高分辨率来知道汽车的轮子处于中间层的位置;网络通常需要知道螺母和螺栓从较高级别处以高分辨率位于何处,并且然后图像数据可以显著缩小,因为它被传递到中间层以用于车轮的定位)。例如,在较低级别中生成的特征包括具有第一分辨率的特征,并且在中间层中生成的特征包括具有小于第一分辨率的第二分辨率的特征。此外,一旦网络具有所有学习的连接,一切都松散地连线并且有利地通过数据学习连接。中间层(266)可以被配置为开始学习部分,例如-对象部分、面部特征等;因此,而不是简单的gabor函数,中间层正处理更复杂的构造或更高级别的特征(例如,波浪形状、阴影等)。然后,当过程向上移动到顶部时,分离成独特的头部分量(component)(264),其中的一些可能具有许多层,并且其中的一些可能具有很少的层。头部分量(264)的层可以称为头部分量层。同样,可扩展性和效率很大程度上是由于大部分(诸如90%)处理能力(例如,以每秒浮点运算(浮点运算(flop))测量)在下层(268)内的事实,然后一小部分(诸如5%的浮点运算)位于中间层(266)处,并且另外5%位于头部(264)中。
可以使用已经存在的信息对这种网络进行预训练。例如,在一个实施例(imagenet)中,可以利用来自大组类(在1000范围内)的大组(在1000万的范围内)来训练所有类。在一个实施例中,一旦训练,可以抛出区分类的顶层,但保留在训练过程中学习的所有权重。
训练具有水螅架构(272)的神经网络的过程涉及向网络呈现输入数据和对应的目标输出数据。包括示例输入和目标输出二者的该数据可以称为训练集。通过训练过程,可以递增地或迭代地适应网络的权重,包括与下层(268)、中间层(266)和头部分量(264)相关联的权重,使得网络的输出在给定来自训练集的特定输入数据的情况下,与该特定输入数据相对应的目标输出匹配(例如,尽可能接近)。
示例nn
诸如深度神经网络(dnn)的神经网络(nn)层可以将线性或非线性变换应用于其输入以生成其输出。深度神经网络层可以是归一化层、卷积层、软设计(softsign)层、修正线性层、级联层、池化层、循环层、类似初始层或其任何组合。归一化层可以归一化其输入的亮度,以通过例如l2归一化来生成其输出。例如,归一化层可以一次相对于彼此归一化多个图像的亮度,以生成多个归一化图像作为其输出。用于归一化亮度的方法的非限制性示例包括局部对比度归一化(lcn)或局部响应归一化(lrn)。局部对比度归一化可以通过在每个像素的基础上归一化图像的局部区域来非线性地归一化图像的对比度,以具有零的均值和1的方差(或者均值和方差的其它值)。局部响应归一化可以使局部输入区域上的图像归一化,以具有零的均值和1的方差(或均值和方差的其它值)。归一化层可以加速训练过程。
卷积层可以应用一组内核,该内核卷积其输入以生成其输出。softsign层可以将softsign函数应用于其输入。softsign函数(softsign(x))可以是例如(x/(1+|x|))。softsign层可能会忽略每个元素野值的影响。修正线性层可以是修正线性层单元(relu)或参数化的修正线性层单元(prelu)。relu层可以将relu函数应用于其输入以生成其输出。relu函数relu(x)可以是例如max(0,x)。prelu层可以将prelu函数应用于其输入以生成其输出。例如,如果x≥0,则prelu函数prelu(x)可以是x,并且如果x<0,则可以是ax,其中a是正数。级联层可以级联其输入以生成其输出。例如,级联层可以级联四个5×5图像以生成一个20×20图像。池化层可以应用池化功能,该功能对其输入进行向下采样以生成其输出。例如,池化层可以将20×20图像向下采样为10×10图像。池化功能的非限制性示例包括最大池化、平均池化或最小池化。
在时间点t,循环层可以计算隐藏状态s(t),并且循环连接可以在时间t将隐藏状态s(t)提供给循环层作为后续时间点t+1的输入。循环层可以基于时间t处的隐藏状态s(t)在时间t+1计算其输出。例如,循环层可以在时间t将softsign函数应用于隐藏状态s(t)以计算其在时间t+1的输出。在时间t+1处的循环层的隐藏状态具有在时间t处的循环层的隐藏状态s(t)作为其输入。循环层可以通过将例如relu函数应用于其输入来计算隐藏状态s(t+1)。类似初始层可包括归一化层、卷积层、软设计层、修正线性层(例如relu层和prelu层)、级联层、池化层或其任何组合中的一个或多个。
在不同的实施方式中,nn中的层数可以不同。例如,下层(268)或中间层(266)中的层数可以是50、100、200或更多。深度神经网络层的输入类型在不同的实施方式中可以是不同的。例如,层可以接收多个层的输出作为其输入。层的输入可以包括五层的输出。作为另一个示例,层的输入可以包括1%的nn层。层的输出可以是多个层的输入。例如,层的输出可以用作五层的输入。作为另一个示例,层的输出可以用作1%的nn层的输入。
层的输入大小或输出大小可能非常大。层的输入大小或输出大小可以是n×m,其中n表示宽度,并且m表示输入或输出的高度。例如,n或m可以是11、21、31或更多。在不同的实施方式中,层的输入或输出的通道大小可以是不同的。例如,层的输入或输出的通道大小可以是4、16、32、64、128或更多。在不同的实施方式中,层的内核大小可以不同。例如,内核大小可以是n×m,其中n表示宽度,并且m表示内核的高度。例如,n或m可以是5、7、9或更多。在不同的实施方式中,层的步幅大小可以不同。例如,深度神经网络层的步幅大小可以是3、5、7或更多。
其它方面和优点
在第一方面,公开了一种头戴式显示系统。头戴式显示系统包括:多个传感器,用于捕获不同类型的传感器数据;非暂态存储器,其被配置为存储:可执行指令,以及深度神经网络,其用于使用由多个传感器捕获的传感器数据执行与用户相关联的多个功能,其中深度神经网络包括用于接收深度神经网络的输入的输入层、多个下层、多个中间层以及用于输出与多个功能相关联的深度神经网络的结果的多个头部分量,其中输入层连接到多个下层的第一层,其中多个下层的最后一层连接到中间层的第一层,其中多个头部分量的头部分量包括头部输出节点,并且其中头部输出节点通过多个头部分量层连接到中间层的最后一层,该头部分量层表示从多个中间层到头部分量的唯一路径;显示器,其被配置为向用户显示与多个功能中的至少一个功能相关的信息;以及与多个传感器、非暂态存储器和显示器通信的硬件处理器,该硬件处理器由可执行指令编程为:从多个传感器接收不同类型的传感器数据;使用不同类型的传感器数据确定深度神经网络的结果;并且使得向用户显示与多个功能的至少一个功能相关的信息。
在第2方面,根据方面1所述的系统,其中,多个传感器包括惯性测量单元、面向外相机、深度感测相机、麦克风或其任何组合。
在第3方面,根据方面1-2中任一方面所述的系统,其中,多个功能包括面部识别、视觉搜索、手势识别、语义分割、对象检测、照明检测、同时定位和构建地图、重定位,或其任何组合。
在第4方面,根据方面1-3中任一方面所述的系统,其中,训练多个下层以从不同类型的传感器数据中提取较低级别特征。
在第5方面,根据方面4所述的系统,其中,训练多个中间层以从所提取的较低级别特征中提取较高级别特征。
在第6方面,根据方面5所述的系统,头部分量使用较高级别特征的子集来确定多个事件中的至少一个事件。
在第7方面,根据方面1-6中任一方面所述的系统,头部分量通过多个头部分量层连接到多个中间层的子集。
在第8方面,根据方面1-7中任一方面所述的系统,头部分量通过多个头部分量层连接到多个中间层中的每一个中间层。
在第9方面,根据方面1-8中任一方面所述的系统,其中,与多个下层相关联的多个权重超过与深度神经网络相关联的权重的50%,并且其中,与多个中间层相关联的多个权重以及与多个头部分量相关联的多个权重的总和小于与深度神经网络相关联的权重的50%。
在第10方面,根据方面1-9中任一方面所述的系统,其中,与多个下层相关联的计算超过与深度神经网络相关联的总计算的50%,并且其中,与多个中间层和多个头部分量相关联的计算小于涉及深度神经网络的计算的50%。
在第11方面,根据方面1-10中任一方面所述的系统,其中,多个下层、多个中间层或多个头部分量层包括卷积层、亮度归一化层、批归一化层、修正线性层、上采样层、级联层、完全连接层、线性完全连接层、软设计层、循环层或其任何组合。
在第12方面,根据方面1-11中任一方面所述的系统,其中,多个中间层或多个头部分量层包括池化层。
在第13方面,公开了一种用于训练神经网络以确定多个不同类型的事件的系统。该系统包括:存储可执行指令的计算机可读存储器;以及一个或多个处理器,其由可执行指令编程以至少:接收不同类型的传感器数据,其中,传感器数据与多个不同类型的事件相关联;生成包括作为输入数据的不同类型的传感器数据和作为对应的目标输出数据的多个不同类型的事件的训练集;以及使用训练集训练神经网络,用于确定多个不同类型的事件,其中,神经网络包括用于接收神经网络输入的输入层、多个中级层和用于输出神经网络的结果的多个头部分量,其中,输入层连接到多个中级层的第一层,其中,多个头部分量的头部分量包括头部输出节点,并且其中,头部输出节点通过多个头部分量层连接到中级层的最后一层。
在第14方面,根据方面13所述的系统,其中,不同类型的传感器数据包括惯性测量单元数据、图像数据、深度数据、声音数据、语音数据或其任何组合。
在第15方面,根据方面13-14中任一方面所述的系统,其中,多个不同类型的事件包括面部识别、视觉搜索、手势识别、语义分割、对象检测、照明检测、同时定位和构建地图、重定位或其任何组合。
在第16方面,根据方面13-15中任一方面所述的系统,其中,多个中级层包括多个下层和多个中间层,其中,训练多个下层以从不同类型的传感器数据提取较低级别特征,并且其中,训练多个中间层以从提取的较低级别特征中提取较高级别特征。
在第17方面,根据方面13-16中任一方面所述的系统,头部分量通过多个头部分量层连接到多个中间层的子集。
在第18方面,根据方面13-17中任一方面所述的系统,头部分量通过多个头部分量层连接到多个中级层中的每一个中级层。
在第19方面,根据方面13-18中任一方面所述的系统,其中,多个中级层或多个头部分量层包括卷积层、亮度归一化层、批归一化层、修正线性层、上采样层、池化层、级联层、完全连接层、线性完全连接层、软设计层、循环层或其任何组合。
在第20方面,根据方面13-19中任一方面所述的系统,其中,一个或多个处理器进一步由可执行指令编程为至少:接收第二不同类型的传感器数据,其中,第二不同类型的传感器数据与第二不同类型的事件相关联;生成包括作为输入数据的第二不同类型的传感器数据和作为对应的目标输出数据的第二不同类型的事件的重新训练集;并且使用重新训练集重新训练神经网络,用于确定第二不同类型的事件,其中,多个头部分量的第二头部分量包括第二头部输出节点,用于输出与第二不同类型的事件相关联的结果,以及其中,头部输出节点通过多个第二头部分量层连接到中级层的最后一层。
在第21方面,根据方面20所述的系统,其中,为了重新训练神经网络,由可执行指令对一个或多个处理器进行编程以至少:更新与多个第二头部分量层相关联的权重。
在第22方面,根据方面20所述的系统,其中,重新训练神经网络而不更新与多个中级层相关联的权重。
在第23方面,根据方面13-22中任一方面所述的系统,其中,多个不同类型的传感器数据与第二不同类型的事件相关联,并且其中,一个或多个处理器进一步由可执行指令编程以至少:生成包括作为输入数据的不同类型的传感器数据和作为对应的目标输出数据的第二不同类型的事件的重新训练集;并使用重新训练集重新训练神经网络,以确定第二不同类型的事件。
在第24方面,根据方面23所述的系统,其中,为了重新训练神经网络,一个或多个处理器由可执行指令编程以至少:更新与多个第二头部分量层相关联的权重。
在第25方面,根据方面23-24中任一方面所述的系统,其中,重新训练神经网络而不更新与多个中级层相关联的权重。
在第26方面,公开了一种方法。该方法受硬件处理器的控制,并包括:接收不同类型的训练传感器数据,其中,训练传感器数据与多个不同类型的事件相关联;生成包括作为输入数据的不同类型的训练传感器数据和作为对应的目标输出数据的多个不同类型的事件的训练集;以及使用训练集训练神经网络,用于确定多个不同类型的事件,其中,神经网络包括用于接收神经网络输入的输入层、多个中级层和用于输出神经网络的结果的多个头部分量,其中,输入层连接到多个中级层的第一层,其中,多个头部分量的头部分量包括头部输出节点,并且其中,头部输出节点通过多个头部分量层连接到中级层的最后一层。
在第27方面,根据方面26所述的方法,其中,不同类型的训练传感器数据包括惯性测量单元数据、图像数据、深度数据、声音数据、语音数据或其任何组合。
在第28方面,根据方面26-27中任一方面所述的方法,其中,多个不同类型的事件包括面部识别、视觉搜索、手势识别、语义分割、对象检测、照明检测、同时定位和构建地图、重定位或其任何组合。
在第29方面,根据方面26-28中任一方面所述的方法,其中,多个中级层包括多个下层和多个中间层。
在第30方面,根据方面29所述的方法,其中,训练多个下层以从不同类型的训练传感器数据中提取较低级别的特征。
在第31方面,根据方面30所述的方法,其中,训练多个中间层以从所提取的较低级别特征中提取更复杂的构造。
在第32方面,根据方面26-31中任一方面所述的方法,其中,与多个下层相关联的多个权重超过与神经网络相关联的权重的50%,并且其中,与多个中间层相关联的多个权重和与多个头部分量相关联的多个权重之和小于与神经网络相关联的权重的50%。
在第33方面,根据方面26-32中任一方面所述的方法,其中,当训练神经网络时与多个下层相关联的计算超过与训练神经网络相关联的总计算的50%,并且其中,与多个中间层和多个头部分量相关联的计算小于涉及神经网络的计算的50%。
在第34方面,根据方面26-33中任一方面所述的方法,其中,多个中级层或多个头部分量层包括卷积层、亮度归一化层、批归一化层、修正线性层、上采样层、池化层、级联层、完全连接层、线性完全连接层、软设计、循环层或其任何组合。
在第35方面,根据方面26-34中任一方面所述的方法,进一步包括:接收第二不同类型的训练传感器数据,其中,第二不同类型的训练传感器数据与第二不同类型的事件相关联;生成包括作为输入数据的第二不同类型的训练传感器数据和作为对应的目标输出数据的第二不同类型的事件的重新训练集;以及使用重新训练集重新训练神经网络,用于确定第二不同类型的事件,其中,多个头部分量的第二头部分量包括第二头部输出节点,用于输出与第二不同类型事件相关联的结果,以及其中,头部输出节点通过多个第二头部分量层连接到中级层的最后一层。
在第36方面,根据方面35所述的方法,其中,为了重新训练神经网络,一个或多个处理器由可执行指令编程以至少:更新与多个第二头部分量层相关联的权重。
在第37方面,根据方面35所述的方法,其中,重新训练神经网络而不更新与多个中级层相关联的权重。
在第38方面,根据方面26-37中任一方面所述的方法,其中,多个不同类型的训练传感器数据与第二不同类型的事件相关联,该方法进一步包括:生成包括作为输入数据的不同类型的训练传感器数据和作为对应的目标输出数据的第二不同类型的事件的重新训练集;并使用重新训练集重新训练神经网络,以确定第二不同类型的事件。
在第39方面,根据方面26-38中任一方面所述的方法,进一步包括:接收与不同类型的训练传感器数据相对应的不同类型的用户传感器数据;以及使用神经网络和不同类型的用户传感器数据确定多个不同类型事件的中事件。在第40方面,根据方面39所述的方法,进一步包括显示与事件有关的信息。
在第40方面,一种可穿戴显示系统,包括:第一传感器,其被配置为以第一频率操作;第二传感器,其被配置为以第二频率操作,该第二频率低于第一频率;硬件处理器,其被编程为接收来自第一传感器的第一输入和来自第二传感器的第二输入,对第一输入和第二输入进行滤波,并输出滤波结果。在一些实施例中,为了滤波第二输入中的第一输入,硬件处理器被编程为利用扩展卡尔曼滤波器。
在第41方面,一种可穿戴显示系统,其包括:多个传感器,以及硬件处理器,其被编程为从多个传感器中的每一个传感器接收输入,评估水螅神经网络架构,并生成多个功能输出。水螅神经网络可包括:多个下层,其被配置为接收来自多个传感器中的每一个传感器的输入并提取多较低级别特征;多个中间层,其被配置为接收来自多个下层的输入并提取多个较高级别特征,该较高级别特征具有小于较低级别特征的分辨率;以及多个头部,其被配置为从中间层接收输入并生成多个功能输出。多个传感器可包括惯性测量单元(imu)、面向外相机、深度传感器或音频传感器。多个功能输出可以包括面部识别、视觉搜索、手势识别、语义分割、对象检测、照明、定位和构建地图、重定位或深度估计。在一些方面,下层不包括池化层,而中间层确实包括池化层。在一些方面,水螅神经网络架构被配置为使得下层执行神经网络的计算的第一部分,中间层执行神经网络的计算的第二部分,并且头部执行神经网络的计算的第三部分,其中第一部分以在从5至100的范围内的因子大于第二部分或第三部分。
其它考虑因素
在此描述和/或附图中描绘的过程、方法和算法中的每一个可以在由一个或多个物理计算系统、硬件计算机处理器、专用电路和/或配置为执行具体和特定计算机指令的电子硬件执行的代码模块中体现,并且完全或部分地由代码模块自动化。例如,计算系统可以包括用特定计算机指令或专用计算机、专用电路等编程的通用计算机(例如服务器)。代码模块可以被编译并链接到可执行程序中,安装在动态链接库中,或者可以用解释的编程语言编写。在一些实施方式中,特定操作和方法可以由特定于给定功能的电路执行。
此外,本公开的功能的某些实施方式在数学上、计算上或技术上足够复杂,以使得应用专用硬件或一个或多个物理计算装置(利用适当的专用可执行指令)可能有必要执行功能,例如由于所涉及的计算的量或复杂性或者基本上实时地提供结果。例如,视频可以包括许多帧,每个帧具有数百万个像素,并且需要专门编程的计算机硬件来处理视频数据以在商业上合理的时间量内提供所需的图像处理任务或应用。
代码模块或任何类型的数据可以存储在任何类型的非暂态计算机可读介质上,诸如包括硬盘驱动器、固态存储器、随机存取存储器(ram)、只读存储器(rom)、光盘、易失性或非易失性存储设备,它们的组合等的物理计算机存储设备。方法和模块(或数据)还可以作为生成的数据信号(例如,作为载波或其它模拟或数字传播信号的一部分)在各种计算机可读传输介质(包括基于无线的和有线的/基于电缆的介质)上发送,并且可以采用多种形式(例如,作为单个或多路复用模拟信号的一部分,或者作为多个离散数字分组或帧)。所公开的过程或过程步骤的结果可以持久地或以其它方式存储在任何类型的非暂态有形计算机存储设备中,或者可以经由计算机可读传输介质传送。
在此描述和/或附图中描绘的流程图中的任何过程、框、状态、步骤或功能应当理解为可能表示代码模块、代码段或代码部分,其包括用于实施特定功能(例如,逻辑或算术)或过程中的步骤的一个或多个可执行指令。各种过程、块、状态、步骤或功能可以与在此提供的说明性示例组合、重新排列、添加、删除、修改或以其它方式改变。在一些实施例中,附加或不同的计算系统或代码模块可以执行在此描述的一些或全部功能。在此描述的方法和过程也不限于任何特定序列,并且与其相关的块、步骤或状态可以以适当的其它顺序执行,例如,以串行、并行或以一些其它方式。可以向所公开的示例实施例添加任务或事件或从中删除任务或事件。此外,在此描述的实施方式中的各种系统部件的分离是出于说明性目的,并且不应被理解为在所有实施方式中都需要这种分离。应当理解,所描述的程序部件、方法和系统通常可以一起集成在单个计算机产品中或打包成多个计算机产品。许多实施方式变化都是可能的。
过程、方法和系统可以在网络(或分布式)计算环境中实施。网络环境包括企业范围的计算机网络、内联网、局域网(lan)、广域网(wan)、个人局域网(pan)、云计算网络、众包计算网络、互联网和万维网。网络可以是有线或无线网络或任何其它类型的通信网络。
本发明包括可以使用本装置执行的方法。该方法可以包括提供这种合适装置的行为。这种提供可以由最终用户执行。换句话说,“提供”行为仅需要终端用户获得、访问、接近、定位、设置、激活、加电或以其它方式行动以在本方法中提供必需的装置。在此所述的方法可以以所述事件的任何顺序进行,该顺序在逻辑上是可能的,并且以所述事件的顺序排列。
本公开的系统和方法各自具有若干创新方面,其中没有一个单独地对在此公开的期望属性负责或要求。上述各种特征和过程可以彼此独立地使用,或者可以以各种方式组合。所有可能的组合和子组合都旨在落入本公开的范围内。对本领域技术人员来说,对本公开中描述的实施方式的各种修改是显而易见的,并且在不脱离本公开的精神或范围的情况下,在此定义的一般原理可以应用于其它实施方式。因此,权利要求不旨在限于在此所示的实施方式,而是与符合本公开、在此公开的原理和新颖特征的最宽范围相一致。
在单独实施方式的上下文中在本说明书中描述的某些特征也可以在单个实施方式中组合实施。相反,在单个实施方式的上下文中描述的各种特征也可以单独地或以任何合适的子组合在多个实施方式中实施。此外,尽管上面的特征可以描述为以某些组合起作用并且甚至最初如此要求保护,但是在一些情况下可以从组合中切除来自所要求保护的组合的一个或多个特征,并且所要求保护的组合可以针对子组合或子组合的变体。对于每个和所有实施例,需要单个特征或特征组并非必需或必不可少。
除非另有说明,或者在所使用的上下文中以其它方式理解,否则在此使用的条件语言,诸如“能够”、“可以”、“可能”、“可”、“例如”等通常旨在传达某些实施例包括某些特征、元件和/或步骤,而其它实施例不包括某些特征、元件和/或步骤。因此,这种条件语言通常不旨在暗示一个或多个实施例以任何方式需要特征、元素和/或步骤,或者一个或多个实施例必须包括用于决定是否在任何特定实施例中包括或将要执行这些特征、元件和/或步骤(无论是否有作者输入或提示)的逻辑。术语“包含”、“包括”、“具有”等是同义的并且以开放式方式包含使用,并且不排除附加元件、特征、动作、操作等。此外,术语“或”在其包含意义上使用(而不是在其独有意义上),因此当使用时,例如,为了连接元素列表,术语“或”表示列表中的一个、一些或全部元素。另外,除非另有说明,否则本申请和所附权利要求中使用的冠词“一”、“一个”和“该”应理解为表示“一个或多个”或“至少一个”。除非在此具体定义,否则在此使用的所有技术和科学术语在保持权利要求有效性的同时尽可能广泛地给出通常理解的含义。还应注意,可以起草权利要求以排除任何可选元素。
如在此所使用的,指代项目列表中的“至少一个”的短语是指那些项目的任何组合,包括单个成员。例如,“a、b或c中的至少一个”旨在涵盖:a、b、c、a和b、a和c、b和c,以及a、b和c。除非另外特别说明,否则诸如短语“x、y和z中的至少一个”的联合语言以其它方式通过上下文理解为通常用于传达项目、术语等可以是x、y或z中的至少一个。因此,这种联合语言通常不旨在暗示某些实施例需要x中的至少一个、y中的至少一个和z中的至少一个各自存在。
类似地,虽然可以以特定顺序在附图中描绘操作,但应认识到,不需要以所示的特定顺序或按顺序执行这些操作,或者执行所有示出的操作,以实现期望的结果。此外,附图可以以流程图的形式示意性地描绘一个或多个示例过程。然而,未示出的其它操作可以包含在示意性示出的示例方法和过程中。例如,可以在任何所示操作之前、之后、同时或之间执行一个或多个附加操作。另外,可以在其它实施方式中重新排列或重新排序操作。在某些情况下,多任务处理和并行处理可能是有利的。此外,上述实施方式中的各种系统部件的分离不应被理解为在所有实施方式中都需要这种分离,并且应当理解,所描述的程序部件和系统通常可以在单个软件产品中集成在一起或者被打包到多种软件产品。另外,其它实施方式在以下权利要求的范围内。在一些情况下,权利要求中记载的动作可以以不同的顺序执行并且仍然实现期望的结果。
- 还没有人留言评论。精彩留言会获得点赞!