用于分割文本的系统和方法与流程
本申请涉及文本处理技术,更具体地涉及从样本文本提取组织词组和基于组织词组分割文本。
背景技术:
文本语音转换技术可以将文本语句转录为音频信号。例如,在导航应用程序(例如,didiapp)中,诸如交通状况、地址等的文本语句可以通过语音呈现给用户。
为了自然的阅读,一段文本(例如,语句)在被转录成音频信号之前必须进行适当地分割。通常,语句中包括的每个词组包含一个或以上的单词。与本申请一致,单词可以是英语、法语、西班牙语或拉丁语,或亚洲语言,如中文、韩文、日文等中的字符。这些单词或字符可以分成至少两个可能组合的词组。
文本语句可能包含地址信息或兴趣点(poi),也可被称为“组织词组”。例如,在导航文本语句“中国-新加坡工业园区距离30公里”中,“工业园区”是组织词组。根据所述组织词组,上述语句可以被分割为“中国-新加坡/工业园区/距离30公里”。因此,组织词组可用于促进文本语句的适当分割。
本申请的实施例提供了一种改进的用于提取组织词组和基于组织词组分割文本的系统和方法。
技术实现要素:
本申请的一个方面提供了一种用于分割文本的方法。该方法可以包括通过处理器识别由至少两个样本文本共有的候选词组。通过处理器确定候选词组的评估分数。当评估分数符合默认标准时,通过处理器将候选词组识别为组织词组,并基于组织词组进行文本分割。
本申请的另一方面提供了一种用于分割文本的系统。该系统可以包括通信接口,其被配置用于接收至少两个样本文本并存储。处理器被配置用于识别由至少两个样本文本共有的候选词组。确定候选词组的评估分数。当评估分数符合默认标准时,将候选词组识别为组织词组,并基于组织词组进行文本分割。
本申请的又一方面提供了一种非暂时性计算机可读取介质,其存储一组指令,当由电子装置的至少一个处理器执行时,使得电子装置执行用于生成组织单词列表的方法。该方法可以包括识别由至少两个样本文本共有的候选词组。确定候选词组的评估分数。当评估分数符合默认标准时,将候选词组识别为组织词组,并基于组织词组进行分割文本。
应当理解,前面的一般性描述和下面的详细描述都只是示例性和说明性的,并不是对本申请所要求保护的限制。
附图说明
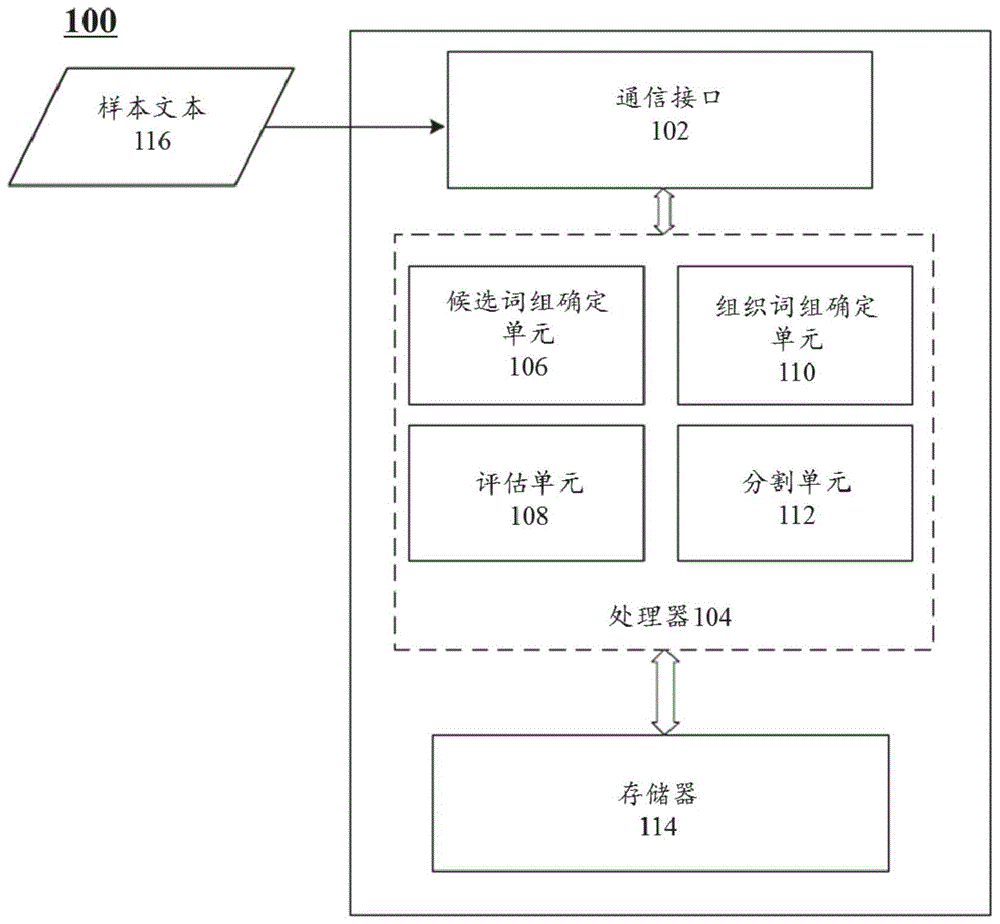
图1是根据本申请的一些实施例所示的用于分割文本的示例性系统框图。
图2是根据本申请的一些实施例所示的用于分割文本的示例性方法的流程图。
图3是根据本申请的一些实施例所示的用于确定评估分数的流程的流程图。
具体实施方式
本申请通过示例性实施例进行详细描述,这些示例性实施例将通过图式进行详细描述。任何可能的情况下,图中同一参考数字表示相同的部分。
本申请的一个方面涉及一种用于分割文本的系统。例如,图1系根据本申请的一些实施例所示的用于分割文本的示例性系统100的框图。
系统100可以是通用服务器或用于处理语句中的文本信息的专用装置。如图1所示,系统100可以包括通信接口102、处理器104和存储器114。处理器104还可以包括多个功能模块,例如候选词组确定单元106、评估单元108、组织词组确定单元110和分割单元112。这些模块(以及任何相应的子模块或子单元)可以是处理器104的功能硬件单元(例如,整合电路的部分),这些硬件单元被设计与其他组件或程序的一部分一起使用。所述程序可以被存储在计算机可读介质上,当其被处理器104执行时,所述程序可以执行一个或多个功能。尽管图1示出的单元106-112全部在处理器104内,但可以预期的是,这些单元可以分布在多个处理器中,这些处理器彼此位置邻近或彼此远离。在一些实施例中,系统100可以在云中或在单独的计算机/服务器上实施。
通信接口102可以被配置为接收一个或以上样本文本116。在一些实施例中,样本文本116可以地址信息以识别位置,例如道路、建筑物、公园等。
存储器114可以被配置为存储一个或以上样本文本116。存储器114可以实现为任何类型的易失性或非易失性存储器装置或其组合,诸如静态随机访问存储器(sram)、电子可擦除可程序设计只读存储器(eeprom)、可程序设计可擦除只读存储器(eprom)、可程序设计只读存储器(prom)、只读存储器(rom)、磁存储器、闪存、或磁盘、或光盘。
根据本申请的实施例,候选词组确定单元106可以基于所接收的样本文本116确定候选词组。例如,至少两个样本文本可包括“北京工业园区”、“上海工业园区”、“硅谷工业园区”、“中国-新加坡工业园区”和“北京新工业园区”。候选词组确定单元106可以比较至少两个样本文本,并确定样本文本116中的共有词组(例如,“工业公园”)作为候选词组。在上述样本文本中,候选词组位于每个样本文本的末尾。
然后,评估单元108可以确定候选词组的评估分数。评估分数表示候选词组是组织词组的概率。在一些实施例中,可以基于候选词组是否与适当的分割路径相关确定评估分数。也就是说,当将候选词组视为组织词组的分割路径产生更高的评估分数时,这表明候选词组确实是组织词组。
在非限制性示例中,评估单元108可以生成不同于第一分割路径的第二分割路径,第一分割路径包括与候选词组相对应的分割,并且评估单元108可以确定第二分割路径是否是适当的分割路径。如果第二分割路径不太可能是适当的分割路径,则相反的第一分割路径更可能是适当的分割路径。因此,候选词组更可能是组织词组。
根据本申请,评估单元108可以识别与每个样本文本的候选词组相关的参考词组,并确定包含参考词组的第一数量的样本文本。参考词组可能与样本文本的不适当分割有关。例如,在样本文本“卡姆登/大街”中,“大街”可以被确定为候选词组,并且评估单元108需要基于候选词组确定分割是否合理。为此,评估单元108可以生成可供选择的分割,例如“卡姆登大/街”。基于该可供选择的分割,评估单元108可将“卡姆登大”确定为参考词组,并确定包含“卡姆登大”总数为t的样本文本。然后,评估单元108可以将每个样本文本分割成多段,并确定包含与参考词组相对应的片段的第二数量的样本文本。参考上述示例,评估单元108可以使用语言模型将每个样本文本分割成多段,并且确定包含与“卡姆登大”相关的片段的总数为m的样本文本。语言模型可以根据自然语言规则生成分割路径。也就是说,在数量为m的样本文本中,“卡姆登大”被分割成段。如上所述,以“卡姆登大”作为分割片段是不适当分割。因此,可以基于数量t和m,确定分割失败率p,p可以根据下面的等式计算。
p=m×m/t
根据以上讨论,参考词组(例如,“卡姆登大”)表示不适当分割,因此p表示与参考词组相关的分割是不合适的。当含有与参考词组相关的分割片段的样本文本的数量m较小时,p的值较小,这表明包括候选词组的分割更可能是一个适当的分割,因为只有少量的其他片段存在。例如,样本文本“卡姆登/大街”的分割失败率p为0.4,样本文本“山西/南道”的分割失败率p为0.3,而“罗/南道”可能有17.2的分割失败率p。
可以想到,上述语言模型可以根据自然语言规则对文本进行分割。语言模型可以针对指定语言进行训练,例如英语、中文、日语等。
基于针对每个样本文本计算的分割失败率,评估单元108可以通过平均各个样本文本的分割失败率确定评估分数。各个样本文本可以各自包括与候选词组相关的分割片段。例如,“大街”的评估分数s可以是0。988,而“壮族街”的评估分数s可以是5.731。可以以任何合适的方式聚类各个得分以得出评估分数。例如,评估分数可以是各个分数的加权平均值而不是各个分数的直接平均值,并且权重可以对应于相关的样本文本的使用频率。例如,在导航应用程序(例如,didiapp)中,“中国-新加坡工业园区”更常用,基于此文本生成的候选词组“工业园区”的评估分数将被分配更大的权值。
当评估分数满足默认标准时,组织词组确定单元110可将候选词组识别为组织词组。在一些实施例中,当评估分数小于阈值时,可以将候选词组确定为组织词组。例如,阈值可以预定为“1”。参考上述“大街”和“壮族街”的例子,具有0.988的评估分数s的“大街”可以被确定为组织词组。
组织词组确定单元110可以进一步生成组织词组的列表,并且在组织词组的列表中按照相应的评估分数的上升顺序进行排名。该列表可以存储在存储器114中并用于进一步处理。在一些实施例中,可以自动或手动地查看列表以移除被认为是非组织词组的一个或以上词组。
分割单元112可以进一步基于组织词组分割文本。例如,当使用语言模型为一个文本生成多于一个的分割路径时,分割单元112可以选择包括组织词组作为片段的分割路径,并相应地分割文本。或者,可以训练语言模型以将组织词组自动地视为片段。
系统100可以从样本文本提取组织词组,所提取的组织词组可以进一步用于在文本被转录为音频信号之前对文本进行分割。
本申请的另一方面涉及一种用于分割文本的方法。例如,图2是根据本申请的一些实施例所示的用于分割文本的示例性方法200的流程图。在一些实施例中,方法200可以由分割装置实现,并且可以包括步骤s202-s208。
在步骤s202中,分割装置可以识别由至少两个样本文本共有的候选词组。可以比较至少两个样本文本以确定候选词组。在一些实施例中,候选词组位于每个样本文本的末尾。
在步骤s204,分割装置可以确定候选词组的评估分数。可以基于文本的多个可供选择的分割路径确定评估分数。分割路径中的至少一个路径以候选词组作为分割片段。图3是根据本申请的一些实施例所示的用于确定评估分数的流程300的流程图。
如图3所示,在步骤s302,分割装置可以确定与每个样本文本的候选词组相关的参考词组。可以基于与包括不同候选词组的分割路径确定参考词组。在步骤s304,分割装置可以确定包含参考词组的第一数量的样本文本。
然后,在步骤s306,分割装置可以将每个样本文本分割成多段,并且确定包含参考词组作为片段的第二数量的样本文本。在一些实施例中,可以使用语言模型分割样本文本。在步骤s308,分割装置可以基于第一数量和第二数量确定分割失败率。
在步骤s310中,分割装置可以通过聚类(例如平均)相应样本文本的分割失败率确定评估分数。各个样本文本可以各自包括与候选词组相关的片段。
返回参考图2,在步骤s206,当评估分数满足默认标准时,分割装置可以将候选词组确定为组织词组。在一些实施例中,当评估分数小于阈值时,可以将候选词组确定为组织词组。例如,阈值可以预定为“1”。
在步骤s208中,分割装置可以基于组织词组对文本进行分割。例如,可以以组织词组作为片段进行分割。
本申请的又一方面涉及存储指令的非暂时性计算机可读介质,如上所述,所述指令在被执行时使得一个或以上处理器执行所述方法。所述计算机可读取介质包括易失性或非易失性、磁性、半导体、磁带、光学、可擦、不可擦或其他类型的计算机可读取介质或计算机可读取存储装置。例如,如本申请所公开的,计算机可读取介质可以是存储装置或其上存储有计算机指令的存储器模块。在一些实施例中,计算机可读取介质可以是其上存储有计算机指令的磁盘或闪存驱动器。
对本领域的普通技术人员显而易见的是,可以对所公开的分割系统和相关方法进行各种修改和变化。考虑到所公开的系统和相关方法的说明书和实践,其他实施例对于本领域的普通技术人员是显而易见的。
本申请中的说明书和示例的目的仅被认为是示例性的,真正的范围由以下权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!