一种面向黑盒测试背景下的回归测试用例分类方法与流程
本发明属于软件测试技术领域,且特别是关于一种面向黑盒测试背景下的回归测试用例分类方法。该方法实现了被测软件源代码不可见及测试预言缺失情形下的软件测试自动化验证,增强了黑盒测试背景下的无测试预言的回归测试的可行性,提高了软件回归测试效率。
背景技术:
软件测试是软件生命周期中的一项重要活动,其主要用于保障软件质量与可靠性。由于软件的升级、软件错误的修复及软件运行环境的变化,软件处于动态演化中。软件一旦发生变化就需要对其进行回归测试,以确保软件的变化没有引入新的错误,且未对原有的代码产生副作用。另外,程序员也通过回归测试建立一种信心。作为软件生命周期代价最昂贵的活动之一,回归测试占了软件维护阶段总费用的50%,总测试预算的80%。在极限编程与快速迭代开发模式中,回归测试消耗更多的测试资源。软件的复杂性以及回归测试高昂的测试代价对软件测试与维护人员提出了新的挑战。有效地降低回归测试资源消耗,提高回归测试的效率已成为软件工程研究领域和工业界亟待解决的问题。
鉴于知识产权的保护及商业机密等原因,软件交给第三方机构进行测评时,其源代码是不公开的。这增加了其测试的难度。无论是在演化的当前软件版本上运行已有的测试用例,还是运行新增的测试用例,都需要基于测试预言检验被测软件的运行是否正确。然而,测试预言的构建是借助专家知识完成的,非常耗时耗力。例如:验证医学影像分割软件就需要依赖医生的专业知识构建测试预言,据此判断分割的医学影像是否正确。
软件演化后原有的测试用例集不一定满足测试充分性的要求,需要产生新的测试用例,同时也要为每一个新产生的测试用例构造测试预言。相似地,针对历史版本中的测试用例构造的测试预言在演化后的软件版本上会发生失效,这就需要基于演化的软件版本为原有的测试用例重新构造测试预言。在当前的工业界,仍是借助手工方式产生测试预言。这意味着软件测试需要消耗更多的测试资源。伴随软件多样性与复杂性的不断增加,亟需软件测试的自动化验证技术,以满足工业需求。
在回归测试背景下,如果不构造测试预言或仅为少量测试用例构造测试预言而又能自动判定回归测试用例的类别将大大地降低回归测试能耗,提高回归测试效率。测试用例反映了测试意图,相似的测试用例的错误检测能力是非常接近的。这意味着相似的测试用例的类别几乎是一致的。测试用例对应的文本信息反映了测试意图,收集该信息并训练分类模型,从而实现自动化判定新增测试用例与原始测试用例在演化之后的软件版本上的类别。这为测试预言缺失及被测软件源代码不可用情形下的回归测试提供了一种高效、可行的解决方案。
随着敏捷开发与快速迭代开发方法的不断普及,软件的回归测试变得更加频繁。为此,软件回归测试需要消耗更多的测试资源。另外,测试预言难以构造及被测软件源代码的不可见性都增加了软件回归测试的难度。这使得传统的回归测试用例分类方法已经越来越不能满足软件回归测试的实际需要。
技术实现要素:
本发明目的在于提供一种面向黑盒测试背景下的回归测试用例分类方法,解决被测软件源代码不可见及测试预言缺失情形下的软件回归测试自动化验证问题。基于测试用例的特征信息对回归测试用例进行自动化分类,实现黑盒测试背景下被测软件的自动化验证,从而提高软件回归测试效率,进而增强软件产品的质量。
本发明的技术方案为:面向黑盒测试背景下的回归测试用例分类方法,对历史测试用例与新增测试用例对应的文本信息进行预处理,采用LDA(Latent DirichletAllocation)主题模型技术对预处理的文本进行主题建模,进一步将测试用例对应的文本表示为主题特征向量;随机选取部分原始测试用例与新增测试用例,并针对当前软件版本为其构造测试预言,基于选择的测试用例在当前软件版本上的运行结果标注其类别;以标注过的测试用例作为训练集,训练支持向量机(Support Vector Machine,SVM)分类模型;将待分类的测试用例对应的主题特征向量作为分类模型的输入,最终输出其类别。
为实现上述目标,本发明提出了一种面向黑盒测试背景下的回归测试用例分类方法,本方法具体步骤如下:
1)对原始测试用例与新增测试用例对应的文本信息进行预处理,移除数字、程序语言的关键词及特定字符,基于骆驼命名法(Camle-Case)分割标识符名称,将每一个单词转换成其基本形式,以降低测试用例文本包含的词汇数;
2)采用LDA主题模型技术对预处理后的文本进行主题建模,获得每一个测试用例对应的文本关于主题的分布,并把每一个测试用例对应的文本表示为主题特征向量;
3)从原始测试用例集合与新增测试用例集合中各随机选择10%的测试用例,针对演化后的软件版本为选择的测试用例构造测试预言,并在演化后的软件版本上运行所选的测试用例,根据运行结果与其测试预言是否一致标注测试用例的类别,若一致,测试用例为正确的用例,反之为错误的用例;
4)基于步骤3)选择的测试用例对应的主题特征向量及类别信息训练SVM分类模型;
5)选择待分类的测试用例对应的主题特征向量作为步骤3)产生的SVM分类模型的输入,最终输出待分类的测试用例的类别。
进一步,其中上述步骤1)的具体步骤如下:
步骤1)-1:起始状态;
步骤1)-2:按行读取一个测试用例对应的文本信息;
步骤1)-3:移除该行文本中的程序语言关键词、运算符,基于骆驼命名法对词进行分割,移除与英语语言相关的停止词,并将每一个单词转换成基本形式;
步骤1)-4:重复执行步骤1)-2和步骤1)-3,直到处理完该测试用例对应的文本信息,并将其保存在磁盘文件中;
步骤1)-5:重复执行上述步骤1)-2、步骤1)-3和步骤1)-4,直到预处理完所有历史测试用例及新增测试用例对应的文本信息;
步骤1)-6:测试用例对应的文本信息预处理完毕;
进一步,其中上述步骤2)的具体步骤如下:
步骤2)-1:起始状态;
步骤2)-2:逐一读入步骤1)预处理后的每个测试用例对应的文档,对该文档进行向量化;
步骤2)-3:重复执行步骤2)-2,直到处理完所有文档,最终将所有文档表示成文档-特征词矩阵;
步骤2)-4:输入初始参数α,β,k的值,它们分别表示Dirichlet分布的参数、主题生成单词的概率及主题个数,利用Gibbs抽样算法进行参数估计,最终构造LDA主题模型;
步骤2)-5:利用LDA对每一个测试用例对应文档进行处理,以获得文档的主题概率分布,采用向量表示,向量中的每一个元素值表示该文档隶属于主题的概率值;
步骤2)-6:重复步骤2)-5,直到获得所有文档的主题概率分布;
步骤2)-7:保存测试用例的编号与其主题特征向量到磁盘文件中;
步骤2)-8:测试用例的主题特征向量构造完毕;
进一步,其中上述步骤3)的具体步骤如下:
步骤3)-1:在原始测试用例集合与新增测试用例集合中各随机选择10%的测试用例作为训练分类模型的训练集;
步骤3)-2:针对演化后的新的软件版本为步骤3)-1选择的测试用例构造测试预言;
步骤3)-3:在演化后的新的软件版本上运行步骤3)-1选择的测试用例,并收集测试用例运行结果信息;
步骤3)-4:根据测试预言与测试结果标注步骤3)-1选择的测试用例类别,如果测试结果与测试预言一致,该测试用例为正确的用例,标签记为1,否则,为错误的用例,标签记为-1;
步骤3)-5:重复执行步骤3)-4,直到已标注了所有选择的测试用例;
步骤3)-6:保存测试用例的编号与标签信息;
步骤3)-7:测试用例的类别标注完毕;
进一步,上述步骤4)的具体步骤如下:
步骤4)-1:读取步骤3)选择的测试用例的编号与标签;
步骤4)-2:按读取的测试用例编号从步骤2)产生的主题特征向量文件中获取测试用例的主题特征向量;
步骤4)-3:重复步骤4)-1与步骤4)-2,直到读取了所有已标注的测试用例主题特征向量与标签信息,以读取的主题特征向量与其标签作为训练分类模型的输入;
步骤4)-4:以径向基函数为核函数,同时指定到达率σ的值,训练SVM分类模型;
步骤4)-5:SVM分类模型构造完毕;
进一步,上述步骤5)的具体步骤如下:
步骤5)-1:选择待分类的测试用例,并按其编号信息从步骤2)产生的主题特征向量文件中获取该测试用例的主题特征向量;
步骤5)-2:以主题特征向量作为步骤4)产生的SVM分类模型的输入,根据模型的输出值判定测试用例的类别;
步骤5)-3:待分类的测试用例类别判定完毕。
本发明基于测试用例的语义信息进行黑盒测试背景下的回归测试用例分类,大幅提高了软件回归测试的自动化效率;本方法有效地解决了被测软件源代码不可见及测试预言缺失情形下的回归测试验证问题,该方法不仅适用于在演化之后的软件版本上对原有测试用例进行分类,同时也适用于针对演化之后的软件版本新增测试用例的分类;本发明从测试用例对应文本的预处理,到基于主题模型的主题特征向量构建,再到分类模型的训练,均采用自动化的方式进行,大大地提高了回归测试的自动化效率,从而更好地控制软件质量。
附图说明
图1为本发明实施例的一种面向黑盒测试背景下的回归测试用例分类方法的流程图。
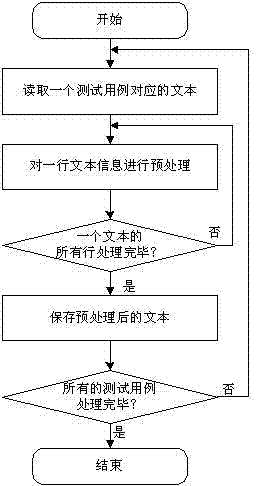
图2为图1中测试用例对应文本预处理的流程图。
图3为图1中测试用例对应文本主题建模的流程图。
图4为图1中测试用例类别标注的流程图。
图5为图1中训练SVM分类模型的流程图。
图6为图1中测试用例分类的流程图。
具体实施方式
为了更清晰的了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
图1为本发明实施例的一种面向黑盒测试背景下的回归测试用例分类方法的流程图。
一种面向黑盒测试背景下的回归测试用例分类方法,其特征在于,包括下列步骤:
S101测试用例对应文本预处理,对原始测试用例与新生成的测试用例对应的文本信息进行预处理,移除数字、程序语言的关键词及特定字符,并基于骆驼命名法(Camle-Case)分割标识符名称,将每一个单词转换成其基本形式,以降低测试用例文本包含的词汇数;
S103测试用例对应文本主题建模,采用LDA主题模型技术对预处理后的文本进行主题建模,获得每一个测试用例对应的文本关于主题的分布,并把每一个测试用例对应的文本表示为主题特征向量;
S105测试用例类别标注,原始的测试用例集合与新增的测试用例集合中各随机选择10%的测试用例,并且为选择的每个测试用例构造其在演化后的软件版本上的测试预言,并在演化后的软件版本上运行所选的测试用例。根据测试用例的运行结果与其测试预言是否一致标注测试用例的类别。若一致,测试用例为正确的用例,反之为错误的用例;
S107训练SVM分类模型,以选择的测试用例对应的主题特征向量及类别信息训练SVM分类模型;
S109测试用例分类,选择待分类的测试用例对应的主题特征向量作为SVM分类模型的输入,输出待分类的测试用例的类别。
图2为测试用例对应文本预处理的流程图。对原始测试用例与新生成的测试用例对应的文本信息进行预处理,移除数字、程序语言的关键词及特定字符,并基于骆驼命名法(Camle-Case)分割标识符名称,将每一个单词转换成其基本形式,以降低测试用例文本包含的词汇数。具体步骤如下:
步骤1:起始状态;步骤2:按行读取一个测试用例对应的文本信息;步骤3:移除该行文本中的程序语言关键词、运算符,基于骆驼命名法对词进行分割,移除与英语语言相关的停止词,并将每一个单词转换成基本形式;步骤4:重复执行步骤2和步骤3,直到处理完该测试用例对应的文本信息,并将其保存在磁盘文件中;步骤5:重复执行上述步骤2、步骤3和步骤4,直到预处理完所有历史测试用例及新增测试用例对应的文本信息;步骤6:测试用例对应的文本信息预处理完毕。
图3为测试用例对应文本主题建模的流程图。采用LDA主题模型技术对预处理后的文本进行主题建模,获得每一个测试用例对应的文本关于主题的分布,并把每一个测试用例对应的文本表示为主题特征向量。具体步骤如下:
步骤1:起始状态;步骤2:逐一读入预处理后的每个测试用例对应的文档,对该文档进行向量化;步骤3:重复执行步骤2,直到处理完所有文档,最终将所有文档表示成文档-特征词矩阵;步骤4:输入初始参数α,β,k的值,它们分别表示Dirichlet分布的参数、主题生成单词的概率及主题个数,利用Gibbs抽样算法进行参数估计,最终构造LDA主题模型;步骤5:利用LDA对每一个测试用例对应文档进行处理,以获得文档的主题概率分布,采用向量表示,向量中的每一个元素值表示该文档隶属于主题的概率值;步骤6:重复步骤5,直到获得所有文档的主题概率分布;步骤7:保存测试用例的编号与其主题特征向量到磁盘文件;步骤8:测试用例的主题特征向量构造完毕。
图4为测试用例类别标注的流程图。从原始测试用例集合与新增测试用例集合中各随机选择10%的测试用例,针对演化后的软件版本为选择的测试用例构造测试预言,并在演化后的软件版本上运行所选的测试用例,根据运行结果与其测试预言是否一致标注测试用例的类别,若一致,测试用例为正确的用例,反之为错误的用例。具体步骤如下:
步骤1:在原始的测试用例集合与新增的测试用例集合中各随机选择10%的测试用例作为训练分类模型的训练集;步骤2:针对演化后的新的软件版本为步骤1选择的测试用例构造测试预言;步骤3:在演化后的新的软件版本上运行步骤1选择的测试用例,并收集测试用例运行结果信息;步骤4:根据测试预言与测试结果标注步骤1选择的测试用例类别,如果测试结果与测试预言一致,该测试用例为正确的用例,标签记为1,否则,为错误的用例,标签记为-1;步骤5:重复执行步骤4,直到已标注了所有选择的测试用例;步骤6:保存测试用例的编号与标签信息;步骤7:测试用例的类别标注完毕。
图5为训练SVM分类模型的流程图。以选择的测试用例对应的文本特征向量及类别信息训练SVM分类模型。具体步骤如下:
步骤1:读取选择的测试用例的编号与标签;步骤2:按读取的测试用例编号从主题特征向量文件中获取该测试用例的主题特征向量;步骤3:重复步骤1与步骤2,直到读取了所有已标注的测试用例主题特征向量与标签信息,并以此作为训练分类模型的输入;步骤4:以径向基函数为核函数,同时指定到达率σ的值,训练SVM分类模型;步骤5:SVM分类模型构造完毕。
图6为测试用例分类的流程图。选择待分类的测试用例对应的主题特征向量作为SVM分类模型的输入,输出待分类的测试用例的类别。具体步骤如下:
步骤1:选择待分类的测试用例,并按其编号信息从主题特征向量文件中获取该测试用例的主题特征向量;步骤2:以主题特征向量作为分类模型的输入,根据模型的输出值判定测试用例的类别;步骤3:待分类的测试用例类别判定完毕。
综上所述,本发明解决了被测软件源代码不可见情形下的软件回归测试验证问题,该方法仅需要为少量测试用例构造测试预言,利用主题模型与支持向量机技术对回归测试用例进行分类,不仅大幅提高了回归测试的自动化程度和运转效率,而且也降低了软件回归测试能耗,从而更好地控制软件产品的质量。
- 还没有人留言评论。精彩留言会获得点赞!